Kubernetes 文档这一部分包含的一些页面展示如何去完成单个任务。 每个任务页面是一般通过给出若干步骤展示如何执行完成某事。
如果你希望编写一个任务页面,参考 创建一个文档拉取请求。
Kubernetes 文档这一部分包含的一些页面展示如何去完成单个任务。 每个任务页面是一般通过给出若干步骤展示如何执行完成某事。
如果你希望编写一个任务页面,参考 创建一个文档拉取请求。
Kubernetes 命令行工具 kubectl, 让你可以对 Kubernetes 集群运行命令。 你可以使用 kubectl 来部署应用、监测和管理集群资源以及查看日志。
有关更多信息,包括 kubectl 操作的完整列表,请参见 kubectl 参考文件。
kubectl 可安装在各种 Linux 平台、 macOS 和 Windows 上。 在下面找到你喜欢的操作系统。
kind 让你能够在本地计算机上运行 Kubernetes。
使用这个工具需要你安装 Docker 或者 Podman。
kind 的 Quick Start 页面展示开始使用
kind 所需要完成的操作。
与 kind 类似,minikube 是一个工具,
能让你在本地运行 Kubernetes。
minikube 在你的个人计算机(包括 Windows、macOS 和 Linux PC)上运行一个一体化(all-in-one)
或多节点的本地 Kubernetes 集群,以便你来尝试 Kubernetes 或者开展每天的开发工作。
如果你关注如何安装此工具,可以按官方的 Get Started!指南操作。
当你拥有了可工作的 minikube 时,
就可以用它来运行示例应用了。
你可以使用 kubeadm 工具来创建和管理 Kubernetes 集群。 该工具能够执行必要的动作并用一种用户友好的方式启动一个可用的、安全的集群。
安装 kubeadm 展示了如何安装 kubeadm 的过程。一旦安装了 kubeadm, 你就可以使用它来创建一个集群。
kubectl 版本和集群版本之间的差异必须在一个小版本号内。 例如:v1.29 版本的客户端能与 v1.28、 v1.29 和 v1.30 版本的控制面通信。 用最新兼容版的 kubectl 有助于避免不可预见的问题。
在 Linux 系统中安装 kubectl 有如下几种方法:
用以下命令下载最新发行版:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl"
如需下载某个指定的版本,请用指定版本号替换该命令的这一部分:
$(curl -L -s https://dl.k8s.io/release/stable.txt)。
例如,要在 Linux x86-64 中下载 1.29.2 版本,请输入:
curl -LO https://dl.k8s.io/release/v1.29.2/bin/linux/amd64/kubectl
对于 Linux ARM64 来说,请输入:
curl -LO https://dl.k8s.io/release/v1.29.2/bin/linux/arm64/kubectl
验证该可执行文件(可选步骤)
下载 kubectl 校验和文件:
curl -LO "https://dl.k8s.io/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl.sha256"
curl -LO "https://dl.k8s.io/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl.sha256"
基于校验和文件,验证 kubectl 的可执行文件:
echo "$(cat kubectl.sha256) kubectl" | sha256sum --check
验证通过时,输出为:
kubectl: OK
验证失败时,sha256 将以非零值退出,并打印如下输出:
kubectl: FAILED
sha256sum: WARNING: 1 computed checksum did NOT match
下载的 kubectl 与校验和文件版本必须相同。
安装 kubectl
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
即使你没有目标系统的 root 权限,仍然可以将 kubectl 安装到目录 ~/.local/bin 中:
chmod +x kubectl
mkdir -p ~/.local/bin
mv ./kubectl ~/.local/bin/kubectl
# 之后将 ~/.local/bin 附加(或前置)到 $PATH
执行测试,以保障你安装的版本是最新的:
kubectl version --client
或者使用如下命令来查看版本的详细信息:
kubectl version --client --output=yaml
更新 apt 包索引,并安装使用 Kubernetes apt 仓库所需要的包:
sudo apt-get update
# apt-transport-https 可以是一个虚拟包;如果是这样,你可以跳过这个包
sudo apt-get install -y apt-transport-https ca-certificates curl
下载 Kubernetes 软件包仓库的公共签名密钥。 同一个签名密钥适用于所有仓库,因此你可以忽略 URL 中的版本信息:
# 如果 `/etc/apt/keyrings` 目录不存在,则应在 curl 命令之前创建它,请阅读下面的注释。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.29/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
在低于 Debian 12 和 Ubuntu 22.04 的发行版本中,/etc/apt/keyrings 默认不存在。
应在 curl 命令之前创建它。
添加合适的 Kubernetes apt 仓库。如果你想用 v1.29 之外的 Kubernetes 版本,
请将下面命令中的 v1.29 替换为所需的次要版本:
# 这会覆盖 /etc/apt/sources.list.d/kubernetes.list 中的所有现存配置
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
要升级 kubectl 到别的次要版本,你需要先升级 /etc/apt/sources.list.d/kubernetes.list 中的版本,
再运行 apt-get update 和 apt-get upgrade。
更详细的步骤可以在更改 Kubernetes 软件包仓库中找到。
更新 apt 包索引,然后安装 kubectl:
sudo apt-get update
sudo apt-get install -y kubectl
添加 Kubernetes 的 yum 仓库。如果你想使用 v1.29 之外的 Kubernetes 版本,
将下面命令中的 v1.29 替换为所需的次要版本。
# 这会覆盖 /etc/yum.repos.d/kubernetes.repo 中现存的所有配置
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/repodata/repomd.xml.key
EOF
要将 kubectl 升级到别的次要版本,你需要先升级 /etc/yum.repos.d/kubernetes.repo
中的版本,再运行 yum update 命令。
更详细的步骤可以在更改 Kubernetes 软件包存储库中找到。
使用 yum 安装 kubectl:
sudo yum install -y kubectl
zypper 软件源。如果你想使用不同于 v1.29
的 Kubernetes 版本,请在下面的命令中将 v1.29 替换为所需的次要版本。# 这将覆盖 /etc/zypp/repos.d/kubernetes.repo 中的任何现有配置。
cat <<EOF | sudo tee /etc/zypp/repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/repodata/repomd.xml.key
EOF
要升级 kubectl 到另一个小版本,你需要先更新 /etc/zypp/repos.d/kubernetes.repo 的版本,
再运行 zypper update。
此过程在更改 Kubernetes 软件包仓库中有更详细的描述。
使用 zypper 安装 kubectl:
sudo zypper install -y kubectl
为了让 kubectl 能发现并访问 Kubernetes 集群,你需要一个
kubeconfig 文件,
该文件在
kube-up.sh
创建集群时,或成功部署一个 Minikube 集群时,均会自动生成。
通常,kubectl 的配置信息存放于文件 ~/.kube/config 中。
通过获取集群状态的方法,检查是否已恰当地配置了 kubectl:
kubectl cluster-info
如果返回一个 URL,则意味着 kubectl 成功地访问到了你的集群。
如果你看到如下所示的消息,则代表 kubectl 配置出了问题,或无法连接到 Kubernetes 集群。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
(访问 <server-name:port> 被拒绝 - 你指定的主机和端口是否有误?)
例如,如果你想在自己的笔记本上(本地)运行 Kubernetes 集群,你需要先安装一个 Minikube 这样的工具,然后再重新运行上面的命令。
如果命令 kubectl cluster-info 返回了 URL,但你还不能访问集群,那可以用以下命令来检查配置是否妥当:
kubectl cluster-info dump
在 Kubernetes 1.26 中,kubectl 删除了以下云提供商托管的 Kubernetes 产品的内置身份验证。 这些提供商已经发布了 kubectl 插件来提供特定于云的身份验证。 有关说明,请参阅以下提供商文档:
(还可能会有其他原因会看到相同的错误信息,和这个更改无关。)
kubectl 为 Bash、Zsh、Fish 和 PowerShell 提供自动补全功能,可以为你节省大量的输入。
下面是为 Bash、Fish 和 Zsh 设置自动补全功能的操作步骤。
kubectl 的 Bash 补全脚本可以用命令 kubectl completion bash 生成。
在 Shell 中导入(Sourcing)补全脚本,将启用 kubectl 自动补全功能。
然而,补全脚本依赖于工具 bash-completion,
所以要先安装它(可以用命令 type _init_completion 检查 bash-completion 是否已安装)。
很多包管理工具均支持 bash-completion(参见这里)。
可以通过 apt-get install bash-completion 或 yum install bash-completion 等命令来安装它。
上述命令将创建文件 /usr/share/bash-completion/bash_completion,它是 bash-completion 的主脚本。
依据包管理工具的实际情况,你需要在 ~/.bashrc 文件中手工导入此文件。
要查看结果,请重新加载你的 Shell,并运行命令 type _init_completion。
如果命令执行成功,则设置完成,否则将下面内容添加到文件 ~/.bashrc 中:
source /usr/share/bash-completion/bash_completion
重新加载 Shell,再输入命令 type _init_completion 来验证 bash-completion 的安装状态。
你现在需要确保一点:kubectl 补全脚本已经导入(sourced)到 Shell 会话中。 可以通过以下两种方法进行设置:
echo 'source <(kubectl completion bash)' >>~/.bashrc
kubectl completion bash | sudo tee /etc/bash_completion.d/kubectl > /dev/null
sudo chmod a+r /etc/bash_completion.d/kubectl
如果 kubectl 有关联的别名,你可以扩展 Shell 补全来适配此别名:
echo 'alias k=kubectl' >>~/.bashrc
echo 'complete -o default -F __start_kubectl k' >>~/.bashrc
bash-completion 负责导入 /etc/bash_completion.d 目录中的所有补全脚本。
两种方式的效果相同。重新加载 Shell 后,kubectl 自动补全功能即可生效。
若要在当前 Shell 会话中启用 Bash 补全功能,源引 ~/.bashrc 文件:
source ~/.bashrc
自动补全 Fish 需要 kubectl 1.23 或更高版本。
kubectl 通过命令 kubectl completion fish 生成 Fish 自动补全脚本。
在 shell 中导入(Sourcing)该自动补全脚本,将启动 kubectl 自动补全功能。
为了在所有的 shell 会话中实现此功能,请将下面内容加入到文件 ~/.config/fish/config.fish 中。
kubectl completion fish | source
重新加载 shell 后,kubectl 自动补全功能将立即生效。
kubectl 通过命令 kubectl completion zsh 生成 Zsh 自动补全脚本。
在 Shell 中导入(Sourcing)该自动补全脚本,将启动 kubectl 自动补全功能。
为了在所有的 Shell 会话中实现此功能,请将下面内容加入到文件 ~/.zshrc 中。
source <(kubectl completion zsh)
如果你为 kubectl 定义了别名,kubectl 自动补全将自动使用它。
重新加载 Shell 后,kubectl 自动补全功能将立即生效。
如果你收到 2: command not found: compdef 这样的错误提示,那请将下面内容添加到
~/.zshrc 文件的开头:
autoload -Uz compinit
compinit
kubectl convert 插件一个 Kubernetes 命令行工具 kubectl 的插件,允许你将清单在不同 API 版本间转换。
这对于将清单迁移到新的 Kubernetes 发行版上未被废弃的 API 版本时尤其有帮助。
更多信息请访问迁移到非弃用 API
用以下命令下载最新发行版:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl-convert"
验证该可执行文件(可选步骤)
下载 kubectl-convert 校验和文件:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl-convert.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/arm64/kubectl-convert.sha256"
基于校验和,验证 kubectl-convert 的可执行文件:
echo "$(cat kubectl-convert.sha256) kubectl-convert" | sha256sum --check
验证通过时,输出为:
kubectl-convert: OK
验证失败时,sha256 将以非零值退出,并打印输出类似于:
kubectl-convert: FAILED
sha256sum: WARNING: 1 computed checksum did NOT match
下载相同版本的可执行文件和校验和。
安装 kubectl-convert
sudo install -o root -g root -m 0755 kubectl-convert /usr/local/bin/kubectl-convert
验证插件是否安装成功
kubectl convert --help
如果你没有看到任何错误就代表插件安装成功了。
安装插件后,清理安装文件:
rm kubectl-convert kubectl-convert.sha256
kubectl 版本和集群之间的差异必须在一个小版本号之内。 例如:v1.29 版本的客户端能与 v1.28、 v1.29 和 v1.30 版本的控制面通信。 用最新兼容版本的 kubectl 有助于避免不可预见的问题。
在 macOS 系统上安装 kubectl 有如下方法:
下载最新的发行版:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl"
如果需要下载某个指定的版本,用该指定版本号替换掉命令的这个部分:$(curl -L -s https://dl.k8s.io/release/stable.txt)。
例如:要为 Intel macOS 系统下载 1.29.2 版本,则输入:
curl -LO "https://dl.k8s.io/release/v1.29.2/bin/darwin/amd64/kubectl"
对于 Apple Silicon 版本的 macOS,输入:
curl -LO "https://dl.k8s.io/release/v1.29.2/bin/darwin/arm64/kubectl"
验证可执行文件(可选操作)
下载 kubectl 的校验和文件:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl.sha256"
根据校验和文件,验证 kubectl:
echo "$(cat kubectl.sha256) kubectl" | shasum -a 256 --check
验证通过时,输出如下:
kubectl: OK
验证失败时,shasum 将以非零值退出,并打印如下输出:
kubectl: FAILED
shasum: WARNING: 1 computed checksum did NOT match
下载的 kubectl 与校验和文件版本要相同。
将 kubectl 置为可执行文件:
chmod +x ./kubectl
将可执行文件 kubectl 移动到系统可寻址路径 PATH 内的一个位置:
sudo mv ./kubectl /usr/local/bin/kubectl
sudo chown root: /usr/local/bin/kubectl
确保 /usr/local/bin 在你的 PATH 环境变量中。
测试一下,确保你安装的是最新的版本:
kubectl version --client
或者使用下面命令来查看版本的详细信息:
kubectl version --client --output=yaml
安装并验证 kubectl 后,删除校验和文件:
rm kubectl.sha256
如果你是 macOS 系统,且用的是 Homebrew 包管理工具, 则可以用 Homebrew 安装 kubectl。
运行安装命令:
brew install kubectl
或
brew install kubernetes-cli
测试一下,确保你安装的是最新的版本:
kubectl version --client
如果你用的是 macOS,且用 Macports 包管理工具,则你可以用 Macports 安装 kubectl。
运行安装命令:
sudo port selfupdate
sudo port install kubectl
测试一下,确保你安装的是最新的版本:
kubectl version --client
为了让 kubectl 能发现并访问 Kubernetes 集群,你需要一个
kubeconfig 文件,
该文件在
kube-up.sh
创建集群时,或成功部署一个 Minikube 集群时,均会自动生成。
通常,kubectl 的配置信息存放于文件 ~/.kube/config 中。
通过获取集群状态的方法,检查是否已恰当地配置了 kubectl:
kubectl cluster-info
如果返回一个 URL,则意味着 kubectl 成功地访问到了你的集群。
如果你看到如下所示的消息,则代表 kubectl 配置出了问题,或无法连接到 Kubernetes 集群。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
(访问 <server-name:port> 被拒绝 - 你指定的主机和端口是否有误?)
例如,如果你想在自己的笔记本上(本地)运行 Kubernetes 集群,你需要先安装一个 Minikube 这样的工具,然后再重新运行上面的命令。
如果命令 kubectl cluster-info 返回了 URL,但你还不能访问集群,那可以用以下命令来检查配置是否妥当:
kubectl cluster-info dump
在 Kubernetes 1.26 中,kubectl 删除了以下云提供商托管的 Kubernetes 产品的内置身份验证。 这些提供商已经发布了 kubectl 插件来提供特定于云的身份验证。 有关说明,请参阅以下提供商文档:
(还可能会有其他原因会看到相同的错误信息,和这个更改无关。)
kubectl 为 Bash、Zsh、Fish 和 PowerShell 提供自动补全功能,可以为你节省大量的输入。
下面是为 Bash、Fish 和 Zsh 设置自动补全功能的操作步骤。
kubectl 的 Bash 补全脚本可以通过 kubectl completion bash 命令生成。
在你的 Shell 中导入(Sourcing)这个脚本即可启用补全功能。
此外,kubectl 补全脚本依赖于工具 bash-completion, 所以你必须先安装它。
bash-completion 有两个版本:v1 和 v2。v1 对应 Bash 3.2(也是 macOS 的默认安装版本), v2 对应 Bash 4.1+。kubectl 的补全脚本无法适配 bash-completion v1 和 Bash 3.2。 必须为它配备 bash-completion v2 和 Bash 4.1+。 有鉴于此,为了在 macOS 上使用 kubectl 补全功能,你必须要安装和使用 Bash 4.1+ (说明)。 后续说明假定你用的是 Bash 4.1+(也就是 Bash 4.1 或更新的版本)。
后续说明假定你已使用 Bash 4.1+。你可以运行以下命令检查 Bash 版本:
echo $BASH_VERSION
如果版本太旧,可以用 Homebrew 安装/升级:
brew install bash
重新加载 Shell,并验证所需的版本已经生效:
echo $BASH_VERSION $SHELL
Homebrew 通常把它安装为 /usr/local/bin/bash。
如前所述,本说明假定你使用的 Bash 版本为 4.1+,这意味着你要安装 bash-completion v2 (不同于 Bash 3.2 和 bash-completion v1,kubectl 的补全功能在该场景下无法工作)。
你可以用命令 type _init_completion 测试 bash-completion v2 是否已经安装。
如未安装,用 Homebrew 来安装它:
brew install bash-completion@2
如命令的输出信息所显示的,将如下内容添加到文件 ~/.bash_profile 中:
brew_etc="$(brew --prefix)/etc" && [[ -r "${brew_etc}/profile.d/bash_completion.sh" ]] && . "${brew_etc}/profile.d/bash_completion.sh"
重新加载 Shell,并用命令 type _init_completion 验证 bash-completion v2 已经恰当的安装。
你现在需要确保在所有的 Shell 环境中均已导入(sourced)kubectl 的补全脚本, 有若干种方法可以实现这一点:
在文件 ~/.bash_profile 中导入(Source)补全脚本:
echo 'source <(kubectl completion bash)' >>~/.bash_profile
将补全脚本添加到目录 /usr/local/etc/bash_completion.d 中:
kubectl completion bash >/usr/local/etc/bash_completion.d/kubectl
如果你为 kubectl 定义了别名,则可以扩展 Shell 补全来兼容该别名:
echo 'alias k=kubectl' >>~/.bash_profile
echo 'complete -o default -F __start_kubectl k' >>~/.bash_profile
如果你是用 Homebrew 安装的 kubectl
(如此页面所描述),
则 kubectl 补全脚本应该已经安装到目录 /usr/local/etc/bash_completion.d/kubectl
中了。这种情况下,你什么都不需要做。
用 Hommbrew 安装的 bash-completion v2 会初始化目录 BASH_COMPLETION_COMPAT_DIR
中的所有文件,这就是后两种方法能正常工作的原因。
总之,重新加载 Shell 之后,kubectl 补全功能将立即生效。
自动补全 Fish 需要 kubectl 1.23 或更高版本。
kubectl 通过命令 kubectl completion fish 生成 Fish 自动补全脚本。
在 shell 中导入(Sourcing)该自动补全脚本,将启动 kubectl 自动补全功能。
为了在所有的 shell 会话中实现此功能,请将下面内容加入到文件 ~/.config/fish/config.fish 中。
kubectl completion fish | source
重新加载 shell 后,kubectl 自动补全功能将立即生效。
kubectl 通过命令 kubectl completion zsh 生成 Zsh 自动补全脚本。
在 Shell 中导入(Sourcing)该自动补全脚本,将启动 kubectl 自动补全功能。
为了在所有的 Shell 会话中实现此功能,请将下面内容加入到文件 ~/.zshrc 中。
source <(kubectl completion zsh)
如果你为 kubectl 定义了别名,kubectl 自动补全将自动使用它。
重新加载 Shell 后,kubectl 自动补全功能将立即生效。
如果你收到 2: command not found: compdef 这样的错误提示,那请将下面内容添加到
~/.zshrc 文件的开头:
autoload -Uz compinit
compinit
kubectl convert 插件 一个 Kubernetes 命令行工具 kubectl 的插件,允许你将清单在不同 API 版本间转换。
这对于将清单迁移到新的 Kubernetes 发行版上未被废弃的 API 版本时尤其有帮助。
更多信息请访问迁移到非弃用 API
用以下命令下载最新发行版:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl-convert"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl-convert"
验证该可执行文件(可选步骤)
下载 kubectl-convert 校验和文件:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/amd64/kubectl-convert.sha256"
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/darwin/arm64/kubectl-convert.sha256"
基于校验和,验证 kubectl-convert 的可执行文件:
echo "$(cat kubectl-convert.sha256) kubectl-convert" | shasum -a 256 --check
验证通过时,输出为:
kubectl-convert: OK
验证失败时,sha256 将以非零值退出,并打印输出类似于:
kubectl-convert: FAILED
shasum: WARNING: 1 computed checksum did NOT match
下载相同版本的可执行文件和校验和。
使 kubectl-convert 二进制文件可执行
chmod +x ./kubectl-convert
将 kubectl-convert 可执行文件移动到系统 PATH 环境变量中的一个位置。
sudo mv ./kubectl-convert /usr/local/bin/kubectl-convert
sudo chown root: /usr/local/bin/kubectl-convert
确保你的 PATH 环境变量中存在 /usr/local/bin。
验证插件是否安装成功
kubectl convert --help
如果你没有看到任何错误就代表插件安装成功了。
安装插件后,清理安装文件:
rm kubectl-convert kubectl-convert.sha256
根据你安装 kubectl 的方式,使用以下某种方法来卸载:
找到你系统上的 kubectl 可执行文件:
which kubectl
移除 kubectl 可执行文件:
sudo rm <path>
将 <path> 替换为上一步中找到的 kubectl 可执行文件的路径。
例如,sudo rm /usr/local/bin/kubectl。
如果你使用 Homebrew 安装了 kubectl,运行以下命令:
brew remove kubectl
kubectl 版本和集群版本之间的差异必须在一个小版本号内。 例如:v1.29 版本的客户端能与 v1.28、 v1.29 和 v1.30 版本的控制面通信。 用最新兼容版的 kubectl 有助于避免不可预见的问题。
在 Windows 系统中安装 kubectl 有如下几种方法:
下载最新补丁版 1.29: kubectl 1.29.2。
如果你已安装了 curl,也可以使用此命令:
curl.exe -LO "https://dl.k8s.io/release/v1.29.2/bin/windows/amd64/kubectl.exe"
要想找到最新稳定的版本(例如:为了编写脚本),可以看看这里 https://dl.k8s.io/release/stable.txt。
验证该可执行文件(可选步骤)
下载 kubectl 校验和文件:
curl.exe -LO "https://dl.k8s.io/v1.29.2/bin/windows/amd64/kubectl.exe.sha256"
基于校验和文件,验证 kubectl 的可执行文件:
在命令行环境中,手工对比 CertUtil 命令的输出与校验和文件:
CertUtil -hashfile kubectl.exe SHA256
type kubectl.exe.sha256
用 PowerShell 自动验证,用运算符 -eq 来直接取得 True 或 False 的结果:
$(Get-FileHash -Algorithm SHA256 .\kubectl.exe).Hash -eq $(Get-Content .\kubectl.exe.sha256)
将 kubectl 二进制文件夹追加或插入到你的 PATH 环境变量中。
测试一下,确保此 kubectl 的版本和期望版本一致:
kubectl version --client
或者使用下面命令来查看版本的详细信息:
kubectl version --client --output=yaml
Windows 版的 Docker Desktop
将其自带版本的 kubectl 添加到 PATH。
如果你之前安装过 Docker Desktop,可能需要把此 PATH 条目置于 Docker Desktop 安装的条目之前,
或者直接删掉 Docker Desktop 的 kubectl。
要在 Windows 上安装 kubectl,你可以使用包管理器 Chocolatey、 命令行安装器 Scoop 或包管理器 winget。
choco install kubernetes-cli
scoop install kubectl
winget install -e --id Kubernetes.kubectl
测试一下,确保安装的是最新版本:
kubectl version --client
导航到你的 home 目录:
# 当你用 cmd.exe 时,则运行: cd %USERPROFILE%
cd ~
创建目录 .kube:
mkdir .kube
切换到新创建的目录 .kube:
cd .kube
配置 kubectl,以接入远程的 Kubernetes 集群:
New-Item config -type file
编辑配置文件,你需要先选择一个文本编辑器,比如 Notepad。
为了让 kubectl 能发现并访问 Kubernetes 集群,你需要一个
kubeconfig 文件,
该文件在
kube-up.sh
创建集群时,或成功部署一个 Minikube 集群时,均会自动生成。
通常,kubectl 的配置信息存放于文件 ~/.kube/config 中。
通过获取集群状态的方法,检查是否已恰当地配置了 kubectl:
kubectl cluster-info
如果返回一个 URL,则意味着 kubectl 成功地访问到了你的集群。
如果你看到如下所示的消息,则代表 kubectl 配置出了问题,或无法连接到 Kubernetes 集群。
The connection to the server <server-name:port> was refused - did you specify the right host or port?
(访问 <server-name:port> 被拒绝 - 你指定的主机和端口是否有误?)
例如,如果你想在自己的笔记本上(本地)运行 Kubernetes 集群,你需要先安装一个 Minikube 这样的工具,然后再重新运行上面的命令。
如果命令 kubectl cluster-info 返回了 URL,但你还不能访问集群,那可以用以下命令来检查配置是否妥当:
kubectl cluster-info dump
在 Kubernetes 1.26 中,kubectl 删除了以下云提供商托管的 Kubernetes 产品的内置身份验证。 这些提供商已经发布了 kubectl 插件来提供特定于云的身份验证。 有关说明,请参阅以下提供商文档:
(还可能会有其他原因会看到相同的错误信息,和这个更改无关。)
kubectl 为 Bash、Zsh、Fish 和 PowerShell 提供自动补全功能,可以为你节省大量的输入。
下面是设置 PowerShell 自动补全功能的操作步骤。
你可以使用命令 kubectl completion powershell 生成 PowerShell 的 kubectl 自动补全脚本。
如果需要自动补全在所有 Shell 会话中生效,请将以下命令添加到 $PROFILE 文件中:
kubectl completion powershell | Out-String | Invoke-Expression
此命令将在每次 PowerShell 启动时重新生成自动补全脚本。你还可以将生成的自动补全脚本添加到 $PROFILE 文件中。
如果需要将自动补全脚本直接添加到 $PROFILE 文件中,请在 PowerShell 命令行运行以下命令:
kubectl completion powershell >> $PROFILE
完成上述操作后重启 Shell,kubectl 的自动补全就可以工作了。
kubectl convert 插件 一个 Kubernetes 命令行工具 kubectl 的插件,允许你将清单在不同 API 版本间转换。
这对于将清单迁移到新的 Kubernetes 发行版上未被废弃的 API 版本时尤其有帮助。
更多信息请访问迁移到非弃用 API
用以下命令下载最新发行版:
curl.exe -LO "https://dl.k8s.io/release/v1.29.2/bin/windows/amd64/kubectl-convert.exe"
验证该可执行文件(可选步骤)。
下载 kubectl-convert 校验和文件:
curl.exe -LO "https://dl.k8s.io/v1.29.2/bin/windows/amd64/kubectl-convert.exe.sha256"
基于校验和验证 kubectl-convert 的可执行文件:
用提示的命令对 CertUtil 的输出和下载的校验和文件进行手动比较。
CertUtil -hashfile kubectl-convert.exe SHA256
type kubectl-convert.exe.sha256
使用 PowerShell -eq 操作使验证自动化,获得 True 或者 False 的结果:
$($(CertUtil -hashfile .\kubectl-convert.exe SHA256)[1] -replace " ", "") -eq $(type .\kubectl-convert.exe.sha256)
将 kubectl-convert 二进制文件夹附加或添加到你的 PATH 环境变量中。
验证插件是否安装成功。
kubectl convert --help
如果你没有看到任何错误就代表插件安装成功了。
安装插件后,清理安装文件:
del kubectl-convert.exe kubectl-convert.exe.sha256
Kubernetes v1.15 [stable]
由 kubeadm 生成的客户端证书在 1 年后到期。 本页说明如何使用 kubeadm 管理证书续订,同时也涵盖其他与 kubeadm 证书管理相关的说明。
你应该熟悉 Kubernetes 中的 PKI 证书和要求。
默认情况下,kubeadm 会生成运行一个集群所需的全部证书。 你可以通过提供你自己的证书来改变这个行为策略。
如果要这样做,你必须将证书文件放置在通过 --cert-dir 命令行参数或者 kubeadm 配置中的
certificatesDir 配置项指明的目录中。默认的值是 /etc/kubernetes/pki。
如果在运行 kubeadm init 之前存在给定的证书和私钥对,kubeadm 将不会重写它们。
例如,这意味着你可以将现有的 CA 复制到 /etc/kubernetes/pki/ca.crt 和
/etc/kubernetes/pki/ca.key 中,而 kubeadm 将使用此 CA 对其余证书进行签名。
只提供了 ca.crt 文件但是不提供 ca.key 文件也是可以的
(这只对 CA 根证书可用,其它证书不可用)。
如果所有的其它证书和 kubeconfig 文件已就绪,kubeadm 检测到满足以上条件就会激活
"外部 CA" 模式。kubeadm 将会在没有 CA 密钥文件的情况下继续执行。
否则,kubeadm 将独立运行 controller-manager,附加一个
--controllers=csrsigner 的参数,并且指明 CA 证书和密钥。
PKI 证书和要求包括集群使用外部 CA 的设置指南。
你可以使用 check-expiration 子命令来检查证书何时过期
kubeadm certs check-expiration
输出类似于以下内容:
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 30, 2020 23:36 UTC 364d no
apiserver Dec 30, 2020 23:36 UTC 364d ca no
apiserver-etcd-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 30, 2020 23:36 UTC 364d ca no
controller-manager.conf Dec 30, 2020 23:36 UTC 364d no
etcd-healthcheck-client Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-peer Dec 30, 2020 23:36 UTC 364d etcd-ca no
etcd-server Dec 30, 2020 23:36 UTC 364d etcd-ca no
front-proxy-client Dec 30, 2020 23:36 UTC 364d front-proxy-ca no
scheduler.conf Dec 30, 2020 23:36 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 28, 2029 23:36 UTC 9y no
etcd-ca Dec 28, 2029 23:36 UTC 9y no
front-proxy-ca Dec 28, 2029 23:36 UTC 9y no
该命令显示 /etc/kubernetes/pki 文件夹中的客户端证书以及
kubeadm(admin.conf、controller-manager.conf 和 scheduler.conf)
使用的 kubeconfig 文件中嵌入的客户端证书的到期时间/剩余时间。
另外,kubeadm 会通知用户证书是否由外部管理; 在这种情况下,用户应该小心的手动/使用其他工具来管理证书更新。
kubeadm 不能管理由外部 CA 签名的证书。
上面的列表中没有包含 kubelet.conf,因为 kubeadm 将 kubelet
配置为自动更新证书。
轮换的证书位于目录 /var/lib/kubelet/pki。
要修复过期的 kubelet 客户端证书,请参阅
kubelet 客户端证书轮换失败。
在通过 kubeadm init 创建的节点上,在 kubeadm 1.17
版本之前有一个缺陷,
该缺陷使得你必须手动修改 kubelet.conf 文件的内容。
kubeadm init 操作结束之后,你必须更新 kubelet.conf 文件将 client-certificate-data
和 client-key-data 改为如下所示的内容以便使用轮换后的 kubelet 客户端证书:
client-certificate: /var/lib/kubelet/pki/kubelet-client-current.pem
client-key: /var/lib/kubelet/pki/kubelet-client-current.pem
kubeadm 会在控制面升级的时候更新所有证书。
这个功能旨在解决最简单的用例;如果你对此类证书的更新没有特殊要求, 并且定期执行 Kubernetes 版本升级(每次升级之间的间隔时间少于 1 年), 则 kubeadm 将确保你的集群保持最新状态并保持合理的安全性。
最佳的做法是经常升级集群以确保安全。
如果你对证书更新有更复杂的需求,则可通过将 --certificate-renewal=false 传递给
kubeadm upgrade apply 或者 kubeadm upgrade node,从而选择不采用默认行为。
kubeadm 在 1.17 版本之前有一个缺陷,
该缺陷导致 kubeadm update node 执行时 --certificate-renewal 的默认值被设置为 false。
在这种情况下,你需要显式地设置 --certificate-renewal=true。
你能随时通过 kubeadm certs renew 命令手动更新你的证书,只需带上合适的命令行选项。
此命令用 CA(或者 front-proxy-CA )证书和存储在 /etc/kubernetes/pki 中的密钥执行更新。
执行完此命令之后你需要重启控制面 Pod。因为动态证书重载目前还不被所有组件和证书支持,所有这项操作是必须的。
静态 Pod 是被本地 kubelet
而不是 API 服务器管理,所以 kubectl 不能用来删除或重启他们。
要重启静态 Pod 你可以临时将清单文件从 /etc/kubernetes/manifests/ 移除并等待 20 秒
(参考 KubeletConfiguration 结构中的
fileCheckFrequency 值)。如果 Pod 不在清单目录里,kubelet 将会终止它。
在另一个 fileCheckFrequency 周期之后你可以将文件移回去,kubelet 可以完成 Pod
的重建,而组件的证书更新操作也得以完成。
如果你运行了一个 HA 集群,这个命令需要在所有控制面板节点上执行。
certs renew 使用现有的证书作为属性(Common Name、Organization、SAN 等)的权威来源,
而不是 kubeadm-config ConfigMap。强烈建议使它们保持同步。
kubeadm certs renew 可以更新任何特定的证书,或者使用子命令 all
更新所有的证书,如下所示:
kubeadm certs renew all
使用 kubeadm 构建的集群通常会将 admin.conf 证书复制到 $HOME/.kube/config 中,
如使用 kubeadm 创建集群中所指示的那样。
在这样的系统中,为了在更新 admin.conf 后更新 $HOME/.kube/config 的内容,
你必须运行以下命令:
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
本节提供有关如何使用 Kubernetes 证书 API 执行手动证书更新的更多详细信息。
这些是针对需要将其组织的证书基础结构集成到 kubeadm 构建的集群中的用户的高级主题。 如果默认的 kubeadm 配置满足了你的需求,则应让 kubeadm 管理证书。
Kubernetes 证书颁发机构不是开箱即用。你可以配置外部签名者,例如 cert-manager, 也可以使用内置签名者。
内置签名者是
kube-controller-manager
的一部分。
要激活内置签名者,请传递 --cluster-signing-cert-file 和 --cluster-signing-key-file 参数。
如果你正在创建一个新的集群,你可以使用 kubeadm 的配置文件。
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
controllerManager:
extraArgs:
cluster-signing-cert-file: /etc/kubernetes/pki/ca.crt
cluster-signing-key-file: /etc/kubernetes/pki/ca.key
有关使用 Kubernetes API 创建 CSR 的信息, 请参见创建 CertificateSigningRequest。
本节提供有关如何使用外部 CA 执行手动更新证书的更多详细信息。
为了更好的与外部 CA 集成,kubeadm 还可以生成证书签名请求(CSR)。 CSR 表示向 CA 请求客户的签名证书。 在 kubeadm 术语中,通常由磁盘 CA 签名的任何证书都可以作为 CSR 生成。但是,CA 不能作为 CSR 生成。
你可以通过 kubeadm certs renew --csr-only 命令创建证书签名请求。
CSR 和随附的私钥都在输出中给出。
你可以传入一个带有 --csr-dir 的目录,将 CSR 输出到指定位置。
如果未指定 --csr-dir,则使用默认证书目录(/etc/kubernetes/pki)。
证书可以通过 kubeadm certs renew --csr-only 来续订。
和 kubeadm init 一样,可以使用 --csr-dir 标志指定一个输出目录。
CSR 中包含一个证书的名字,域和 IP,但是未指定用法。 颁发证书时,CA 有责任指定正确的证书用法
openssl 中,这是通过
openssl ca 命令
来完成的。cfssl 中,这是通过
在配置文件中指定用法
来完成的。使用首选方法对证书签名后,必须将证书和私钥复制到 PKI 目录(默认为 /etc/kubernetes/pki)。
kubeadm 并不直接支持对 CA 证书的轮换或者替换。
关于手动轮换或者置换 CA 的更多信息, 可参阅手动轮换 CA 证书。
默认情况下,kubeadm 所部署的 kubelet 服务证书是自签名(Self-Signed)。 这意味着从 metrics-server 这类外部服务发起向 kubelet 的链接时无法使用 TLS 来完成保护。
要在新的 kubeadm 集群中配置 kubelet 以使用被正确签名的服务证书,
你必须向 kubeadm init 传递如下最小配置数据:
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
serverTLSBootstrap: true
如果你已经创建了集群,你必须通过执行下面的操作来完成适配:
kube-system 名字空间中名为 kubelet-config-1.29
的 ConfigMap 并编辑之。
在该 ConfigMap 中,kubelet 键下面有一个
KubeletConfiguration
文档作为其取值。编辑该 KubeletConfiguration 文档以设置
serverTLSBootstrap: true。/var/lib/kubelet/config.yaml 文件中添加
serverTLSBootstrap: true 字段,并使用 systemctl restart kubelet
来重启 kubelet。字段 serverTLSBootstrap 将允许启动引导 kubelet 的服务证书,方式是从
certificates.k8s.io API 处读取。这种方式的一种局限在于这些证书的
CSR(证书签名请求)不能被 kube-controller-manager 中默认的签名组件
kubernetes.io/kubelet-serving
批准。需要用户或者第三方控制器来执行此操作。
可以使用下面的命令来查看 CSR:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-9wvgt 112s kubernetes.io/kubelet-serving system:node:worker-1 Pending
csr-lz97v 1m58s kubernetes.io/kubelet-serving system:node:control-plane-1 Pending
你可以执行下面的操作来批准这些请求:
kubectl certificate approve <CSR-名称>
默认情况下,这些服务证书会在一年后过期。
kubeadm 将 KubeletConfiguration 的 rotateCertificates 字段设置为
true;这意味着证书快要过期时,会生成一组针对服务证书的新的 CSR,而这些
CSR 也要被批准才能完成证书轮换。要进一步了解这里的细节,
可参阅证书轮换文档。
如果你在寻找一种能够自动批准这些 CSR 的解决方案,建议你与你的云提供商 联系,询问他们是否有 CSR 签名组件,用来以带外(out-of-band)的方式检查 节点的标识符。
也可以使用第三方定制的控制器:
除非既能够验证 CSR 中的 CommonName,也能检查请求的 IP 和域名, 这类控制器还算不得安全的机制。 只有完成彻底的检查,才有可能避免有恶意的、能够访问 kubelet 客户端证书的第三方为任何 IP 或域名请求服务证书。
在集群创建过程中,kubeadm 对 admin.conf 中的证书进行签名时,将其配置为
Subject: O = system:masters, CN = kubernetes-admin。
system:masters
是一个例外的超级用户组,可以绕过鉴权层(例如 RBAC)。
强烈建议不要将 admin.conf 文件与任何人共享。
你要使用 kubeadm kubeconfig user
命令为其他用户生成 kubeconfig 文件,这个命令支持命令行参数和
kubeadm 配置结构。
以上命令会将 kubeconfig 打印到终端上,也可以使用 kubeadm kubeconfig user ... > somefile.conf
输出到一个文件中。
如下 kubeadm 可以在 --config 后加的配置文件示例:
# example.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
# kubernetes 将作为 kubeconfig 中集群名称
clusterName: "kubernetes"
# some-dns-address:6443 将作为集群 kubeconfig 文件中服务地址(IP 或者 DNS 名称)
controlPlaneEndpoint: "some-dns-address:6443"
# 从本地挂载集群的 CA 秘钥和 CA 证书
certificatesDir: "/etc/kubernetes/pki"
确保这些设置与所需的目标集群设置相匹配。可以使用以下命令查看现有集群的设置:
kubectl get cm kubeadm-config -n kube-system -o=jsonpath="{.data.ClusterConfiguration}"
以下示例将为在 appdevs 组的 johndoe 用户创建一个有效期为 24 小时的 kubeconfig 文件:
kubeadm kubeconfig user --config example.yaml --org appdevs --client-name johndoe --validity-period 24h
以下示例将为管理员创建一个有效期有一周的 kubeconfig 文件:
kubeadm kubeconfig user --config example.yaml --client-name admin --validity-period 168h
本页阐述如何配置 kubelet 的 cgroup 驱动以匹配 kubeadm 集群中的容器运行时的 cgroup 驱动。
你应该熟悉 Kubernetes 的容器运行时需求。
容器运行时页面提到,
由于 kubeadm 把 kubelet 视为一个
系统服务来管理,
所以对基于 kubeadm 的安装, 我们推荐使用 systemd 驱动,
不推荐 kubelet 默认的 cgroupfs 驱动。
此页还详述了如何安装若干不同的容器运行时,并将 systemd 设为其默认驱动。
kubeadm 支持在执行 kubeadm init 时,传递一个 KubeletConfiguration 结构体。
KubeletConfiguration 包含 cgroupDriver 字段,可用于控制 kubelet 的 cgroup 驱动。
在版本 1.22 及更高版本中,如果用户没有在 KubeletConfiguration 中设置 cgroupDriver 字段,
kubeadm 会将它设置为默认值 systemd。
在 Kubernetes v1.28 中,你可以以 Alpha 功能启用 cgroup 驱动的自动检测。 有关更多详情,请查看 systemd cgroup 驱动。
这是一个最小化的示例,其中显式的配置了此字段:
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
这样一个配置文件就可以传递给 kubeadm 命令了:
kubeadm init --config kubeadm-config.yaml
Kubeadm 对集群所有的节点,使用相同的 KubeletConfiguration。
KubeletConfiguration 存放于 kube-system 命名空间下的某个
ConfigMap 对象中。
执行 init、join 和 upgrade 等子命令会促使 kubeadm
将 KubeletConfiguration 写入到文件 /var/lib/kubelet/config.yaml 中,
继而把它传递给本地节点的 kubelet。
cgroupfs 驱动如仍需使用 cgroupfs 且要防止 kubeadm upgrade 修改现有系统中
KubeletConfiguration 的 cgroup 驱动,你必须显式声明它的值。
此方法应对的场景为:在将来某个版本的 kubeadm 中,你不想使用默认的 systemd 驱动。
参阅以下章节“修改 kubelet 的 ConfigMap ”,了解显式设置该值的方法。
如果你希望配置容器运行时来使用 cgroupfs 驱动,
则必须参考所选容器运行时的文档。
systemd 驱动要将现有 kubeadm 集群的 cgroup 驱动从 cgroupfs 就地升级为 systemd,
需要执行一个与 kubelet 升级类似的过程。
该过程必须包含下面两个步骤:
systemd 的新节点替换掉集群中的老节点。
按这种方法,在加入新节点、确保工作负载可以安全迁移到新节点、及至删除旧节点这一系列操作之前,
只需执行以下第一个步骤。
运行 kubectl edit cm kubelet-config -n kube-system。
修改现有 cgroupDriver 的值,或者新增如下式样的字段:
cgroupDriver: systemd
该字段必须出现在 ConfigMap 的 kubelet: 小节下。
对于集群中的每一个节点:
kubectl drain <node-name> --ignore-daemonsets,以
腾空节点systemctl stop kubelet,以停止 kubeletsystemd/var/lib/kubelet/config.yaml 中添加设置 cgroupDriver: systemdsystemctl start kubelet,以启动 kubeletkubectl uncordon <node-name>,以
取消节点隔离在节点上依次执行上述步骤,确保工作负载有充足的时间被调度到其他节点。
流程完成后,确认所有节点和工作负载均健康如常。
kubeadm 不支持自动重新配置部署在托管节点上的组件的方式。 一种自动化的方法是使用自定义的 operator。
要修改组件配置,你必须手动编辑磁盘上关联的集群对象和文件。 本指南展示了实现 kubeadm 集群重新配置所需执行的正确步骤顺序。
/etc/kubernetes/admin.conf)
和从安装了 kubectl 的主机到集群中正在运行的 kube-apiserver 的网络连接kubeadm 在 ConfigMap 和其他对象中写入了一组集群范围的组件配置选项。
这些对象必须手动编辑,可以使用命令 kubectl edit。
kubectl edit 命令将打开一个文本编辑器,你可以在其中直接编辑和保存对象。
你可以使用环境变量 KUBECONFIG 和 KUBE_EDITOR 来指定 kubectl
使用的 kubeconfig 文件和首选文本编辑器的位置。
例如:
KUBECONFIG=/etc/kubernetes/admin.conf KUBE_EDITOR=nano kubectl edit <parameters>
保存对这些集群对象的任何更改后,节点上运行的组件可能不会自动更新。 以下步骤将指导你如何手动执行该操作。
ConfigMaps 中的组件配置存储为非结构化数据(YAML 字符串)。 这意味着在更新 ConfigMap 的内容时不会执行验证。 你必须小心遵循特定组件配置的文档化 API 格式, 并避免引入拼写错误和 YAML 缩进错误。
ClusterConfiguration在集群创建和升级期间,kubeadm 将其
ClusterConfiguration
写入 kube-system 命名空间中名为 kubeadm-config 的 ConfigMap。
要更改 ClusterConfiguration 中的特定选项,你可以使用以下命令编辑 ConfigMap:
kubectl edit cm -n kube-system kubeadm-config
配置位于 data.ClusterConfiguration 键下。
ClusterConfiguration 包括各种影响单个组件配置的选项, 例如
kube-apiserver、kube-scheduler、kube-controller-manager、
CoreDNS、etcd 和 kube-proxy。 对配置的更改必须手动反映在节点组件上。
ClusterConfiguration 更改kubeadm 将控制平面组件作为位于 /etc/kubernetes/manifests
目录中的静态 Pod 清单进行管理。
对 apiServer、controllerManager、scheduler 或 etcd键下的
ClusterConfiguration 的任何更改都必须反映在控制平面节点上清单目录中的关联文件中。
此类更改可能包括:
extraArgs - 需要更新传递给组件容器的标志列表extraMounts - 需要更新组件容器的卷挂载*SANs - 需要使用更新的主题备用名称编写新证书在继续进行这些更改之前,请确保你已备份目录 /etc/kubernetes/。
要编写新证书,你可以使用:
kubeadm init phase certs <component-name> --config <config-file>
要在 /etc/kubernetes/manifests 中编写新的清单文件,你可以使用以下命令:
# Kubernetes 控制平面组件
kubeadm init phase control-plane <component-name> --config <config-file>
# 本地 etcd
kubeadm init phase etcd local --config <config-file>
<config-file> 内容必须与更新后的 ClusterConfiguration 匹配。
<component-name> 值必须是一个控制平面组件(apiserver、controller-manager 或 scheduler)的名称。
更新 /etc/kubernetes/manifests 中的文件将告诉 kubelet 重新启动相应组件的静态 Pod。
尝试一次对一个节点进行这些更改,以在不停机的情况下离开集群。
KubeletConfiguration在集群创建和升级期间,kubeadm 将其
KubeletConfiguration
写入 kube-system 命名空间中名为 kubelet-config 的 ConfigMap。
你可以使用以下命令编辑 ConfigMap:
kubectl edit cm -n kube-system kubelet-config
配置位于 data.kubelet 键下。
要反映 kubeadm 节点上的更改,你必须执行以下操作:
kubeadm upgrade node phase kubelet-config 下载最新的
kubelet-config ConfigMap 内容到本地文件 /var/lib/kubelet/config.yaml/var/lib/kubelet/kubeadm-flags.env 以使用标志来应用额外的配置systemctl restart kubelet 重启 kubelet 服务一次执行一个节点的这些更改,以允许正确地重新安排工作负载。
在 kubeadm upgrade 期间,kubeadm 从 kubelet-config ConfigMap
下载 KubeletConfiguration 并覆盖 /var/lib/kubelet/config.yaml 的内容。
这意味着节点本地配置必须通过/var/lib/kubelet/kubeadm-flags.env中的标志或在
kubeadm upgrade后手动更新/var/lib/kubelet/config.yaml` 的内容来应用,
然后重新启动 kubelet。
KubeProxyConfiguration在集群创建和升级期间,kubeadm 将其写入
KubeProxyConfiguration
在名为 kube-proxy 的 kube-system 命名空间中的 ConfigMap 中。
此 ConfigMap 由 kube-system 命名空间中的 kube-proxy DaemonSet 使用。
要更改 KubeProxyConfiguration 中的特定选项,你可以使用以下命令编辑 ConfigMap:
kubectl edit cm -n kube-system kube-proxy
配置位于 data.config.conf 键下。
更新 kube-proxy ConfigMap 后,你可以重新启动所有 kube-proxy Pod:
获取 Pod 名称:
kubectl get po -n kube-system | grep kube-proxy
使用以下命令删除 Pod:
kubectl delete po -n kube-system <pod-name>
将创建使用更新的 ConfigMap 的新 Pod。
由于 kubeadm 将 kube-proxy 部署为 DaemonSet,因此不支持特定于节点的配置。
kubeadm 将 CoreDNS 部署为名为 coredns 的 Deployment,并使用 Service kube-dns,
两者都在 kube-system 命名空间中。
要更新任何 CoreDNS 设置,你可以编辑 Deployment 和 Service:
kubectl edit deployment -n kube-system coredns
kubectl edit service -n kube-system kube-dns
应用 CoreDNS 更改后,你可以删除 CoreDNS Pod。
获取 Pod 名称:
kubectl get po -n kube-system | grep coredns
使用以下命令删除 Pod:
kubectl delete po -n kube-system <pod-name>
将创建具有更新的 CoreDNS 配置的新 Pod。
kubeadm 不允许在集群创建和升级期间配置 CoreDNS。
这意味着如果执行了 kubeadm upgrade apply,你对
CoreDNS 对象的更改将丢失并且必须重新应用。
在受管节点上执行 kubeadm upgrade 期间,kubeadm
可能会覆盖在创建集群(重新配置)后应用的配置。
kubeadm 在特定 Kubernetes 节点的 Node 对象上写入标签、污点、CRI 套接字和其他信息。要更改此 Node 对象的任何内容,你可以使用:
kubectl edit no <node-name>
在 kubeadm upgrade 期间,此类节点的内容可能会被覆盖。
如果你想在升级后保留对 Node 对象的修改,你可以准备一个
kubectl patch
并将其应用到 Node 对象:
kubectl patch no <node-name> --patch-file <patch-file>
控制平面配置的主要来源是存储在集群中的 ClusterConfiguration 对象。
要扩展静态 Pod 清单配置,可以使用
patches。
这些补丁文件必须作为文件保留在控制平面节点上,以确保它们可以被
kubeadm upgrade ... --patches <directory> 使用。
如果对 ClusterConfiguration 和磁盘上的静态 Pod 清单进行了重新配置,则必须相应地更新节点特定补丁集。
对存储在 /var/lib/kubelet/config.yaml 中的 KubeletConfiguration
所做的任何更改都将在 kubeadm upgrade 时因为下载集群范围内的 kubelet-config
ConfigMap 的内容而被覆盖。
要持久保存 kubelet 节点特定的配置,文件 /var/lib/kubelet/config.yaml
必须在升级后手动更新,或者文件 /var/lib/kubelet/kubeadm-flags.env 可以包含标志。
kubelet 标志会覆盖相关的 KubeletConfiguration 选项,但请注意,有些标志已被弃用。
更改 /var/lib/kubelet/config.yaml 或 /var/lib/kubelet/kubeadm-flags.env
后需要重启 kubelet。
本页介绍如何将 kubeadm 创建的 Kubernetes 集群从 1.28.x 版本
升级到 1.29.x 版本以及从 1.29.x
升级到 1.29.y(其中 y > x)。略过次版本号的升级是
不被支持的。更多详情请访问版本偏差策略。
要查看 kubeadm 创建的有关旧版本集群升级的信息,请参考以下页面:
升级工作的基本流程如下:
kubeadm upgrade 不会影响你的工作负载,只会涉及 Kubernetes 内部的组件,但备份终究是好的。systemctl status kubelet
或 journalctl -xeu kubelet 查看服务日志。kubeadm upgrade 的 --config 参数和
kubeadm 配置 API 类型来重新配置集群,
这样会产生意想不到的结果。
请按照重新配置 kubeadm 集群中的步骤来进行。由于 kube-apiserver 静态 Pod 始终在运行(即使你已经执行了腾空节点的操作),
因此当你执行包括 etcd 升级在内的 kubeadm 升级时,对服务器正在进行的请求将停滞,
因为要重新启动新的 etcd 静态 Pod。作为一种解决方法,可以在运行 kubeadm upgrade apply
命令之前主动停止 kube-apiserver 进程几秒钟。这样可以允许正在进行的请求完成处理并关闭现有连接,
并最大限度地减少 etcd 停机的后果。此操作可以在控制平面节点上按如下方式完成:
killall -s SIGTERM kube-apiserver # 触发 kube-apiserver 体面关闭
sleep 20 # 等待一下,以完成进行中的请求
kubeadm upgrade ... # 执行 kubeadm 升级命令
如果你正在使用社区版的软件包仓库(pkgs.k8s.io),
你需要启用所需的 Kubernetes 小版本的软件包仓库。
这一点在更改 Kubernetes 软件包仓库文档中有详细说明。
apt.kubernetes.io and yum.kubernetes.io) have been
deprecated and frozen starting from September 13, 2023.
Using the new package repositories hosted at pkgs.k8s.io
is strongly recommended and required in order to install Kubernetes versions released after September 13, 2023.
The deprecated legacy repositories, and their contents, might be removed at any time in the future and without
a further notice period. The new package repositories provide downloads for Kubernetes versions starting with v1.24.0.
使用操作系统的包管理器找到最新的补丁版本 Kubernetes 1.29:
# 在列表中查找最新的 1.29 版本
# 它看起来应该是 1.29.x-*,其中 x 是最新的补丁版本
sudo apt update
sudo apt-cache madison kubeadm
# 在列表中查找最新的 1.29 版本
# 它看起来应该是 1.29.x-*,其中 x 是最新的补丁版本
sudo yum list --showduplicates kubeadm --disableexcludes=kubernetes
控制面节点上的升级过程应该每次处理一个节点。
首先选择一个要先行升级的控制面节点。该节点上必须拥有
/etc/kubernetes/admin.conf 文件。
对于第一个控制面节点
升级 kubeadm:
# 用最新的补丁版本号替换 1.29.x-* 中的 x
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm='1.29.x-*' && \
sudo apt-mark hold kubeadm
# 用最新的补丁版本号替换 1.29.x-* 中的 x
sudo yum install -y kubeadm-'1.29.x-*' --disableexcludes=kubernetes
验证下载操作正常,并且 kubeadm 版本正确:
kubeadm version
验证升级计划:
sudo kubeadm upgrade plan
此命令检查你的集群是否可被升级,并取回你要升级的目标版本。 命令也会显示一个包含组件配置版本状态的表格。
kubeadm upgrade 也会自动对 kubeadm 在节点上所管理的证书执行续约操作。
如果需要略过证书续约操作,可以使用标志 --certificate-renewal=false。
更多的信息,可参阅证书管理指南。
如果 kubeadm upgrade plan 给出任何需要手动升级的组件配置,
用户必须通过 --config 命令行标志向 kubeadm upgrade apply 命令提供替代的配置文件。
如果不这样做,kubeadm upgrade apply 会出错并退出,不再执行升级操作。
选择要升级到的目标版本,运行合适的命令。例如:
# 将 x 替换为你为此次升级所选择的补丁版本号
sudo kubeadm upgrade apply v1.29.x
一旦该命令结束,你应该会看到:
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.29.x". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
对于 v1.28 之前的版本,kubeadm 默认采用这样一种模式:在 kubeadm upgrade apply
期间立即升级插件(包括 CoreDNS 和 kube-proxy),而不管是否还有其他尚未升级的控制平面实例。
这可能会导致兼容性问题。从 v1.28 开始,kubeadm 默认采用这样一种模式:
在开始升级插件之前,先检查是否已经升级所有的控制平面实例。
你必须按顺序执行控制平面实例的升级,或者至少确保在所有其他控制平面实例已完成升级之前不启动最后一个控制平面实例的升级,
并且在最后一个控制平面实例完成升级之后才执行插件的升级。如果你要保留旧的升级行为,可以通过
kubeadm upgrade apply --feature-gates=UpgradeAddonsBeforeControlPlane=true 启用
UpgradeAddonsBeforeControlPlane 特性门控。Kubernetes 项目通常不建议启用此特性门控,
你应该转为更改你的升级过程或集群插件,这样你就不需要启用旧的行为。
UpgradeAddonsBeforeControlPlane 特性门控将在后续的版本中被移除。
手动升级你的 CNI 驱动插件。
你的容器网络接口(CNI)驱动应该提供了程序自身的升级说明。 参阅插件页面查找你的 CNI 驱动, 并查看是否需要其他升级步骤。
如果 CNI 驱动作为 DaemonSet 运行,则在其他控制平面节点上不需要此步骤。
对于其它控制面节点
与第一个控制面节点相同,但是使用:
sudo kubeadm upgrade node
而不是:
sudo kubeadm upgrade apply
此外,不需要执行 kubeadm upgrade plan 和更新 CNI 驱动插件的操作。
将节点标记为不可调度并驱逐所有负载,准备节点的维护:
# 将 <node-to-drain> 替换为你要腾空的控制面节点名称
kubectl drain <node-to-drain> --ignore-daemonsets
升级 kubelet 和 kubectl:
# 用最新的补丁版本替换 1.29.x-* 中的 x
sudo apt-mark unhold kubelet kubectl && \
sudo apt-get update && sudo apt-get install -y kubelet='1.29.x-*' kubectl='1.29.x-*' && \
sudo apt-mark hold kubelet kubectl
# 用最新的补丁版本号替换 1.29.x-* 中的 x
sudo yum install -y kubelet-'1.29.x-*' kubectl-'1.29.x-*' --disableexcludes=kubernetes
重启 kubelet:
sudo systemctl daemon-reload
sudo systemctl restart kubelet
通过将节点标记为可调度,让其重新上线:
# 将 <node-to-uncordon> 替换为你的节点名称
kubectl uncordon <node-to-uncordon>
工作节点上的升级过程应该一次执行一个节点,或者一次执行几个节点, 以不影响运行工作负载所需的最小容量。
以下内容演示如何升级 Linux 和 Windows 工作节点:
在所有节点上升级 kubelet 后,通过从 kubectl 可以访问集群的任何位置运行以下命令, 验证所有节点是否再次可用:
kubectl get nodes
STATUS 应显示所有节点为 Ready 状态,并且版本号已经被更新。
如果 kubeadm upgrade 失败并且没有回滚,例如由于执行期间节点意外关闭,
你可以再次运行 kubeadm upgrade。
此命令是幂等的,并最终确保实际状态是你声明的期望状态。
要从故障状态恢复,你还可以运行 sudo kubeadm upgrade apply --force 而无需更改集群正在运行的版本。
在升级期间,kubeadm 向 /etc/kubernetes/tmp 目录下的如下备份文件夹写入数据:
kubeadm-backup-etcd-<date>-<time>kubeadm-backup-manifests-<date>-<time>kubeadm-backup-etcd 包含当前控制面节点本地 etcd 成员数据的备份。
如果 etcd 升级失败并且自动回滚也无法修复,则可以将此文件夹中的内容复制到
/var/lib/etcd 进行手工修复。如果使用的是外部的 etcd,则此备份文件夹为空。
kubeadm-backup-manifests 包含当前控制面节点的静态 Pod 清单文件的备份版本。
如果升级失败并且无法自动回滚,则此文件夹中的内容可以复制到
/etc/kubernetes/manifests 目录实现手工恢复。
如果由于某些原因,在升级前后某个组件的清单未发生变化,则 kubeadm 也不会为之生成备份版本。
kubeadm upgrade apply 做了以下工作:
Ready 状态CoreDNS 和 kube-proxy 清单,并强制创建所有必需的 RBAC 规则。kubeadm upgrade node 在其他控制平节点上执行以下操作:
ClusterConfiguration。kubeadm upgrade node 在工作节点上完成以下工作:
ClusterConfiguration。本页讲述了如何升级用 kubeadm 创建的 Linux 工作节点。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
如果你正在使用社区自治的软件包仓库(pkgs.k8s.io),
你需要启用所需的 Kubernetes 小版本的软件包仓库。
这一点在更改 Kubernetes 软件包仓库文档中有详细说明。
apt.kubernetes.io and yum.kubernetes.io) have been
deprecated and frozen starting from September 13, 2023.
Using the new package repositories hosted at pkgs.k8s.io
is strongly recommended and required in order to install Kubernetes versions released after September 13, 2023.
The deprecated legacy repositories, and their contents, might be removed at any time in the future and without
a further notice period. The new package repositories provide downloads for Kubernetes versions starting with v1.24.0.
升级 kubeadm:
# 将 1.29.x-* 中的 x 替换为最新的补丁版本
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm='1.29.x-*' && \
sudo apt-mark hold kubeadm
# 将 1.29.x-* 中的 x 替换为最新的补丁版本
sudo yum install -y kubeadm-'1.29.x-*' --disableexcludes=kubernetes
对于工作节点,下面的命令会升级本地的 kubelet 配置:
sudo kubeadm upgrade node
将节点标记为不可调度并驱逐所有负载,准备节点的维护:
# 在控制平面节点上执行此命令
# 将 <node-to-drain> 替换为你正腾空的节点的名称
kubectl drain <node-to-drain> --ignore-daemonsets
升级 kubelet 和 kubectl:
# 将 1.29.x-* 中的 x 替换为最新的补丁版本
sudo apt-mark unhold kubelet kubectl && \
sudo apt-get update && sudo apt-get install -y kubelet='1.29.x-*' kubectl='1.29.x-*' && \
sudo apt-mark hold kubelet kubectl
# 将 1.29.x-* 中的 x 替换为最新的补丁版本
sudo yum install -y kubelet-'1.29.x-*' kubectl-'1.29.x-*' --disableexcludes=kubernetes
重启 kubelet:
sudo systemctl daemon-reload
sudo systemctl restart kubelet
通过将节点标记为可调度,让节点重新上线:
# 在控制平面节点上执行此命令
# 将 <node-to-uncordon> 替换为你的节点名称
kubectl uncordon <node-to-uncordon>
Kubernetes v1.18 [beta]
本页解释如何升级用 kubeadm 创建的 Windows 节点。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.17. 要获知版本信息,请输入kubectl version.
在 Windows 节点上升级 kubeadm:
# 将 1.29.2 替换为你希望的版本
curl.exe -Lo <kubeadm.exe 路径> "https://dl.k8s.io/v1.29.2/bin/windows/amd64/kubeadm.exe"
在一个能访问到 Kubernetes API 的机器上,将 Windows 节点标记为不可调度并 驱逐其上的所有负载,以便准备节点维护操作:
# 将 <要腾空的节点> 替换为你要腾空的节点的名称
kubectl drain <要腾空的节点> --ignore-daemonsets
你应该会看到类似下面的输出:
node/ip-172-31-85-18 cordoned
node/ip-172-31-85-18 drained
在 Windows 节点上,执行下面的命令来同步新的 kubelet 配置:
kubeadm upgrade node
在 Windows 节点上升级并重启 kubelet:
stop-service kubelet
curl.exe -Lo <kubelet.exe 路径> "https://dl.k8s.io/v1.29.2/bin/windows/amd64/kubelet.exe"
restart-service kubelet
在 Windows 节点上升级并重启 kube-proxy:
stop-service kube-proxy
curl.exe -Lo <kube-proxy.exe 路径> "https://dl.k8s.io/v1.29.2/bin/windows/amd64/kube-proxy.exe"
restart-service kube-proxy
如果你是在 Pod 内的 HostProcess 容器中运行 kube-proxy,而不是作为 Windows 服务, 你可以通过应用更新版本的 kube-proxy 清单文件来升级 kube-proxy。
从一台能够访问到 Kubernetes API 的机器上,通过将节点标记为可调度,使之 重新上线:
# 将 <要腾空的节点> 替换为你的节点名称
kubectl uncordon <要腾空的节点>
本页介绍了如何在升级集群时启用包含 Kubernetes 次要版本的软件包仓库。
这仅适用于使用托管在 pkgs.k8s.io 上社区自治软件包仓库的用户。
启用新的 Kubernetes 小版本的软件包仓库。与传统的软件包仓库不同,
社区自治的软件包仓库所采用的结构为每个 Kubernetes 小版本都有一个专门的软件包仓库。
本指南仅介绍 Kubernetes 升级过程的一部分。 有关升级 Kubernetes 集群的更多信息, 请参阅升级指南。
仅在将集群升级到另一个次要版本时才需要执行此步骤。 如果你要升级到同一次要版本中的另一个补丁版本(例如:v1.29.5 到 v1.29.7)则不需要遵循本指南。 但是,如果你仍在使用旧的软件包仓库,则需要在升级之前迁移到社区自治的新软件包仓库 (有关如何执行此操作的更多详细信息,请参阅下一节)。
本文假设你已经在使用社区自治的软件包仓库(pkgs.k8s.io)。如果不是这种情况,
强烈建议按照官方公告中所述,
迁移到社区自治的软件包仓库。
apt.kubernetes.io and yum.kubernetes.io) have been
deprecated and frozen starting from September 13, 2023.
Using the new package repositories hosted at pkgs.k8s.io
is strongly recommended and required in order to install Kubernetes versions released after September 13, 2023.
The deprecated legacy repositories, and their contents, might be removed at any time in the future and without
a further notice period. The new package repositories provide downloads for Kubernetes versions starting with v1.24.0.
如果你不确定自己是在使用社区自治的软件包仓库还是在使用老旧的软件包仓库, 可以执行以下步骤进行验证:
打印定义 Kubernetes apt 仓库的文件的内容:
# 在你的系统上,此配置文件可能具有不同的名称
pager /etc/apt/sources.list.d/kubernetes.list
如果你看到类似以下的一行:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /
你正在使用 Kubernetes 软件包仓库,本指南适用于你。 否则,强烈建议按照官方公告中所述, 迁移到 Kubernetes 软件包仓库。
打印定义 Kubernetes yum 仓库的文件的内容:
# 在你的系统上,此配置文件可能具有不同的名称
cat /etc/yum.repos.d/kubernetes.repo
如果你看到的 baseurl 类似以下输出中的 baseurl:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl
你正在使用 Kubernetes 软件包仓库,本指南适用于你。 否则,强烈建议按照官方公告中所述, 迁移到 Kubernetes 软件包仓库。
打印定义 Kubernetes zypper 仓库的文件的内容:
# 在你的系统上,此配置文件可能具有不同的名称
cat /etc/zypp/repos.d/kubernetes.repo
如果你看到的 baseurl 类似以下输出中的 baseurl:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl
你正在使用 Kubernetes 软件包仓库,本指南适用于你。 否则,强烈建议按照官方公告中所述, 迁移到 Kubernetes 软件包仓库。
Kubernetes 软件包仓库所用的 URL 不仅限于 pkgs.k8s.io,还可以是以下之一:
pkgs.k8s.iopkgs.kubernetes.iopackages.kubernetes.io在从一个 Kubernetes 小版本升级到另一个版本时,应执行此步骤以获取所需 Kubernetes 小版本的软件包访问权限。
使用你所选择的文本编辑器打开定义 Kubernetes apt 仓库的文件:
nano /etc/apt/sources.list.d/kubernetes.list
你应该看到一行包含当前 Kubernetes 小版本的 URL。 例如,如果你正在使用 v1.28,你应该看到类似以下的输出:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /
将 URL 中的版本更改为下一个可用的小版本,例如:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /
使用你所选择的文本编辑器打开定义 Kubernetes yum 仓库的文件:
nano /etc/yum.repos.d/kubernetes.repo
你应该看到一个文件包含当前 Kubernetes 小版本的两个 URL。 例如,如果你正在使用 v1.28,你应该看到类似以下的输出:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.28/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
将这些 URL 中的版本更改为下一个可用的小版本,例如:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
本节提供从 dockershim 迁移到其他容器运行时的必备知识。
自从 Kubernetes 1.20 宣布 弃用 dockershim, 各类疑问随之而来:这对各类工作负载和 Kubernetes 部署会产生什么影响。 我们的弃用 Dockershim 常见问题可以帮助你更好地理解这个问题。
Dockershim 在 Kubernetes v1.24 版本已经被移除。 如果你集群内是通过 dockershim 使用 Docker Engine 作为容器运行时,并希望 Kubernetes 升级到 v1.24, 建议你迁移到其他容器运行时或使用其他方法以获得 Docker 引擎支持。
请参阅容器运行时 一节以了解可用的备选项。
带 dockershim 的 Kubernetes 版本 (1.23) 已不再支持, v1.24 很快也将不再支持。
当在迁移过程中遇到麻烦,请上报问题。 那么问题就可以及时修复,你的集群也可以进入移除 dockershim 前的就绪状态。 在 v1.24 支持结束后,如果出现影响集群的严重问题, 你需要联系你的 Kubernetes 供应商以获得支持或一次升级多个版本。
你的集群中可以有不止一种类型的节点,尽管这不是常见的情况。
下面这些任务可以帮助你完成迁移:
本任务给出将容器运行时从 Docker 改为 containerd 所需的步骤。 此任务适用于运行 1.23 或更早版本 Kubernetes 的集群操作人员。 同时,此任务也涉及从 dockershim 迁移到 containerd 的示例场景。 有关其他备选的容器运行时,可查阅 此页面进行拣选。
安装 containerd。进一步的信息可参见 containerd 的安装文档。 关于一些特定的环境准备工作,请遵循 containerd 指南。
kubectl drain <node-to-drain> --ignore-daemonsets
将 <node-to-drain> 替换为你所要腾空的节点的名称。
systemctl stop kubelet
systemctl disable docker.service --now
遵循此指南 了解安装 containerd 的详细步骤。
containerd.io 包。关于为你所使用的 Linux 发行版来设置
Docker 仓库,以及安装 containerd.io 包的详细说明,
可参见开始使用 containerd。配置 containerd:
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
重启 containerd:
sudo systemctl restart containerd
启动一个 Powershell 会话,将 $Version 设置为期望的版本(例如:$Version="1.4.3"),
之后运行下面的命令:
下载 containerd:
curl.exe -L https://github.com/containerd/containerd/releases/download/v$Version/containerd-$Version-windows-amd64.tar.gz -o containerd-windows-amd64.tar.gz
tar.exe xvf .\containerd-windows-amd64.tar.gz
解压缩并执行配置:
Copy-Item -Path ".\bin\" -Destination "$Env:ProgramFiles\containerd" -Recurse -Force
cd $Env:ProgramFiles\containerd\
.\containerd.exe config default | Out-File config.toml -Encoding ascii
# 请审查配置信息。取决于你的安装环境,你可能需要调整:
# - sandbox_image (Kubernetes pause 镜像)
# - CNI 的 bin_dir 和 conf_dir 的位置
Get-Content config.toml
# (可选步骤,但强烈建议执行)将 containerd 排除在 Windows Defender 扫描之外
Add-MpPreference -ExclusionProcess "$Env:ProgramFiles\containerd\containerd.exe"
启动 containerd:
.\containerd.exe --register-service
Start-Service containerd
编辑文件 /var/lib/kubelet/kubeadm-flags.env,将 containerd 运行时添加到标志中;
--container-runtime-endpoint=unix:///run/containerd/containerd.sock。
使用 kubeadm 的用户应该知道,kubeadm 工具将每个主机的 CRI 套接字保存在该主机对应的
Node 对象的注解中。
要更改这一注解信息,你可以在一台包含 kubeadm /etc/kubernetes/admin.conf 文件的机器上执行以下命令:
kubectl edit no <node-name>
这一命令会打开一个文本编辑器,供你在其中编辑 Node 对象。
要选择不同的文本编辑器,你可以设置 KUBE_EDITOR 环境变量。
更改 kubeadm.alpha.kubernetes.io/cri-socket 值,将其从
/var/run/dockershim.sock 改为你所选择的 CRI 套接字路径
(例如:unix:///run/containerd/containerd.sock)。
注意新的 CRI 套接字路径必须带有 unix:// 前缀。
保存文本编辑器中所作的修改,这会更新 Node 对象。
systemctl start kubelet
运行 kubectl get nodes -o wide,containerd 会显示为我们所更改的节点上的运行时。
如果节点显示正常,删除 Docker。
sudo yum remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
sudo dnf remove docker-ce docker-ce-cli
sudo apt-get purge docker-ce docker-ce-cli
上面的命令不会移除你的主机上的镜像、容器、卷或者定制的配置文件。 要删除这些内容,参阅 Docker 的指令来卸载 Docker Engine。
Docker 所提供的卸载 Docker Engine 命令指导中,存在删除 containerd 的风险。 在执行命令时要谨慎。
kubectl uncordon <node-to-uncordon>
将 <node-to-uncordon> 替换为你之前腾空的节点的名称。
本页面为你展示如何迁移你的 Docker Engine 节点,使之使用 cri-dockerd 而不是 dockershim。
在以下场景中,你可以遵从这里的步骤执行操作:
cri-dockerd 是你的一种选项。要进一步了解 dockershim 的移除,请阅读 FAQ 页面。
在 Kubernetes v1.24 及更早版本中,你可以在 Kubernetes 中使用 Docker Engine,
依赖于一个称作 dockershim 的内置 Kubernetes 组件。
dockershim 组件在 Kubernetes v1.24 发行版本中已被移除;不过,一种来自第三方的替代品,
cri-dockerd 是可供使用的。cri-dockerd 适配器允许你通过
容器运行时接口(Container Runtime Interface,CRI)
来使用 Docker Engine。
如果你已经在使用 cri-dockerd,那么你不会被 dockershim 的移除影响到。
在开始之前,检查你的节点是否在使用 dockershim。
如果你想要迁移到 cri-dockerd 以便继续使用 Docker Engine 作为你的容器运行时,
你需要在所有被影响的节点上执行以下操作:
cri-dockerd;cri-dockerd;首先在非关键节点上测试这一迁移过程。
你应该针对所有希望迁移到 cri-dockerd 的节点执行以下步骤。
cri-dockerd
并且该服务已经在各节点上启动;隔离节点,阻止新的 Pod 被调度到节点上:
kubectl cordon <NODE_NAME>
将 <NODE_NAME> 替换为节点名称。
腾空节点以安全地逐出所有运行中的 Pod:
kubectl drain <NODE_NAME> --ignore-daemonsets
下面的步骤适用于用 kubeadm 工具安装的集群。如果你使用不同的工具, 你需要使用针对该工具的配置指令来修改 kubelet。
/var/lib/kubelet/kubeadm-flags.env 文件;--container-runtime-endpoint 标志,将其设置为 unix:///var/run/cri-dockerd.sock。--container-runtime 标志修改为 remote(在 Kubernetes v1.27 及更高版本中不可用)。kubeadm 工具将节点上的套接字存储为控制面上 Node 对象的注解。
要为每个被影响的节点更改此套接字:
编辑 Node 对象的 YAML 表示:
KUBECONFIG=/path/to/admin.conf kubectl edit no <NODE_NAME>
根据下面的说明执行替换:
/path/to/admin.conf:指向 kubectl 配置文件 admin.conf 的路径;<NODE_NAME>:你要修改的节点的名称。将 kubeadm.alpha.kubernetes.io/cri-socket 标志从
/var/run/dockershim.sock 更改为 unix:///var/run/cri-dockerd.sock;
保存所作更改。保存时,Node 对象被更新。
systemctl restart kubelet
要检查节点是否在使用 cri-dockerd 端点,
按照找出你所使用的运行时页面所给的指令操作。
kubelet 的 --container-runtime-endpoint 标志取值应该是 unix:///var/run/cri-dockerd.sock。
kubectl uncordon <NODE_NAME>
本页面描述查明集群中节点所使用的容器运行时 的步骤。
取决于你运行集群的方式,节点所使用的容器运行时可能是事先配置好的,
也可能需要你来配置。如果你在使用托管的 Kubernetes 服务,
可能存在特定于厂商的方法来检查节点上配置的容器运行时。
本页描述的方法应该在能够执行 kubectl 的场合下都可以工作。
安装并配置 kubectl。参见安装工具 节了解详情。
使用 kubectl 来读取并显示节点信息:
kubectl get nodes -o wide
输出如下面所示。CONTAINER-RUNTIME 列给出容器运行时及其版本。
对于 Docker Engine,输出类似于:
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.16.15 docker://19.3.1
node-2 Ready v1.16.15 docker://19.3.1
node-3 Ready v1.16.15 docker://19.3.1
如果你的容器运行时显示为 Docker Engine,你仍然可能不会被 v1.24 中 dockershim 的移除所影响。 通过检查运行时端点,可以查看你是否在使用 dockershim。 如果你没有使用 dockershim,你就不会被影响。
对于 containerd,输出类似于这样:
# For containerd
NAME STATUS VERSION CONTAINER-RUNTIME
node-1 Ready v1.19.6 containerd://1.4.1
node-2 Ready v1.19.6 containerd://1.4.1
node-3 Ready v1.19.6 containerd://1.4.1
你可以在容器运行时 页面找到与容器运行时相关的更多信息。
容器运行时使用 Unix Socket 与 kubelet 通信,这一通信使用基于 gRPC 框架的 CRI 协议。kubelet 扮演客户端,运行时扮演服务器端。 在某些情况下,你可能想知道你的节点使用的是哪个 socket。 如若集群是 Kubernetes v1.24 及以后的版本, 或许你想知道当前运行时是否是使用 dockershim 的 Docker Engine。
如果你的节点在通过 cri-dockerd 使用 Docker Engine,
那么集群不会受到 Kubernetes 移除 dockershim 的影响。
可以通过检查 kubelet 的参数得知当前使用的是哪个 socket。
查看 kubelet 进程的启动命令
tr \\0 ' ' < /proc/"$(pgrep kubelet)"/cmdline
如有节点上没有 tr 或者 pgrep,就需要手动检查 kubelet 的启动命令
在命令的输出中,查找 --container-runtime 和 --container-runtime-endpoint 标志。
--container-runtime 标志值不是 remote,则你在通过 dockershim 套接字使用
Docker Engine。
在 Kubernetes v1.27 及以后的版本中,--container-runtime 命令行参数不再可用。--container-runtime-endpoint 参数,查看套接字名称即可得知当前使用的运行时。
如若套接字 unix:///run/containerd/containerd.sock 是 containerd 的端点。如果你将节点上的容器运行时从 Docker Engine 改变为 containerd,可在
迁移到不同的运行时
找到更多信息。或者,如果你想在 Kubernetes v1.24 及以后的版本仍使用 Docker Engine,
可以安装 CRI 兼容的适配器实现,如 cri-dockerd。
为了避免 CNI 插件相关的错误,需要验证你正在使用或升级到一个经过测试的容器运行时, 该容器运行时能够在你的 Kubernetes 版本上正常工作。
在 containerd v1.6.0-v1.6.3 中,当配置或清除 Pod CNI 网络时,如果 CNI 插件没有升级和/或 CNI 配置文件中没有声明 CNI 配置版本时,会出现服务问题。containerd 团队报告说: “这些问题在 containerd v1.6.4 中得到了解决。”
在使用 containerd v1.6.0-v1.6.3 时,如果你不升级 CNI 插件和/或声明 CNI 配置版本, 你可能会遇到以下 "Incompatible CNI versions" 或 "Failed to destroy network for sandbox" 错误状况。
如果因为配置版本比插件版本新,导致你的 CNI 插件版本与配置中的插件版本无法正确匹配时, 在启动 Pod 时,containerd 日志可能会显示类似的错误信息:
incompatible CNI versions; config is \"1.0.0\", plugin supports [\"0.1.0\" \"0.2.0\" \"0.3.0\" \"0.3.1\" \"0.4.0\"]"
为了解决这个问题,需要更新你的 CNI 插件和 CNI 配置文件。
如果 CNI 插件配置中未给出插件的版本, Pod 可能可以运行。但是,停止 Pod 时会产生类似于以下错误:
ERROR[2022-04-26T00:43:24.518165483Z] StopPodSandbox for "b" failed
error="failed to destroy network for sandbox \"bbc85f891eaf060c5a879e27bba9b6b06450210161dfdecfbb2732959fb6500a\": invalid version \"\": the version is empty"
此错误使 Pod 处于未就绪状态,且仍然挂接到某网络名字空间上。 为修复这一问题,编辑 CNI 配置文件以添加缺失的版本信息。 下一次尝试停止 Pod 应该会成功。
如果你使用 containerd v1.6.0-v1.6.3 并遇到 "Incompatible CNI versions" 或者 "Failed to destroy network for sandbox" 错误,考虑更新你的 CNI 插件并编辑 CNI 配置文件。
以下是针对各节点要执行的典型步骤的概述:
containerd,请确保你已安装 CNI loopback 插件的最新版本(v1.0.0 或更高版本)。kubectl uncordon <nodename>)。以下示例显示了 containerd 运行时 v1.6.x 的配置,
它支持最新版本的 CNI 规范(v1.0.0)。
请参阅你的插件和网络提供商的文档,以获取有关你系统配置的进一步说明。
在 Kubernetes 中,作为其默认行为,containerd 运行时为 Pod 添加一个本地回路接口:lo。
containerd 运行时通过 CNI 插件 loopback 配置本地回路接口。
loopback 插件作为 containerd 发布包的一部分,扮演 cni 角色。
containerd v1.6.0 及更高版本包括与 CNI v1.0.0 兼容的 loopback 插件以及其他默认 CNI 插件。
loopback 插件的配置由 containerd 内部完成,并被设置为使用 CNI v1.0.0。
这也意味着当这个更新版本的 containerd 启动时,loopback 插件的版本必然是 v1.0.0 或更高版本。
以下 Bash 命令生成一个 CNI 配置示例。这里,cniVersion 字段被设置为配置版本值 1.0.0,
以供 containerd 调用 CNI 桥接插件时使用。
cat << EOF | tee /etc/cni/net.d/10-containerd-net.conflist
{
"cniVersion": "1.0.0",
"name": "containerd-net",
"plugins": [
{
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"promiscMode": true,
"ipam": {
"type": "host-local",
"ranges": [
[{
"subnet": "10.88.0.0/16"
}],
[{
"subnet": "2001:db8:4860::/64"
}]
],
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "::/0" }
]
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true},
"externalSetMarkChain": "KUBE-MARK-MASQ"
}
]
}
EOF
基于你的用例和网络地址规划,将前面示例中的 IP 地址范围更新为合适的值。
Kubernetes 的 dockershim 组件使得你可以把 Docker 用作 Kubernetes 的
容器运行时。
在 Kubernetes v1.24 版本中,内建组件 dockershim 被移除。
本页讲解你的集群把 Docker 用作容器运行时的运作机制,
并提供使用 dockershim 时,它所扮演角色的详细信息,
继而展示了一组操作,可用来检查移除 dockershim 对你的工作负载是否有影响。
即使你是通过 Docker 创建的应用容器,也不妨碍你在其他任何容器运行时上运行这些容器。 这种使用 Docker 的方式并不构成对 Docker 作为一个容器运行时的依赖。
当用了别的容器运行时之后,Docker 命令可能不工作,或者产生意外的输出。 下面是判定你是否依赖于 Docker 的方法。
docker ps)、重新启动 Docker
服务(如 systemctl restart docker.service)或修改 Docker 配置文件
/etc/docker/daemon.json。/etc/docker/daemon.json)中容器镜像仓库的镜像(mirror)站点设置。
这些配置通常需要针对不同容器运行时来重新设置。容器运行时是一个软件, 用来运行组成 Kubernetes Pod 的容器。 Kubernetes 负责编排和调度 Pod;在每一个节点上,kubelet 使用抽象的容器运行时接口,所以你可以任意选用兼容的容器运行时。
在早期版本中,Kubernetes 提供的兼容性支持一个容器运行时:Docker。
在 Kubernetes 后来的发展历史中,集群运营人员希望采用别的容器运行时。
于是 CRI 被设计出来满足这类灵活性需求 - 而 kubelet 亦开始支持 CRI。
然而,因为 Docker 在 CRI 规范创建之前就已经存在,Kubernetes 就创建了一个适配器组件 dockershim。
dockershim 适配器允许 kubelet 与 Docker 交互,就好像 Docker 是一个 CRI 兼容的运行时一样。
你可以阅读博文 Kubernetes 正式支持集成 Containerd。
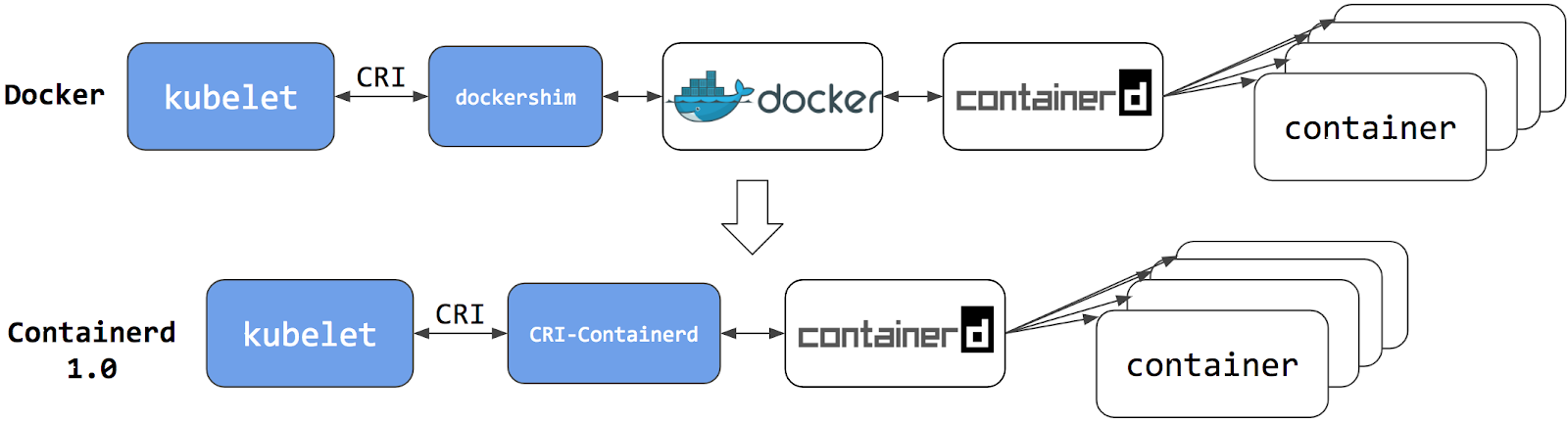
切换到 Containerd 容器运行时可以消除掉中间环节。 所有相同的容器都可由 Containerd 这类容器运行时来运行。 但是现在,由于直接用容器运行时调度容器,它们对 Docker 是不可见的。 因此,你以前用来检查这些容器的 Docker 工具或漂亮的 UI 都不再可用。
你不能再使用 docker ps 或 docker inspect 命令来获取容器信息。
由于你不能列出容器,因此你不能获取日志、停止容器,甚至不能通过 docker exec 在容器中执行命令。
如果你在用 Kubernetes 运行工作负载,最好通过 Kubernetes API 停止容器, 而不是通过容器运行时来停止它们(此建议适用于所有容器运行时,不仅仅是针对 Docker)。
你仍然可以下载镜像,或者用 docker build 命令创建它们。
但用 Docker 创建、下载的镜像,对于容器运行时和 Kubernetes,均不可见。
为了在 Kubernetes 中使用,需要把镜像推送(push)到某镜像仓库。
Kubelet /metrics/cadvisor 端点提供 Prometheus 指标,
如 Kubernetes 系统组件指标 中所述。
如果你安装了一个依赖该端点的指标收集器,你可能会看到以下问题:
Docker 节点上的指标格式为 k8s_<container-name>_<pod-name>_<namespace>_<pod-uid>_<restart-count>,
但其他运行时的格式不同。例如,在 containerd 节点上它是 <container-id>。
一些文件系统指标缺失,如下所示:
container_fs_inodes_free
container_fs_inodes_total
container_fs_io_current
container_fs_io_time_seconds_total
container_fs_io_time_weighted_seconds_total
container_fs_limit_bytes
container_fs_read_seconds_total
container_fs_reads_merged_total
container_fs_sector_reads_total
container_fs_sector_writes_total
container_fs_usage_bytes
container_fs_write_seconds_total
container_fs_writes_merged_total
你可以通过使用 cAdvisor 作为一个独立的守护程序来缓解这个问题。
vX.Y.Z-containerd-cri 的最新
cAdvisor 版本(例如 v0.42.0-containerd-cri)。/metrics 端点。
该端点提供了全套的 Prometheus 容器指标。替代方案:
/stats/summary 提供服务。Kubernetes 对与 Docker Engine 直接集成的支持已被弃用且已经被删除。 大多数应用程序不直接依赖于托管容器的运行时。但是,仍然有大量的遥测和监控代理依赖 docker 来收集容器元数据、日志和指标。 本文汇总了一些信息和链接:信息用于阐述如何探查这些依赖,链接用于解释如何迁移这些代理去使用通用的工具或其他容器运行。
在 Kubernetes 集群中,有几种不同的方式来运行遥测或安全代理。 一些代理在以 DaemonSet 的形式运行或直接在节点上运行时,直接依赖于 Docker Engine。
从历史上看,Kubernetes 是专门为与 Docker Engine 一起工作而编写的。 Kubernetes 负责网络和调度,依靠 Docker Engine 在节点上启动并运行容器(在 Pod 内)。一些与遥测相关的信息,例如 pod 名称, 只能从 Kubernetes 组件中获得。其他数据,例如容器指标,不是容器运行时的责任。 早期遥测代理需要查询容器运行时和 Kubernetes 以报告准确的信息。 随着时间的推移,Kubernetes 获得了支持多种运行时的能力, 现在支持任何兼容容器运行时接口的运行时。
一些代理和 Docker 工具紧密绑定。比如代理会用到
docker ps
或 docker top
这类命令来列出容器和进程,用
docker logs
订阅 Docker 的日志。
如果现有集群中的节点使用 Docker Engine,在你切换到其它容器运行时的时候,
这些命令将不再起作用。
如果某 Pod 想调用运行在节点上的 dockerd,该 Pod 必须满足以下两个条件之一:
举例来说:在 COS 镜像中,Docker 通过 /var/run/docker.sock 开放其 Unix 域套接字。
这意味着 Pod 的规约中需要包含 hostPath 卷以挂载 /var/run/docker.sock。
下面是一个 shell 示例脚本,用于查找包含直接映射 Docker 套接字的挂载点的 Pod。
你也可以删掉 grep '/var/run/docker.sock' 这一代码片段以查看其它挂载信息。
kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort \
| grep '/var/run/docker.sock'
/var/run 的父目录而非其完整路径
(就像这个例子)。
上述脚本只检测最常见的使用方式。
在你的集群节点被定制、且在各个节点上均安装了额外的安全和遥测代理的场景下, 一定要和代理的供应商确认:该代理是否依赖于 Docker。
本节旨在汇总有关可能依赖于容器运行时的各种遥测和安全代理的信息。
我们通过 谷歌文档 提供了为各类遥测和安全代理供应商准备的持续更新的迁移指导。 请与供应商联系,获取从 dockershim 迁移的最新说明。
无需更改:在运行时变更时可以无缝切换运行。
如何迁移: Kubernetes 中对于 Docker 的弃用 名字中包含以下字符串的 Pod 可能访问 Docker Engine:
datadog-agentdatadogdd-agent如何迁移: 在 Dynatrace 上从 Docker-only 迁移到通用容器指标
Containerd 支持公告:在基于 containerd 的 Kubernetes 环境的获取容器的自动化全栈可见性 CRI-O 支持公告:在基于 CRI-O 的 Kubernetes 环境获取容器的自动化全栈可见性(测试版)
名字中包含以下字符串的 Pod 可能访问 Docker:
dynatrace-oneagent如何迁移: 迁移 Falco 从 dockershim Falco 支持任何与 CRI 兼容的运行时(默认配置中使用 containerd);该文档解释了所有细节。
名字中包含以下字符串的 Pod 可能访问 Docker:
falco在依赖于 CRI(非 Docker)的集群上安装 Prisma Cloud 时,查看 Prisma Cloud 提供的文档。
名字中包含以下字符串的 Pod 可能访问 Docker:
twistlock-defender-dsSignalFx Smart Agent(已弃用)在 Kubernetes 集群上使用了多种不同的监视器,
包括 kubernetes-cluster,kubelet-stats/kubelet-metrics,docker-container-stats。
kubelet-stats 监视器此前已被供应商所弃用,现支持 kubelet-metrics。
docker-container-stats 监视器受 dockershim 移除的影响。
不要为 docker-container-stats 监视器使用 Docker Engine 之外的运行时。
如何从依赖 dockershim 的代理迁移:
docker-container-stats。
注意,若节点上已经安装了 Docker,在非 dockershim 环境中启用此监视器后会导致报告错误的指标;
如果节点未安装 Docker,则无法获得指标。kubelet-metrics 监视器。名字中包含以下字符串的 Pod 可能访问 Docker:
signalfx-agentFlame 不支持 Docker 以外的容器运行时,具体可见 https://github.com/yahoo/kubectl-flame/issues/51
在使用客户端证书认证的场景下,你可以通过 easyrsa、
openssl 或 cfssl
等工具以手工方式生成证书。
easyrsa 支持以手工方式为你的集群生成证书。
下载、解压、初始化打过补丁的 easyrsa3。
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
生成新的证书颁发机构(CA)。参数 --batch 用于设置自动模式;
参数 --req-cn 用于设置新的根证书的通用名称(CN)。
./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass
生成服务器证书和秘钥。
参数 --subject-alt-name 设置 API 服务器的 IP 和 DNS 名称。
MASTER_CLUSTER_IP 用于 API 服务器和控制器管理器,通常取 CIDR 的第一个 IP,
由 --service-cluster-ip-range 的参数提供。
参数 --days 用于设置证书的过期时间。
下面的示例假定你的默认 DNS 域名为 cluster.local。
./easyrsa --subject-alt-name="IP:${MASTER_IP},"\
"IP:${MASTER_CLUSTER_IP},"\
"DNS:kubernetes,"\
"DNS:kubernetes.default,"\
"DNS:kubernetes.default.svc,"\
"DNS:kubernetes.default.svc.cluster,"\
"DNS:kubernetes.default.svc.cluster.local" \
--days=10000 \
build-server-full server nopass
pki/ca.crt、pki/issued/server.crt 和 pki/private/server.key 到你的目录中。在 API 服务器的启动参数中添加以下参数:
--client-ca-file=/yourdirectory/ca.crt
--tls-cert-file=/yourdirectory/server.crt
--tls-private-key-file=/yourdirectory/server.key
openssl 支持以手工方式为你的集群生成证书。
生成一个 2048 位的 ca.key 文件
openssl genrsa -out ca.key 2048
在 ca.key 文件的基础上,生成 ca.crt 文件(用参数 -days 设置证书有效期)
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt
生成一个 2048 位的 server.key 文件:
openssl genrsa -out server.key 2048
创建一个用于生成证书签名请求(CSR)的配置文件。
保存文件(例如:csr.conf)前,记得用真实值替换掉尖括号中的值(例如:<MASTER_IP>)。
注意:MASTER_CLUSTER_IP 就像前一小节所述,它的值是 API 服务器的服务集群 IP。
下面的例子假定你的默认 DNS 域名为 cluster.local。
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = <country>
ST = <state>
L = <city>
O = <organization>
OU = <organization unit>
CN = <MASTER_IP>
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = <MASTER_IP>
IP.2 = <MASTER_CLUSTER_IP>
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
subjectAltName=@alt_names
基于上面的配置文件生成证书签名请求:
openssl req -new -key server.key -out server.csr -config csr.conf
基于 ca.key、ca.crt 和 server.csr 等三个文件生成服务端证书:
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \
-CAcreateserial -out server.crt -days 10000 \
-extensions v3_ext -extfile csr.conf -sha256
查看证书签名请求:
openssl req -noout -text -in ./server.csr
查看证书:
openssl x509 -noout -text -in ./server.crt
最后,为 API 服务器添加相同的启动参数。
cfssl 是另一个用于生成证书的工具。
下载、解压并准备如下所示的命令行工具。
注意:你可能需要根据所用的硬件体系架构和 cfssl 版本调整示例命令。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl
chmod +x cfssl
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson
chmod +x cfssljson
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo
chmod +x cfssl-certinfo
创建一个目录,用它保存所生成的构件和初始化 cfssl:
mkdir cert
cd cert
../cfssl print-defaults config > config.json
../cfssl print-defaults csr > csr.json
创建一个 JSON 配置文件来生成 CA 文件,例如:ca-config.json:
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
创建一个 JSON 配置文件,用于 CA 证书签名请求(CSR),例如:ca-csr.json。
确认用你需要的值替换掉尖括号中的值。
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names":[{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
生成 CA 秘钥文件(ca-key.pem)和证书文件(ca.pem):
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
创建一个 JSON 配置文件,用来为 API 服务器生成秘钥和证书,例如:server-csr.json。
确认用你需要的值替换掉尖括号中的值。MASTER_CLUSTER_IP 是为 API 服务器 指定的服务集群 IP,就像前面小节描述的那样。
以下示例假定你的默认 DNS 域名为cluster.local。
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"<MASTER_IP>",
"<MASTER_CLUSTER_IP>",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
为 API 服务器生成秘钥和证书,默认会分别存储为server-key.pem 和 server.pem 两个文件。
../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \
--config=ca-config.json -profile=kubernetes \
server-csr.json | ../cfssljson -bare server
客户端节点可能不认可自签名 CA 证书的有效性。 对于非生产环境,或者运行在公司防火墙后的环境,你可以分发自签名的 CA 证书到所有客户节点,并刷新本地列表以使证书生效。
在每一个客户节点,执行以下操作:
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
你可以通过 certificates.k8s.io API 提供 x509 证书,用来做身份验证,
如管理集群中的 TLS 认证文档所述。
本章介绍如何为命名空间配置默认的内存请求和限制。
一个 Kubernetes 集群可被划分为多个命名空间。 如果你在具有默认内存限制 的命名空间内尝试创建一个 Pod,并且这个 Pod 中的容器没有声明自己的内存资源限制, 那么控制面会为该容器设定默认的内存限制。
Kubernetes 还为某些情况指定了默认的内存请求,本章后面会进行介绍。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在你的集群里你必须要有创建命名空间的权限。
你的集群中的每个节点必须至少有 2 GiB 的内存。
创建一个命名空间,以便本练习中所建的资源与集群的其余资源相隔离。
kubectl create namespace default-mem-example
以下为 LimitRange 的示例清单。 清单中声明了默认的内存请求和默认的内存限制。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
memory: 256Mi
type: Container
在 default-mem-example 命名空间创建限制范围:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults.yaml --namespace=default-mem-example
现在如果你在 default-mem-example 命名空间中创建一个 Pod, 并且该 Pod 中所有容器都没有声明自己的内存请求和内存限制, 控制面 会将内存的默认请求值 256MiB 和默认限制值 512MiB 应用到 Pod 上。
以下为只包含一个容器的 Pod 的清单。该容器没有声明内存请求和限制。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo
spec:
containers:
- name: default-mem-demo-ctr
image: nginx
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod.yaml --namespace=default-mem-example
查看 Pod 的详情:
kubectl get pod default-mem-demo --output=yaml --namespace=default-mem-example
输出内容显示该 Pod 的容器有 256 MiB 的内存请求和 512 MiB 的内存限制。 这些都是 LimitRange 设置的默认值。
containers:
- image: nginx
imagePullPolicy: Always
name: default-mem-demo-ctr
resources:
limits:
memory: 512Mi
requests:
memory: 256Mi
删除你的 Pod:
kubectl delete pod default-mem-demo --namespace=default-mem-example
以下为只包含一个容器的 Pod 的清单。该容器声明了内存限制,而没有声明内存请求。
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-2
spec:
containers:
- name: default-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1Gi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-2.yaml --namespace=default-mem-example
查看 Pod 的详情:
kubectl get pod default-mem-demo-2 --output=yaml --namespace=default-mem-example
输出结果显示容器的内存请求被设置为它的内存限制相同的值。注意该容器没有被指定默认的内存请求值 256MiB。
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
以下为只包含一个容器的 Pod 的清单。该容器声明了内存请求,但没有内存限制:
apiVersion: v1
kind: Pod
metadata:
name: default-mem-demo-3
spec:
containers:
- name: default-mem-demo-3-ctr
image: nginx
resources:
requests:
memory: "128Mi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-defaults-pod-3.yaml --namespace=default-mem-example
查看 Pod 声明:
kubectl get pod default-mem-demo-3 --output=yaml --namespace=default-mem-example
输出结果显示所创建的 Pod 中,容器的内存请求为 Pod 清单中声明的值。 然而同一容器的内存限制被设置为 512MiB,此值是该命名空间的默认内存限制值。
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
LimitRange 不会检查它应用的默认值的一致性。 这意味着 LimitRange 设置的 limit 的默认值可能小于客户端提交给
API 服务器的声明中为容器指定的 request 值。如果发生这种情况,最终会导致 Pod 无法调度。更多信息,
请参阅资源限制的 limit 和 request。
如果你的命名空间设置了内存 资源配额, 那么为内存限制设置一个默认值会很有帮助。 以下是内存资源配额对命名空间的施加的三条限制:
命名空间中运行的每个 Pod 中的容器都必须有内存限制。 (如果为 Pod 中的每个容器声明了内存限制, Kubernetes 可以通过将其容器的内存限制相加推断出 Pod 级别的内存限制)。
内存限制用来在 Pod 被调度到的节点上执行资源预留。 预留给命名空间中所有 Pod 使用的内存总量不能超过规定的限制。
命名空间中所有 Pod 实际使用的内存总量也不能超过规定的限制。
当你添加 LimitRange 时:
如果该命名空间中的任何 Pod 的容器未指定内存限制, 控制面将默认内存限制应用于该容器, 这样 Pod 可以在受到内存 ResourceQuota 限制的命名空间中运行。
删除你的命名空间:
kubectl delete namespace default-mem-example
本章介绍如何为命名空间配置默认的 CPU 请求和限制。
一个 Kubernetes 集群可被划分为多个命名空间。 如果你在具有默认 CPU 限制 的命名空间内创建一个 Pod,并且这个 Pod 中任何容器都没有声明自己的 CPU 限制, 那么控制面会为容器设定默认的 CPU 限制。
Kubernetes 在一些特定情况还可以设置默认的 CPU 请求,本文后续章节将会对其进行解释。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在你的集群里你必须要有创建命名空间的权限。
如果你还不熟悉 Kubernetes 中 1.0 CPU 的含义, 请阅读 CPU 的含义。
创建一个命名空间,以便本练习中创建的资源和集群的其余部分相隔离。
kubectl create namespace default-cpu-example
以下为 LimitRange 的示例清单。 清单中声明了默认 CPU 请求和默认 CPU 限制。
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Container
在命名空间 default-cpu-example 中创建 LimitRange 对象:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults.yaml --namespace=default-cpu-example
现在如果你在 default-cpu-example 命名空间中创建一个 Pod, 并且该 Pod 中所有容器都没有声明自己的 CPU 请求和 CPU 限制, 控制面会将 CPU 的默认请求值 0.5 和默认限制值 1 应用到 Pod 上。
以下为只包含一个容器的 Pod 的清单。该容器没有声明 CPU 请求和限制。
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo
spec:
containers:
- name: default-cpu-demo-ctr
image: nginx
创建 Pod。
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod.yaml --namespace=default-cpu-example
查看该 Pod 的声明:
kubectl get pod default-cpu-demo --output=yaml --namespace=default-cpu-example
输出显示该 Pod 的唯一的容器有 500m cpu 的 CPU 请求和 1 cpu 的 CPU 限制。
这些是 LimitRange 声明的默认值。
containers:
- image: nginx
imagePullPolicy: Always
name: default-cpu-demo-ctr
resources:
limits:
cpu: "1"
requests:
cpu: 500m
以下为只包含一个容器的 Pod 的清单。该容器声明了 CPU 限制,而没有声明 CPU 请求。
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-2
spec:
containers:
- name: default-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-2.yaml --namespace=default-cpu-example
查看你所创建的 Pod 的规约:
kubectl get pod default-cpu-demo-2 --output=yaml --namespace=default-cpu-example
输出显示该容器的 CPU 请求和 CPU 限制设置相同。注意该容器没有被指定默认的 CPU 请求值 0.5 cpu:
resources:
limits:
cpu: "1"
requests:
cpu: "1"
这里给出了包含一个容器的 Pod 的示例清单。该容器声明了 CPU 请求,而没有声明 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: default-cpu-demo-3
spec:
containers:
- name: default-cpu-demo-3-ctr
image: nginx
resources:
requests:
cpu: "0.75"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-defaults-pod-3.yaml --namespace=default-cpu-example
查看你所创建的 Pod 的规约:
kubectl get pod default-cpu-demo-3 --output=yaml --namespace=default-cpu-example
输出显示你所创建的 Pod 中,容器的 CPU 请求为 Pod 清单中声明的值。
然而同一容器的 CPU 限制被设置为 1 cpu,此值是该命名空间的默认 CPU 限制值。
resources:
limits:
cpu: "1"
requests:
cpu: 750m
如果你的命名空间设置了 CPU 资源配额, 为 CPU 限制设置一个默认值会很有帮助。 以下是 CPU 资源配额对命名空间的施加的两条限制:
命名空间中运行的每个 Pod 中的容器都必须有 CPU 限制。
CPU 限制用来在 Pod 被调度到的节点上执行资源预留。
预留给命名空间中所有 Pod 使用的 CPU 总量不能超过规定的限制。
当你添加 LimitRange 时:
如果该命名空间中的任何 Pod 的容器未指定 CPU 限制, 控制面将默认 CPU 限制应用于该容器, 这样 Pod 可以在受到 CPU ResourceQuota 限制的命名空间中运行。
删除你的命名空间:
kubectl delete namespace default-cpu-example
本页介绍如何设置在名字空间 中运行的容器所使用的内存的最小值和最大值。你可以在 LimitRange 对象中指定最小和最大内存值。如果 Pod 不满足 LimitRange 施加的约束, 则无法在名字空间中创建它。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在你的集群里你必须要有创建命名空间的权限。
集群中的每个节点都必须至少有 1 GiB 的内存可供 Pod 使用。
创建一个命名空间,以便在此练习中创建的资源与集群的其余资源隔离。
kubectl create namespace constraints-mem-example
下面是 LimitRange 的示例清单:
apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
创建 LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
查看 LimitRange 的详情:
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
输出显示预期的最小和最大内存约束。 但请注意,即使你没有在 LimitRange 的配置文件中指定默认值,默认值也会自动生成。
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
现在,每当在 constraints-mem-example 命名空间中创建 Pod 时,Kubernetes 就会执行下面的步骤:
以下为包含一个容器的 Pod 清单。该容器声明了 600 MiB 的内存请求和 800 MiB 的内存限制, 这些满足了 LimitRange 施加的最小和最大内存约束。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
确认 Pod 正在运行,并且其容器处于健康状态:
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
查看 Pod 详情:
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
输出结果显示该 Pod 的容器的内存请求为 600 MiB,内存限制为 800 MiB。 这些满足这个命名空间中 LimitRange 设定的限制范围。
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
删除你创建的 Pod:
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
以下为包含一个容器的 Pod 的清单。这个容器声明了 800 MiB 的内存请求和 1.5 GiB 的内存限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
输出结果显示 Pod 没有创建成功,因为它定义了一个容器的内存请求超过了允许的值。
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
以下为只有一个容器的 Pod 的清单。这个容器声明了 100 MiB 的内存请求和 800 MiB 的内存限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
输出结果显示 Pod 没有创建成功,因为它定义了一个容器的内存请求小于强制要求的最小值:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
以下为只有一个容器的 Pod 清单。该容器没有声明内存请求,也没有声明内存限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
查看 Pod 详情:
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
输出结果显示 Pod 的唯一容器内存请求为 1 GiB,内存限制为 1 GiB。容器怎样获得那些数值呢?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
因为你的 Pod 没有为容器声明任何内存请求和限制,集群会从 LimitRange 获取默认的内存请求和限制。 应用于容器。
这意味着 Pod 的定义会显示这些值。你可以通过 kubectl describe 查看:
# 查看输出结果中的 "Requests:" 的值
kubectl describe pod constraints-mem-demo-4 --namespace=constraints-mem-example
此时,你的 Pod 可能已经运行起来也可能没有运行起来。 回想一下我们本次任务的先决条件是你的每个节点都至少有 1 GiB 的内存。 如果你的每个节点都只有 1 GiB 的内存,那将没有一个节点拥有足够的可分配内存来满足 1 GiB 的内存请求。
删除你的 Pod:
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
LimitRange 为命名空间设定的最小和最大内存限制只有在 Pod 创建和更新时才会强制执行。 如果你更新 LimitRange,它不会影响此前创建的 Pod。
作为集群管理员,你可能想规定 Pod 可以使用的内存总量限制。例如:
删除你的命名空间:
kubectl delete namespace constraints-mem-example
本页介绍如何为命名空间中的容器和 Pod 设置其所使用的 CPU 资源的最小和最大值。你可以通过 LimitRange 对象声明 CPU 的最小和最大值. 如果 Pod 不能满足 LimitRange 的限制,就无法在该命名空间中被创建。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在你的集群里你必须要有创建命名空间的权限。
集群中的每个节点都必须至少有 1.0 个 CPU 可供 Pod 使用。
请阅读 CPU 的含义 理解 "1 CPU" 在 Kubernetes 中的含义。
创建一个命名空间,以便本练习中创建的资源和集群的其余资源相隔离。
kubectl create namespace constraints-cpu-example
以下为 LimitRange 的示例清单:
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-min-max-demo-lr
spec:
limits:
- max:
cpu: "800m"
min:
cpu: "200m"
type: Container
创建 LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints.yaml --namespace=constraints-cpu-example
查看 LimitRange 详情:
kubectl get limitrange cpu-min-max-demo-lr --output=yaml --namespace=constraints-cpu-example
输出结果显示 CPU 的最小和最大限制符合预期。但需要注意的是,尽管你在 LimitRange 的配置文件中你没有声明默认值,默认值也会被自动创建。
limits:
- default:
cpu: 800m
defaultRequest:
cpu: 800m
max:
cpu: 800m
min:
cpu: 200m
type: Container
现在,每当你在 constraints-cpu-example 命名空间中创建 Pod 时,或者某些其他的 Kubernetes API 客户端创建了等价的 Pod 时,Kubernetes 就会执行下面的步骤:
如果 Pod 中的任何容器未声明自己的 CPU 请求和限制,控制面将为该容器设置默认的 CPU 请求和限制。
确保该 Pod 中的每个容器的 CPU 请求至少 200 millicpu。
确保该 Pod 中每个容器 CPU 请求不大于 800 millicpu。
LimitRange 对象时,你也可以声明大页面和 GPU 的限制。
当这些资源同时声明了 default 和 defaultRequest 参数时,两个参数值必须相同。
以下为某个仅包含一个容器的 Pod 的清单。 该容器声明了 CPU 请求 500 millicpu 和 CPU 限制 800 millicpu。 这些参数满足了 LimitRange 对象为此名字空间规定的 CPU 最小和最大限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo
spec:
containers:
- name: constraints-cpu-demo-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "500m"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod.yaml --namespace=constraints-cpu-example
确认 Pod 正在运行,并且其容器处于健康状态:
kubectl get pod constraints-cpu-demo --namespace=constraints-cpu-example
查看 Pod 的详情:
kubectl get pod constraints-cpu-demo --output=yaml --namespace=constraints-cpu-example
输出结果显示该 Pod 的容器的 CPU 请求为 500 millicpu,CPU 限制为 800 millicpu。 这些参数满足 LimitRange 规定的限制范围。
resources:
limits:
cpu: 800m
requests:
cpu: 500m
kubectl delete pod constraints-cpu-demo --namespace=constraints-cpu-example
这里给出了包含一个容器的 Pod 清单。容器声明了 500 millicpu 的 CPU 请求和 1.5 CPU 的 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-2
spec:
containers:
- name: constraints-cpu-demo-2-ctr
image: nginx
resources:
limits:
cpu: "1.5"
requests:
cpu: "500m"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-2.yaml --namespace=constraints-cpu-example
输出结果表明 Pod 没有创建成功,因为其中定义了一个无法被接受的容器。 该容器之所以无法被接受是因为其中设定了过高的 CPU 限制值:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-2.yaml":
pods "constraints-cpu-demo-2" is forbidden: maximum cpu usage per Container is 800m, but limit is 1500m.
以下为某个只有一个容器的 Pod 的清单。该容器声明了 CPU 请求 100 millicpu 和 CPU 限制 800 millicpu。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-3
spec:
containers:
- name: constraints-cpu-demo-3-ctr
image: nginx
resources:
limits:
cpu: "800m"
requests:
cpu: "100m"
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-3.yaml --namespace=constraints-cpu-example
输出结果显示 Pod 没有创建成功,因为其中定义了一个无法被接受的容器。 该容器无法被接受的原因是其中所设置的 CPU 请求小于最小值的限制:
Error from server (Forbidden): error when creating "examples/admin/resource/cpu-constraints-pod-3.yaml":
pods "constraints-cpu-demo-3" is forbidden: minimum cpu usage per Container is 200m, but request is 100m.
以下为一个只有一个容器的 Pod 的清单。该容器没有声明 CPU 请求,也没有声明 CPU 限制。
apiVersion: v1
kind: Pod
metadata:
name: constraints-cpu-demo-4
spec:
containers:
- name: constraints-cpu-demo-4-ctr
image: vish/stress
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/cpu-constraints-pod-4.yaml --namespace=constraints-cpu-example
查看 Pod 的详情:
kubectl get pod constraints-cpu-demo-4 --namespace=constraints-cpu-example --output=yaml
输出结果显示 Pod 的唯一容器的 CPU 请求为 800 millicpu,CPU 限制为 800 millicpu。
容器是怎样获得这些数值的呢?
resources:
limits:
cpu: 800m
requests:
cpu: 800m
因为这一容器没有声明自己的 CPU 请求和限制, 控制面会根据命名空间中配置 LimitRange 设置默认的 CPU 请求和限制。
此时,你的 Pod 可能已经运行起来也可能没有运行起来。 回想一下我们本次任务的先决条件是你的每个节点都至少有 1 CPU。 如果你的每个节点都只有 1 CPU,那将没有一个节点拥有足够的可分配 CPU 来满足 800 millicpu 的请求。 如果你在用的节点恰好有 2 CPU,那么有可能有足够的 CPU 来满足 800 millicpu 的请求。
删除你的 Pod:
kubectl delete pod constraints-cpu-demo-4 --namespace=constraints-cpu-example
只有当 Pod 创建或者更新时,LimitRange 为命名空间规定的 CPU 最小和最大限制才会被强制执行。 如果你对 LimitRange 进行修改,那不会影响此前创建的 Pod。
作为集群管理员,你可能想设定 Pod 可以使用的 CPU 资源限制。例如:
删除你的命名空间:
kubectl delete namespace constraints-cpu-example
本文介绍如何为命名空间下运行的所有 Pod 设置总的内存和 CPU 配额。你可以通过使用 ResourceQuota 对象设置配额.
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在你的集群里你必须要有创建命名空间的权限。
集群中每个节点至少有 1 GiB 的内存。
创建一个命名空间,以便本练习中创建的资源和集群的其余部分相隔离。
kubectl create namespace quota-mem-cpu-example
下面是 ResourceQuota 的示例清单:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
创建 ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu.yaml --namespace=quota-mem-cpu-example
查看 ResourceQuota 详情:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
ResourceQuota 在 quota-mem-cpu-example 命名空间中设置了如下要求:
请阅读 CPU 的含义 理解 "1 CPU" 在 Kubernetes 中的含义。
以下是 Pod 的示例清单:
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo
spec:
containers:
- name: quota-mem-cpu-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
cpu: "800m"
requests:
memory: "600Mi"
cpu: "400m"
创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod.yaml --namespace=quota-mem-cpu-example
确认 Pod 正在运行,并且其容器处于健康状态:
kubectl get pod quota-mem-cpu-demo --namespace=quota-mem-cpu-example
再查看 ResourceQuota 的详情:
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example --output=yaml
输出结果显示了配额以及有多少配额已经被使用。你可以看到 Pod 的内存和 CPU 请求值及限制值没有超过配额。
status:
hard:
limits.cpu: "2"
limits.memory: 2Gi
requests.cpu: "1"
requests.memory: 1Gi
used:
limits.cpu: 800m
limits.memory: 800Mi
requests.cpu: 400m
requests.memory: 600Mi
如果有 jq 工具的话,你可以通过(使用 JSONPath)
直接查询 used 字段的值,并且输出整齐的 JSON 格式。
kubectl get resourcequota mem-cpu-demo --namespace=quota-mem-cpu-example -o jsonpath='{ .status.used }' | jq .
以下为第二个 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: quota-mem-cpu-demo-2
spec:
containers:
- name: quota-mem-cpu-demo-2-ctr
image: redis
resources:
limits:
memory: "1Gi"
cpu: "800m"
requests:
memory: "700Mi"
cpu: "400m"
在清单中,你可以看到 Pod 的内存请求为 700 MiB。 请注意新的内存请求与已经使用的内存请求之和超过了内存请求的配额: 600 MiB + 700 MiB > 1 GiB。
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-mem-cpu-pod-2.yaml --namespace=quota-mem-cpu-example
第二个 Pod 不能被创建成功。输出结果显示创建第二个 Pod 会导致内存请求总量超过内存请求配额。
Error from server (Forbidden): error when creating "examples/admin/resource/quota-mem-cpu-pod-2.yaml":
pods "quota-mem-cpu-demo-2" is forbidden: exceeded quota: mem-cpu-demo,
requested: requests.memory=700Mi,used: requests.memory=600Mi, limited: requests.memory=1Gi
如你在本练习中所见,你可以用 ResourceQuota 限制命名空间中所有 Pod 的内存请求总量。 同样你也可以限制内存限制总量、CPU 请求总量、CPU 限制总量。
除了可以管理命名空间资源使用的总和,如果你想限制单个 Pod,或者限制这些 Pod 中的容器资源, 可以使用 LimitRange 实现这类的功能。
删除你的命名空间:
kubectl delete namespace quota-mem-cpu-example
本文主要介绍如何在命名空间中设置可运行 Pod 总数的配额。 你可以通过使用 ResourceQuota 对象来配置配额。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在你的集群里你必须要有创建命名空间的权限。
首先创建一个命名空间,这样可以将本次操作中创建的资源与集群其他资源隔离开来。
kubectl create namespace quota-pod-example
下面是 ResourceQuota 的示例清单:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-demo
spec:
hard:
pods: "2"
创建 ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod.yaml --namespace=quota-pod-example
查看资源配额的详细信息:
kubectl get resourcequota pod-demo --namespace=quota-pod-example --output=yaml
从输出的信息我们可以看到,该命名空间下 Pod 的配额是 2 个,目前创建的 Pod 数为 0, 配额使用率为 0。
spec:
hard:
pods: "2"
status:
hard:
pods: "2"
used:
pods: "0"
下面是一个 Deployment 的示例清单:
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-quota-demo
spec:
selector:
matchLabels:
purpose: quota-demo
replicas: 3
template:
metadata:
labels:
purpose: quota-demo
spec:
containers:
- name: pod-quota-demo
image: nginx
在清单中,replicas: 3 告诉 Kubernetes 尝试创建三个新的 Pod,
且运行相同的应用。
创建这个 Deployment:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-pod-deployment.yaml --namespace=quota-pod-example
查看 Deployment 的详细信息:
kubectl get deployment pod-quota-demo --namespace=quota-pod-example --output=yaml
从输出的信息显示,即使 Deployment 指定了三个副本, 也只有两个 Pod 被创建,原因是之前已经定义了配额:
spec:
...
replicas: 3
...
status:
availableReplicas: 2
...
lastUpdateTime: 2021-04-02T20:57:05Z
message: 'unable to create pods: pods "pod-quota-demo-1650323038-" is forbidden:
exceeded quota: pod-demo, requested: pods=1, used: pods=2, limited: pods=2'
在此任务中,你定义了一个限制 Pod 总数的 ResourceQuota, 你也可以限制其他类型对象的总数。 例如,你可以限制在一个命名空间中可以创建的 CronJob 的数量。
删除你的命名空间:
kubectl delete namespace quota-pod-example
本页展示了如何在 kubernetes 中安装和使用 Antrea CNI 插件。 要了解 Antrea 项目的背景,请阅读 Antrea 介绍。
你需要拥有一个 kuernetes 集群。 遵循 kubeadm 入门指南自行创建一个。
遵循入门指南 为 kubeadm 部署 Antrea 。
一旦你的集群已经运行,你可以遵循 声明网络策略 来尝试 Kubernetes NetworkPolicy。
本页展示了几种在 Kubernetes 上快速创建 Calico 集群的方法。
先决条件:gcloud
启动一个带有 Calico 的 GKE 集群,需要加上参数 --enable-network-policy。
语法
gcloud container clusters create [CLUSTER_NAME] --enable-network-policy
示例
gcloud container clusters create my-calico-cluster --enable-network-policy
使用如下命令验证部署是否正确。
kubectl get pods --namespace=kube-system
Calico 的 Pod 名以 calico 打头,检查确认每个 Pod 状态为 Running。
使用 kubeadm 在 15 分钟内得到一个本地单主机 Calico 集群,请参考 Calico 快速入门。
集群运行后, 你可以按照声明网络策略去尝试使用 Kubernetes NetworkPolicy。
本页展示如何使用 Cilium 提供 NetworkPolicy。
关于 Cilium 的背景知识,请阅读 Cilium 介绍。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
为了轻松熟悉 Cilium,你可以根据 Cilium Kubernetes 入门指南 在 minikube 中执行一个 Cilium 的基本 DaemonSet 安装。
要启动 minikube,需要的最低版本为 1.5.2,使用下面的参数运行:
minikube version
minikube version: v1.5.2
minikube start --network-plugin=cni
对于 minikube 你可以使用 Cilium 的 CLI 工具安装它。 为此,先用以下命令下载最新版本的 CLI:
curl -LO https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
然后用以下命令将下载的文件解压缩到你的 /usr/local/bin 目录:
sudo tar xzvfC cilium-linux-amd64.tar.gz /usr/local/bin
rm cilium-linux-amd64.tar.gz
运行上述命令后,你现在可以用以下命令安装 Cilium:
cilium install
随后 Cilium 将自动检测集群配置,并创建和安装合适的组件以成功完成安装。 这些组件为:
cilium-ca 中的证书机构 (CA) 和 Hubble(Cilium 的可观测层)所用的证书。安装之后,你可以用 cilium status 命令查看 Cilium Deployment 的整体状态。
在此处查看
status 命令的预期输出。
入门指南其余的部分用一个示例应用说明了如何强制执行 L3/L4(即 IP 地址 + 端口)的安全策略以及 L7 (如 HTTP)的安全策略。
关于部署 Cilium 用于生产的详细说明,请参见 Cilium Kubernetes 安装指南。 此文档包括详细的需求、说明和生产用途 DaemonSet 文件示例。
部署使用 Cilium 的集群会添加 Pod 到 kube-system 命名空间。要查看 Pod 列表,运行:
kubectl get pods --namespace=kube-system -l k8s-app=cilium
你将看到像这样的 Pod 列表:
NAME READY STATUS RESTARTS AGE
cilium-kkdhz 1/1 Running 0 3m23s
...
你的集群中的每个节点上都会运行一个 cilium Pod,通过使用 Linux BPF
针对该节点上的 Pod 的入站、出站流量实施网络策略控制。
集群运行后, 你可以按照声明网络策略试用基于 Cilium 的 Kubernetes NetworkPolicy。玩得开心,如果你有任何疑问,请到 Cilium Slack 频道联系我们。
本页展示如何使用 Kube-router 提供 NetworkPolicy。
你需要拥有一个运行中的 Kubernetes 集群。如果你还没有集群,可以使用任意的集群 安装程序如 Kops、Bootkube、Kubeadm 等创建一个。
kube-router 插件自带一个网络策略控制器,监视来自于 Kubernetes API 服务器的 NetworkPolicy 和 Pod 的变化,根据策略指示配置 iptables 规则和 ipsets 来允许或阻止流量。 请根据 通过集群安装程序尝试 kube-router 指南安装 kube-router 插件。
在你安装了 kube-router 插件后,可以参考 声明网络策略 去尝试使用 Kubernetes NetworkPolicy。
本页展示如何使用 Romana 作为 NetworkPolicy。
完成 kubeadm 入门指南中的 1、2、3 步。
按照容器化安装指南, 使用 kubeadm 安装。
使用以下的一种方式应用网络策略:
Romana 安装完成后,你可以按照 声明网络策略 去尝试使用 Kubernetes NetworkPolicy。
本页展示如何使用 Weave Net 提供 NetworkPolicy。
你需要拥有一个 Kubernetes 集群。按照 kubeadm 入门指南 来启动一个。
按照通过插件集成 Kubernetes 指南执行安装。
Kubernetes 的 Weave Net 插件带有
网络策略控制器,
可自动监控 Kubernetes 所有名字空间的 NetworkPolicy 注释,
配置 iptables 规则以允许或阻止策略指示的流量。
验证 weave 是否有效。
输入以下命令:
kubectl get pods -n kube-system -o wide
输出类似这样:
NAME READY STATUS RESTARTS AGE IP NODE
weave-net-1t1qg 2/2 Running 0 9d 192.168.2.10 worknode3
weave-net-231d7 2/2 Running 1 7d 10.2.0.17 worknodegpu
weave-net-7nmwt 2/2 Running 3 9d 192.168.2.131 masternode
weave-net-pmw8w 2/2 Running 0 9d 192.168.2.216 worknode2
每个 Node 都有一个 weave Pod,所有 Pod 都是 Running 和 2/2 READY。
(2/2 表示每个 Pod 都有 weave 和 weave-npc。)
安装 Weave Net 插件后,你可以参考 声明网络策略 来试用 Kubernetes NetworkPolicy。 如果你有任何疑问,请通过 Slack 上的 #weave-community 频道或者 Weave 用户组 联系我们。
本页展示了如何使用 Kubernetes API 访问集群。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
首次访问 Kubernetes API 时,请使用 Kubernetes 命令行工具 kubectl。
要访问集群,你需要知道集群位置并拥有访问它的凭证。 通常,当你完成入门指南时,这会自动设置完成,或者由其他人设置好集群并将凭证和位置提供给你。
使用此命令检查 kubectl 已知的位置和凭证:
kubectl config view
许多样例 提供了使用 kubectl 的介绍。完整文档请见 kubectl 手册。
kubectl 处理对 API 服务器的定位和身份验证。如果你想通过 http 客户端(如 curl、wget
或浏览器)直接访问 REST API,你可以通过多种方式对 API 服务器进行定位和身份验证:
使用 Go 或 Python 客户端库可以在代理模式下访问 kubectl。
下列命令使 kubectl 运行在反向代理模式下。它处理 API 服务器的定位和身份认证。
像这样运行它:
kubectl proxy --port=8080 &
参见 kubectl 代理 获取更多细节。
然后你可以通过 curl,wget,或浏览器浏览 API,像这样:
curl http://localhost:8080/api/
输出类似如下:
{
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
通过将身份认证令牌直接传给 API 服务器,可以避免使用 kubectl 代理,像这样:
使用 grep/cut 方式:
# 查看所有的集群,因为你的 .kubeconfig 文件中可能包含多个上下文
kubectl config view -o jsonpath='{"Cluster name\tServer\n"}{range .clusters[*]}{.name}{"\t"}{.cluster.server}{"\n"}{end}'
# 从上述命令输出中选择你要与之交互的集群的名称
export CLUSTER_NAME="some_server_name"
# 指向引用该集群名称的 API 服务器
APISERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name==\"$CLUSTER_NAME\")].cluster.server}")
# 创建一个 secret 来保存默认服务账户的令牌
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: default-token
annotations:
kubernetes.io/service-account.name: default
type: kubernetes.io/service-account-token
EOF
# 等待令牌控制器使用令牌填充 secret:
while ! kubectl describe secret default-token | grep -E '^token' >/dev/null; do
echo "waiting for token..." >&2
sleep 1
done
# 获取令牌
TOKEN=$(kubectl get secret default-token -o jsonpath='{.data.token}' | base64 --decode)
# 使用令牌玩转 API
curl -X GET $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
输出类似如下:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
上面例子使用了 --insecure 标志位。这使它易受到 MITM 攻击。
当 kubectl 访问集群时,它使用存储的根证书和客户端证书访问服务器。
(已安装在 ~/.kube 目录下)。
由于集群认证通常是自签名的,因此可能需要特殊设置才能让你的 http 客户端使用根证书。
在一些集群中,API 服务器不需要身份认证;它运行在本地,或由防火墙保护着。 对此并没有一个标准。 配置对 API 的访问 讲解了作为集群管理员可如何对此进行配置。
Kubernetes 官方支持 Go、Python、Java、 dotnet、JavaScript 和 Haskell 语言的客户端库。还有一些其他客户端库由对应作者而非 Kubernetes 团队提供并维护。 参考客户端库了解如何使用其他语言来访问 API 以及如何执行身份认证。
go get k8s.io/client-go/kubernetes-<kubernetes 版本号>,
参见 https://github.com/kubernetes/client-go/releases
查看受支持的版本。client-go 定义了自己的 API 对象,因此如果需要,从 client-go 而不是主仓库导入
API 定义,例如 import "k8s.io/client-go/kubernetes" 是正确做法。
Go 客户端可以使用与 kubectl 命令行工具相同的 kubeconfig 文件 定位和验证 API 服务器。参见这个 例子:
package main
import (
"context"
"fmt"
"k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
// 在 kubeconfig 中使用当前上下文
// path-to-kubeconfig -- 例如 /root/.kube/config
config, _ := clientcmd.BuildConfigFromFlags("", "<path-to-kubeconfig>")
// 创建 clientset
clientset, _ := kubernetes.NewForConfig(config)
// 访问 API 以列出 Pod
pods, _ := clientset.CoreV1().Pods("").List(context.TODO(), v1.ListOptions{})
fmt.Printf("There are %d pods in the cluster\n", len(pods.Items))
}
如果该应用程序部署为集群中的一个 Pod,请参阅从 Pod 内访问 API。
要使用 Python 客户端,运行下列命令:
pip install kubernetes。
参见 Python 客户端库主页了解更多安装选项。
Python 客户端可以使用与 kubectl 命令行工具相同的 kubeconfig 文件 定位和验证 API 服务器。参见这个 例子:
from kubernetes import client, config
config.load_kube_config()
v1=client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
要安装 Java 客户端,运行:
# 克隆 Java 库
git clone --recursive https://github.com/kubernetes-client/java
# 安装项目文件、POM 等
cd java
mvn install
参阅 https://github.com/kubernetes-client/java/releases 了解当前支持的版本。
Java 客户端可以使用 kubectl 命令行所使用的 kubeconfig 文件 以定位 API 服务器并向其认证身份。 参看此示例:
package io.kubernetes.client.examples;
import io.kubernetes.client.ApiClient;
import io.kubernetes.client.ApiException;
import io.kubernetes.client.Configuration;
import io.kubernetes.client.apis.CoreV1Api;
import io.kubernetes.client.models.V1Pod;
import io.kubernetes.client.models.V1PodList;
import io.kubernetes.client.util.ClientBuilder;
import io.kubernetes.client.util.KubeConfig;
import java.io.FileReader;
import java.io.IOException;
/**
* A simple example of how to use the Java API from an application outside a kubernetes cluster
*
* <p>Easiest way to run this: mvn exec:java
* -Dexec.mainClass="io.kubernetes.client.examples.KubeConfigFileClientExample"
*
*/
public class KubeConfigFileClientExample {
public static void main(String[] args) throws IOException, ApiException {
// file path to your KubeConfig
String kubeConfigPath = "~/.kube/config";
// loading the out-of-cluster config, a kubeconfig from file-system
ApiClient client =
ClientBuilder.kubeconfig(KubeConfig.loadKubeConfig(new FileReader(kubeConfigPath))).build();
// set the global default api-client to the in-cluster one from above
Configuration.setDefaultApiClient(client);
// the CoreV1Api loads default api-client from global configuration.
CoreV1Api api = new CoreV1Api();
// invokes the CoreV1Api client
V1PodList list = api.listPodForAllNamespaces(null, null, null, null, null, null, null, null, null);
System.out.println("Listing all pods: ");
for (V1Pod item : list.getItems()) {
System.out.println(item.getMetadata().getName());
}
}
}
要使用 .Net 客户端,运行下面的命令:
dotnet add package KubernetesClient --version 1.6.1。
参见 .Net 客户端库页面了解更多安装选项。
关于可支持的版本,参见https://github.com/kubernetes-client/csharp/releases。
.Net 客户端可以使用与 kubectl CLI 相同的 kubeconfig 文件来定位并验证 API 服务器。 参见样例:
using System;
using k8s;
namespace simple
{
internal class PodList
{
private static void Main(string[] args)
{
var config = KubernetesClientConfiguration.BuildDefaultConfig();
IKubernetes client = new Kubernetes(config);
Console.WriteLine("Starting Request!");
var list = client.ListNamespacedPod("default");
foreach (var item in list.Items)
{
Console.WriteLine(item.Metadata.Name);
}
if (list.Items.Count == 0)
{
Console.WriteLine("Empty!");
}
}
}
}
要安装 JavaScript 客户端,运行下面的命令:
npm install @kubernetes/client-node。
参考https://github.com/kubernetes-client/javascript/releases了解可支持的版本。
JavaScript 客户端可以使用 kubectl 命令行所使用的 kubeconfig 文件 以定位 API 服务器并向其认证身份。 参见此例:
const k8s = require('@kubernetes/client-node');
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.CoreV1Api);
k8sApi.listNamespacedPod('default').then((res) => {
console.log(res.body);
});
参考 https://github.com/kubernetes-client/haskell/releases 了解支持的版本。
Haskell 客户端 可以使用 kubectl 命令行所使用的 kubeconfig 文件 以定位 API 服务器并向其认证身份。 参见此例:
exampleWithKubeConfig :: IO ()
exampleWithKubeConfig = do
oidcCache <- atomically $ newTVar $ Map.fromList []
(mgr, kcfg) <- mkKubeClientConfig oidcCache $ KubeConfigFile "/path/to/kubeconfig"
dispatchMime
mgr
kcfg
(CoreV1.listPodForAllNamespaces (Accept MimeJSON))
>>= print
本文展示了如何为节点指定扩展资源(Extended Resource)。 扩展资源允许集群管理员发布节点级别的资源,这些资源在不进行发布的情况下无法被 Kubernetes 感知。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
kubectl get nodes
选择一个节点用于此练习。
为在一个节点上发布一种新的扩展资源,需要发送一个 HTTP PATCH 请求到 Kubernetes API server。 例如:假设你的一个节点上带有四个 dongle 资源。 下面是一个 PATCH 请求的示例,该请求为你的节点发布四个 dongle 资源。
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "add",
"path": "/status/capacity/example.com~1dongle",
"value": "4"
}
]
注意:Kubernetes 不需要了解 dongle 资源的含义和用途。 前面的 PATCH 请求告诉 Kubernetes 你的节点拥有四个你称之为 dongle 的东西。
启动一个代理(proxy),以便你可以很容易地向 Kubernetes API server 发送请求:
kubectl proxy
在另一个命令窗口中,发送 HTTP PATCH 请求。 用你的节点名称替换 <your-node-name>:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
在前面的请求中,~1 为 patch 路径中 “/” 符号的编码。
JSON-Patch 中的操作路径值被解析为 JSON 指针。
更多细节,请查看 IETF RFC 6901 的第 3 节。
输出显示该节点的 dongle 资源容量(capacity)为 4:
"capacity": {
"cpu": "2",
"memory": "2049008Ki",
"example.com/dongle": "4",
描述你的节点:
kubectl describe node <your-node-name>
输出再次展示了 dongle 资源:
Capacity:
cpu: 2
memory: 2049008Ki
example.com/dongle: 4
现在,应用开发者可以创建请求一定数量 dongle 资源的 Pod 了。 参见将扩展资源分配给容器。
扩展资源类似于内存和 CPU 资源。例如,正如一个节点拥有一定数量的内存和 CPU 资源, 它们被节点上运行的所有组件共享,该节点也可以拥有一定数量的 dongle 资源, 这些资源同样被节点上运行的所有组件共享。 此外,正如应用开发者可以创建请求一定数量的内存和 CPU 资源的 Pod, 他们也可以创建请求一定数量 dongle 资源的 Pod。
扩展资源对 Kubernetes 是不透明的。Kubernetes 不知道扩展资源含义相关的任何信息。 Kubernetes 只了解一个节点拥有一定数量的扩展资源。 扩展资源必须以整形数量进行发布。 例如,一个节点可以发布 4 个 dongle 资源,但是不能发布 4.5 个。
假设一个节点拥有一种特殊类型的磁盘存储,其容量为 800 GiB。
你可以为该特殊存储创建一个名称,如 example.com/special-storage。
然后你就可以按照一定规格的块(如 100 GiB)对其进行发布。
在这种情况下,你的节点将会通知它拥有八个 example.com/special-storage 类型的资源。
Capacity:
...
example.com/special-storage: 8
如果你想要允许针对特殊存储任意(数量)的请求,你可以按照 1 字节大小的块来发布特殊存储。 在这种情况下,你将会发布 800Gi 数量的 example.com/special-storage 类型的资源。
Capacity:
...
example.com/special-storage: 800Gi
然后,容器就能够请求任意数量(多达 800Gi)字节的特殊存储。
Capacity:
...
example.com/special-storage: 800Gi
这里是一个从节点移除 dongle 资源发布的 PATCH 请求。
PATCH /api/v1/nodes/<your-node-name>/status HTTP/1.1
Accept: application/json
Content-Type: application/json-patch+json
Host: k8s-master:8080
[
{
"op": "remove",
"path": "/status/capacity/example.com~1dongle",
}
]
启动一个代理,以便你可以很容易地向 Kubernetes API 服务器发送请求:
kubectl proxy
在另一个命令窗口中,发送 HTTP PATCH 请求。用你的节点名称替换 <your-node-name>:
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "remove", "path": "/status/capacity/example.com~1dongle"}]' \
http://localhost:8001/api/v1/nodes/<your-node-name>/status
验证 dongle 资源的发布已经被移除:
kubectl describe node <your-node-name> | grep dongle
(你应该看不到任何输出)
本页展示了如何在你的 Kubernetes 集群中启用和配置 DNS 服务的自动扩缩功能。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
本指南假设你的节点使用 AMD64 或 Intel 64 CPU 架构
确保 Kubernetes DNS 已启用。
在 kube-system 命名空间中列出集群中的 Deployment:
kubectl get deployment --namespace=kube-system
输出类似如下这样:
NAME READY UP-TO-DATE AVAILABLE AGE
...
kube-dns-autoscaler 1/1 1 1 ...
...
如果在输出中看到 “kube-dns-autoscaler”,说明 DNS 水平自动扩缩已经启用, 可以跳到调优 DNS 自动扩缩参数。
列出集群内 kube-system 命名空间中的 DNS Deployment:
kubectl get deployment -l k8s-app=kube-dns --namespace=kube-system
输出类似如下这样:
NAME READY UP-TO-DATE AVAILABLE AGE
...
coredns 2/2 2 2 ...
...
如果看不到 DNS 服务的 Deployment,你也可以通过名字来查找:
kubectl get deployment --namespace=kube-system
并在输出中寻找名称为 coredns 或 kube-dns 的 Deployment。
你的扩缩目标为:
Deployment/<your-deployment-name>
其中 <your-deployment-name> 是 DNS Deployment 的名称。
例如,如果你的 DNS Deployment 名称是 coredns,则你的扩展目标是 Deployment/coredns。
CoreDNS 是 Kubernetes 的默认 DNS 服务。CoreDNS 设置标签 k8s-app=kube-dns,
以便能够在原来使用 kube-dns 的集群中工作。
在本节,我们创建一个新的 Deployment。Deployment 中的 Pod 运行一个基于
cluster-proportional-autoscaler-amd64 镜像的容器。
创建文件 dns-horizontal-autoscaler.yaml,内容如下所示:
kind: ServiceAccount
apiVersion: v1
metadata:
name: kube-dns-autoscaler
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-dns-autoscaler
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["replicationcontrollers/scale"]
verbs: ["get", "update"]
- apiGroups: ["apps"]
resources: ["deployments/scale", "replicasets/scale"]
verbs: ["get", "update"]
# 待以下 issue 修复后,请删除 Configmaps
# kubernetes-incubator/cluster-proportional-autoscaler#16
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: system:kube-dns-autoscaler
subjects:
- kind: ServiceAccount
name: kube-dns-autoscaler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-dns-autoscaler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-dns-autoscaler
namespace: kube-system
labels:
k8s-app: kube-dns-autoscaler
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: kube-dns-autoscaler
template:
metadata:
labels:
k8s-app: kube-dns-autoscaler
spec:
priorityClassName: system-cluster-critical
securityContext:
seccompProfile:
type: RuntimeDefault
supplementalGroups: [ 65534 ]
fsGroup: 65534
nodeSelector:
kubernetes.io/os: linux
containers:
- name: autoscaler
image: registry.k8s.io/cpa/cluster-proportional-autoscaler:1.8.4
resources:
requests:
cpu: "20m"
memory: "10Mi"
command:
- /cluster-proportional-autoscaler
- --namespace=kube-system
- --configmap=kube-dns-autoscaler
# 应该保持目标与 cluster/addons/dns/kube-dns.yaml.base 同步。
- --target=<SCALE_TARGET>
# 当集群使用大节点(有更多核)时,“coresPerReplica”应该占主导地位。
# 如果使用小节点,“nodesPerReplica“ 应该占主导地位。
- --default-params={"linear":{"coresPerReplica":256,"nodesPerReplica":16,"preventSinglePointFailure":true,"includeUnschedulableNodes":true}}
- --logtostderr=true
- --v=2
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
serviceAccountName: kube-dns-autoscaler
在此文件中,将 <SCALE_TARGET> 替换成扩缩目标。
进入到包含配置文件的目录中,输入如下命令创建 Deployment:
kubectl apply -f dns-horizontal-autoscaler.yaml
命令成功执行后的输出为:
deployment.apps/kube-dns-autoscaler created
DNS 水平自动扩缩现在已经启用了。
验证 kube-dns-autoscaler ConfigMap 是否存在:
kubectl get configmap --namespace=kube-system
输出类似于:
NAME DATA AGE
...
kube-dns-autoscaler 1 ...
...
修改此 ConfigMap 中的数据:
kubectl edit configmap kube-dns-autoscaler --namespace=kube-system
找到如下这行内容:
linear: '{"coresPerReplica":256,"min":1,"nodesPerReplica":16}'
根据需要修改对应的字段。“min” 字段表明 DNS 后端的最小数量。 实际后端的数量通过使用如下公式来计算:
replicas = max( ceil( cores × 1/coresPerReplica ) , ceil( nodes × 1/nodesPerReplica ) )
注意 coresPerReplica 和 nodesPerReplica 的值都是浮点数。
背后的思想是,当一个集群使用具有很多核心的节点时,由 coresPerReplica 来控制。
当一个集群使用具有较少核心的节点时,由 nodesPerReplica 来控制。
其它的扩缩模式也是支持的,详情查看 cluster-proportional-autoscaler。
有几个可供调优的 DNS 水平自动扩缩选项。具体使用哪个选项因环境而异。
此选项适用于所有场景。运行如下命令:
kubectl scale deployment --replicas=0 kube-dns-autoscaler --namespace=kube-system
输出如下所示:
deployment.apps/kube-dns-autoscaler scaled
验证当前副本数为 0:
kubectl get rs --namespace=kube-system
输出内容中,在 DESIRED 和 CURRENT 列显示为 0:
NAME DESIRED CURRENT READY AGE
...
kube-dns-autoscaler-6b59789fc8 0 0 0 ...
...
如果 kube-dns-autoscaler 为你所控制,也就说没有人会去重新创建它,可以选择此选项:
kubectl delete deployment kube-dns-autoscaler --namespace=kube-system
输出内容如下所示:
deployment.apps "kube-dns-autoscaler" deleted
如果 kube-dns-autoscaler 在插件管理器 的控制之下,并且具有操作主控节点的写权限,可以使用此选项。
登录到主控节点,删除对应的清单文件。 kube-dns-autoscaler 对应的路径一般为:
/etc/kubernetes/addons/dns-horizontal-autoscaler/dns-horizontal-autoscaler.yaml
当清单文件被删除后,插件管理器将删除 kube-dns-autoscaler Deployment。
cluster-proportional-autoscaler 应用独立于 DNS 服务部署。
autoscaler Pod 运行一个客户端,它通过轮询 Kubernetes API 服务器获取集群中节点和核心的数量。
系统会基于当前可调度的节点个数、核心数以及所给的扩缩参数,计算期望的副本数并应用到 DNS 后端。
扩缩参数和数据点会基于一个 ConfigMap 来提供给 autoscaler,它会在每次轮询时刷新它的参数表, 以与最近期望的扩缩参数保持一致。
扩缩参数是可以被修改的,而且不需要重建或重启 autoscaler Pod。
autoscaler 提供了一个控制器接口来支持两种控制模式:linear 和 ladder。
Kubernetes v1.27 [beta]
本页展示了如何迁移节点以使用基于事件的更新来获取容器状态。 与依赖轮询的传统方法相比,基于事件的实现可以减少 kubelet 对节点资源的消耗。 你可以将这个特性称为事件驱动的 Pod 生命周期事件生成器 (PLEG)。 这是在 Kubernetes 项目内部针对关键实现细节所用的名称。
基于轮询的方法称为通用 PLEG。
kubectl version.
如果你正在运行不同版本的 Kubernetes,请查阅对应版本的文档。EventedPLEG 后启动 kubelet。
你可以通过编辑 kubelet 配置文件并重启
kubelet 服务来管理 kubelet 特性门控。
你需要在使用此特性的所有节点上执行此操作。确保节点被腾空后再继续。
启用容器事件生成后启动容器运行时。
版本 1.7+
版本 1.26+
通过验证配置,检查 CRI-O 是否已配置为发送 CRI 事件:
crio config | grep enable_pod_events
如果已启用,输出应类似于:
enable_pod_events = true
要启用它,可使用 --enable-pod-events=true 标志或添加以下配置来启动 CRI-O 守护进程:
[crio.runtime]
enable_pod_events: true
kubectl version.
确认 kubelet 正使用基于事件的容器阶段变更监控。
要检查这一点,可在 kubelet 日志中查找 EventedPLEG 词条。
输出类似于:
I0314 11:10:13.909915 1105457 feature_gate.go:249] feature gates: &{map[EventedPLEG:true]}
如果你将 --v 设置为 4 及更高值,你可能会看到更多条目表明
kubelet 正在使用基于事件的容器状态监控。
I0314 11:12:42.009542 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=3b2c6172-b112-447a-ba96-94e7022912dc
I0314 11:12:44.623326 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=b3fba5ea-a8c5-4b76-8f43-481e17e8ec40
I0314 11:12:44.714564 1110177 evented.go:238] "Evented PLEG: Generated pod status from the received event" podUID=b3fba5ea-a8c5-4b76-8f43-481e17e8ec40
本文展示了如何改变默认的 Storage Class,它用于为没有特殊需求的 PersistentVolumeClaims 配置 volumes。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
取决于安装模式,你的 Kubernetes 集群可能和一个被标记为默认的已有 StorageClass 一起部署。 这个默认的 StorageClass 以后将被用于动态的为没有特定存储类需求的 PersistentVolumeClaims 配置存储。更多细节请查看 PersistentVolumeClaim 文档。
预先安装的默认 StorageClass 可能不能很好的适应你期望的工作负载;例如,它配置的存储可能太过昂贵。 如果是这样的话,你可以改变默认 StorageClass,或者完全禁用它以防止动态配置存储。
删除默认 StorageClass 可能行不通,因为它可能会被你集群中的扩展管理器自动重建。 请查阅你的安装文档中关于扩展管理器的细节,以及如何禁用单个扩展。
列出你的集群中的 StorageClass:
kubectl get storageclass
输出类似这样:
NAME PROVISIONER AGE
standard (default) kubernetes.io/gce-pd 1d
gold kubernetes.io/gce-pd 1d
默认 StorageClass 以 (default) 标记。
标记默认 StorageClass 非默认:
默认 StorageClass 的注解 storageclass.kubernetes.io/is-default-class 设置为 true。
注解的其它任意值或者缺省值将被解释为 false。
要标记一个 StorageClass 为非默认的,你需要改变它的值为 false:
kubectl patch storageclass standard -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
这里的 standard 是你选择的 StorageClass 的名字。
标记一个 StorageClass 为默认的:
和前面的步骤类似,你需要添加/设置注解 storageclass.kubernetes.io/is-default-class=true。
kubectl patch storageclass <your-class-name> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
请注意,最多只能有一个 StorageClass 能够被标记为默认。 如果它们中有两个或多个被标记为默认,Kubernetes 将忽略这个注解, 也就是它将表现为没有默认 StorageClass。
验证你选用的 StorageClass 为默认的:
kubectl get storageclass
输出类似这样:
NAME PROVISIONER AGE
standard kubernetes.io/gce-pd 1d
gold (default) kubernetes.io/gce-pd 1d
本文展示了如何更改 Kubernetes PersistentVolume 的回收策略。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
PersistentVolumes 可以有多种回收策略,包括 "Retain"、"Recycle" 和 "Delete"。 对于动态配置的 PersistentVolumes 来说,默认回收策略为 "Delete"。 这表示当用户删除对应的 PersistentVolumeClaim 时,动态配置的 volume 将被自动删除。 如果 volume 包含重要数据时,这种自动行为可能是不合适的。 那种情况下,更适合使用 "Retain" 策略。 使用 "Retain" 时,如果用户删除 PersistentVolumeClaim,对应的 PersistentVolume 不会被删除。 相反,它将变为 Released 状态,表示所有的数据可以被手动恢复。
列出你集群中的 PersistentVolumes
kubectl get pv
输出类似于这样:
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 manual 10s
pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 manual 6s
pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim3 manual 3s
这个列表同样包含了绑定到每个卷的 claims 名称,以便更容易的识别动态配置的卷。
选择你的 PersistentVolumes 中的一个并更改它的回收策略:
kubectl patch pv <your-pv-name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
这里的 <your-pv-name> 是你选择的 PersistentVolume 的名字。
在 Windows 系统上,你必须对包含空格的 JSONPath 模板加双引号(而不是像上面 一样为 Bash 环境使用的单引号)。这也意味着你必须使用单引号或者转义的双引号 来处理模板中的字面值。例如:
kubectl patch pv <your-pv-name> -p "{\"spec\":{\"persistentVolumeReclaimPolicy\":\"Retain\"}}"
验证你选择的 PersistentVolume 拥有正确的策略:
kubectl get pv
输出类似于这样:
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-b6efd8da-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim1 manual 40s
pvc-b95650f8-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Delete Bound default/claim2 manual 36s
pvc-bb3ca71d-b7b5-11e6-9d58-0ed433a7dd94 4Gi RWO Retain Bound default/claim3 manual 33s
在前面的输出中,你可以看到绑定到申领 default/claim3 的卷的回收策略为 Retain。
当用户删除申领 default/claim3 时,它不会被自动删除。
.spec.persistentVolumeReclaimPolicy
字段。Kubernetes v1.11 [beta]
由于云驱动的开发和发布的步调与 Kubernetes 项目不同,将服务提供商专用代码抽象到
cloud-controller-manager
二进制中有助于云服务厂商在 Kubernetes 核心代码之外独立进行开发。
cloud-controller-manager 可以被链接到任何满足
cloudprovider.Interface
约束的云服务提供商。为了兼容旧版本,Kubernetes 核心项目中提供的
cloud-controller-manager
使用和 kube-controller-manager 相同的云服务类库。
已经在 Kubernetes 核心项目中支持的云服务提供商预计将通过使用 in-tree 的 cloud-controller-manager
过渡为非 Kubernetes 核心代码。
每个云服务都有一套各自的需求用于系统平台的集成,这不应与运行
kube-controller-manager 的需求有太大差异。作为经验法则,你需要:
你需要对集群配置做适当的修改以成功地运行云管理控制器:
kubelet、kube-apiserver 和 kube-controller-manager 必须根据用户对外部 CCM 的使用进行设置。
如果用户有一个外部的 CCM(不是 Kubernetes 控制器管理器中的内部云控制器回路),
那么必须添加 --cloud-provider=external 参数。否则,不应添加此参数。请记住,设置集群使用云管理控制器将用多种方式更改集群行为:
--cloud-provider=external 的组件将被添加一个 node.cloudprovider.kubernetes.io/uninitialized
的污点,导致其在初始化过程中不可调度(NoSchedule)。
这将标记该节点在能够正常调度前,需要外部的控制器进行二次初始化。
请注意,如果云管理控制器不可用,集群中的新节点会一直处于不可调度的状态。
这个污点很重要,因为调度器可能需要关于节点的云服务特定的信息,比如他们的区域或类型
(高端 CPU、GPU 支持、内存较大、临时实例等)。云管理控制器可以实现:
如果当前 Kubernetes 内核支持你使用的云服务,并且想要采用云管理控制器,请参见 kubernetes 内核中的云管理控制器。
对于不在 Kubernetes 核心代码库中的云管理控制器,你可以在云服务厂商或 SIG 领导者的源中找到对应的项目。
对于已经存在于 Kubernetes 内核中的提供商,你可以在集群中将 in-tree 云管理控制器作为守护进程运行。请使用如下指南:
# 这是一个如何将 cloud-controller-manager 安装为集群中的 Daemonset 的示例。
# 本例假定你的主控节点可以运行 pod 并具有角色 node-role.kubernetes.io/master
# 请注意,这里的 Daemonset 不能直接在你的云上工作,此例只是一个指导。
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:cloud-controller-manager
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: cloud-controller-manager
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: cloud-controller-manager
name: cloud-controller-manager
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: cloud-controller-manager
template:
metadata:
labels:
k8s-app: cloud-controller-manager
spec:
serviceAccountName: cloud-controller-manager
containers:
- name: cloud-controller-manager
# 对于树内驱动,我们使用 registry.k8s.io/cloud-controller-manager,
# 镜像可以替换为其他树外驱动的镜像
image: registry.k8s.io/cloud-controller-manager:v1.8.0
command:
- /usr/local/bin/cloud-controller-manager
- --cloud-provider=[YOUR_CLOUD_PROVIDER] # 在此处添加你自己的云驱动!
- --leader-elect=true
- --use-service-account-credentials
# 这些标志因每个云驱动而异
- --allocate-node-cidrs=true
- --configure-cloud-routes=true
- --cluster-cidr=172.17.0.0/16
tolerations:
# 这一设置是必需的,为了让 CCM 可以自行引导
- key: node.cloudprovider.kubernetes.io/uninitialized
value: "true"
effect: NoSchedule
# 这些容忍度使得守护进程能够在控制平面节点上运行
# 如果你的控制平面节点不应该运行 pod,请删除它们
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
# 这是为了限制 CCM 仅在主节点上运行
# 节点选择器可能因你的集群设置而异
nodeSelector:
node-role.kubernetes.io/master: ""
运行云管理控制器会有一些可能的限制。虽然以后的版本将处理这些限制,但是知道这些生产负载的限制很重要。
云管理控制器未实现 kube-controller-manager 中的任何 volume 控制器,
因为和 volume 的集成还需要与 kubelet 协作。由于我们引入了 CSI (容器存储接口,
container storage interface) 并对弹性 volume 插件添加了更强大的支持,
云管理控制器将添加必要的支持,以使云服务同 volume 更好的集成。
请在这里了解更多关于
out-of-tree CSI volume 插件的信息。
通过云管理控制器查询你的云提供商的 API 以检索所有节点的信息。 对于非常大的集群,请考虑可能的瓶颈,例如资源需求和 API 速率限制。
云管理控制器的目标是将云服务特性的开发从 Kubernetes 核心项目中解耦。 不幸的是,Kubernetes 项目的许多方面都假设云服务提供商的特性同项目紧密结合。 因此,这种新架构的采用可能导致某些场景下,当一个请求需要从云服务提供商获取信息时, 在该请求没有完成的情况下云管理控制器不能返回那些信息。
Kubelet 中的 TLS 引导特性是一个很好的例子。 目前,TLS 引导认为 kubelet 有能力从云提供商(或本地元数据服务)获取所有的地址类型(私有、公用等), 但在被初始化之前,云管理控制器不能设置节点地址类型,而这需要 kubelet 拥有 TLS 证书以和 API 服务器通信。
随着整个动议的演进,将来的发行版中将作出改变来解决这些问题。
要构建和开发你自己的云管理控制器,请阅读 开发云管理控制器 文档。
Kubernetes v1.26 [stable]
从 Kubernetes v1.20 开始,kubelet 可以使用 exec 插件动态获得针对某容器镜像库的凭据。 kubelet 使用 Kubernetes 版本化 API 通过标准输入输出(标准输入、标准输出和标准错误)和 exec 插件通信。这些插件允许 kubelet 动态请求容器仓库的凭据,而不是将静态凭据存储在磁盘上。 例如,插件可能会与本地元数据服务器通信,以获得 kubelet 正在拉取的镜像的短期凭据。
如果以下任一情况属实,你可能对此功能感兴趣:
本指南演示如何配置 kubelet 的镜像凭据提供程序插件机制。
kubectl version.
凭据提供程序插件是将由 kubelet 运行的可执行二进制文件。 你需要确保插件可执行文件存在于你的集群的每个节点上,并存储在已知目录中。 稍后配置 kubelet 标志需要该目录。
为了使用这个特性,kubelet 需要设置以下两个标志:
--image-credential-provider-config —— 凭据提供程序插件配置文件的路径。--image-credential-provider-bin-dir —— 凭据提供程序插件二进制可执行文件所在目录的路径。kubelet 会读取通过 --image-credential-provider-config 设定的配置文件,
以确定应该为哪些容器镜像调用哪些 exec 插件。
如果你正在使用基于 ECR-based 插件,
这里有个样例配置文件你可能最终会使用到:
apiVersion: kubelet.config.k8s.io/v1
kind: CredentialProviderConfig
# providers 是将由 kubelet 启用的凭据提供程序帮助插件列表。
# 多个提供程序可能与单个镜像匹配,在这种情况下,来自所有提供程序的凭据将返回到 kubelet。
# 如果为单个镜像调用了多个提供程序,则返回结果会被合并。
# 如果提供程序返回重叠的身份验证密钥,则使用提供程序列表中较早的值。
providers:
# name 是凭据提供程序的必需名称。
# 它必须与 kubelet 看到的提供程序可执行文件的名称相匹配。
# 可执行文件必须在 kubelet 的 bin 目录中
# (由 --image-credential-provider-bin-dir 标志设置)。
- name: ecr-credential-provider
# matchImages 是一个必需的字符串列表,用于匹配镜像以确定是否应调用此提供程序。
# 如果其中一个字符串与 kubelet 请求的镜像相匹配,则该插件将被调用并有机会提供凭据。
# 镜像应包含注册域和 URL 路径。
#
# matchImages 中的每个条目都是一个模式字符串,可以选择包含端口和路径。
# 可以在域中使用通配符,但不能在端口或路径中使用。
# 支持通配符作为子域(例如 "*.k8s.io" 或 "k8s.*.io")和顶级域(例如 "k8s.*")。
# 还支持匹配部分子域,如 "app*.k8s.io"。
# 每个通配符只能匹配一个子域段,因此 "*.io" **不** 匹配 "*.k8s.io"。
#
# 当以下所有条件都为真时,镜像和 matchImage 之间存在匹配:
#
# - 两者都包含相同数量的域部分并且每个部分都匹配。
# - matchImages 的 URL 路径必须是目标镜像 URL 路径的前缀。
# - 如果 matchImages 包含端口,则该端口也必须在镜像中匹配。
#
# matchImages 的示例值:
#
# - 123456789.dkr.ecr.us-east-1.amazonaws.com
# - *.azurecr.io
# - gcr.io
# - *.*.registry.io
# - registry.io:8080/path
matchImages:
- "*.dkr.ecr.*.amazonaws.com"
- "*.dkr.ecr.*.amazonaws.com.cn"
- "*.dkr.ecr-fips.*.amazonaws.com"
- "*.dkr.ecr.us-iso-east-1.c2s.ic.gov"
- "*.dkr.ecr.us-isob-east-1.sc2s.sgov.gov"
# defaultCacheDuration 是插件将在内存中缓存凭据的默认持续时间。
# 如果插件响应中未提供缓存持续时间。此字段是必需的。
defaultCacheDuration: "12h"
# exec CredentialProviderRequest 的必需输入版本。
# 返回的 CredentialProviderResponse 必须使用与输入相同的编码版本。当前支持的值为:
# - credentialprovider.kubelet.k8s.io/v1
apiVersion: credentialprovider.kubelet.k8s.io/v1
# 执行命令时传递给命令的参数。
# 可选
# args:
# - --example-argument
# env 定义了额外的环境变量以暴露给进程。
# 这些与主机环境以及 client-go 用于将参数传递给插件的变量结合在一起。
# 可选
env:
- name: AWS_PROFILE
value: example_profile
providers 字段是 kubelet 所使用的已启用插件列表。每个条目都有几个必填字段:
name:插件的名称,必须与传入 --image-credential-provider-bin-dir
的目录中存在的可执行二进制文件的名称相匹配。matchImages:字符串列表,用于匹配镜像以确定是否应调用此提供程序。
更多相关信息参见后文。defaultCacheDuration:如果插件未指定缓存时长,kubelet 将在内存中缓存凭据的默认时长。apiVersion:kubelet 和 exec 插件在通信时将使用的 API 版本。每个凭据提供程序也可以被赋予可选的参数和环境变量。 你可以咨询插件实现者以确定给定插件需要哪些参数和环境变量集。
kubelet 使用每个凭据提供程序的 matchImages 字段来确定是否应该为 Pod
正在使用的给定镜像调用插件。
matchImages 中的每个条目都是一个镜像模式字符串,可以选择包含端口和路径。
可以在域中使用通配符,但不能在端口或路径中使用。
支持通配符作为子域,如 *.k8s.io 或 k8s.*.io,以及顶级域,如 k8s.*。
还支持匹配部分子域,如 app*.k8s.io。每个通配符只能匹配一个子域段,
因此 *.io 不匹配 *.k8s.io。
当以下条件全部满足时,镜像名称和 matchImage 条目之间存在匹配:
matchImages 模式的一些示例值:
123456789.dkr.ecr.us-east-1.amazonaws.com*.azurecr.iogcr.io*.*.registry.iofoo.registry.io:8080/pathCredentialProviderConfig 的详细信息。本文讨论如何为 API 对象配置配额,包括 PersistentVolumeClaim 和 Service。 配额限制了可以在命名空间中创建的特定类型对象的数量。 你可以在 ResourceQuota 对象中指定配额。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
创建一个命名空间以便本例中创建的资源和集群中的其余部分相隔离。
kubectl create namespace quota-object-example
下面是一个 ResourceQuota 对象的配置文件:
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-quota-demo
spec:
hard:
persistentvolumeclaims: "1"
services.loadbalancers: "2"
services.nodeports: "0"
创建 ResourceQuota:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects.yaml --namespace=quota-object-example
查看 ResourceQuota 的详细信息:
kubectl get resourcequota object-quota-demo --namespace=quota-object-example --output=yaml
输出结果表明在 quota-object-example 命名空间中,至多只能有一个 PersistentVolumeClaim, 最多两个 LoadBalancer 类型的服务,不能有 NodePort 类型的服务。
status:
hard:
persistentvolumeclaims: "1"
services.loadbalancers: "2"
services.nodeports: "0"
used:
persistentvolumeclaims: "0"
services.loadbalancers: "0"
services.nodeports: "0"
下面是一个 PersistentVolumeClaim 对象的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-quota-demo
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
创建 PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects-pvc.yaml --namespace=quota-object-example
确认已创建完 PersistentVolumeClaim:
kubectl get persistentvolumeclaims --namespace=quota-object-example
输出信息表明 PersistentVolumeClaim 存在并且处于 Pending 状态:
NAME STATUS
pvc-quota-demo Pending
下面是第二个 PersistentVolumeClaim 的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-quota-demo-2
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi
尝试创建第二个 PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/admin/resource/quota-objects-pvc-2.yaml --namespace=quota-object-example
输出信息表明第二个 PersistentVolumeClaim 没有创建成功,因为这会超出命名空间的配额。
persistentvolumeclaims "pvc-quota-demo-2" is forbidden:
exceeded quota: object-quota-demo, requested: persistentvolumeclaims=1,
used: persistentvolumeclaims=1, limited: persistentvolumeclaims=1
下面这些字符串可被用来标识那些能被配额限制的 API 资源:
| 字符串 | API 对象 |
|---|---|
| "pods" | Pod |
| "services" | Service |
| "replicationcontrollers" | ReplicationController |
| "resourcequotas" | ResourceQuota |
| "secrets" | Secret |
| "configmaps" | ConfigMap |
| "persistentvolumeclaims" | PersistentVolumeClaim |
| "services.nodeports" | NodePort 类型的 Service |
| "services.loadbalancers" | LoadBalancer 类型的 Service |
删除你的命名空间:
kubectl delete namespace quota-object-example
Kubernetes v1.26 [stable]
按照设计,Kubernetes 对 Pod 执行相关的很多方面进行了抽象,使得用户不必关心。 然而,为了正常运行,有些工作负载要求在延迟和/或性能方面有更强的保证。 为此,kubelet 提供方法来实现更复杂的负载放置策略,同时保持抽象,避免显式的放置指令。
有关资源管理的详细信息, 请参阅 Pod 和容器的资源管理文档。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.26. 要获知版本信息,请输入kubectl version.
如果你正在运行一个旧版本的 Kubernetes,请参阅与该版本对应的文档。
默认情况下,kubelet 使用 CFS 配额 来执行 Pod 的 CPU 约束。 当节点上运行了很多 CPU 密集的 Pod 时,工作负载可能会迁移到不同的 CPU 核, 这取决于调度时 Pod 是否被扼制,以及哪些 CPU 核是可用的。 许多工作负载对这种迁移不敏感,因此无需任何干预即可正常工作。
然而,有些工作负载的性能明显地受到 CPU 缓存亲和性以及调度延迟的影响。 对此,kubelet 提供了可选的 CPU 管理策略,来确定节点上的一些分配偏好。
CPU 管理策略通过 kubelet 参数 --cpu-manager-policy
或 KubeletConfiguration
中的 cpuManagerPolicy 字段来指定。
支持两种策略:
CPU 管理器定期通过 CRI 写入资源更新,以保证内存中 CPU 分配与 cgroupfs 一致。
同步频率通过新增的 Kubelet 配置参数 --cpu-manager-reconcile-period 来设置。
如果不指定,默认与 --node-status-update-frequency 的周期相同。
Static 策略的行为可以使用 --cpu-manager-policy-options 参数来微调。
该参数采用一个逗号分隔的 key=value 策略选项列表。
如果你禁用 CPUManagerPolicyOptions
特性门控,
则你不能微调 CPU 管理器策略。这种情况下,CPU 管理器仅使用其默认设置运行。
除了顶级的 CPUManagerPolicyOptions 特性门控,
策略选项分为两组:Alpha 质量(默认隐藏)和 Beta 质量(默认可见)。
这些组分别由 CPUManagerPolicyAlphaOptions 和 CPUManagerPolicyBetaOptions 特性门控来管控。
不同于 Kubernetes 标准,这里是由这些特性门控来管控选项组,因为为每个单独选项都添加一个特性门控过于繁琐。
由于 CPU 管理器策略只能在 kubelet 生成新 Pod 时应用,所以简单地从 "none" 更改为 "static" 将不会对现有的 Pod 起作用。 因此,为了正确更改节点上的 CPU 管理器策略,请执行以下步骤:
/var/lib/kubelet/cpu_manager_state。
这将清除 CPUManager 维护的状态,以便新策略设置的 cpu-sets 不会与之冲突。对需要更改其 CPU 管理器策略的每个节点重复此过程。 跳过此过程将导致 kubelet crashlooping 并出现以下错误:
could not restore state from checkpoint: configured policy "static" differs from state checkpoint policy "none", please drain this node and delete the CPU manager checkpoint file "/var/lib/kubelet/cpu_manager_state" before restarting Kubelet
none 策略显式地启用现有的默认 CPU 亲和方案,不提供操作系统调度器默认行为之外的亲和性策略。
通过 CFS 配额来实现 Guaranteed Pods
和 Burstable Pods
的 CPU 使用限制。
static 策略针对具有整数型 CPU requests 的 Guaranteed Pod,
它允许该类 Pod 中的容器访问节点上的独占 CPU 资源。这种独占性是使用
cpuset cgroup 控制器来实现的。
诸如容器运行时和 kubelet 本身的系统服务可以继续在这些独占 CPU 上运行。独占性仅针对其他 Pod。
CPU 管理器不支持运行时下线和上线 CPU。此外,如果节点上的在线 CPU 集合发生变化,
则必须驱逐节点上的 Pod,并通过删除 kubelet 根目录中的状态文件 cpu_manager_state
来手动重置 CPU 管理器。
此策略管理一个 CPU 共享池,该共享池最初包含节点上所有的 CPU 资源。
可独占性 CPU 资源数量等于节点的 CPU 总量减去通过 kubelet --kube-reserved 或 --system-reserved
参数保留的 CPU 资源。
从 1.17 版本开始,可以通过 kubelet --reserved-cpus 参数显式地指定 CPU 预留列表。
由 --reserved-cpus 指定的显式 CPU 列表优先于由 --kube-reserved 和 --system-reserved
指定的 CPU 预留。
通过这些参数预留的 CPU 是以整数方式,按物理核心 ID 升序从初始共享池获取的。
共享池是 BestEffort 和 Burstable Pod 运行的 CPU 集合。
Guaranteed Pod 中的容器,如果声明了非整数值的 CPU requests,也将运行在共享池的 CPU 上。
只有 Guaranteed Pod 中,指定了整数型 CPU requests 的容器,才会被分配独占 CPU 资源。
当启用 static 策略时,要求使用 --kube-reserved 和/或 --system-reserved 或
--reserved-cpus 来保证预留的 CPU 值大于零。
这是因为零预留 CPU 值可能使得共享池变空。
当 Guaranteed Pod 调度到节点上时,如果其容器符合静态分配要求,
相应的 CPU 会被从共享池中移除,并放置到容器的 cpuset 中。
因为这些容器所使用的 CPU 受到调度域本身的限制,所以不需要使用 CFS 配额来进行 CPU 的绑定。
换言之,容器 cpuset 中的 CPU 数量与 Pod 规约中指定的整数型 CPU limit 相等。
这种静态分配增强了 CPU 亲和性,减少了 CPU 密集的工作负载在节流时引起的上下文切换。
考虑以下 Pod 规格的容器:
spec:
containers:
- name: nginx
image: nginx
该 Pod 属于 BestEffort QoS 类型,因为其未指定 requests 或 limits 值。
所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
该 Pod 属于 Burstable QoS 类型,因为其资源 requests 不等于 limits,且未指定 cpu 数量。
所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "100Mi"
cpu: "1"
该 Pod 属于 Burstable QoS 类型,因为其资源 requests 不等于 limits。
所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
该 Pod 属于 Guaranteed QoS 类型,因为其 requests 值与 limits相等。
同时,容器对 CPU 资源的限制值是一个大于或等于 1 的整数值。
所以,该 nginx 容器被赋予 2 个独占 CPU。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "1.5"
requests:
memory: "200Mi"
cpu: "1.5"
该 Pod 属于 Guaranteed QoS 类型,因为其 requests 值与 limits相等。
但是容器对 CPU 资源的限制值是一个小数。所以该容器运行在共享 CPU 池中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
该 Pod 属于 Guaranteed QoS 类型,因其指定了 limits 值,同时当未显式指定时,
requests 值被设置为与 limits 值相等。
同时,容器对 CPU 资源的限制值是一个大于或等于 1 的整数值。
所以,该 nginx 容器被赋予 2 个独占 CPU。
你可以使用以下特性门控根据成熟度级别打开或关闭选项组:
CPUManagerPolicyBetaOptions 默认启用。禁用以隐藏 beta 级选项。CPUManagerPolicyAlphaOptions 默认禁用。启用以显示 alpha 级选项。
你仍然必须使用 CPUManagerPolicyOptions kubelet 选项启用每个选项。静态 CPUManager 策略存在以下策略选项:
full-pcpus-only(Beta,默认可见)(1.22 或更高版本)distribute-cpus-across-numa(alpha,默认隐藏)(1.23 或更高版本)align-by-socket(Alpha,默认隐藏)(1.25 或更高版本)如果使用 full-pcpus-only 策略选项,static 策略总是会分配完整的物理核心。
默认情况下,如果不使用该选项,static 策略会使用拓扑感知最适合的分配方法来分配 CPU。
在启用了 SMT 的系统上,此策略所分配是与硬件线程对应的、独立的虚拟核。
这会导致不同的容器共享相同的物理核心,
该行为进而会导致吵闹的邻居问题。
启用该选项之后,只有当一个 Pod 里所有容器的 CPU 请求都能够分配到完整的物理核心时,
kubelet 才会接受该 Pod。
如果 Pod 没有被准入,它会被置于 Failed 状态,错误消息是 SMTAlignmentError。
如果使用 distribute-cpus-across-numa 策略选项,
在需要多个 NUMA 节点来满足分配的情况下,
static 策略会在 NUMA 节点上平均分配 CPU。
默认情况下,CPUManager 会将 CPU 分配到一个 NUMA 节点上,直到它被填满,
剩余的 CPU 会简单地溢出到下一个 NUMA 节点。
这会导致依赖于同步屏障(以及类似的同步原语)的并行代码出现不期望的瓶颈,
因为此类代码的运行速度往往取决于最慢的工作线程
(由于至少一个 NUMA 节点存在可用 CPU 较少的情况,因此速度变慢)。
通过在 NUMA 节点上平均分配 CPU,
应用程序开发人员可以更轻松地确保没有某个工作线程单独受到 NUMA 影响,
从而提高这些类型应用程序的整体性能。
如果指定了 align-by-socket 策略选项,那么在决定如何分配 CPU 给容器时,CPU 将被视为在 CPU 的插槽边界对齐。
默认情况下,CPUManager 在 NUMA 边界对齐 CPU 分配,如果需要从多个 NUMA 节点提取出 CPU 以满足分配,将可能会导致系统性能下降。
尽管 align-by-socket 策略试图确保从 NUMA 节点的最小数量分配所有 CPU,但不能保证这些 NUMA 节点将位于同一个 CPU 的插槽上。
通过指示 CPUManager 在 CPU 的插槽边界而不是 NUMA 边界显式对齐 CPU,我们能够避免此类问题。
注意,此策略选项不兼容 TopologyManager 与 single-numa-node 策略,并且不适用于 CPU 的插槽数量大于 NUMA 节点数量的硬件。
可以通过将 full-pcpus-only=true 添加到 CPUManager 策略选项来启用 full-pcpus-only 选项。
同样地,可以通过将 distribute-cpus-across-numa=true 添加到 CPUManager 策略选项来启用 distribute-cpus-across-numa 选项。
当两者都设置时,它们是“累加的”,因为 CPU 将分布在 NUMA 节点的 full-pcpus 块中,而不是单个核心。
可以通过将 align-by-socket=true 添加到 CPUManager 策略选项来启用 align-by-socket 策略选项。
同样,也能够将 distribute-cpus-across-numa=true 添加到 full-pcpus-only
和 distribute-cpus-across-numa 策略选项中。
Kubernetes v1.27 [beta]
越来越多的系统利用 CPU 和硬件加速器的组合来支持要求低延迟的任务和高吞吐量的并行计算。 这类负载包括电信、科学计算、机器学习、金融服务和数据分析等。 此类混合系统需要有高性能环境支持。
为了获得最佳性能,需要进行与 CPU 隔离、内存和设备局部性有关的优化。 但是,在 Kubernetes 中,这些优化由各自独立的组件集合来处理。
拓扑管理器(Topology Manager) 是一个 kubelet 组件,旨在协调负责这些优化的一组组件。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.18. 要获知版本信息,请输入kubectl version.
在引入拓扑管理器之前,Kubernetes 中的 CPU 和设备管理器相互独立地做出资源分配决策。 这可能会导致在多处理系统上出现不符合期望的资源分配情况;由于这些与期望相左的分配,对性能或延迟敏感的应用将受到影响。 这里的不符合期望意指,例如,CPU 和设备是从不同的 NUMA 节点分配的,因此会导致额外的延迟。
拓扑管理器是一个 Kubelet 组件,扮演信息源的角色,以便其他 Kubelet 组件可以做出与拓扑结构相对应的资源分配决定。
拓扑管理器为组件提供了一个称为 建议提供者(Hint Provider) 的接口,以发送和接收拓扑信息。 拓扑管理器具有一组节点级策略,具体说明如下。
拓扑管理器从 建议提供者 接收拓扑信息,作为表示可用的 NUMA 节点和首选分配指示的位掩码。 拓扑管理器策略对所提供的建议执行一组操作,并根据策略对提示进行约减以得到最优解; 如果存储了与预期不符的建议,则该建议的优选字段将被设置为 false。 在当前策略中,首选是最窄的优选掩码。 所选建议将被存储为拓扑管理器的一部分。 取决于所配置的策略,所选建议可用来决定节点接受或拒绝 Pod。 之后,建议会被存储在拓扑管理器中,供 建议提供者 在作资源分配决策时使用。
拓扑管理器目前:
如果满足这些条件,则拓扑管理器将对齐请求的资源。
为了定制如何进行对齐,拓扑管理器提供了两种不同的方式:scope 和 policy。
scope 定义了你希望的资源对齐粒度(例如,是在 pod 还是 container 层级上对齐)。
policy 定义了对齐时实际使用的策略(例如,best-effort、restricted、single-numa-node 等等)。
可以在下文找到现今可用的各种 scopes 和 policies 的具体信息。
拓扑管理器可以在以下不同的作用域内进行资源对齐:
container (默认)pod在 kubelet 启动时,可以使用 --topology-manager-scope 标志来选择其中任一选项。
默认使用的是 container 作用域。
在该作用域内,拓扑管理器依次进行一系列的资源对齐, 也就是,对(Pod 中的)每一个容器计算单独的对齐。 换句话说,在该特定的作用域内,没有根据特定的 NUMA 节点集来把容器分组的概念。 实际上,拓扑管理器会把单个容器任意地对齐到 NUMA 节点上。
容器分组的概念是在以下的作用域内特别实现的,也就是 pod 作用域。
启动 kubelet 时附带 --topology-manager-scope=pod 命令行选项,就可以选择 pod 作用域。
该作用域允许把一个 Pod 里的所有容器作为一个分组,分配到一个共同的 NUMA 节点集。 也就是,拓扑管理器会把一个 Pod 当成一个整体, 并且试图把整个 Pod(所有容器)分配到一个单个的 NUMA 节点或者一个共同的 NUMA 节点集。 以下的例子说明了拓扑管理器在不同的场景下使用的对齐方式:
整个 Pod 所请求的某种资源总量是根据 有效 request/limit 公式来计算的,因此,对某一种资源而言,该总量等于以下数值中的最大值:
pod 作用域与 single-numa-node 拓扑管理器策略一起使用,
对于延时敏感的工作负载,或者对于进行 IPC 的高吞吐量应用程序,都是特别有价值的。
把这两个选项组合起来,你可以把一个 Pod 里的所有容器都放到一个单个的 NUMA 节点,
使得该 Pod 消除了 NUMA 之间的通信开销。
在 single-numa-node 策略下,只有当可能的分配方案中存在合适的 NUMA 节点集时,Pod 才会被接受。
重新考虑上述的例子:
简要地说,拓扑管理器首先计算出 NUMA 节点集,然后使用拓扑管理器策略来测试该集合, 从而决定拒绝或者接受 Pod。
拓扑管理器支持四种分配策略。
你可以通过 Kubelet 标志 --topology-manager-policy 设置策略。
所支持的策略有四种:
none (默认)best-effortrestrictedsingle-numa-node这是默认策略,不执行任何拓扑对齐。
对于 Pod 中的每个容器,具有 best-effort 拓扑管理策略的
kubelet 将调用每个建议提供者以确定资源可用性。
使用此信息,拓扑管理器存储该容器的首选 NUMA 节点亲和性。
如果亲和性不是首选,则拓扑管理器将存储该亲和性,并且无论如何都将 Pod 接纳到该节点。
之后建议提供者可以在进行资源分配决策时使用这个信息。
对于 Pod 中的每个容器,配置了 restricted 拓扑管理策略的 kubelet
调用每个建议提供者以确定其资源可用性。
使用此信息,拓扑管理器存储该容器的首选 NUMA 节点亲和性。
如果亲和性不是首选,则拓扑管理器将从节点中拒绝此 Pod。
这将导致 Pod 处于 Terminated 状态,且 Pod 无法被节点接受。
一旦 Pod 处于 Terminated 状态,Kubernetes 调度器将不会尝试重新调度该 Pod。
建议使用 ReplicaSet 或者 Deployment 来触发重新部署 Pod。
还可以通过实现外部控制环,以触发重新部署具有 Topology Affinity 错误的 Pod。
如果 Pod 被允许运行在某节点,则建议提供者可以在做出资源分配决定时使用此信息。
对于 Pod 中的每个容器,配置了 single-numa-node 拓扑管理策略的
kubelet 调用每个建议提供者以确定其资源可用性。
使用此信息,拓扑管理器确定是否支持单 NUMA 节点亲和性。
如果支持,则拓扑管理器将存储此信息,然后 建议提供者 可以在做出资源分配决定时使用此信息。
如果不支持,则拓扑管理器将拒绝 Pod 运行于该节点。
这将导致 Pod 处于 Terminated 状态,且 Pod 无法被节点接受。
一旦 Pod 处于 Terminated 状态,Kubernetes 调度器将不会尝试重新调度该 Pod。
建议使用多副本的 Deployment 来触发重新部署 Pod。
还可以通过实现外部控制环,以触发重新部署具有 Topology Affinity 错误的 Pod。
对拓扑管理器策略选项的支持需要启用 TopologyManagerPolicyOptions
特性门控(默认启用)。
你可以使用以下特性门控根据成熟度级别打开和关闭这些选项组:
TopologyManagerPolicyBetaOptions 默认启用。启用以显示 Beta 级别选项。TopologyManagerPolicyAlphaOptions 默认禁用。启用以显示 Alpha 级别选项。你仍然需要使用 TopologyManagerPolicyOptions kubelet 选项来启用每个选项。
存在以下策略选项:
prefer-closest-numa-nodes(Beta,默认可见,TopologyManagerPolicyOptions 和
TopologyManagerPolicyAlphaOptions 特性门控必须被启用)。
prefer-closest-numa-nodes 策略选项在 Kubernetes 1.29
中是 Beta 版。如果 prefer-closest-numa-nodes 策略选项被指定,则在做出准入决策时 best-effort 和 restricted
策略将偏向于彼此之间距离较短的一组 NUMA 节点。
你可以通过将 prefer-closest-numa-nodes=true 添加到拓扑管理器策略选项来启用此选项。
默认情况下,如果没有此选项,拓扑管理器会在单个 NUMA 节点或(在需要多个 NUMA 节点时)最小数量的 NUMA 节点上对齐资源。
然而,TopologyManager 无法感知到 NUMA 距离且在做出准入决策时也没有考虑这些距离。
这种限制出现在多插槽以及单插槽多 NUMA 系统中,如果拓扑管理器决定在非相邻 NUMA 节点上对齐资源,
可能导致对执行延迟敏感和高吞吐的应用程序出现明显的性能下降。
考虑以下 Pod 规范中的容器:
spec:
containers:
- name: nginx
image: nginx
该 Pod 以 BestEffort QoS 类运行,因为没有指定资源 requests 或 limits。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
由于 requests 数少于 limits,因此该 Pod 以 Burstable QoS 类运行。
如果选择的策略是 none 以外的任何其他策略,拓扑管理器都会评估这些 Pod 的规范。
拓扑管理器会咨询建议提供者,获得拓扑建议。
若策略为 static,则 CPU 管理器策略会返回默认的拓扑建议,因为这些 Pod
并没有显式地请求 CPU 资源。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
此 Pod 独立使用 CPU 请求量,以 Guaranteed QoS 类运行,因为其 requests 值等于 limits 值。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
此 Pod 和其他资源共享 CPU 请求量,以 Guaranteed QoS 类运行,因为其 requests 值等于 limits 值。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
example.com/deviceA: "1"
example.com/deviceB: "1"
requests:
example.com/deviceA: "1"
example.com/deviceB: "1"
因为未指定 CPU 和内存请求,所以 Pod 以 BestEffort QoS 类运行。
拓扑管理器将考虑以上 Pod。拓扑管理器将咨询建议提供者即 CPU 和设备管理器,以获取 Pod 的拓扑提示。
对于独立使用 CPU 请求量的 Guaranteed Pod,static CPU 管理器策略将返回独占 CPU 相关的拓扑提示,
而设备管理器将返回有关所请求设备的提示。
对于与其他资源 CPU 共享请求量的 Guaranteed Pod,static CPU
管理器策略将返回默认的拓扑提示,因为没有独享的 CPU 请求;而设备管理器
则针对所请求的设备返回有关提示。
在上述两种 Guaranteed Pod 的情况中,none CPU 管理器策略会返回默认的拓扑提示。
对于 BestEffort Pod,由于没有 CPU 请求,static CPU 管理器策略将发送默认拓扑提示,
而设备管理器将为每个请求的设备发送提示。
基于此信息,拓扑管理器将为 Pod 计算最佳提示并存储该信息,并且供 提示提供程序在进行资源分配时使用。
本页说明如何配置 DNS Pod,以及定制集群中 DNS 解析过程。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的集群必须运行 CoreDNS 插件。
你的 Kubernetes 服务器版本必须不低于版本 v1.12.
要获知版本信息,请输入 kubectl version.
DNS 是使用 插件管理器 集群插件自动启动的 Kubernetes 内置服务。
CoreDNS 服务在其 metadata.name 字段被命名为 kube-dns。
这是为了能够与依靠传统 kube-dns 服务名称来解析集群内部地址的工作负载具有更好的互操作性。
使用 kube-dns 作为服务名称可以抽离共有名称之后运行的是哪个 DNS 提供程序这一实现细节。
如果你在使用 Deployment 运行 CoreDNS,则该 Deployment 通常会向外暴露为一个具有
静态 IP 地址 Kubernetes 服务。
kubelet 使用 --cluster-dns=<DNS 服务 IP> 标志将 DNS 解析器的信息传递给每个容器。
DNS 名称也需要域名。你可在 kubelet 中使用 --cluster-domain=<默认本地域名>
标志配置本地域名。
DNS 服务器支持正向查找(A 和 AAAA 记录)、端口发现(SRV 记录)、反向 IP 地址发现(PTR 记录)等。 更多信息,请参见 Service 与 Pod 的 DNS。
如果 Pod 的 dnsPolicy 设置为 default,则它将从 Pod 运行所在节点继承名称解析配置。
Pod 的 DNS 解析行为应该与节点相同。
但请参阅已知问题。
如果你不想这样做,或者想要为 Pod 使用其他 DNS 配置,则可以使用 kubelet 的
--resolv-conf 标志。将此标志设置为 "" 可以避免 Pod 继承 DNS。
将其设置为有别于 /etc/resolv.conf 的有效文件路径可以设定 DNS 继承不同的配置。
CoreDNS 是通用的权威 DNS 服务器,可以用作集群 DNS,符合 DNS 规范。
CoreDNS 是模块化且可插拔的 DNS 服务器,每个插件都为 CoreDNS 添加了新功能。 可以通过维护 Corefile,即 CoreDNS 配置文件, 来配置 CoreDNS 服务器。作为一个集群管理员,你可以修改 CoreDNS Corefile 的 ConfigMap, 以更改 DNS 服务发现针对该集群的工作方式。
在 Kubernetes 中,CoreDNS 安装时使用如下默认 Corefile 配置:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Corefile 配置包括以下 CoreDNS 插件:
errors:错误记录到标准输出。
health:在 http://localhost:8080/health 处提供 CoreDNS 的健康报告。
在这个扩展语法中,lameduck 会使此进程不健康,等待 5 秒后进程被关闭。
ready:在端口 8181 上提供的一个 HTTP 端点, 当所有能够表达自身就绪的插件都已就绪时,在此端点返回 200 OK。
kubernetes:CoreDNS 将基于服务和 Pod 的 IP 来应答 DNS 查询。 你可以在 CoreDNS 网站找到有关此插件的更多细节。
ttl 来定制响应的 TTL。默认值是 5 秒钟。TTL 的最小值可以是 0 秒钟,
最大值为 3600 秒。将 TTL 设置为 0 可以禁止对 DNS 记录进行缓存。pods insecure 选项是为了与 kube-dns 向后兼容。pods verified 选项,该选项使得仅在相同名字空间中存在具有匹配 IP 的 Pod 时才返回 A 记录。pods disabled 选项。http://localhost:9153/metrics 上提供。你可以通过修改 ConfigMap 来更改默认的 CoreDNS 行为。
CoreDNS 能够使用 forward 插件配置存根域和上游域名服务器。
如果集群操作员在 "10.150.0.1" 处运行了 Consul 域服务器,
且所有 Consul 名称都带有后缀 .consul.local。要在 CoreDNS 中对其进行配置,
集群管理员可以在 CoreDNS 的 ConfigMap 中创建加入以下字段。
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
要显式强制所有非集群 DNS 查找通过特定的域名服务器(位于 172.16.0.1),可将 forward
指向该域名服务器,而不是 /etc/resolv.conf。
forward . 172.16.0.1
最终的包含默认的 Corefile 配置的 ConfigMap 如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 172.16.0.1
cache 30
loop
reload
loadbalance
}
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
CoreDNS 不支持 FQDN 作为存根域和域名服务器(例如 "ns.foo.com")。 转换期间,CoreDNS 配置中将忽略所有的 FQDN 域名服务器。
这篇文章提供了一些关于 DNS 问题诊断的方法。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的集群必须使用了 CoreDNS 插件
或者其前身,kube-dns。
kubectl version.
apiVersion: v1
kind: Pod
metadata:
name: dnsutils
namespace: default
spec:
containers:
- name: dnsutils
image: registry.k8s.io/e2e-test-images/jessie-dnsutils:1.3
command:
- sleep
- "infinity"
imagePullPolicy: IfNotPresent
restartPolicy: Always
default 名字空间创建 Pod。
服务的 DNS 名字解析取决于 Pod 的名字空间。
详细信息请查阅 Pod 与 Service 的 DNS。
使用上面的清单来创建一个 Pod:
kubectl apply -f https://k8s.io/examples/admin/dns/dnsutils.yaml
pod/dnsutils created
验证其状态:
kubectl get pods dnsutils
NAME READY STATUS RESTARTS AGE
dnsutils 1/1 Running 0 <some-time>
一旦 Pod 处于运行状态,你就可以在该环境里执行 nslookup。
如果你看到类似下列的内容,则表示 DNS 是正常运行的。
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
输出为:
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: kubernetes.default
Address 1: 10.0.0.1
如果 nslookup 命令执行失败,请检查下列内容:
查看 resolv.conf 文件的内容 (阅读定制 DNS 服务 和 后文的已知问题 ,获取更多信息)
kubectl exec -ti dnsutils -- cat /etc/resolv.conf
验证 search 和 nameserver 的配置是否与下面的内容类似 (注意 search 根据不同的云提供商可能会有所不同):
search default.svc.cluster.local svc.cluster.local cluster.local google.internal c.gce_project_id.internal
nameserver 10.0.0.10
options ndots:5
下列错误表示 CoreDNS (或 kube-dns)插件或者相关服务出现了问题:
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
输出为:
Server: 10.0.0.10
Address 1: 10.0.0.10
nslookup: can't resolve 'kubernetes.default'
或者
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
输出为:
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'kubernetes.default'
使用 kubectl get pods 命令来验证 DNS Pod 是否运行。
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
输出为:
NAME READY STATUS RESTARTS AGE
...
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
...
k8s-app 的值都应该是 kube-dns。
如果你发现没有 CoreDNS Pod 在运行,或者该 Pod 的状态是 failed 或者 completed, 那可能这个 DNS 插件在你当前的环境里并没有成功部署,你将需要手动去部署它。
使用 kubectl logs 命令来查看 DNS 容器的日志信息。
如查看 CoreDNS 的日志信息:
kubectl logs --namespace=kube-system -l k8s-app=kube-dns
下列是一个正常运行的 CoreDNS 日志信息:
.:53
2018/08/15 14:37:17 [INFO] CoreDNS-1.2.2
2018/08/15 14:37:17 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.2
linux/amd64, go1.10.3, 2e322f6
2018/08/15 14:37:17 [INFO] plugin/reload: Running configuration MD5 = 24e6c59e83ce706f07bcc82c31b1ea1c
查看是否日志中有一些可疑的或者意外的消息。
使用 kubectl get service 命令来检查 DNS 服务是否已经启用。
kubectl get svc --namespace=kube-system
输出为:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
kube-dns。
如果你已经创建了 DNS 服务,或者该服务应该是默认自动创建的但是它并没有出现, 请阅读调试服务 来获取更多信息。
你可以使用 kubectl get endpoints 命令来验证 DNS 的端点是否公开了。
kubectl get endpoints kube-dns --namespace=kube-system
NAME ENDPOINTS AGE
kube-dns 10.180.3.17:53,10.180.3.17:53 1h
如果你没看到对应的端点,请阅读 调试服务的端点部分。
若需要了解更多的 Kubernetes DNS 例子,请在 Kubernetes GitHub 仓库里查看 cluster-dns 示例。
你可以通过给 CoreDNS 的配置文件(也叫 Corefile)添加 log 插件来检查查询是否被正确接收。
CoreDNS 的 Corefile 被保存在一个叫 coredns 的
ConfigMap 里,使用下列命令来编辑它:
kubectl -n kube-system edit configmap coredns
然后按下面的例子给 Corefile 添加 log。
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
log
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
保存这些更改后,你可能会需要等待一到两分钟让 Kubernetes 把这些更改应用到 CoreDNS 的 Pod 里。
接下来,发起一些查询并依照前文所述查看日志信息,如果 CoreDNS 的 Pod 接收到这些查询, 你将可以在日志信息里看到它们。
下面是日志信息里的查询例子:
.:53
2018/08/15 14:37:15 [INFO] CoreDNS-1.2.0
2018/08/15 14:37:15 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.0
linux/amd64, go1.10.3, 2e322f6
2018/09/07 15:29:04 [INFO] plugin/reload: Running configuration MD5 = 162475cdf272d8aa601e6fe67a6ad42f
2018/09/07 15:29:04 [INFO] Reloading complete
172.17.0.18:41675 - [07/Sep/2018:15:29:11 +0000] 59925 "A IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR qr,aa,rd,ra 106 0.000066649s
CoreDNS 必须能够列出 service 和 endpoint 相关的资源来正确解析服务名称。
示例错误消息:
2022-03-18T07:12:15.699431183Z [INFO] 10.96.144.227:52299 - 3686 "A IN serverproxy.contoso.net.cluster.local. udp 52 false 512" SERVFAIL qr,aa,rd 145 0.000091221s
首先,获取当前的 ClusterRole system:coredns:
kubectl describe clusterrole system:coredns -n kube-system
预期输出:
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
endpoints [] [] [list watch]
namespaces [] [] [list watch]
pods [] [] [list watch]
services [] [] [list watch]
endpointslices.discovery.k8s.io [] [] [list watch]
如果缺少任何权限,请编辑 ClusterRole 来添加它们:
kubectl edit clusterrole system:coredns -n kube-system
EndpointSlices 权限的插入示例:
...
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
...
未指定名字空间的 DNS 查询仅作用于 Pod 所在的名字空间。
如果 Pod 和服务的名字空间不相同,则 DNS 查询必须指定服务所在的名字空间。
该查询仅限于 Pod 所在的名字空间:
kubectl exec -i -t dnsutils -- nslookup <service-name>
指定名字空间的查询:
kubectl exec -i -t dnsutils -- nslookup <service-name>.<namespace>
要进一步了解名字解析,请查看 Pod 与 Service 的 DNS。
有些 Linux 发行版本(比如 Ubuntu)默认使用一个本地的 DNS 解析器(systemd-resolved)。
systemd-resolved 会用一个存根文件(Stub File)来覆盖 /etc/resolv.conf 内容,
从而可能在上游服务器中解析域名产生转发环(forwarding loop)。 这个问题可以通过手动指定
kubelet 的 --resolv-conf 标志为正确的 resolv.conf(如果是 systemd-resolved,
则这个文件路径为 /run/systemd/resolve/resolv.conf)来解决。
kubeadm 会自动检测 systemd-resolved 并对应的更改 kubelet 的命令行标志。
Kubernetes 的安装并不会默认配置节点的 resolv.conf 文件来使用集群的 DNS 服务,因为这个配置对于不同的发行版本是不一样的。这个问题应该迟早会被解决的。
Linux 的 libc(又名 glibc)默认将 DNS nameserver 记录限制为 3,
而 Kubernetes 需要使用 1 条 nameserver 记录。
这意味着如果本地的安装已经使用了 3 个 nameserver,那么其中有些条目将会丢失。
要解决此限制,节点可以运行 dnsmasq,以提供更多 nameserver 条目。
你也可以使用 kubelet 的 --resolv-conf 标志来解决这个问题。
如果你使用 Alpine 3.17 或更早版本作为你的基础镜像,DNS 可能会由于 Alpine 的设计问题而无法工作。 在 musl 1.24 版本之前,DNS 存根解析器都没有包括 TCP 回退, 这意味着任何超过 512 字节的 DNS 调用都会失败。请将你的镜像升级到 Alpine 3.18 或更高版本。
本文可以帮助你开始使用 Kubernetes 的 NetworkPolicy API 声明网络策略去管理 Pod 之间的通信
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.8. 要获知版本信息,请输入kubectl version.
你首先需要有一个支持网络策略的 Kubernetes 集群。已经有许多支持 NetworkPolicy 的网络提供商,包括:
nginx Deployment 并且通过服务将其暴露为了查看 Kubernetes 网络策略是怎样工作的,可以从创建一个nginx Deployment 并且通过服务将其暴露开始
kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
将此 Deployment 以名为 nginx 的 Service 暴露出来:
kubectl expose deployment nginx --port=80
service/nginx exposed
上述命令创建了一个带有一个 nginx 的 Deployment,并将之通过名为 nginx 的
Service 暴露出来。名为 nginx 的 Pod 和 Deployment 都位于 default
名字空间内。
kubectl get svc,pod
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes 10.100.0.1 <none> 443/TCP 46m
service/nginx 10.100.0.16 <none> 80/TCP 33s
NAME READY STATUS RESTARTS AGE
pod/nginx-701339712-e0qfq 1/1 Running 0 35s
你应该可以从其它的 Pod 访问这个新的 nginx 服务。
要从 default 命名空间中的其它 Pod 来访问该服务。可以启动一个 busybox 容器:
kubectl run busybox --rm -ti --image=busybox:1.28 -- /bin/sh
在你的 Shell 中,运行下面的命令:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
nginx 服务的访问如果想限制对 nginx 服务的访问,只让那些拥有标签 access: true 的 Pod 访问它,
那么可以创建一个如下所示的 NetworkPolicy 对象:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
NetworkPolicy 对象的名称必须是一个合法的 DNS 子域名.
podSelector。
你可以看到上面的策略选择的是带有标签 app=nginx 的 Pods。
此标签是被自动添加到 nginx Deployment 中的 Pod 上的。
如果 podSelector 为空,则意味着选择的是名字空间中的所有 Pods。
使用 kubectl 根据上面的 nginx-policy.yaml 文件创建一个 NetworkPolicy:
kubectl apply -f https://k8s.io/examples/service/networking/nginx-policy.yaml
networkpolicy.networking.k8s.io/access-nginx created
如果你尝试从没有设定正确标签的 Pod 中去访问 nginx 服务,请求将会超时:
kubectl run busybox --rm -ti --image=busybox:1.28 -- /bin/sh
在 Shell 中运行命令:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
wget: download timed out
创建一个拥有正确标签的 Pod,你将看到请求是被允许的:
kubectl run busybox --rm -ti --labels="access=true" --image=busybox:1.28 -- /bin/sh
在 Shell 中运行命令:
wget --spider --timeout=1 nginx
Connecting to nginx (10.100.0.16:80)
remote file exists
Kubernetes v1.11 [beta]
一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager) 允许将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
通过分离 Kubernetes 和底层云基础设置之间的互操作性逻辑,
cloud-controller-manager 组件使云提供商能够以不同于 Kubernetes 主项目的步调发布新特征。
由于云驱动的开发和发布与 Kubernetes 项目本身步调不同,将特定于云环境的代码抽象到
cloud-controller-manager 二进制组件有助于云厂商独立于 Kubernetes
核心代码推进其驱动开发。
Kubernetes 项目提供 cloud-controller-manager 的框架代码,其中包含 Go 语言的接口,
便于你(或者你的云驱动提供者)接驳你自己的实现。这意味着每个云驱动可以通过从
Kubernetes 核心代码导入软件包来实现一个 cloud-controller-manager;
每个云驱动会通过调用 cloudprovider.RegisterCloudProvider 接口来注册其自身实现代码,
从而更新一个用来记录可用云驱动的全局变量。
要为你的云环境构建一个树外(Out-of-Tree)云控制器管理器:
cloudprovider.Interface
接口的实现来创建一个 Go 语言包。main.go
作为 main.go 的模板。如上所述,唯一的区别应该是将导入的云包不同。main.go 中导入你的云包,确保你的包有一个 init 块来运行
cloudprovider.RegisterCloudProvider。很多云驱动都将其控制器管理器代码以开源代码的形式公开。 如果你在开发一个新的 cloud-controller-manager,你可以选择某个树外(Out-of-Tree) 云控制器管理器作为出发点。
对于树内(In-Tree)驱动,你可以将树内云控制器管理器作为集群中的 DaemonSet 来运行。 有关详细信息,请参阅云控制器管理器管理。
本页展示怎么用集群的 控制平面. 启用/禁用 API 版本。
通过 API 服务器的命令行参数 --runtime-config=api/<version> ,
可以开启/关闭某个指定的 API 版本。
此参数的值是一个逗号分隔的 API 版本列表。
此列表中,后面的值可以覆盖前面的值。
命令行参数 runtime-config 支持两个特殊的值(keys):
api/all:指所有已知的 APIapi/legacy:指过时的 API。过时的 API 就是明确地
弃用
的 API。例如:为了停用除去 v1 版本之外的全部其他 API 版本,
就用参数 --runtime-config=api/all=false,api/v1=true 启动 kube-apiserver。
阅读完整的文档,
以了解 kube-apiserver 组件。
Kubernetes 中允许允许用户编辑的持久 API 资源数据的所有 API 都支持静态加密。 例如,你可以启用静态加密 Secret。 此静态加密是对 etcd 集群或运行 kube-apiserver 的主机上的文件系统的任何系统级加密的补充。
本页展示如何启用和配置静态 API 数据加密。
此任务涵盖使用 Kubernetes API 存储的资源数据的加密。 例如,你可以加密 Secret 对象,包括它们包含的键值数据。
如果要加密安装到容器中的文件系统中的数据,则需要:
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
此任务假设你将 Kubernetes API 服务器组件以静态 Pod 方式运行在每个控制平面节点上。
集群的控制平面必须使用 etcd v3.x(主版本 3,任何次要版本)。
要加密自定义资源,你的集群必须运行 Kubernetes v1.26 或更高版本。
在 Kubernetes v1.27 或更高版本中可以使用通配符匹配资源。
kubectl version.
默认情况下,API 服务器将资源的明文表示存储在 etcd 中,没有静态加密。
kube-apiserver 进程使用 --encryption-provider-config 参数指定配置文件的路径,
所指定的配置文件的内容将控制 Kubernetes API 数据在 etcd 中的加密方式。
如果你在运行 kube-apiserver 时没有使用 --encryption-provider-config 命令行参数,
则你未启用静态加密。如果你在运行 kube-apiserver 时使用了 --encryption-provider-config
命令行参数,并且此参数所引用的文件指定 identity 提供程序作为加密提供程序列表中的第一个,
则你未启用静态加密(默认的 identity 提供程序不提供任何机密性保护)。
如果你在运行 kube-apiserver 时使用了 --encryption-provider-config 命令行参数,
并且此参数所引用的文件指定一个不是 identity 的提供程序作为加密提供程序列表中的第一个,
则你已启用静态加密。然而此项检查并未告知你先前向加密存储的迁移是否成功。如果你不确定,
请参阅确保所有相关数据都已加密。
重要: 对于高可用配置(有两个或多个控制平面节点),加密配置文件必须相同!
否则,kube-apiserver 组件无法解密存储在 etcd 中的数据。
---
#
# 注意:这是一个示例配置。请勿将其用于你自己的集群!
#
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example # 自定义资源 API
providers:
# 此配置不提供数据机密性。
# 第一个配置的 provider 正在指定将资源存储为纯文本的 "identity" 机制。
- identity: {} # 纯文本,换言之未加密
- aesgcm:
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- aescbc:
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- secretbox:
keys:
- name: key1
secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
- resources:
- events
providers:
- identity: {} # 即使如下指定 *.* 也不会加密 events
- resources:
- '*.apps' # 通配符匹配需要 Kubernetes 1.27 或更高版本
providers:
- aescbc:
keys:
- name: key2
secret: c2VjcmV0IGlzIHNlY3VyZSwgb3IgaXMgaXQ/Cg==
- resources:
- '*.*' # 通配符匹配需要 Kubernetes 1.27 或更高版本
providers:
- aescbc:
keys:
- name: key3
secret: c2VjcmV0IGlzIHNlY3VyZSwgSSB0aGluaw==每个 resources 数组项目是一个单独的完整的配置。
resources.resources 字段是应加密的 Kubernetes 资源(例如 Secret、ConfigMap 或其他资源)名称
(resource 或 resource.group)的数组。
如果自定义资源被添加到 EncryptionConfiguration 并且集群版本为 1.26 或更高版本,
则 EncryptionConfiguration 中提到的任何新创建的自定义资源都将被加密。
在该版本之前存在于 etcd 中的任何自定义资源和配置不会被加密,直到它们被下一次写入到存储为止。
这与内置资源的行为相同。请参阅确保所有 Secret 都已加密一节。
providers 数组是可能的加密提供程序的有序列表,用于你所列出的 API。
每个提供程序支持多个密钥 - 解密时会按顺序尝试这些密钥,
如果这是第一个提供程序,其第一个密钥将被用于加密。
每个条目只能指定一个提供程序类型(可以是 identity 或 aescbc,但不能在同一个项目中同时指定二者)。
列表中的第一个提供程序用于加密写入存储的资源。
当从存储器读取资源时,与存储的数据匹配的所有提供程序将按顺序尝试解密数据。
如果由于格式或密钥不匹配而导致没有提供程序能够读取存储的数据,则会返回一个错误,以防止客户端访问该资源。
EncryptionConfiguration 支持使用通配符指定应加密的资源。
使用 “*.<group>” 加密 group 内的所有资源(例如以上例子中的 “*.apps”)或使用
“*.*” 加密所有资源。“*.” 可用于加密核心组中的所有资源。“*.*”
将加密所有资源,甚至包括 API 服务器启动之后添加的自定义资源。
不允许在同一资源列表或跨多个条目中使用相互重疊的通配符,因为这样一来配置的一部分将无法生效。
resources 列表的处理顺序和优先级由配置中列出的顺序决定。
如果你有一个涵盖资源(resource)的通配符,并且想要过滤掉静态加密的特定类型资源,
则可以通过添加一个单独的 resources 数组项来实现此目的,
其中包含要豁免的资源的名称,还可以在其后跟一个 providers 数组项来指定 identity 提供商。
你可以将此数组项添加到列表中,以便它早于你指定加密的配置(不是 identity 的提供商)出现。
例如,如果启用了 '*.*',并且你想要选择不加密 Event 和 ConfigMap,
请在 resources 中靠前的位置添加一个新的条目,后跟带有 identity
的 providers 数组项作为提供程序。较为特定的条目必须位于通配符条目之前。
新项目看起来类似于:
...
- resources:
- configmaps. # 特定于来自核心 API 组的资源,因为结尾是 “.”
- events
providers:
- identity: {}
# 然后是资源中的其他条目
确保新项列在资源数组中的通配符 “*.*” 项之前,使新项优先。
有关 EncryptionConfiguration 结构体的更多详细信息,
请参阅加密配置 API。
如果通过加密配置无法读取资源(因为密钥已更改),唯一的方法是直接从底层 etcd 中删除该密钥。 任何尝试读取资源的调用将会失败,直到它被删除或提供有效的解密密钥。
在为集群的 Kubernetes API 数据配置静态加密之前,你需要选择要使用的提供程序。
下表描述了每个可用的提供程序:
| 名称 | 加密类型 | 强度 | 速度 | 密钥长度 |
|---|---|---|---|---|
| identity | 无 | N/A | N/A | N/A |
| 不加密写入的资源。当设置为第一个提供程序时,已加密的资源将在新值写入时被解密。 | ||||
| aescbc | 带有 PKCS#7 填充的 AES-CBC | 弱 | 快 | 32 字节 |
| 由于 CBC 容易受到密文填塞攻击(Padding Oracle Attack),不推荐使用。密钥材料可从控制面主机访问。 | ||||
| aesgcm | 带有随机数的 AES-GCM | 每写入 200k 次后必须轮换 | 最快 | 16、24 或者 32 字节 |
| 不建议使用,除非实施了自动密钥轮换方案。密钥材料可从控制面主机访问。 | ||||
| kms v1 (自 Kubernetes 1.28 起弃用) | 针对每个资源使用不同的 DEK 来完成信封加密。 | 最强 | 慢(与 kms V2 相比) | 32 字节 |
|
通过数据加密密钥(DEK)使用 AES-GCM 加密数据;
DEK 根据 Key Management Service(KMS)中的配置通过密钥加密密钥(Key Encryption Keys,KEK)加密。
密钥轮换方式简单,每次加密都会生成一个新的 DEK,KEK 的轮换由用户控制。
阅读如何配置 KMS V1 提供程序 |
||||
| kms v2 | 针对每个 API 服务器使用不同的 DEK 来完成信封加密。 | 最强 | 快 | 32 字节 |
|
通过数据加密密钥(DEK)使用 AES-GCM 加密数据;
DEK 根据 Key Management Service(KMS)中的配置通过密钥加密密钥(Key Encryption Keys,KEK)加密。
Kubernetes 基于秘密的种子数为每次加密生成一个新的 DEK。
每当 KEK 轮换时,种子也会轮换。
如果使用第三方工具进行密钥管理,这是一个不错的选择。
从 `v1.29` 开始,该功能处于稳定阶段。
阅读如何配置 KMS V2 提供程序。 |
||||
| secretbox | XSalsa20 和 Poly1305 | 强 | 更快 | 32 字节 |
| 使用相对较新的加密技术,在需要高度评审的环境中可能不被接受。密钥材料可从控制面主机访问。 | ||||
如果你没有另外指定,identity 提供程序将作为默认选项。
identity 提供程序不会加密存储的数据,并且提供无附加的机密保护。
使用本地管理的密钥对 Secret 数据进行加密可以防止 etcd 受到威胁,但无法防范主机受到威胁的情况。 由于加密密钥被存储在主机上的 EncryptionConfiguration YAML 文件中,有经验的攻击者可以访问该文件并提取加密密钥。
KMS 提供程序使用封套加密:Kubernetes 使用一个数据密钥来加密资源,然后使用托管的加密服务来加密该数据密钥。 Kubernetes 为每个资源生成唯一的数据密钥。API 服务器将数据密钥的加密版本与密文一起存储在 etcd 中; API 服务器在读取资源时,调用托管的加密服务并提供密文和(加密的)数据密钥。 在托管的加密服务中,提供程序使用密钥加密密钥来解密数据密钥,解密数据密钥后恢复为明文。 在控制平面和 KMS 之间的通信需要在传输过程中提供 TLS 这类保护。
使用封套加密会依赖于密钥加密密钥,此密钥不存储在 Kubernetes 中。 就 KMS 而言,如果攻击者意图未经授权地访问明文值,则需要同时入侵 etcd 和第三方 KMS 提供程序。
你应该采取适当的措施来保护允许解密的机密信息,无论是本地加密密钥还是允许 API 服务器调用 KMS 的身份验证令牌。
即使你依赖提供商来管理主加密密钥(或多个密钥)的使用和生命周期, 你仍然有责任确保托管加密服务的访问控制和其他安全措施满足你的安全需求。
以下步骤假设你没有使用 KMS,因此这些步骤还假设你需要生成加密密钥。 如果你已有加密密钥,请跳至编写加密配置文件。
与不加密相比,将原始加密密钥存储在 EncryptionConfig 中只能适度改善你的安全状况。
为了获得额外的保密性,请考虑使用 kms 提供程序,因为这依赖于 Kubernetes
集群外部保存的密钥。kms 的实现可以与硬件安全模块或由云提供商管理的加密服务配合使用。
要了解如何使用 KMS 设置静态加密,请参阅使用 KMS 提供程序进行数据加密。 你使用的 KMS 提供程序插件可能还附带其他特定文档。
首先生成新的加密密钥,然后使用 base64 对其进行编码:
生成 32 字节随机密钥并对其进行 base64 编码。你可以使用这个命令:
head -c 32 /dev/urandom | base64
如果你想使用 PC 的内置硬件熵源,可以使用 /dev/hwrng 而不是 /dev/urandom。
并非所有 Linux 设备都提供硬件随机数生成器。
生成 32 字节随机密钥并对其进行 base64 编码。你可以使用此命令:
head -c 32 /dev/urandom | base64
生成 32 字节随机密钥并对其进行 base64 编码。你可以使用此命令:
# 不要在已设置随机数生成器种子的会话中运行此命令。
[Convert]::ToBase64String((1..32|%{[byte](Get-Random -Max 256)}))
保持加密密钥的机密性,包括在生成密钥时,甚至理想的情况下在你不再主动使用密钥后也要保密。
使用安全的文件传输机制,将该加密密钥的副本提供给所有其他控制平面主机。
至少,使用传输加密 - 例如,安全 shell(SSH)。为了提高安全性, 请在主机之间使用非对称加密,或更改你正在使用的方法,以便依赖 KMS 加密。
加密配置文件可能包含可以解密 etcd 中内容的密钥。 如果此配置文件包含任何密钥信息,你必须在所有控制平面主机上合理限制权限, 以便只有运行 kube-apiserver 的用户可以读取此配置。
创建一个新的加密配置文件。其内容应类似于:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- aescbc:
keys:
- name: key1
# 参见以下文本了解有关 Secret 值的详情
secret: <BASE 64 ENCODED SECRET>
- identity: {} # 这个回退允许读取未加密的 Secret;
# 例如,在初始迁移期间
要创建新的加密密钥(不使用 KMS),请参阅生成加密密钥。
你将需要把新的加密配置文件挂载到 kube-apiserver 静态 Pod。以下是这个操作的示例:
将新的加密配置文件保存到控制平面节点上的 /etc/kubernetes/enc/enc.yaml。
编辑 kube-apiserver 静态 Pod 的清单:/etc/kubernetes/manifests/kube-apiserver.yaml,
代码范例如下:
---
#
# 这是一个静态 Pod 的清单片段。
# 检查是否适用于你的集群和 API 服务器。
#
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/kube-apiserver.advertise-address.endpoint: 10.20.30.40:443
creationTimestamp: null
labels:
app.kubernetes.io/component: kube-apiserver
tier: control-plane
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
...
- --encryption-provider-config=/etc/kubernetes/enc/enc.yaml # 增加这一行
volumeMounts:
...
- name: enc # 增加这一行
mountPath: /etc/kubernetes/enc # 增加这一行
readOnly: true # 增加这一行
...
volumes:
...
- name: enc # 增加这一行
hostPath: # 增加这一行
path: /etc/kubernetes/enc # 增加这一行
type: DirectoryOrCreate # 增加这一行
...
你的配置文件包含可以解密 etcd 内容的密钥,因此你必须正确限制控制平面节点的访问权限,
以便只有能运行 kube-apiserver 的用户才能读取它。
你现在已经为一个控制平面主机进行了加密。典型的 Kubernetes 集群有多个控制平面主机,因此需要做的事情更多。
如果你的集群中有多个 API 服务器,应轮流将更改部署到每个 API 服务器。
确保在每个控制平面主机上使用相同的加密配置。
数据在写入 etcd 时会被加密。重新启动你的 kube-apiserver 后,任何新创建或更新的 Secret
或在 EncryptionConfiguration 中配置的其他资源类别都应在存储时被加密。
如果想要检查,你可以使用 etcdctl 命令行程序来检索你的 Secret 数据内容。
以下示例演示了如何对加密 Secret API 进行检查。
创建一个新的 Secret,名称为 secret1,命名空间为 default:
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
使用 etcdctl 命令行工具,从 etcd 中读取 Secret:
ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -C
这里的 [...] 是用来连接 etcd 服务的额外参数。
例如:
ETCDCTL_API=3 etcdctl \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
get /registry/secrets/default/secret1 | hexdump -C
输出类似于(有删减):
00000000 2f 72 65 67 69 73 74 72 79 2f 73 65 63 72 65 74 |/registry/secret|
00000010 73 2f 64 65 66 61 75 6c 74 2f 73 65 63 72 65 74 |s/default/secret|
00000020 31 0a 6b 38 73 3a 65 6e 63 3a 61 65 73 63 62 63 |1.k8s:enc:aescbc|
00000030 3a 76 31 3a 6b 65 79 31 3a c7 6c e7 d3 09 bc 06 |:v1:key1:.l.....|
00000040 25 51 91 e4 e0 6c e5 b1 4d 7a 8b 3d b9 c2 7c 6e |%Q...l..Mz.=..|n|
00000050 b4 79 df 05 28 ae 0d 8e 5f 35 13 2c c0 18 99 3e |.y..(..._5.,...>|
[...]
00000110 23 3a 0d fc 28 ca 48 2d 6b 2d 46 cc 72 0b 70 4c |#:..(.H-k-F.r.pL|
00000120 a5 fc 35 43 12 4e 60 ef bf 6f fe cf df 0b ad 1f |..5C.N`..o......|
00000130 82 c4 88 53 02 da 3e 66 ff 0a |...S..>f..|
0000013a
验证存储的密钥前缀是否为 k8s:enc:aescbc:v1:,这表明 aescbc provider 已加密结果数据。
确认 etcd 中显示的密钥名称和上述 EncryptionConfiguration 中指定的密钥名称一致。
在此例中,你可以看到在 etcd 和 EncryptionConfiguration 中使用了名为 key1 的加密密钥。
通过 API 检索,验证 Secret 是否被正确解密:
kubectl get secret secret1 -n default -o yaml
其输出应该包含 mykey: bXlkYXRh,其中 mydata 的内容使用 base64 进行加密,
请参阅解密 Secret
了解如何完全解码 Secret 内容。
仅仅确保新对象被加密通常是不够的:你还希望对已经存储的对象进行加密。
例如,你已经配置了集群,使得 Secret 在写入时进行加密。 为每个 Secret 执行替换操作将加密那些对象保持不变的静态内容。
你可以在集群中的所有 Secret 上进行此项变更:
# 以能够读写所有 Secret 的管理员身份运行此命令
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
上面的命令读取所有 Secret,然后使用相同的数据更新这些 Secret,以便应用服务端加密。
如果由于冲突写入而发生错误,请重试该命令。 多次运行此命令是安全的。
对于较大的集群,你可能希望通过命名空间或更新脚本来对 Secret 进行划分。
如果你想确保对特定 API 类型的唯一访问是使用加密完成的,你可以移除 API 服务器以明文形式读取该 API 的支持数据的能力。
此更改可防止 API 服务器检索标记为静态加密但实际上以明文形式存储的资源。
当你为某个 API 配置静态加密时(例如:API 种类 Secret,代表核心 API 组中的 secrets 资源),
你必须确保该集群中的所有这些资源确实被静态加密,
在后续步骤开始之前请检查此项。
一旦集群中的所有 Secret 都被加密,你就可以删除加密配置中的 identity 部分。例如:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
- identity: {} # 删除此行…然后依次重新启动每个 API 服务器。此更改可防止 API 服务器访问纯文本 Secret,即使是意外访问也是如此。
在不发生停机的情况下更改 Kubernetes 的加密密钥需要多步操作,特别是在有多个 kube-apiserver
进程正在运行的高可用环境中。
kube-apiserver 进程以确保每台服务器都可以使用新密钥加密任何数据keys 数组中的第一个条目,以便将其用于新编写的静态加密kube-apiserver 进程,以确保每个控制平面主机现在使用新密钥进行加密kubectl get secrets --all-namespaces -o json | kubectl replace -f -
以用新密钥加密所有现有的 Secret此示例演示如何停止静态加密 Secret API。如果你所加密的是其他 API 类型,请调整对应步骤来适配。
要禁用静态加密,请将 identity 提供程序作为加密配置文件中的第一个条目:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
# 在此列出你之前静态加密的任何其他资源
providers:
- identity: {} # 添加此行
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET> # 将其保留在适当的位置并确保它位于 "identity" 之后
然后运行以下命令以强制解密所有 Secret:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
将所有现有加密资源替换为不使用加密的支持数据后,你可以从 kube-apiserver
中删除加密设置。
你可以配置加密提供程序配置的自动重新加载。
该设置决定了 API 服务器
是仅在启动时加载一次为 --encryption-provider-config 指定的文件,
还是在每次你更改该文件时都自动加载。
启用此选项可允许你在不重启 API 服务器的情况下更改静态加密所需的密钥。
要允许自动重新加载,
可使用 --encryption-provider-config-automatic-reload=true 运行 API 服务器。
Kubernetes 中允许允许你写入持久性 API 资源数据的所有 API 都支持静态加密。 例如,你可以为 Secret 启用静态加密。 此静态加密是对 etcd 集群或运行 kube-apiserver 的主机上的文件系统的所有系统级加密的补充。
本文介绍如何停止静态加密 API 数据,以便 API 数据以未加密的形式存储。 你可能希望这样做以提高性能;但通常情况下,如果加密某些数据是个好主意,那么继续加密这些数据也是一个好主意。
此任务涵盖使用 Kubernetes API 存储的资源数据的加密。例如,你可以加密 Secret 对象,包括它们所包含的键值数据。
如果要加密安装到容器中的文件系统中的数据,则需要:
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
此任务假设你将 Kubernetes API 服务器组件以静态 Pod 方式运行在每个控制平面节点上。
集群的控制平面必须使用 etcd v3.x(主版本 3,任何次要版本)。
要加密自定义资源,你的集群必须运行 Kubernetes v1.26 或更高版本。
你应该有一些已加密的 API 数据。
kubectl version.
默认情况下,API 服务器使用一个名为 identity 的提供程序来存储资源的明文表示。
默认的 identity 提供程序不提供任何机密性保护。
kube-apiserver 进程接受参数 --encryption-provider-config,该参数指定了配置文件的路径。
如果你指定了一个路径,那么该文件的内容将控制 Kubernetes API 数据在 etcd 中的加密方式。
如果未指定,则表示你未启用静态加密。
该配置文件的格式是 YAML,表示名为
EncryptionConfiguration 的配置 API 类别。
你可以在静态加密配置中查看示例配置。
如果设置了 --encryption-provider-config,检查哪些资源(如 secrets)已配置为进行加密,
并查看所适用的是哪个提供程序。确保该资源类型首选的提供程序 不是 identity;
只有在想要禁用静态加密时,才可将 identity(无加密)设置为默认值。
验证资源首选的提供程序是否不是 identity,这意味着写入该类型资源的任何新信息都将按照配置被加密。
如果在任何资源的首选提供程序中看到 identity,这意味着这些资源将以非加密的方式写入 etcd 中。
本例展示如何停止对 Secret API 进行静态加密。如果你正在加密其他 API 类别,可以相应调整以下步骤。
首先,找到 API 服务器的配置文件。在每个控制平面节点上,kube-apiserver 的静态 Pod
清单指定了一个命令行参数 --encryption-provider-config。你很可能会发现此文件通过
hostPath 卷挂载到静态 Pod 中。
一旦你找到到此卷,就可以在节点文件系统中找到此文件并对其进行检查。
要禁用静态加密,将 identity 提供程序设置为加密配置文件中的第一个条目。
例如,如果你现有的 EncryptionConfiguration 文件内容如下:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
# 你加密时不要使用这个(无效)的示例密钥
- name: example
secret: 2KfZgdiq2K0g2YrYpyDYs9mF2LPZhQ==
然后将其更改为:
---
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity: {} # 增加这一行
- aescbc:
keys:
- name: example
secret: 2KfZgdiq2K0g2YrYpyDYs9mF2LPZhQ==
并重启此节点上的 kube-apiserver Pod。
如果你的集群中有多个 API 服务器,应轮流对每个 API 服务器部署这些更改。
确保在每个控制平面主机上使用相同的加密配置。
然后运行以下命令强制解密所有 Secret:
# 如果你正在解密不同类别的对象,请相应更改 "secrets"
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
一旦你用未加密的后台数据替换了所有现有的已加密资源,即可从 kube-apiserver 中删除这些加密设置。
要移除的命令行选项为:
--encryption-provider-config--encryption-provider-config-automatic-reload再次重启 kube-apiserver Pod 以应用新的配置。
如果你的集群中有多个 API 服务器,应再次轮流对每个 API 服务器部署这些更改。
确保在每个控制平面主机上使用相同的加密配置。
Kubernetes 核心组件(如 API 服务器、调度器、控制器管理器)在控制平面节点上运行。 但是插件必须在常规集群节点上运行。 其中一些插件对于功能完备的集群至关重要,例如 Heapster、DNS 和 UI。 如果关键插件被逐出(手动或作为升级等其他操作的副作用)或者变成挂起状态,集群可能会停止正常工作。 关键插件进入挂起状态的例子有:集群利用率过高;被逐出的关键插件 Pod 释放了空间,但该空间被之前悬决的 Pod 占用;由于其它原因导致节点上可用资源的总量发生变化。
注意,把某个 Pod 标记为关键 Pod 并不意味着完全避免该 Pod 被逐出;它只能防止该 Pod 变成永久不可用。 被标记为关键性的静态 Pod 不会被逐出。但是,被标记为关键性的非静态 Pod 总是会被重新调度。
要将 Pod 标记为关键性(critical),设置 Pod 的 priorityClassName 为 system-cluster-critical 或者 system-node-critical。
system-node-critical 是最高级别的可用性优先级,甚至比 system-cluster-critical 更高。
此页面展示如何配置和启用 ip-masq-agent。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
ip-masq-agent 配置 iptables 规则以隐藏位于集群节点 IP 地址后面的 Pod 的 IP 地址。
这通常在将流量发送到集群的 Pod
CIDR
范围之外的目的地时使用。
ip-masq-agent 配置 iptables 规则,以便在将流量发送到集群节点的 IP 和集群 IP
范围之外的目标时处理伪装节点或 Pod 的 IP 地址。这本质上隐藏了集群节点 IP 地址后面的
Pod IP 地址。在某些环境中,去往"外部"地址的流量必须从已知的机器地址发出。
例如,在 Google Cloud 中,任何到互联网的流量都必须来自 VM 的 IP。
使用容器时,如 Google Kubernetes Engine,从 Pod IP 发出的流量将被拒绝出站。
为了避免这种情况,我们必须将 Pod IP 隐藏在 VM 自己的 IP 地址后面 - 通常称为"伪装"。
默认情况下,代理配置为将
RFC 1918
指定的三个私有 IP 范围视为非伪装
CIDR。
这些范围是 10.0.0.0/8、172.16.0.0/12 和 192.168.0.0/16。
默认情况下,代理还将链路本地地址(169.254.0.0/16)视为非伪装 CIDR。
代理程序配置为每隔 60 秒从 /etc/config/ip-masq-agent 重新加载其配置,
这也是可修改的。
代理配置文件必须使用 YAML 或 JSON 语法编写,并且可能包含三个可选值:
nonMasqueradeCIDRs:
CIDR
表示法中的字符串列表,用于指定不需伪装的地址范围。masqLinkLocal:布尔值(true/false),表示是否为本地链路前缀 169.254.0.0/16
的流量提供伪装。默认为 false。resyncInterval:代理从磁盘重新加载配置的重试时间间隔。
例如 '30s',其中 's' 是秒,'ms' 是毫秒。10.0.0.0/8、172.16.0.0/12 和 192.168.0.0/16 范围内的流量不会被伪装。 任何其他流量(假设是互联网)将被伪装。 Pod 访问本地目的地的例子,可以是其节点的 IP 地址、另一节点的地址或集群的 IP 地址范围内的一个 IP 地址。 默认情况下,任何其他流量都将伪装。以下条目展示了 ip-masq-agent 的默认使用的规则:
iptables -t nat -L IP-MASQ-AGENT
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 172.16.0.0/12 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 192.168.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches) */ ADDRTYPE match dst-type !LOCAL
默认情况下,在 GCE/Google Kubernetes Engine 中,如果启用了网络策略,
或者你使用的集群 CIDR 不在 10.0.0.0/8 范围内,
则 ip-masq-agent 将在你的集群中运行。
如果你在其他环境中运行,可以将 ip-masq-agent
DaemonSet
添加到你的集群中。
通过运行以下 kubectl 指令创建 ip-masq-agent:
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/ip-masq-agent/master/ip-masq-agent.yaml
你必须同时将适当的节点标签应用于集群中希望代理运行的任何节点。
kubectl label nodes my-node node.kubernetes.io/masq-agent-ds-ready=true
更多信息可以通过 ip-masq-agent 文档这里找到。
在大多数情况下,默认的规则集应该足够;但是,如果你的集群不是这种情况,则可以创建并应用 ConfigMap 来自定义受影响的 IP 范围。 例如,要允许 ip-masq-agent 仅作用于 10.0.0.0/8,你可以在一个名为 "config" 的文件中创建以下 ConfigMap。
重要的是,该文件之所以被称为 config,是因为默认情况下,该文件将被用作
ip-masq-agent 查找的主键:
nonMasqueradeCIDRs:
- 10.0.0.0/8
resyncInterval: 60s
运行以下命令将 ConfigMap 添加到你的集群:
kubectl create configmap ip-masq-agent --from-file=config --namespace=kube-system
这将更新位于 /etc/config/ip-masq-agent 的一个文件,该文件以 resyncInterval
为周期定期检查并应用于集群节点。
重新同步间隔到期后,你应该看到你的更改在 iptables 规则中体现:
iptables -t nat -L IP-MASQ-AGENT
Chain IP-MASQ-AGENT (1 references)
target prot opt source destination
RETURN all -- anywhere 169.254.0.0/16 /* ip-masq-agent: cluster-local traffic should not be subject to MASQUERADE */ ADDRTYPE match dst-type !LOCAL
RETURN all -- anywhere 10.0.0.0/8 /* ip-masq-agent: cluster-local
MASQUERADE all -- anywhere anywhere /* ip-masq-agent: outbound traffic should be subject to MASQUERADE (this match must come after cluster-local CIDR matches) */ ADDRTYPE match dst-type !LOCAL
默认情况下,本地链路范围(169.254.0.0/16)也由 ip-masq agent 处理,
该代理设置适当的 iptables 规则。要使 ip-masq-agent 忽略本地链路,
可以在 ConfigMap 中将 masqLinkLocal 设置为 true。
nonMasqueradeCIDRs:
- 10.0.0.0/8
resyncInterval: 60s
masqLinkLocal: true
此示例演示如何限制一个名字空间中的存储使用量。
演示中用到了以下资源:ResourceQuota、 LimitRange 和 PersistentVolumeClaim。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
集群管理员代表用户群操作集群,该管理员希望控制单个名字空间可以消耗多少存储空间以控制成本。
该管理员想要限制:
将 LimitRange 添加到名字空间会为存储请求大小强制设置最小值和最大值。
存储是通过 PersistentVolumeClaim 来发起请求的。
执行限制范围控制的准入控制器会拒绝任何高于或低于管理员所设阈值的 PVC。
在此示例中,请求 10Gi 存储的 PVC 将被拒绝,因为它超过了最大 2Gi。
apiVersion: v1
kind: LimitRange
metadata:
name: storagelimits
spec:
limits:
- type: PersistentVolumeClaim
max:
storage: 2Gi
min:
storage: 1Gi
当底层存储提供程序需要某些最小值时,将会用到所设置最小存储请求值。 例如,AWS EBS volumes 的最低要求为 1Gi。
管理员可以限制某个名字空间中的 PVC 个数以及这些 PVC 的累计容量。 如果 PVC 的数目超过任一上限值,新的 PVC 将被拒绝。
在此示例中,名字空间中的第 6 个 PVC 将被拒绝,因为它超过了最大计数 5。 或者,当与上面的 2Gi 最大容量限制结合在一起时, 意味着 5Gi 的最大配额不能支持 3 个都是 2Gi 的 PVC。 后者实际上是向名字空间请求 6Gi 容量,而该名字空间已经设置上限为 5Gi。
apiVersion: v1
kind: ResourceQuota
metadata:
name: storagequota
spec:
hard:
persistentvolumeclaims: "5"
requests.storage: "5Gi"
限制范围对象可以用来设置可请求的存储量上限,而资源配额对象则可以通过申领计数和 累计存储容量有效地限制名字空间耗用的存储量。 这两种机制使得集群管理员能够规划其集群存储预算而不会发生任一项目超量分配的风险。
一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager) 允许将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
通过分离 Kubernetes 和底层云基础设置之间的互操作性逻辑,
cloud-controller-manager 组件使云提供商能够以不同于 Kubernetes 主项目的步调发布新特征。
作为云驱动提取工作
的一部分,所有特定于云的控制器都必须移出 kube-controller-manager。
所有在 kube-controller-manager 中运行云控制器的现有集群必须迁移到特定于云厂商的
cloud-controller-manager 中运行这些控制器。
领导者迁移(Leader Migration)提供了一种机制,使得 HA 集群可以通过这两个组件之间共享资源锁,
在升级多副本的控制平面时,安全地将“特定于云”的控制器从 kube-controller-manager 迁移到
cloud-controller-manager。
对于单节点控制平面,或者在升级过程中可以容忍控制器管理器不可用的情况,则不需要领导者迁移,
亦可以忽略本指南。
领导者迁移可以通过在 kube-controller-manager 或 cloud-controller-manager 上设置
--enable-leader-migration 来启用。
领导者迁移仅在升级期间适用,并且在升级完成后可以安全地禁用或保持启用状态。
本指南将引导你手动将控制平面从内置的云驱动的 kube-controller-manager 升级为
同时运行 kube-controller-manager 和 cloud-controller-manager。
如果使用某种工具来部署和管理集群,请参阅对应工具和云驱动的文档以获取迁移的具体说明。
假定控制平面正在运行 Kubernetes 版本 N,要升级到版本 N+1。
尽管可以在同一版本内进行迁移,但理想情况下,迁移应作为升级的一部分执行,
以便可以配置的变更可以与发布版本变化对应起来。
N 和 N+1 的确切版本值取决于各个云厂商。例如,如果云厂商构建了一个可与 Kubernetes 1.24
配合使用的 cloud-controller-manager,则 N 可以为 1.23,N+1 可以为 1.24。
控制平面节点应运行 kube-controller-manager 并启用领导者选举,这也是默认设置。
在版本 N 中,树内云驱动必须设置 --cloud-provider 标志,而且 cloud-controller-manager
应该尚未部署。
树外云驱动必须已经构建了一个实现了领导者迁移的 cloud-controller-manager。
如果云驱动导入了 v0.21.0 或更高版本的 k8s.io/cloud-provider 和 k8s.io/controller-manager,
则可以进行领导者迁移。
但是,对 v0.22.0 以下的版本,领导者迁移是一项 Alpha 阶段功能,需要在 cloud-controller-manager
中启用特性门控 ControllerManagerLeaderMigration。
本指南假定每个控制平面节点的 kubelet 以静态 Pod 的形式启动 kube-controller-manager
和 cloud-controller-manager,静态 Pod 的定义在清单文件中。
如果组件以其他设置运行,请相应地调整这里的步骤。
关于鉴权,本指南假定集群使用 RBAC。如果其他鉴权模式授予 kube-controller-manager
和 cloud-controller-manager 组件权限,请以与该模式匹配的方式授予所需的访问权限。
控制器管理器的默认权限仅允许访问其主租约(Lease)对象。为了使迁移正常进行, 需要授权它访问其他 Lease 对象。
你可以通过修改 system::leader-locking-kube-controller-manager 角色来授予
kube-controller-manager 对 Lease API 的完全访问权限。
本任务指南假定迁移 Lease 的名称为 cloud-provider-extraction-migration。
kubectl patch -n kube-system role 'system::leader-locking-kube-controller-manager' -p '{"rules": [ {"apiGroups":[ "coordination.k8s.io"], "resources": ["leases"], "resourceNames": ["cloud-provider-extraction-migration"], "verbs": ["create", "list", "get", "update"] } ]}' --type=merge
对 system::leader-locking-cloud-controller-manager 角色执行相同的操作。
kubectl patch -n kube-system role 'system::leader-locking-cloud-controller-manager' -p '{"rules": [ {"apiGroups":[ "coordination.k8s.io"], "resources": ["leases"], "resourceNames": ["cloud-provider-extraction-migration"], "verbs": ["create", "list", "get", "update"] } ]}' --type=merge
领导者迁移可以选择使用一个表示如何将控制器分配给不同管理器的配置文件。
目前,对于树内云驱动,kube-controller-manager 运行 route、service 和
cloud-node-lifecycle。以下示例配置显示的是这种分配。
领导者迁移可以不指定配置的情况下启用。请参阅默认配置 以获取更多详细信息。
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
controllerLeaders:
- name: route
component: kube-controller-manager
- name: service
component: kube-controller-manager
- name: cloud-node-lifecycle
component: kube-controller-manager
或者,由于控制器可以在任一控制器管理器下运行,因此将双方的 component 设置为 *
可以使迁移双方的配置文件保持一致。
# 通配符版本
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
controllerLeaders:
- name: route
component: *
- name: service
component: *
- name: cloud-node-lifecycle
component: *
在每个控制平面节点上,请将如上内容保存到 /etc/leadermigration.conf 中,
并更新 kube-controller-manager 清单,以便将文件挂载到容器内的同一位置。
另外,请更新同一清单,添加以下参数:
--enable-leader-migration 在控制器管理器上启用领导者迁移--leader-migration-config=/etc/leadermigration.conf 设置配置文件在每个节点上重新启动 kube-controller-manager。这时,kube-controller-manager
已启用领导者迁移,为迁移准备就绪。
在版本 N+1 中,如何将控制器分配给不同管理器的预期分配状态可以由新的配置文件表示,
如下所示。请注意,各个 controllerLeaders 的 component 字段从 kube-controller-manager
更改为 cloud-controller-manager。
或者,使用上面提到的通配符版本,它具有相同的效果。
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
controllerLeaders:
- name: route
component: cloud-controller-manager
- name: service
component: cloud-controller-manager
- name: cloud-node-lifecycle
component: cloud-controller-manager
当创建版本 N+1 的控制平面节点时,应将如上内容写入到 /etc/leadermigration.conf。
你需要更新 cloud-controller-manager 的清单,以与版本 N 的 kube-controller-manager
相同的方式挂载配置文件。
类似地,添加 --enable-leader-migration
和 --leader-migration-config=/etc/leadermigration.conf 到 cloud-controller-manager
的参数中。
使用已更新的 cloud-controller-manager 清单创建一个新的 N+1 版本的控制平面节点,
同时设置 kube-controller-manager 的 --cloud-provider 标志为 external。
版本为 N+1 的 kube-controller-manager 不能启用领导者迁移,
因为在使用外部云驱动的情况下,它不再运行已迁移的控制器,因此不参与迁移。
请参阅云控制器管理器管理
了解有关如何部署 cloud-controller-manager 的更多细节。
现在,控制平面同时包含 N 和 N+1 版本的节点。
版本 N 的节点仅运行 kube-controller-manager,而版本 N+1 的节点同时运行
kube-controller-manager 和 cloud-controller-manager。
根据配置所指定,已迁移的控制器在版本 N 的 kube-controller-manager 或版本
N+1 的 cloud-controller-manager 下运行,具体取决于哪个控制器管理器拥有迁移租约对象。
任何时候都不会有同一个控制器在两个控制器管理器下运行。
以滚动的方式创建一个新的版本为 N+1 的控制平面节点,并将版本 N 中的一个关闭,
直到控制平面仅包含版本为 N+1 的节点。
如果需要从 N+1 版本回滚到 N 版本,则将 kube-controller-manager 启用了领导者迁移的、
且版本为 N 的节点添加回控制平面,每次替换 N+1 版本中的一个,直到只有版本 N 的节点为止。
现在,控制平面已经完成升级,同时运行版本 N+1 的 kube-controller-manager
和 cloud-controller-manager。领导者迁移的任务已经结束,可以被安全地禁用以节省一个
Lease 资源。在将来可以安全地重新启用领导者迁移,以完成回滚。
在滚动管理器中,更新 cloud-controller-manager 的清单以同时取消设置
--enable-leader-migration 和 --leader-migration-config= 标志,并删除
/etc/leadermigration.conf 的挂载,最后删除 /etc/leadermigration.conf。
要重新启用领导者迁移,请重新创建配置文件,并将其挂载和启用领导者迁移的标志添加回到
cloud-controller-manager。
从 Kubernetes 1.22 开始,领导者迁移提供了一个默认配置,它适用于控制器与管理器间默认的分配关系。
可以通过设置 --enable-leader-migration,但不设置 --leader-migration-config=
来启用默认配置。
对于 kube-controller-manager 和 cloud-controller-manager,如果没有用参数来启用树内云驱动或者改变控制器属主,
则可以使用默认配置来避免手动创建配置文件。
如果你的云供应商提供了节点 IPAM 控制器的实现,你应该切换到 cloud-controller-manager 中的实现。
通过在其标志中添加 --controllers=*,-nodeipam 来禁用 N+1 版本的 kube-controller-manager 中的节点 IPAM 控制器。
然后将 nodeipam 添加到迁移的控制器列表中。
# 通配符版本,带有 nodeipam
kind: LeaderMigrationConfiguration
apiVersion: controllermanager.config.k8s.io/v1
leaderName: cloud-provider-extraction-migration
controllerLeaders:
- name: route
component: *
- name: service
component: *
- name: cloud-node-lifecycle
component: *
- name: nodeipam
- component: *
Kubernetes 名字空间 有助于不同的项目、团队或客户去共享 Kubernetes 集群。
名字空间通过以下方式实现这点:
使用多个名字空间是可选的。
此示例演示了如何使用 Kubernetes 名字空间细分集群。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
此示例作如下假设:
默认情况下,Kubernetes 集群会在配置集群时实例化一个默认名字空间,用以存放集群所使用的默认 Pod、Service 和 Deployment 集合。
假设你有一个新的集群,你可以通过执行以下操作来检查可用的名字空间:
kubectl get namespaces
NAME STATUS AGE
default Active 13m
在本练习中,我们将创建两个额外的 Kubernetes 名字空间来保存我们的内容。
我们假设一个场景,某组织正在使用共享的 Kubernetes 集群来支持开发和生产:
开发团队希望在集群中维护一个空间,以便他们可以查看用于构建和运行其应用程序的 Pod、Service 和 Deployment 列表。在这个空间里,Kubernetes 资源被自由地加入或移除, 对谁能够或不能修改资源的限制被放宽,以实现敏捷开发。
运维团队希望在集群中维护一个空间,以便他们可以强制实施一些严格的规程, 对谁可以或谁不可以操作运行生产站点的 Pod、Service 和 Deployment 集合进行控制。
该组织可以遵循的一种模式是将 Kubernetes 集群划分为两个名字空间:development 和 production。
让我们创建两个新的名字空间来保存我们的工作。
文件 namespace-dev.yaml 描述了 development 名字空间:
apiVersion: v1
kind: Namespace
metadata:
name: development
labels:
name: development
使用 kubectl 创建 development 名字空间。
kubectl create -f https://k8s.io/examples/admin/namespace-dev.yaml
将下列的内容保存到文件 namespace-prod.yaml 中,
这些内容是对 production 名字空间的描述:
apiVersion: v1
kind: Namespace
metadata:
name: production
labels:
name: production
让我们使用 kubectl 创建 production 名字空间。
kubectl create -f https://k8s.io/examples/admin/namespace-prod.yaml
为了确保一切正常,我们列出集群中的所有名字空间。
kubectl get namespaces --show-labels
NAME STATUS AGE LABELS
default Active 32m <none>
development Active 29s name=development
production Active 23s name=production
Kubernetes 名字空间为集群中的 Pod、Service 和 Deployment 提供了作用域。
与一个名字空间交互的用户不会看到另一个名字空间中的内容。
为了演示这一点,让我们在 development 名字空间中启动一个简单的 Deployment 和 Pod。
我们首先检查一下当前的上下文:
kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://130.211.122.180
name: lithe-cocoa-92103_kubernetes
contexts:
- context:
cluster: lithe-cocoa-92103_kubernetes
user: lithe-cocoa-92103_kubernetes
name: lithe-cocoa-92103_kubernetes
current-context: lithe-cocoa-92103_kubernetes
kind: Config
preferences: {}
users:
- name: lithe-cocoa-92103_kubernetes
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
token: 65rZW78y8HbwXXtSXuUw9DbP4FLjHi4b
- name: lithe-cocoa-92103_kubernetes-basic-auth
user:
password: h5M0FtUUIflBSdI7
username: admin
kubectl config current-context
lithe-cocoa-92103_kubernetes
下一步是为 kubectl 客户端定义一个上下文,以便在每个名字空间中工作。 "cluster" 和 "user" 字段的值将从当前上下文中复制。
kubectl config set-context dev --namespace=development \
--cluster=lithe-cocoa-92103_kubernetes \
--user=lithe-cocoa-92103_kubernetes
kubectl config set-context prod --namespace=production \
--cluster=lithe-cocoa-92103_kubernetes \
--user=lithe-cocoa-92103_kubernetes
默认情况下,上述命令会添加两个上下文到 .kube/config 文件中。
你现在可以查看上下文并根据你希望使用的名字空间并在这两个新的请求上下文之间切换。
查看新的上下文:
kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https://130.211.122.180
name: lithe-cocoa-92103_kubernetes
contexts:
- context:
cluster: lithe-cocoa-92103_kubernetes
user: lithe-cocoa-92103_kubernetes
name: lithe-cocoa-92103_kubernetes
- context:
cluster: lithe-cocoa-92103_kubernetes
namespace: development
user: lithe-cocoa-92103_kubernetes
name: dev
- context:
cluster: lithe-cocoa-92103_kubernetes
namespace: production
user: lithe-cocoa-92103_kubernetes
name: prod
current-context: lithe-cocoa-92103_kubernetes
kind: Config
preferences: {}
users:
- name: lithe-cocoa-92103_kubernetes
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
token: 65rZW78y8HbwXXtSXuUw9DbP4FLjHi4b
- name: lithe-cocoa-92103_kubernetes-basic-auth
user:
password: h5M0FtUUIflBSdI7
username: admin
让我们切换到 development 名字空间进行操作。
kubectl config use-context dev
你可以使用下列命令验证当前上下文:
kubectl config current-context
dev
此时,我们从命令行向 Kubernetes 集群发出的所有请求都限定在 development 名字空间中。
让我们创建一些内容。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: snowflake
name: snowflake
spec:
replicas: 2
selector:
matchLabels:
app: snowflake
template:
metadata:
labels:
app: snowflake
spec:
containers:
- image: registry.k8s.io/serve_hostname
imagePullPolicy: Always
name: snowflake
应用清单文件来创建 Deployment。
kubectl apply -f https://k8s.io/examples/admin/snowflake-deployment.yaml
我们创建了一个副本大小为 2 的 Deployment,该 Deployment 运行名为 snowflake 的 Pod,
其中包含一个仅提供主机名服务的基本容器。
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app=snowflake
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
这很棒,开发人员可以做他们想要的事情,而不必担心影响 production 名字空间中的内容。
让我们切换到 production 名字空间,展示一个名字空间中的资源如何对另一个名字空间不可见。
kubectl config use-context prod
production 名字空间应该是空的,下列命令应该返回的内容为空。
kubectl get deployment
kubectl get pods
生产环境需要以放牛的方式运维,让我们创建一些名为 cattle 的 Pod。
kubectl create deployment cattle --image=registry.k8s.io/serve_hostname --replicas=5
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l run=cattle
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
此时,应该很清楚的展示了用户在一个名字空间中创建的资源对另一个名字空间是不可见的。
随着 Kubernetes 中的策略支持的发展,我们将扩展此场景,以展示如何为每个名字空间提供不同的授权规则。
etcd 是 一致且高可用的键值存储,用作 Kubernetes 所有集群数据的后台数据库。
如果你的 Kubernetes 集群使用 etcd 作为其后台数据库, 请确保你针对这些数据有一份 备份计划。
你可以在官方文档中找到有关 etcd 的深入知识。
你需要有一个 Kubernetes 集群,并且必须配置 kubectl 命令行工具以与你的集群通信。 建议参照本指南在至少有两个不充当控制平面的节点上运行此任务。如果你还没有集群, 你可以使用 minikube 创建一个。
运行的 etcd 集群个数成员为奇数。
etcd 是一个基于领导者(Leader-Based)的分布式系统。确保主节点定期向所有从节点发送心跳,以保持集群稳定。
确保不发生资源不足。
集群的性能和稳定性对网络和磁盘 I/O 非常敏感。任何资源匮乏都会导致心跳超时, 从而导致集群的不稳定。不稳定的情况表明没有选出任何主节点。 在这种情况下,集群不能对其当前状态进行任何更改,这意味着不能调度新的 Pod。
保持 etcd 集群的稳定对 Kubernetes 集群的稳定性至关重要。 因此,请在专用机器或隔离环境上运行 etcd 集群, 以满足所需资源需求。
在生产环境中运行的 etcd 最低推荐版本为 3.4.22+ 和 3.5.6+。
使用有限的资源运行 etcd 只适合测试目的。为了在生产中部署,需要先进的硬件配置。 在生产中部署 etcd 之前,请查看所需资源参考文档。
本节介绍如何启动单节点和多节点 etcd 集群。
只为测试目的使用单节点 etcd 集群。
运行以下命令:
etcd --listen-client-urls=http://$PRIVATE_IP:2379 \
--advertise-client-urls=http://$PRIVATE_IP:2379
使用参数 --etcd-servers=$PRIVATE_IP:2379 启动 Kubernetes API 服务器。
确保将 PRIVATE_IP 设置为 etcd 客户端 IP。
出于耐用性和高可用性考量,在生产环境中应以多节点集群的方式运行 etcd,并且定期备份。 建议在生产环境中使用五个成员的集群。 有关该内容的更多信息,请参阅常见问题文档。
可以通过静态成员信息或动态发现的方式配置 etcd 集群。 有关集群的详细信息,请参阅 etcd 集群文档。
例如,考虑运行以下客户端 URL 的五个成员的 etcd 集群:http://$IP1:2379、
http://$IP2:2379、http://$IP3:2379、http://$IP4:2379 和 http://$IP5:2379。
要启动 Kubernetes API 服务器:
运行以下命令:
etcd --listen-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379 --advertise-client-urls=http://$IP1:2379,http://$IP2:2379,http://$IP3:2379,http://$IP4:2379,http://$IP5:2379
使用参数 --etcd-servers=$IP1:2379,$IP2:2379,$IP3:2379,$IP4:2379,$IP5:2379
启动 Kubernetes API 服务器。
确保将 IP<n> 变量设置为客户端 IP 地址。
要运行负载均衡的 etcd 集群:
$LB。--etcd-servers=$LB:2379 启动 Kubernetes API 服务器。对 etcd 的访问相当于集群中的 root 权限,因此理想情况下只有 API 服务器才能访问它。 考虑到数据的敏感性,建议只向需要访问 etcd 集群的节点授予权限。
想要确保 etcd 的安全,可以设置防火墙规则或使用 etcd 提供的安全特性,这些安全特性依赖于 x509 公钥基础设施(PKI)。
首先,通过生成密钥和证书对来建立安全的通信通道。
例如,使用密钥对 peer.key 和 peer.cert 来保护 etcd 成员之间的通信,
而 client.key 和 client.cert 用于保护 etcd 与其客户端之间的通信。
请参阅 etcd 项目提供的示例脚本,
以生成用于客户端身份验证的密钥对和 CA 文件。
若要使用安全对等通信对 etcd 进行配置,请指定参数 --peer-key-file=peer.key
和 --peer-cert-file=peer.cert,并使用 HTTPS 作为 URL 模式。
类似地,要使用安全客户端通信对 etcd 进行配置,请指定参数 --key-file=k8sclient.key
和 --cert-file=k8sclient.cert,并使用 HTTPS 作为 URL 模式。
使用安全通信的客户端命令的示例:
ETCDCTL_API=3 etcdctl --endpoints 10.2.0.9:2379 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
member list
配置安全通信后,使用 TLS 身份验证来限制只有 Kubernetes API 服务器可以访问 etcd 集群。
例如,考虑由 CA etcd.ca 信任的密钥对 k8sclient.key 和 k8sclient.cert。
当 etcd 配置为 --client-cert-auth 和 TLS 时,它使用系统 CA 或由 --trusted-ca-file
参数传入的 CA 验证来自客户端的证书。指定参数 --client-cert-auth=true 和
--trusted-ca-file=etcd.ca 将限制对具有证书 k8sclient.cert 的客户端的访问。
一旦正确配置了 etcd,只有具有有效证书的客户端才能访问它。要让 Kubernetes API 服务器访问,
可以使用参数 --etcd-certfile=k8sclient.cert、--etcd-keyfile=k8sclient.key 和 --etcd-cafile=ca.cert 配置。
Kubernetes 没有为 etcd 提供身份验证的计划。
etcd 集群通过容忍少数成员故障实现高可用性。 但是,要改善集群的整体健康状况,请立即替换失败的成员。当多个成员失败时,逐个替换它们。 替换失败成员需要两个步骤:删除失败成员和添加新成员。
虽然 etcd 在内部保留唯一的成员 ID,但建议为每个成员使用唯一的名称,以避免人为错误。
例如,考虑一个三成员的 etcd 集群。假定 URL 分别为:member1=http://10.0.0.1、member2=http://10.0.0.2
和 member3=http://10.0.0.3。当 member1 失败时,将其替换为 member4=http://10.0.0.4。
获取失败的 member1 的成员 ID:
etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member list
显示以下信息:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379
91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379
fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379
执行以下操作之一:
--etcd-servers 标志中移除删除失败的成员,然后重新启动每个 Kubernetes API 服务器。移除失败的成员:
etcdctl member remove 8211f1d0f64f3269
显示以下信息:
Removed member 8211f1d0f64f3269 from cluster
增加新成员:
etcdctl member add member4 --peer-urls=http://10.0.0.4:2380
显示以下信息:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4
在 IP 为 10.0.0.4 的机器上启动新增加的成员:
export ETCD_NAME="member4"
export ETCD_INITIAL_CLUSTER="member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380"
export ETCD_INITIAL_CLUSTER_STATE=existing
etcd [flags]
执行以下操作之一:
--etcd-servers 标志,然后重新启动每个 Kubernetes API 服务器。有关集群重新配置的详细信息,请参阅 etcd 重构文档。
所有 Kubernetes 对象都存储在 etcd 中。 定期备份 etcd 集群数据对于在灾难场景(例如丢失所有控制平面节点)下恢复 Kubernetes 集群非常重要。 快照文件包含所有 Kubernetes 状态和关键信息。为了保证敏感的 Kubernetes 数据的安全,可以对快照文件进行加密。
备份 etcd 集群可以通过两种方式完成:etcd 内置快照和卷快照。
etcd 支持内置快照。快照可以从使用 etcdctl snapshot save 命令的活动成员中创建,
也可以通过从 etcd 数据目录
复制 member/snap/db 文件,该 etcd 数据目录目前没有被 etcd 进程使用。创建快照不会影响成员的性能。
下面是一个示例,用于创建 $ENDPOINT 所提供的键空间的快照到文件 snapshot.db:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
验证快照:
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshot.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
如果 etcd 运行在支持备份的存储卷(如 Amazon Elastic Block 存储)上,则可以通过创建存储卷的快照来备份 etcd 数据。
我们还可以使用 etcdctl 提供的各种选项来制作快照。例如:
ETCDCTL_API=3 etcdctl -h
列出 etcdctl 可用的各种选项。例如,你可以通过指定端点、证书和密钥来制作快照,如下所示:
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
snapshot save <backup-file-location>
可以从 etcd Pod 的描述中获得 trusted-ca-file、cert-file 和 key-file。
通过交换性能,对 etcd 集群扩容可以提高可用性。缩放不会提高集群性能和能力。 一般情况下不要扩大或缩小 etcd 集群的集合。不要为 etcd 集群配置任何自动缩放组。 强烈建议始终在任何官方支持的规模上运行生产 Kubernetes 集群时使用静态的五成员 etcd 集群。
合理的扩展是在需要更高可靠性的情况下,将三成员集群升级为五成员集群。 请参阅 etcd 重构文档 以了解如何将成员添加到现有集群中的信息。
etcd 支持从 major.minor 或其他不同 patch 版本的 etcd 进程中获取的快照进行恢复。 还原操作用于恢复失败的集群的数据。
在启动还原操作之前,必须有一个快照文件。它可以是来自以前备份操作的快照文件, 也可以是来自剩余数据目录的快照文件。
在恢复集群时,使用 --data-dir 选项来指定集群应被恢复到哪个文件夹。
ETCDCTL_API=3 etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
其中 <data-dir-location> 是将在恢复过程中创建的目录。
另一个例子是先导出 ETCDCTL_API 环境变量:
export ETCDCTL_API=3
etcdctl --data-dir <data-dir-location> snapshot restore snapshot.db
如果 <data-dir-location> 与之前的文件夹相同,请先删除此文件夹并停止 etcd 进程,再恢复集群。
否则,需要在恢复后更改 etcd 配置并重新启动 etcd 进程才能使用新的数据目录。
有关从快照文件还原集群的详细信息和示例,请参阅 etcd 灾难恢复文档。
如果还原的集群的访问 URL 与前一个集群不同,则必须相应地重新配置 Kubernetes API 服务器。
在本例中,使用参数 --etcd-servers=$NEW_ETCD_CLUSTER 而不是参数 --etcd-servers=$OLD_ETCD_CLUSTER
重新启动 Kubernetes API 服务器。用相应的 IP 地址替换 $NEW_ETCD_CLUSTER 和 $OLD_ETCD_CLUSTER。
如果在 etcd 集群前面使用负载均衡,则可能需要更新负载均衡器。
如果大多数 etcd 成员永久失败,则认为 etcd 集群失败。在这种情况下,Kubernetes 不能对其当前状态进行任何更改。 虽然已调度的 Pod 可能继续运行,但新的 Pod 无法调度。在这种情况下, 恢复 etcd 集群并可能需要重新配置 Kubernetes API 服务器以修复问题。
如果集群中正在运行任何 API 服务器,则不应尝试还原 etcd 的实例。相反,请按照以下步骤还原 etcd:
我们还建议重启所有组件(例如 kube-scheduler、kube-controller-manager、kubelet),
以确保它们不会依赖一些过时的数据。请注意,实际中还原会花费一些时间。
在还原过程中,关键组件将丢失领导锁并自行重启。
有关 etcd 升级的更多详细信息,请参阅 etcd 升级文档。
在开始升级之前,请先备份你的 etcd 集群。
有关 etcd 维护的更多详细信息,请参阅 etcd 维护文档。
碎片整理是一种昂贵的操作,因此应尽可能少地执行此操作。 另一方面,也有必要确保任何 etcd 成员都不会超过存储配额。 Kubernetes 项目建议在执行碎片整理时, 使用诸如 etcd-defrag 之类的工具。
你还可以将碎片整理工具作为 Kubernetes CronJob 运行,以确保定期进行碎片整理。
有关详细信息,请参阅
etcd-defrag-cronjob.yaml。
Kubernetes 的节点可以按照 Capacity 调度。默认情况下 pod 能够使用节点全部可用容量。
这是个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程。
除非为这些系统守护进程留出资源,否则它们将与 Pod 争夺资源并导致节点资源短缺问题。
kubelet 公开了一个名为 'Node Allocatable' 的特性,有助于为系统守护进程预留计算资源。
Kubernetes 推荐集群管理员按照每个节点上的工作负载密度配置 'Node Allocatable'。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.8. 要获知版本信息,请输入kubectl version.
你的 kubernetes 服务器版本必须至少是 1.17 版本,才能使用 kubelet
命令行选项 --reserved-cpus 设置显式预留 CPU 列表。

Kubernetes 节点上的 'Allocatable' 被定义为 Pod 可用计算资源量。 调度器不会超额申请 'Allocatable'。 目前支持 'CPU'、'memory' 和 'ephemeral-storage' 这几个参数。
可分配的节点暴露为 API 中 v1.Node 对象的一部分,也是 CLI 中
kubectl describe node 的一部分。
在 kubelet 中,可以为两类系统守护进程预留资源。
为了恰当地在节点范围实施节点可分配约束,你必须通过 --cgroups-per-qos
标志启用新的 cgroup 层次结构。这个标志是默认启用的。
启用后,kubelet 将在其管理的 cgroup 层次结构中创建所有终端用户的 Pod。
kubelet 支持在主机上使用 cgroup 驱动操作 cgroup 层次结构。
该驱动通过 --cgroup-driver 标志进行配置。
支持的参数值如下:
cgroupfs 是默认的驱动,在主机上直接操作 cgroup 文件系统以对 cgroup
沙箱进行管理。systemd 是可选的驱动,使用 init 系统支持的资源的瞬时切片管理
cgroup 沙箱。取决于相关容器运行时的配置,操作员可能需要选择一个特定的 cgroup 驱动来保证系统正常运行。
例如,如果操作员使用 containerd 运行时提供的 systemd cgroup 驱动时,
必须配置 kubelet 使用 systemd cgroup 驱动。
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]--kube-reserved-cgroup=kube-reserved 用来给诸如 kubelet、容器运行时、节点问题监测器等
Kubernetes 系统守护进程记述其资源预留值。
该配置并非用来给以 Pod 形式运行的系统守护进程预留资源。kube-reserved
通常是节点上 Pod 密度 的函数。
除了 cpu、内存 和 ephemeral-storage 之外,pid 可用来指定为
Kubernetes 系统守护进程预留指定数量的进程 ID。
要选择性地对 Kubernetes 系统守护进程上执行 kube-reserved 保护,需要把 kubelet 的
--kube-reserved-cgroup 标志的值设置为 kube 守护进程的父控制组。
推荐将 Kubernetes 系统守护进程放置于顶级控制组之下(例如 systemd 机器上的
runtime.slice)。
理想情况下每个系统守护进程都应该在其自己的子控制组中运行。
请参考这个设计方案,
进一步了解关于推荐控制组层次结构的细节。
请注意,如果 --kube-reserved-cgroup 不存在,Kubelet 将 不会 创建它。
如果指定了一个无效的 cgroup,Kubelet 将会无法启动。就 systemd cgroup 驱动而言,
你要为所定义的 cgroup 设置名称时要遵循特定的模式:
所设置的名字应该是你为 --kube-reserved-cgroup 所给的参数值加上 .slice 后缀。
--system-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]--system-reserved-cgroup=system-reserved 用于为诸如 sshd、udev 等系统守护进程记述其资源预留值。
system-reserved 也应该为 kernel 预留 内存,因为目前 kernel
使用的内存并不记在 Kubernetes 的 Pod 上。
同时还推荐为用户登录会话预留资源(systemd 体系中的 user.slice)。
除了 cpu、内存 和 ephemeral-storage 之外,pid 可用来指定为
Kubernetes 系统守护进程预留指定数量的进程 ID。
要想为系统守护进程上可选地实施 system-reserved 约束,请指定 kubelet 的
--system-reserved-cgroup 标志值为 OS 系统守护进程的父级控制组。
推荐将 OS 系统守护进程放在一个顶级控制组之下(例如 systemd 机器上的
system.slice)。
请注意,如果 --system-reserved-cgroup 不存在,kubelet 不会 创建它。
如果指定了无效的 cgroup,kubelet 将会失败。就 systemd cgroup 驱动而言,
你在指定 cgroup 名字时要遵循特定的模式:
该名字应该是你为 --system-reserved-cgroup 参数所设置的值加上 .slice 后缀。
Kubernetes v1.17 [stable]
Kubelet 标志: --reserved-cpus=0-3
KubeletConfiguration 标志:reservedSystemCPUs: 0-3
reserved-cpus 旨在为操作系统守护程序和 Kubernetes 系统守护程序预留一组明确指定编号的 CPU。
reserved-cpus 适用于不打算针对 cpuset 资源为操作系统守护程序和 Kubernetes
系统守护程序定义独立的顶级 cgroups 的系统。
如果 Kubelet 没有 指定参数 --system-reserved-cgroup 和 --kube-reserved-cgroup,
则 reserved-cpus 的设置将优先于 --kube-reserved 和 --system-reserved 选项。
此选项是专门为电信/NFV 用例设计的,在这些用例中不受控制的中断或计时器可能会影响其工作负载性能。 你可以使用此选项为系统或 Kubernetes 守护程序以及中断或计时器显式定义 cpuset, 这样系统上的其余 CPU 可以专门用于工作负载,因不受控制的中断或计时器的影响得以降低。 要将系统守护程序、Kubernetes 守护程序和中断或计时器移动到此选项定义的显式 cpuset 上,应使用 Kubernetes 之外的其他机制。 例如:在 CentOS 系统中,可以使用 tuned 工具集来执行此操作。
Kubelet 标志:--eviction-hard=[memory.available<500Mi]
节点级别的内存压力将导致系统内存不足,这将影响到整个节点及其上运行的所有 Pod。
节点可以暂时离线直到内存已经回收为止。为了防止系统内存不足(或减少系统内存不足的可能性),
kubelet 提供了资源不足管理。
驱逐操作只支持 memory 和 ephemeral-storage。
通过 --eviction-hard 标志预留一些内存后,当节点上的可用内存降至预留值以下时,
kubelet 将尝试驱逐 Pod。
如果节点上不存在系统守护进程,Pod 将不能使用超过 capacity-eviction-hard 所指定的资源量。
因此,为驱逐而预留的资源对 Pod 是不可用的。
Kubelet 标志:--enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
调度器将 'Allocatable' 视为 Pod 可用的 capacity(资源容量)。
kubelet 默认对 Pod 执行 'Allocatable' 约束。
无论何时,如果所有 Pod 的总用量超过了 'Allocatable',驱逐 Pod 的措施将被执行。
有关驱逐策略的更多细节可以在节点压力驱逐页找到。
可通过设置 kubelet --enforce-node-allocatable 标志值为 pods 控制这个措施。
可选地,通过在同一标志中同时指定 kube-reserved 和 system-reserved 值,
可以使 kubelet 强制实施 kube-reserved 和 system-reserved 约束。
请注意,要想执行 kube-reserved 或者 system-reserved 约束,
需要对应设置 --kube-reserved-cgroup 或者 --system-reserved-cgroup。
系统守护进程一般会被按照类似
Guaranteed 的 Pod
一样对待。
系统守护进程可以在与其对应的控制组中出现突发资源用量,这一行为要作为 Kubernetes 部署的一部分进行管理。
例如,kubelet 应该有它自己的控制组并和容器运行时共享 kube-reserved 资源。
不过,如果执行了 kube-reserved 约束,则 kubelet 不可出现突发负载并用光节点的所有可用资源。
在执行 system-reserved 预留策略时请加倍小心,因为它可能导致节点上的关键系统服务出现 CPU 资源短缺、
因为内存不足而被终止或者无法在节点上创建进程。
建议只有当用户详尽地描述了他们的节点以得出精确的估计值,
并且对该组中进程因内存不足而被杀死时,有足够的信心将其恢复时,
才可以强制执行 system-reserved 策略。
pods 上执行 'Allocatable' 约束。kube-reserved 策略。system-reserved 策略。随着时间推进和越来越多特性被加入,kube 系统守护进程对资源的需求可能也会增加。
以后 Kubernetes 项目将尝试减少对节点系统守护进程的利用,但目前这件事的优先级并不是最高。
所以,将来的发布版本中 Allocatable 容量是有可能降低的。
这是一个用于说明节点可分配(Node Allocatable)计算方式的示例:
32Gi memory、16 CPU 和 100Gi Storage 资源--kube-reserved 被设置为 cpu=1,memory=2Gi,ephemeral-storage=1Gi--system-reserved 被设置为 cpu=500m,memory=1Gi,ephemeral-storage=1Gi--eviction-hard 被设置为 memory.available<500Mi,nodefs.available<10%在这个场景下,'Allocatable' 将会是 14.5 CPUs、28.5Gi 内存以及 88Gi 本地存储。
调度器保证这个节点上的所有 Pod 的内存 requests 总量不超过 28.5Gi,存储不超过 '88Gi'。
当 Pod 的内存使用总量超过 28.5Gi 或者磁盘使用总量超过 88Gi 时,kubelet 将会驱逐它们。
如果节点上的所有进程都尽可能多地使用 CPU,则 Pod 加起来不能使用超过 14.5 CPUs 的资源。
当没有执行 kube-reserved 和/或 system-reserved 策略且系统守护进程使用量超过其预留时,
如果节点内存用量高于 31.5Gi 或 storage 大于 90Gi,kubelet 将会驱逐 Pod。
Kubernetes v1.22 [alpha]
这个文档描述了怎样不使用 root 特权,而是通过使用 用户命名空间 去运行 Kubernetes 节点组件(例如 kubelet、CRI、OCI、CNI)。
这种技术也叫做 rootless 模式(Rootless mode)。
你的 Kubernetes 服务器版本必须不低于版本 1.22.
要获知版本信息,请输入 kubectl version.
/etc/subuid 和 /etc/subgid 文件中KubeletInUserNamespace 特性门控kind 支持使用 Rootless 模式的 Docker 或者 Podman 运行 Kubernetes。
请参阅使用 Rootless 模式的 Docker 运行 kind。
minikube 也支持使用 Rootless 模式的 Docker 或 Podman 运行 Kubernetes。
请参阅 Minikube 文档:
Sysbox 是一个开源容器运行时 (类似于 “runc”),支持在 Linux 用户命名空间隔离的非特权容器内运行系统级工作负载, 比如 Docker 和 Kubernetes。
查看 Sysbox 快速入门指南: Kubernetes-in-Docker 了解更多细节。
Sysbox 支持在非特权容器内运行 Kubernetes,
而不需要 cgroup v2 和 “KubeletInUserNamespace” 特性门控。
Sysbox 通过在容器内暴露特定的 /proc 和 /sys 文件系统,
以及其它一些先进的操作系统虚拟化技术来实现。
K3s 实验性支持了 Rootless 模式。
请参阅使用 Rootless 模式运行 K3s 页面中的用法.
Usernetes 是 Kubernetes 的一个参考发行版,
它可以在不使用 root 特权的情况下安装在 $HOME 目录下。
Usernetes 支持使用 containerd 和 CRI-O 作为 CRI 运行时。 Usernetes 支持配置了 Flannel (VXLAN)的多节点集群。
关于用法,请参阅 Usernetes 仓库。
本节提供在用户命名空间手动运行 Kubernetes 的注意事项。
第一步是创建一个 用户命名空间。
如果你正在尝试使用用户命名空间的容器(例如 Rootless 模式的 Docker/Podman 或 LXC/LXD) 运行 Kubernetes,那么你已经准备就绪,可以直接跳到下一小节。
否则你需要通过传递参数 CLONE_NEWUSER 调用 unshare(2),自己创建一个命名空间。
用户命名空间也可以通过如下所示的命令行工具取消共享:
在取消命名空间的共享之后,你也必须对其它的命名空间例如 mount 命名空间取消共享。
在取消 mount 命名空间的共享之后,你不需要调用 chroot() 或者 pivot_root(),
但是你必须在这个命名空间内挂载可写的文件系统到几个目录上。
请确保这个命名空间内(不是这个命名空间外部)至少以下几个目录是可写的:
/etc/run/var/logs/var/lib/kubelet/var/lib/cni/var/lib/containerd (参照 containerd)/var/lib/containers (参照 CRI-O)除了用户命名空间,你也需要有一个版本为 cgroup v2 的可写 cgroup 树。
如果你在一个采用 systemd 机制的主机上使用用户命名空间的容器(例如 Rootless 模式的 Docker/Podman 或 LXC/LXD)来运行 Kubernetes,那么你已经准备就绪。
否则你必须创建一个具有 Delegate=yes 属性的 systemd 单元,来委派一个具有可写权限的 cgroup 树。
在你的节点上,systemd 必须已经配置为允许委派。更多细节请参阅 Rootless 容器文档的 cgroup v2 部分。
节点组件的网络命名空间必须有一个非本地回路的网卡。它可以使用 slirp4netns、 VPNKit、 lxc-user-nic(1) 等工具进行配置。
Pod 的网络命名空间可以使用常规的 CNI 插件配置。对于多节点的网络,已知 Flannel (VXLAN、8472/UDP) 可以正常工作。
诸如 kubelet 端口(10250/TCP)和 NodePort 服务端口之类的端口必须通过外部端口转发器
(例如 RootlessKit、slirp4netns 或
socat(1)) 从节点网络命名空间暴露给主机。
你可以使用 K3s 的端口转发器。更多细节请参阅
在 Rootless 模式下运行 K3s。
该实现可以在 k3s 的 pkg/rootlessports 包中找到。
kubelet 依赖于容器运行时。你需要部署一个容器运行时(例如 containerd 或 CRI-O), 并确保它在 kubelet 启动之前已经在用户命名空间内运行。
containerd 1.4 开始支持在用户命名空间运行 containerd 的 CRI 插件。
在用户命名空间运行 containerd 必须进行如下配置:
version = 2
[plugins."io.containerd.grpc.v1.cri"]
# 禁用 AppArmor
disable_apparmor = true
# 忽略配置 oom_score_adj 时的错误
restrict_oom_score_adj = true
# 禁用 hugetlb cgroup v2 控制器(因为 systemd 不支持委派 hugetlb controller)
disable_hugetlb_controller = true
[plugins."io.containerd.grpc.v1.cri".containerd]
# 如果内核 >= 5.11 , 也可以使用 non-fuse overlayfs, 但需要禁用 SELinux
snapshotter = "fuse-overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# 我们使用的 cgroupfs 已经被 systemd 委派,所以我们不使用 SystemdCgroup 驱动
# (除非你在命名空间内运行了另一个 systemd)
SystemdCgroup = false
配置文件的默认路径是 /etc/containerd/config.toml。
可以用 containerd -c /path/to/containerd/config.toml 来指定该路径。
CRI-O 1.22 开始支持在用户命名空间运行 CRI-O。
CRI-O 必须配置一个环境变量 _CRIO_ROOTLESS=1。
也推荐使用以下配置:
[crio]
storage_driver = "overlay"
# 如果内核 >= 5.11 , 也可以使用 non-fuse overlayfs, 但需要禁用 SELinux
storage_option = ["overlay.mount_program=/usr/local/bin/fuse-overlayfs"]
[crio.runtime]
# 我们使用的 cgroupfs 已经被 systemd 委派,所以我们不使用 "systemd" 驱动
# (除非你在命名空间内运行了另一个 systemd)
cgroup_manager = "cgroupfs"
配置文件的默认路径是 /etc/containerd/config.toml。
可以用 containerd -c /path/to/containerd/config.toml 来指定该路径。
在用户命名空间运行 kubelet 必须进行如下配置:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
featureGates:
KubeletInUserNamespace: true
# 我们使用的 cgroupfs 已经被 systemd 委派,所以我们不使用 "systemd" 驱动
# (除非你在命名空间内运行了另一个 systemd)
cgroupDriver: "cgroupfs"
当 KubeletInUserNamespace 特性门控被启用时, kubelet 会忽略节点内由于配置如下几个 sysctl
参数值而可能产生的错误。
vm.overcommit_memoryvm.panic_on_oomkernel.panickernel.panic_on_oopskernel.keys.root_maxkeyskernel.keys.root_maxbytes.在用户命名空间内, kubelet 也会忽略任何由于打开 /dev/kmsg 而产生的错误。
这个特性门控也允许 kube-proxy 忽略由于配置 RLIMIT_NOFILE 而产生的一个错误。
KubeletInUserNamespace 特性门控从 Kubernetes v1.22 被引入, 标记为 "alpha" 状态。
通过挂载特制的 proc 文件系统 (比如 Sysbox), 也可以在不使用这个特性门控的情况下在用户命名空间运行 kubelet,但这不受官方支持。
在用户命名空间运行 kube-proxy 需要进行以下配置:
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "iptables" # or "userspace"
conntrack:
# 跳过配置 sysctl 的值 "net.netfilter.nf_conntrack_max"
maxPerCore: 0
# 跳过配置 "net.netfilter.nf_conntrack_tcp_timeout_established"
tcpEstablishedTimeout: 0s
# 跳过配置 "net.netfilter.nf_conntrack_tcp_timeout_close"
tcpCloseWaitTimeout: 0s
大部分“非本地”的卷驱动(例如 nfs 和 iscsi)不能正常工作。
已知诸如 local、hostPath、emptyDir、configMap、secret 和 downwardAPI
这些本地卷是能正常工作的。
一些 CNI 插件可能不正常工作。已知 Flannel (VXLAN) 是能正常工作的。
更多细节请参阅 rootlesscontaine.rs 站点的 Caveats and Future work 页面。
本页展示了如何在确保 PodDisruptionBudget 的前提下, 安全地清空一个节点。
此任务假定你已经满足了以下先决条件:
为了确保你的负载在维护期间仍然可用,你可以配置一个 PodDisruptionBudget。 如果可用性对于正在清空的该节点上运行或可能在该节点上运行的任何应用程序很重要, 首先 配置一个 PodDisruptionBudgets 并继续遵循本指南。
建议为你的 PodDisruptionBudgets 设置 AlwaysAllow
不健康 Pod 驱逐策略,
以在节点清空期间支持驱逐异常的应用程序。
默认行为是等待应用程序的 Pod 变为 健康后,
才能进行清空操作。
kubectl drain 从服务中删除一个节点在对节点执行维护(例如内核升级、硬件维护等)之前,
可以使用 kubectl drain 从节点安全地逐出所有 Pod。
安全的驱逐过程允许 Pod 的容器体面地终止,
并确保满足指定的 PodDisruptionBudgets。
默认情况下,kubectl drain 将忽略节点上不能杀死的特定系统 Pod;
有关更多细节,请参阅
kubectl drain 文档。
kubectl drain 的成功返回,表明所有的 Pod(除了上一段中描述的被排除的那些),
已经被安全地逐出(考虑到期望的终止宽限期和你定义的 PodDisruptionBudget)。
然后就可以安全地关闭节点,
比如关闭物理机器的电源,如果它运行在云平台上,则删除它的虚拟机。
如果存在新的、能够容忍 node.kubernetes.io/unschedulable 污点的 Pod,
那么这些 Pod 可能会被调度到你已经清空的节点上。
除了 DaemonSet 之外,请避免容忍此污点。
如果你或另一个 API 用户(绕过调度器)直接为 Pod 设置了
nodeName字段,
则即使你已将该节点清空并标记为不可调度,Pod 仍将被绑定到这个指定的节点并在该节点上运行。
首先,确定想要清空的节点的名称。可以用以下命令列出集群中的所有节点:
kubectl get nodes
接下来,告诉 Kubernetes 清空节点:
kubectl drain --ignore-daemonsets <节点名称>
如果存在 DaemonSet 管理的 Pod,你将需要为 kubectl 设置 --ignore-daemonsets 以成功地清空节点。
kubectl drain 子命令自身实际上不清空节点上的 DaemonSet Pod 集合:
DaemonSet 控制器(作为控制平面的一部分)会立即用新的等效 Pod 替换缺少的 Pod。
DaemonSet 控制器还会创建忽略不可调度污点的 Pod,这种污点允许在你正在清空的节点上启动新的 Pod。
一旦它返回(没有报错), 你就可以下线此节点(或者等价地,如果在云平台上,删除支持该节点的虚拟机)。 如果要在维护操作期间将节点留在集群中,则需要运行:
kubectl uncordon <node name>
然后告诉 Kubernetes,它可以继续在此节点上调度新的 Pod。
kubectl drain 命令一次只能发送给一个节点。
但是,你可以在不同的终端或后台为不同的节点并行地运行多个 kubectl drain 命令。
同时运行的多个 drain 命令仍然遵循你指定的 PodDisruptionBudget。
例如,如果你有一个三副本的 StatefulSet,
并设置了一个 PodDisruptionBudget,指定 minAvailable: 2。
如果所有的三个 Pod 处于健康(healthy)状态,
并且你并行地发出多个 drain 命令,那么 kubectl drain 只会从 StatefulSet 中逐出一个 Pod,
因为 Kubernetes 会遵守 PodDisruptionBudget 并确保在任何时候只有一个 Pod 不可用
(最多不可用 Pod 个数的计算方法:replicas - minAvailable)。
任何会导致处于健康(healthy)
状态的副本数量低于指定预算的清空操作都将被阻止。
如果你不喜欢使用 kubectl drain (比如避免调用外部命令,或者更细化地控制 Pod 驱逐过程), 你也可以用驱逐 API 通过编程的方式达到驱逐的效果。 更多信息,请参阅 API 发起的驱逐。
本文档涉及与保护集群免受意外或恶意访问有关的主题,并对总体安全性提出建议。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
因为 Kubernetes 是完全通过 API 驱动的,所以,控制和限制谁可以通过 API 访问集群, 以及允许这些访问者执行什么样的 API 动作,就成为了安全控制的第一道防线。
Kubernetes 期望集群中所有的 API 通信在默认情况下都使用 TLS 加密, 大多数安装方法也允许创建所需的证书并且分发到集群组件中。 请注意,某些组件和安装方法可能使用 HTTP 来访问本地端口, 管理员应该熟悉每个组件的设置,以识别可能不安全的流量。
安装集群时,选择一个 API 服务器的身份验证机制,去使用与之匹配的公共访问模式。 例如,小型的单用户集群可能希望使用简单的证书或静态承载令牌方法。 更大的集群则可能希望整合现有的、OIDC、LDAP 等允许用户分组的服务器。
所有 API 客户端都必须经过身份验证,即使它是基础设施的一部分,比如节点、代理、调度程序和卷插件。 这些客户端通常使用 服务帐户 或 X509 客户端证书,并在集群启动时自动创建或是作为集群安装的一部分进行设置。
如果你希望获取更多信息,请参考认证参考文档。
一旦通过身份认证,每个 API 的调用都将通过鉴权检查。 Kubernetes 集成基于角色的访问控制(RBAC)组件, 将传入的用户或组与一组绑定到角色的权限匹配。 这些权限将动作(get、create、delete)和资源(Pod、Service、Node)进行组合,并可在名字空间或者集群范围生效。 Kubernetes 提供了一组可直接使用的角色,这些角色根据客户可能希望执行的操作提供合理的责任划分。 建议你同时使用 Node 和 RBAC 两个鉴权组件,再与 NodeRestriction 准入插件结合使用。
与身份验证一样,简单而广泛的角色可能适合于较小的集群,但是随着更多的用户与集群交互, 可能需要将团队划分到有更多角色限制的、 单独的名字空间中去。
就鉴权而言,很重要的一点是理解对象上的更新操作如何导致在其它地方发生对应行为。 例如,用户可能不能直接创建 Pod,但允许他们通过创建 Deployment 来创建这些 Pod, 这将让他们间接创建这些 Pod。 同样地,从 API 删除一个节点将导致调度到这些节点上的 Pod 被中止,并在其他节点上重新创建。 原生的角色设计代表了灵活性和常见用例之间的平衡,但须限制的角色应该被仔细审查, 以防止意外的权限升级。如果内置的角色无法满足你的需求,则可以根据使用场景需要创建特定的角色。
如果你希望获取更多信息,请参阅鉴权参考。
Kubelet 公开 HTTPS 端点,这些端点提供了对节点和容器的强大的控制能力。 默认情况下,Kubelet 允许对此 API 进行未经身份验证的访问。
生产级别的集群应启用 Kubelet 身份认证和授权。
进一步的信息,请参考 Kubelet 身份验证/授权参考。
Kubernetes 中的授权故意设计成较高抽象级别,侧重于对资源的粗粒度行为。 更强大的控制是 策略 的形式呈现的,根据使用场景限制这些对象如何作用于集群、自身和其他资源。
资源配额(Resource Quota)限制了赋予命名空间的资源的数量或容量。 资源配额通常用于限制名字空间可以分配的 CPU、内存或持久磁盘的数量, 但也可以控制每个名字空间中存在多少个 Pod、Service 或 Volume。
限制范围(Limit Range) 限制上述某些资源的最大值或者最小值,以防止用户使用类似内存这样的通用保留资源时请求不合理的过高或过低的值, 或者在没有指定的情况下提供默认限制。
Pod 定义包含了一个安全上下文, 用于描述一些访问请求,如以某个节点上的特定 Linux 用户(如 root)身份运行, 以特权形式运行,访问主机网络,以及一些在宿主节点上不受约束地运行的其它控制权限等等。
你可以配置 Pod 安全准入来在某个 名字空间中 强制实施特定的 Pod 安全标准(Pod Security Standard), 或者检查安全上的缺陷。
一般来说,大多数应用程序需要对主机资源的有限制的访问, 这样它们可以在不访问主机信息的情况下,成功地以 root 账号(UID 0)运行。 但是,考虑到与 root 用户相关的特权,在编写应用程序容器时,你应该使用非 root 用户运行。 类似地,希望阻止客户端应用程序从其容器中逃逸的管理员,应该应用 Baseline 或 Restricted Pod 安全标准。
如果在某些情况下,Linux 内核会根据需要自动从磁盘加载内核模块, 这类情况的例子有挂接了一个硬件或挂载了一个文件系统。 与 Kubernetes 特别相关的是,即使是非特权的进程也可能导致某些网络协议相关的内核模块被加载, 而这只需创建一个适当类型的套接字。 这就可能允许攻击者利用管理员假定未使用的内核模块中的安全漏洞。
为了防止特定模块被自动加载,你可以将它们从节点上卸载或者添加规则来阻止这些模块。
在大多数 Linux 发行版上,你可以通过创建类似 /etc/modprobe.d/kubernetes-blacklist.conf
这种文件来做到这一点,其中的内容如下所示:
# DCCP is unlikely to be needed, has had multiple serious
# vulnerabilities, and is not well-maintained.
blacklist dccp
# SCTP is not used in most Kubernetes clusters, and has also had
# vulnerabilities in the past.
blacklist sctp
为了更大范围地阻止内核模块被加载,你可以使用 Linux 安全模块(如 SELinux)
来彻底拒绝容器的 module_request 权限,从而防止在任何情况下系统为容器加载内核模块。
(Pod 仍然可以使用手动加载的模块,或者使用由内核代表某些特权进程所加载的模块。)
基于名字空间的网络策略 允许应用程序作者限制其它名字空间中的哪些 Pod 可以访问自身名字空间内的 Pod 和端口。 现在已经有许多支持网络策略的 Kubernetes 网络驱动。
配额(Quota)和限制范围(Limit Range)也可用于控制用户是否可以请求节点端口或负载均衡服务。 在很多集群上,节点端口和负载均衡服务也可控制用户的应用程序是否在集群之外可见。
此外也可能存在一些基于插件或基于环境的网络规则,能够提供额外的保护能力。 例如各节点上的防火墙、物理隔离集群节点以防止串扰或者高级的网络策略等。
云平台(AWS、Azure、GCE 等)经常将 metadata 本地服务暴露给实例。 默认情况下,这些 API 可由运行在实例上的 Pod 访问,并且可以包含 该云节点的凭据或配置数据(如 kubelet 凭据)。 这些凭据可以用于在集群内升级或在同一账户下升级到其他云服务。
在云平台上运行 Kubernetes 时,需要限制对实例凭据的权限,使用 网络策略 限制 Pod 对元数据 API 的访问,并避免使用配置数据来传递机密信息。
默认情况下,对 Pod 可以运行在哪些节点上是没有任何限制的。 Kubernetes 给最终用户提供了 一组丰富的策略用于控制 Pod 所放置的节点位置, 以及基于污点的 Pod 放置和驱逐。 对于许多集群,使用这些策略来分离工作负载可以作为一种约定,要求作者遵守或者通过工具强制。
对于管理员,Beta 阶段的准入插件 PodNodeSelector 可用于强制某名字空间中的 Pod
使用默认的或特定的节点选择算符。
如果最终用户无法改变名字空间,这一机制可以有效地限制特定工作负载中所有 Pod 的放置位置。
本节描述保护集群免受破坏的一些常用模式。
拥有对 API 的 etcd 后端的写访问权限相当于获得了整个集群的 root 权限, 读访问权限也可能被利用,实现相当快速的权限提升。 对于从 API 服务器访问其 etcd 服务器,管理员应该总是使用比较强的凭证,如通过 TLS 客户端证书来实现双向认证。 通常,我们建议将 etcd 服务器隔离到只有 API 服务器可以访问的防火墙后面。
审计日志是 Beta 特性, 负责记录 API 操作以便在发生破坏时进行事后分析。 建议启用审计日志,并将审计文件归档到安全服务器上。
Kubernetes 的 Alpha 和 Beta 特性还在努力开发中,可能存在导致安全漏洞的缺陷或错误。 要始终评估 Alpha 和 Beta 特性可能给你的安全态势带来的风险。 当你怀疑存在风险时,可以禁用那些不需要使用的特性。
一项机密信息或凭据的生命期越短,攻击者就越难使用该凭据。 在证书上设置较短的生命期并实现自动轮换是控制安全的一个好方法。 使用身份验证提供程序时,应该使用那些可以控制所发布令牌的合法时长的提供程序, 并尽可能设置较短的生命期。 如果在外部集成场景中使用服务帐户令牌,则应该经常性地轮换这些令牌。 例如,一旦引导阶段完成,就应该撤销用于配置节点的引导令牌,或者取消它的授权。
许多集成到 Kubernetes 的第三方软件或服务都可能改变你的集群的安全配置。 启用集成时,在授予访问权限之前,你应该始终检查扩展所请求的权限。 例如,许多安全性集成中可能要求查看集群上的所有 Secret 的访问权限, 本质上该组件便成为了集群的管理员。 当有疑问时,如果可能的话,将要集成的组件限制在某指定名字空间中运行。
如果执行 Pod 创建操作的组件能够在 kube-system 这类名字空间中创建 Pod,
则这类组件也可能获得意外的权限,因为这些 Pod 可以访问服务账户的 Secret,
或者,如果对应服务帐户被授权访问宽松的
PodSecurityPolicy,
它们就能以较高的权限运行。
如果你使用 Pod 安全准入, 并且允许任何组件在一个允许执行特权 Pod 的名字空间中创建 Pod,这些 Pod 就可能从所在的容器中逃逸,利用被拓宽的访问权限来实现特权提升。
你不应该允许不可信的组件在任何系统名字空间(名字以 kube- 开头)中创建 Pod,
也不允许它们在访问权限授权可被利用来提升特权的名字空间中创建 Pod。
一般情况下,etcd 数据库包含了通过 Kubernetes API 可以访问到的所有信息, 并且可能为攻击者提供对你的集群的状态的较多的可见性。 你要始终使用经过充分审查的备份和加密方案来加密备份数据, 并考虑在可能的情况下使用全盘加密。
对于 Kubernetes API 中的信息,Kubernetes 支持可选的静态数据加密。
这让你可以确保当 Kubernetes 存储对象(例如 Secret 或 ConfigMap)的数据时,API 服务器写入的是加密的对象。
这种加密意味着即使有权访问 etcd 备份数据的某些人也无法查看这些对象的内容。
在 Kubernetes 1.29 中,你也可以加密自定义资源;
针对以 CustomResourceDefinition 形式定义的扩展 API,对其执行静态加密的能力作为 v1.26
版本的一部分已添加到 Kubernetes。
请加入 kubernetes-announce 组,这样你就能够收到有关安全公告的邮件。有关如何报告漏洞的更多信息, 请参见安全报告页面。
通过保存在硬盘的配置文件设置 kubelet 的部分配置参数,这可以作为命令行参数的替代。
建议通过配置文件的方式提供参数,因为这样可以简化节点部署和配置管理。
KubeletConfiguration
结构体定义了可以通过文件配置的 kubelet 配置子集,
配置文件必须是这个结构体中参数的 JSON 或 YAML 表现形式。 确保 kubelet 可以读取该文件。
下面是一个 kubelet 配置文件示例:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: "192.168.0.8"
port: 20250
serializeImagePulls: false
evictionHard:
memory.available: "100Mi"
nodefs.available: "10%"
nodefs.inodesFree: "5%"
imagefs.available: "15%"
在此示例中,kubelet 配置为以下设置:
address:kubelet 将在 192.168.0.8 IP 地址上提供服务。port:kubelet 将在 20250 端口上提供服务。serializeImagePulls:并行拉取镜像。evictionHard:kubelet 将在以下情况之一驱逐 Pod:
在示例中,通过只更改 evictionHard 的一个参数的默认值, 其他参数的默认值将不会被继承,他们会被设置为零。如果要提供自定义值,你应该分别设置所有阈值。
imagefs 是一个可选的文件系统,容器运行时使用它来存储容器镜像和容器可写层。
如果你使用 kubeadm 初始化你的集群,在使用 kubeadm init 创建你的集群的时候请使用 kubelet-config。
更多细节请阅读使用 kubeadm 配置 kubelet
启动 kubelet 需要将 --config 参数设置为 kubelet 配置文件的路径。kubelet 将从此文件加载其配置。
请注意,命令行参数与配置文件有相同的值时,就会覆盖配置文件中的该值。 这有助于确保命令行 API 的向后兼容性。
请注意,kubelet 配置文件中的相对文件路径是相对于 kubelet 配置文件的位置解析的, 而命令行参数中的相对路径是相对于 kubelet 的当前工作目录解析的。
请注意,命令行参数和 kubelet 配置文件的某些默认值不同。
如果设置了 --config,并且没有通过命令行指定值,则 KubeletConfiguration
版本的默认值生效。在上面的例子中,version 是 kubelet.config.k8s.io/v1beta1。
自 Kubernetes v1.28.0 起,kubelet 被扩展以支持一个插件配置目录。
该目录的位置可以使用 --config-dir 标志来指定,默认为 "",也就是被禁用状态。
只有在为 kubelet 进程设置环境变量 KUBELET_CONFIG_DROPIN_DIR_ALPHA
(该变量的值无关紧要)时才可以设置 --config-dir。对于 Kubernetes v1.29,
如果你未设置该变量而指定了 --config-dir,kubelet 将返回错误并且启动失败。
你不能使用 kubelet 配置文件指定插件配置目录;只能使用 CLI 参数 --config-dir 进行设置。
你可以以类似于 kubelet 配置文件的方式使用 kubelet 配置目录。
合法的 kubelet 插件配置文件的后缀必须为 .conf。例如 99-kubelet-address.conf。
例如,你可能想要为所有节点设置一个基准的 kubelet 配置,但你可能想要自定义 address 字段。
可以按如下方式操作:
kubelet 配置文件的主要内容如下:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
port: 20250
serializeImagePulls: false
evictionHard:
memory.available: "200Mi"
--config-dir 目录中某个文件的内容如下:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
address: "192.168.0.8"
在启动时,kubelet 会合并来自以下几部分的配置:
这将产生与之前示例中使用的单个配置文件相同的结果。
KubeletConfiguration
进一步学习 kubelet 的配置。本页展示如何查看、使用和删除名字空间。 本页同时展示如何使用 Kubernetes 名字空间来划分集群。
列出集群中现有的名字空间:
kubectl get namespaces
NAME STATUS AGE
default Active 11d
kube-node-lease Active 11d
kube-public Active 11d
kube-system Active 11d
初始状态下,Kubernetes 具有四个名字空间:
default 无名字空间对象的默认名字空间kube-node-lease 此名字空间保存与每个节点关联的租约(Lease)对象。
节点租约允许 kubelet 发送[心跳](/zh-cn/docs/concepts/architecture/nodes/#heartbeats),
以便控制平面可以检测节点故障。kube-public 自动创建且被所有用户可读的名字空间(包括未经身份认证的)。
此名字空间通常在某些资源在整个集群中可见且可公开读取时被集群使用。
此名字空间的公共方面只是一个约定,而不是一个必要条件。kube-system 由 Kubernetes 系统创建的对象的名字空间你还可以通过下列命令获取特定名字空间的摘要:
kubectl get namespaces <name>
或用下面的命令获取详细信息:
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- ---
Container cpu - - 100m
请注意,这些详情同时显示了资源配额(如果存在)以及资源限制区间。
资源配额跟踪并聚合 Namespace 中资源的使用情况, 并允许集群运营者定义 Namespace 可能消耗的 Hard 资源使用限制。
限制区间定义了单个实体在一个 Namespace 中可使用的最小/最大资源量约束。
参阅准入控制:限制区间。
名字空间可以处于下列两个阶段中的一个:
Active 名字空间正在被使用中Terminating 名字空间正在被删除,且不能被用于新对象。更多细节,参阅 API 参考中的名字空间。
避免使用前缀 kube- 创建名字空间,因为它是为 Kubernetes 系统名字空间保留的。
新建一个名为 my-namespace.yaml 的 YAML 文件,并写入下列内容:
apiVersion: v1
kind: Namespace
metadata:
name: <insert-namespace-name-here>
然后运行:
kubectl create -f ./my-namespace.yaml
或者,你可以使用下面的命令创建名字空间:
kubectl create namespace <insert-namespace-name-here>
请注意,名字空间的名称必须是一个合法的 DNS 标签。
可选字段 finalizers 允许观察者们在名字空间被删除时清除资源。
记住如果指定了一个不存在的终结器,名字空间仍会被创建,
但如果用户试图删除它,它将陷入 Terminating 状态。
更多有关 finalizers 的信息请查阅
设计文档中名字空间部分。
删除名字空间使用命令:
kubectl delete namespaces <insert-some-namespace-name>
这会删除名字空间下的 所有内容 !
删除是异步的,所以有一段时间你会看到名字空间处于 Terminating 状态。
默认情况下,Kubernetes 集群会在配置集群时实例化一个 default 名字空间,用以存放集群所使用的默认 Pod、Service 和 Deployment 集合。
假设你有一个新的集群,你可以通过执行以下操作来内省可用的名字空间:
kubectl get namespaces
NAME STATUS AGE
default Active 13m
在本练习中,我们将创建两个额外的 Kubernetes 名字空间来保存我们的内容。
在某组织使用共享的 Kubernetes 集群进行开发和生产的场景中:
该组织可以遵循的一种模式是将 Kubernetes 集群划分为两个名字空间:development 和 production。
让我们创建两个新的名字空间来保存我们的工作。
使用 kubectl 创建 development 名字空间。
kubectl create -f https://k8s.io/examples/admin/namespace-dev.json
让我们使用 kubectl 创建 production 名字空间。
kubectl create -f https://k8s.io/examples/admin/namespace-prod.json
为了确保一切正常,列出集群中的所有名字空间。
kubectl get namespaces --show-labels
NAME STATUS AGE LABELS
default Active 32m <none>
development Active 29s name=development
production Active 23s name=production
Kubernetes 名字空间为集群中的 Pod、Service 和 Deployment 提供了作用域。
与一个名字空间交互的用户不会看到另一个名字空间中的内容。
为了演示这一点,让我们在 development 名字空间中启动一个简单的 Deployment 和 Pod。
kubectl create deployment snowflake \
--image=registry.k8s.io/serve_hostname \
-n=development --replicas=2
我们创建了一个副本个数为 2 的 Deployment,运行名为 snowflake 的
Pod,其中包含一个负责提供主机名的基本容器。
kubectl get deployment -n=development
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app=snowflake -n=development
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
看起来还不错,开发人员能够做他们想做的事,而且他们不必担心会影响到
production 名字空间下面的内容。
让我们切换到 production 名字空间,
展示一下一个名字空间中的资源是如何对另一个名字空间隐藏的。
名字空间 production 应该是空的,下面的命令应该不会返回任何东西。
kubectl get deployment -n=production
kubectl get pods -n=production
生产环境下一般以养牛的方式运行负载,所以让我们创建一些 Cattle(牛)Pod。
kubectl create deployment cattle --image=registry.k8s.io/serve_hostname -n=production
kubectl scale deployment cattle --replicas=5 -n=production
kubectl get deployment -n=production
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l app=cattle -n=production
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
此时,应该很清楚地展示了用户在一个名字空间中创建的资源对另一个名字空间是隐藏的。
随着 Kubernetes 中的策略支持的发展,我们将扩展此场景,以展示如何为每个名字空间提供不同的授权规则。
单个集群应该能满足多个用户及用户组的需求(以下称为 “用户社区”)。
Kubernetes 名字空间 帮助不同的项目、团队或客户去共享 Kubernetes 集群。
名字空间通过以下方式实现这点:
使用多个名字空间是可选的。
每个用户社区都希望能够与其他社区隔离开展工作。 每个用户社区都有自己的:
集群运营者可以为每个唯一用户社区创建名字空间。
名字空间为下列内容提供唯一的作用域:
用例包括:
当你创建服务时,Kubernetes
会创建相应的 DNS 条目。
此条目的格式为 <服务名称>.<名字空间名称>.svc.cluster.local。
这意味着如果容器使用 <服务名称>,它将解析为名字空间本地的服务。
这对于在多个名字空间(如开发、暂存和生产)中使用相同的配置非常有用。
如果要跨名字空间访问,则需要使用完全限定的域名(FQDN)。
本页概述升级 Kubernetes 集群的步骤。
升级集群的方式取决于你最初部署它的方式、以及后续更改它的方式。
从高层规划的角度看,要执行的步骤是:
你必须有一个集群。 本页内容涉及从 Kubernetes 1.28 升级到 Kubernetes 1.29。 如果你的集群未运行 Kubernetes 1.28, 那请参考目标 Kubernetes 版本的文档。
如果你的集群是使用 kubeadm 安装工具部署而来,
那么升级集群的详细信息,请参阅升级 kubeadm 集群。
升级集群之后,要记得安装最新版本的 kubectl。
这些步骤不考虑网络和存储插件等第三方扩展。
你应该按照下面的操作顺序,手动更新控制平面:
现在,你应该安装最新版本的 kubectl。
对于集群中的每个节点, 首先需要腾空节点, 然后使用一个运行了 kubelet 1.29 版本的新节点替换它; 或者升级此节点的 kubelet,并使节点恢复服务。
在升级 kubelet 之前先进行节点排空,这样可以确保 Pod 被重新准入并且容器被重新创建。 这一步骤对于解决某些安全问题或其他关键错误是非常必要的。
参阅你的集群部署工具对应的文档,了解用于维护的推荐设置步骤。
对象序列化到 etcd,是为了提供集群中活动 Kubernetes 资源的内部表示法, 这些对象都使用特定版本的 API 编写。
当底层的 API 更改时,这些对象可能需要用新 API 重写。 如果不能做到这一点,会导致再也不能用 Kubernetes API 服务器解码、使用该对象。
对于每个受影响的对象,请使用最新支持的 API 读取它,然后使用所支持的最新 API 将其写回。
升级到新版本 Kubernetes 就可以获取到新的 API。
你可以使用 kubectl convert 命令在不同 API 版本之间转换清单。
例如:
kubectl convert -f pod.yaml --output-version v1
kubectl 替换了 pod.yaml 的内容,
在新的清单文件中,kind 被设置为 Pod(未变),
但 apiVersion 则被修订了。
如果你的集群正在运行设备插件(Device Plugin)并且节点需要升级到具有更新的设备插件(Device Plugin) API 版本的 Kubernetes 版本,则必须在升级节点之前升级设备插件以同时支持这两个插件 API 版本, 以确保升级过程中设备分配能够继续成功完成。
有关详细信息,请参阅 API 兼容性和 kubelet 设备管理器 API 版本。
本页面向你展示如何设置在你的集群执行垃圾收集 时要使用的级联删除 类型。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你还需要创建一个 Deployment 示例 以试验不同类型的级联删除。你需要为每种级联删除类型来重建 Deployment。
检查确认你的 Pods 上存在 ownerReferences 字段:
kubectl get pods -l app=nginx --output=yaml
输出中包含 ownerReferences 字段,类似这样:
apiVersion: v1
...
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-6b474476c4
uid: 4fdcd81c-bd5d-41f7-97af-3a3b759af9a7
...
默认情况下,Kubernetes 使用后台级联删除
以删除依赖某对象的其他对象。取决于你的集群所运行的 Kubernetes 版本,
你可以使用 kubectl 或者 Kubernetes API 来切换到前台级联删除。
要获知版本信息,请输入 kubectl version.
你可以使用 kubectl 或者 Kubernetes API 来基于前台级联删除来删除对象。
使用 kubectl
运行下面的命令:
kubectl delete deployment nginx-deployment --cascade=foreground
使用 Kubernetes API
启动一个本地代理会话:
kubectl proxy --port=8080
使用 curl 来触发删除操作:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
-H "Content-Type: application/json"
输出中包含 foregroundDeletion finalizer,
类似这样:
"kind": "Deployment",
"apiVersion": "apps/v1",
"metadata": {
"name": "nginx-deployment",
"namespace": "default",
"uid": "d1ce1b02-cae8-4288-8a53-30e84d8fa505",
"resourceVersion": "1363097",
"creationTimestamp": "2021-07-08T20:24:37Z",
"deletionTimestamp": "2021-07-08T20:27:39Z",
"finalizers": [
"foregroundDeletion"
]
...
kubectl 或者 Kubernetes API 来删除 Deployment。
要获知版本信息,请输入 kubectl version.
你可以使用 kubectl 或者 Kubernetes API 来执行后台级联删除方式的对象删除操作。
Kubernetes 默认采用后台级联删除方式,如果你在运行下面的命令时不指定
--cascade 标志或者 propagationPolicy 参数时,用这种方式来删除对象。
使用 kubectl
运行下面的命令:
kubectl delete deployment nginx-deployment --cascade=background
使用 Kubernetes API
启动一个本地代理会话:
kubectl proxy --port=8080
使用 curl 来触发删除操作:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Background"}' \
-H "Content-Type: application/json"
输出类似于:
"kind": "Status",
"apiVersion": "v1",
...
"status": "Success",
"details": {
"name": "nginx-deployment",
"group": "apps",
"kind": "deployments",
"uid": "cc9eefb9-2d49-4445-b1c1-d261c9396456"
}
默认情况下,当你告诉 Kubernetes 删除某个对象时,
控制器 也会删除依赖该对象
的其他对象。
取决于你的集群所运行的 Kubernetes 版本,你也可以使用 kubectl 或者 Kubernetes
API 来让 Kubernetes 孤立 这些依赖对象。
要获知版本信息,请输入 kubectl version.
使用 kubectl
运行下面的命令:
kubectl delete deployment nginx-deployment --cascade=orphan
使用 Kubernetes API
启动一个本地代理会话:
kubectl proxy --port=8080
使用 curl 来触发删除操作:
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/deployments/nginx-deployment \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
-H "Content-Type: application/json"
输出中在 finalizers 字段中包含 orphan,如下所示:
"kind": "Deployment",
"apiVersion": "apps/v1",
"namespace": "default",
"uid": "6f577034-42a0-479d-be21-78018c466f1f",
"creationTimestamp": "2021-07-09T16:46:37Z",
"deletionTimestamp": "2021-07-09T16:47:08Z",
"deletionGracePeriodSeconds": 0,
"finalizers": [
"orphan"
],
...
你可以检查 Deployment 所管理的 Pods 仍然处于运行状态:
kubectl get pods -l app=nginx
本页展示了如何配置密钥管理服务(Key Management Service,KMS)驱动和插件以启用 Secret 数据加密。 在 Kubernetes 1.29 中,存在两个版本的 KMS 静态加密方式。 如果可行的话,建议使用 KMS v2,因为(自 Kubernetes v1.28 起)KMS v1 已经被弃用并 (自 Kubernetes v1.29 起)默认被禁用。 KMS v2 提供了比 KMS v1 明显更好的性能特征。
本文适用于正式发布的 KMS v2 实现(以及已废弃的 v1 实现)。 如果你使用的控制平面组件早于 Kubernetes v1.29,请查看集群所运行的 Kubernetes 版本文档中的相应页面。 早期版本的 Kubernetes 在信息安全方面具有不同的行为。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你所需要的 Kubernetes 版本取决于你已选择的 KMS API 版本。Kubernetes 推荐使用 KMS v2。
kubectl version.
Kubernetes v1.28 [deprecated]
--feature-gates=KMSv1=true 以配置 KMS v1 驱动。Kubernetes v1.29 [stable]
KMS 加密驱动使用封套加密模型来加密 etcd 中的数据。数据使用数据加密密钥(DEK)加密。 这些 DEK 经一个密钥加密密钥(KEK)加密后在一个远端的 KMS 中存储和管理。
如果你使用(已弃用的)KMS v1 实现,每次加密将生成新的 DEK。
对于 KMS v2,每次加密将生成新的 DEK: API 服务器使用密钥派生函数根据秘密的种子数结合一些随机数据生成一次性的数据加密密钥。 种子会在 KEK 轮换时进行轮换 (有关更多详细信息,请参阅下面的“了解 key_id 和密钥轮换”章节)。
KMS 驱动使用 gRPC 通过 UNIX 域套接字与一个特定的 KMS 插件通信。 这个 KMS 插件作为一个 gRPC 服务器被部署在 Kubernetes 控制平面的相同主机上,负责与远端 KMS 的通信。
为了在 API 服务器上配置 KMS 驱动,在加密配置文件中的 providers 数组中加入一个类型为 kms
的驱动,并设置下列属性:
apiVersion:针对 KMS 驱动的 API 版本。此项留空或设为 v1。name:KMS 插件的显示名称。一旦设置,就无法更改。endpoint:gRPC 服务器(KMS 插件)的监听地址。该端点是一个 UNIX 域套接字。cachesize:以明文缓存的数据加密密钥(DEK)的数量。一旦被缓存,
就可以直接使用 DEK 而无需另外调用 KMS;而未被缓存的 DEK 需要调用一次 KMS 才能解包。timeout:在返回一个错误之前,kube-apiserver 等待 kms-plugin 响应的时间(默认是 3 秒)。apiVersion:针对 KMS 驱动的 API 版本。此项设为 v2。name:KMS 插件的显示名称。一旦设置,就无法更改。endpoint:gRPC 服务器(KMS 插件)的监听地址。该端点是一个 UNIX 域套接字。timeout:在返回一个错误之前,kube-apiserver 等待 kms-plugin 响应的时间(默认是 3 秒)。KMS v2 不支持 cachesize 属性。一旦服务器通过调用 KMS 解密了数据加密密钥(DEK),
所有的 DEK 将会以明文形式被缓存。一旦被缓存,DEK 可以无限期地用于解密操作,而无需再次调用 KMS。
参见理解静态配置加密。
为实现一个 KMS 插件,你可以开发一个新的插件 gRPC 服务器或启用一个由你的云服务驱动提供的 KMS 插件。 你可以将这个插件与远程 KMS 集成,并把它部署到 Kubernetes 控制平面上。
有关启用云服务驱动特定的 KMS 插件的说明,请咨询你的云服务驱动商。
你可以使用 Go 语言的存根文件开发 KMS 插件 gRPC 服务器。 对于其他语言,你可以用 proto 文件创建可以用于开发 gRPC 服务器代码的存根文件。
使用 Go:提供了一个高级库简化这个过程。 底层实现可以使用存根文件 api.pb.go 中的函数和数据结构开发 gRPC 服务器代码。
使用 Go 以外的其他语言:用 protoc 编译器编译 proto 文件: api.proto 为指定语言生成存根文件。
然后使用存根文件中的函数和数据结构开发服务器代码。
kms 插件版本:v1beta1
作为对过程调用 Version 的响应,兼容的 KMS 插件应把 v1beta1 作为 VersionResponse.version 版本返回。
消息版本:v1beta1
所有来自 KMS 驱动的消息都把 version 字段设置为 v1beta1。
协议:UNIX 域套接字 (unix)
该插件被实现为一个在 UNIX 域套接字上侦听的 gRPC 服务器。
该插件部署时应在文件系统上创建一个文件来运行 gRPC UNIX 域套接字连接。
API 服务器(gRPC 客户端)配置了 KMS 驱动(gRPC 服务器)UNIX 域套接字端点,以便与其通信。
通过以 /@ 开头的端点,可以使用一个抽象的 Linux 套接字,即 unix:///@foo。
使用这种类型的套接字时必须小心,因为它们没有 ACL 的概念(与传统的基于文件的套接字不同)。
然而,这些套接字遵从 Linux 网络命名空间约束,因此只能由同一 Pod 中的容器进行访问,除非使用了主机网络。
KMS 插件版本:v2
作为对过程调用 Status 的响应,兼容的 KMS 插件应把 StatusResponse.version 作为其 KMS 兼容版本返回。
该状态响应还应包括 "ok" 作为 StatusResponse.healthz 以及 key_id(远程 KMS KEK ID)作为
StatusResponse.key_id。Kubernetes 项目建议你的插件与稳定的 v2 KMS API 兼容。
Kubernetes 1.29 针对 KMS 还支持 v2beta1 API;
Kubernetes 后续版本可能会继续支持该 Beta 版本。
当一切健康时,API 服务器大约每分钟轮询一次 Status 过程调用,
而插件不健康时每 10 秒钟轮询一次。使用这些插件时要注意优化此调用,因为此调用将经受持续的负载。
加密
EncryptRequest 过程调用提供明文和一个 UID 以用于日志记录。
响应必须包括密文、使用的 KEK 的 key_id,以及可选的任意元数据,这些元数据可以
帮助 KMS 插件在未来的 DecryptRequest 调用中(通过 annotations 字段)进行解密。
插件必须保证所有不同的明文都会产生不同的响应 (ciphertext, key_id, annotations)。
如果插件返回一个非空的 annotations 映射,则所有映射键必须是完全限定域名,
例如 example.com。annotation 的一个示例用例是
{"kms.example.io/remote-kms-auditid":"<远程 KMS 使用的审计 ID>"}。
当 API 服务器运行正常时,并不会高频执行 EncryptRequest 过程调用。
插件实现仍应力求使每个请求的延迟保持在 100 毫秒以下。
解密
DecryptRequest 过程调用提供 EncryptRequest 中的 (ciphertext, key_id, annotations)
和一个 UID 以用于日志记录。正如预期的那样,它是 EncryptRequest 调用的反向操作。插件必须验证
key_id 是否为其理解的密钥ID - 除非这些插件确定数据是之前自己加密的,否则不应尝试解密。
在启动时,API 服务器可能会执行数千个 DecryptRequest 过程调用以填充其监视缓存。
因此,插件实现必须尽快执行这些调用,并应力求使每个请求的延迟保持在 10 毫秒以下。
理解 key_id 和密钥轮换
key_id 是目前使用的远程 KMS KEK 的公共、非机密名称。
它可能会在 API 服务器的常规操作期间记录,因此不得包含任何私有数据。
建议插件实现使用哈希来避免泄漏任何数据。
KMS v2 指标负责在通过 /metrics 端点公开之前对此值进行哈希。
API 服务器认为从 Status 过程调用返回的 key_id 是权威性的。因此,此值的更改表示远程 KEK 已更改,
并且使用旧 KEK 加密的数据应在执行无操作写入时标记为过期(如下所述)。如果 EncryptRequest
过程调用返回与 Status 不同的 key_id,则响应将被丢弃,并且插件将被认为是不健康的。
因此,插件实现必须保证从 Status 返回的 key_id 与 EncryptRequest 返回的 key_id 相同。
此外,插件必须确保 key_id 是稳定的,并且不会在不同值之间翻转(即在远程 KEK 轮换期间)。
插件不能重新使用 key_id,即使在先前使用的远程 KEK 被恢复的情况下也是如此。
例如,如果插件使用了 key_id=A,切换到 key_id=B,然后又回到 key_id=A,
那么插件应报告 key_id=A_001 或使用一个新值,如 key_id=C。
由于 API 服务器大约每分钟轮询一次 Status,因此 key_id 轮换并不立即发生。
此外,API 服务器在三分钟内以最近一个有效状态为准。因此,
如果用户想采取被动方法进行存储迁移(即等待),则必须安排迁移在远程 KEK 轮换后的 3 + N + M 分钟内发生
(其中 N 表示插件观察 key_id 更改所需的时间,M 是允许处理配置更改的缓冲区时间 - 建议至少使用 5 分钟)。
请注意,执行 KEK 轮换不需要进行 API 服务器重启。
因为你未控制使用 DEK 执行的写入次数,所以 Kubernetes 项目建议至少每 90 天轮换一次 KEK。
协议:UNIX 域套接字 (unix)
该插件被实现为一个在 UNIX 域套接字上侦听的 gRPC 服务器。
该插件部署时应在文件系统上创建一个文件来运行 gRPC UNIX 域套接字连接。
API 服务器(gRPC 客户端)配置了 KMS 驱动(gRPC 服务器)UNIX 域套接字端点,以便与其通信。
通过以 /@ 开头的端点,可以使用一个抽象的 Linux 套接字,即 unix:///@foo。
使用这种类型的套接字时必须小心,因为它们没有 ACL 的概念(与传统的基于文件的套接字不同)。
然而,这些套接字遵从 Linux 网络命名空间,因此只能由同一 Pod 中的容器进行访问,除非使用了主机网络。
KMS 插件可以用任何受 KMS 支持的协议与远程 KMS 通信。
所有的配置数据,包括 KMS 插件用于与远程 KMS 通信的认证凭据,都由 KMS 插件独立地存储和管理。
KMS 插件可以用额外的元数据对密文进行编码,这些元数据是在把它发往 KMS 进行解密之前可能要用到的
(KMS v2 提供了专用的 annotations 字段简化了这个过程)。
确保 KMS 插件与 Kubernetes API 服务器运行在同一主机上。
为了加密数据:
使用适合于 kms 驱动的属性创建一个新的 EncryptionConfiguration 文件,以加密
Secret 和 ConfigMap 等资源。
如果要加密使用 CustomResourceDefinition 定义的扩展 API,你的集群必须运行 Kubernetes v1.26 或更高版本。
设置 kube-apiserver 的 --encryption-provider-config 参数指向配置文件的位置。
--encryption-provider-config-automatic-reload 布尔参数决定了磁盘内容发生变化时是否应自动重新加载
通过 --encryption-provider-config 设置的文件。这样可以在不重启 API 服务器的情况下进行密钥轮换。
重启你的 API 服务器。
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- kms:
name: myKmsPluginFoo
endpoint: unix:///tmp/socketfile.sock
cachesize: 100
timeout: 3s
- kms:
name: myKmsPluginBar
endpoint: unix:///tmp/socketfile.sock
cachesize: 100
timeout: 3s
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
- configmaps
- pandas.awesome.bears.example
providers:
- kms:
apiVersion: v2
name: myKmsPluginFoo
endpoint: unix:///tmp/socketfile.sock
timeout: 3s
- kms:
apiVersion: v2
name: myKmsPluginBar
endpoint: unix:///tmp/socketfile.sock
timeout: 3s
--encryption-provider-config-automatic-reload 设置为 true 会将所有健康检查集中到同一个健康检查端点。
只有 KMS v1 驱动正使用且加密配置未被自动重新加载时,才能进行独立的健康检查。
下表总结了每个 KMS 版本的健康检查端点:
| KMS 配置 | 没有自动重新加载 | 有自动重新加载 |
|---|---|---|
| 仅 KMS v1 | Individual Healthchecks | Single Healthcheck |
| 仅 KMS v2 | Single Healthcheck | Single Healthcheck |
| KMS v1 和 v2 | Individual Healthchecks | Single Healthcheck |
| 没有 KMS | 无 | Single Healthcheck |
Single Healthcheck 意味着唯一的健康检查端点是 /healthz/kms-providers。
Individual Healthchecks 意味着每个 KMS 插件都有一个对应的健康检查端点,
并且这一端点基于插件在加密配置中的位置确定,例如 /healthz/kms-provider-0、/healthz/kms-provider-1 等。
这些健康检查端点路径是由服务器硬编码、生成并控制的。
Individual Healthchecks 的索引序号对应于 KMS 加密配置被处理的顺序。
在执行确保所有 Secret 都加密中所给步骤之前,
providers 列表应以 identity: {} 提供程序作为结尾,以允许读取未加密的数据。
加密所有资源后,应移除 identity 提供程序,以防止 API 服务器接受未加密的数据。
有关 EncryptionConfiguration 格式的更多详细信息,请参阅
kube-apiserver 加密 API 参考(v1)。
当静态加密被正确配置时,资源将在写入时被加密。
重启 kube-apiserver 后,所有新建或更新的 Secret 或在
EncryptionConfiguration 中配置的其他资源类型在存储时应该已被加密。
要验证这点,你可以用 etcdctl 命令行程序获取私密数据的内容。
在默认的命名空间里创建一个名为 secret1 的 Secret:
kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
用 etcdctl 命令行,从 etcd 读取出 Secret:
ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 [...] | hexdump -C
其中 [...] 包含连接 etcd 服务器的额外参数。
k8s:enc:kms:v1: 开头,
对于 KMS v2,保存的 Secret 以 k8s:enc:kms:v2: 开头,这表明 kms 驱动已经对结果数据加密。验证通过 API 获取的 Secret 已被正确解密:
kubectl describe secret secret1 -n default
Secret 应包含 mykey: mydata。
当静态加密被正确配置时,资源将在写入时被加密。 这样我们可以执行就地零干预更新来确保数据被加密。
下列命令读取所有 Secret 并更新它们以便应用服务器端加密。如果因为写入冲突导致错误发生, 请重试此命令。对较大的集群,你可能希望根据命名空间或脚本更新去细分 Secret 内容。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
为了从本地加密驱动切换到 kms 驱动并重新加密所有 Secret 内容:
在配置文件中加入 kms 驱动作为第一个条目,如下列样例所示
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- kms:
apiVersion: v2
name : myKmsPlugin
endpoint: unix:///tmp/socketfile.sock
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
重启所有 kube-apiserver 进程。
运行下列命令使用 kms 驱动强制重新加密所有 Secret。
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
如果你不想再对 Kubernetes API 中保存的数据加密, 请阅读解密已静态存储的数据。
此页面介绍了 CoreDNS 升级过程以及如何安装 CoreDNS 而不是 kube-dns。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.9. 要获知版本信息,请输入kubectl version.
CoreDNS 是一个灵活可扩展的 DNS 服务器,可以作为 Kubernetes 集群 DNS。 与 Kubernetes 一样,CoreDNS 项目由 CNCF 托管。
通过替换现有集群部署中的 kube-dns,或者使用 kubeadm 等工具来为你部署和升级集群, 可以在你的集群中使用 CoreDNS 而非 kube-dns。
有关手动部署或替换 kube-dns,请参阅 CoreDNS 网站。
在 Kubernetes 1.21 版本中,kubeadm 移除了对将 kube-dns 作为 DNS 应用的支持。
对于 kubeadm v1.29,所支持的唯一的集群 DNS 应用是 CoreDNS。
当你使用 kubeadm 升级使用 kube-dns 的集群时,你还可以执行到 CoreDNS 的迁移。
在这种场景中,kubeadm 将基于 kube-dns ConfigMap 生成 CoreDNS 配置("Corefile"),
保存存根域和上游名称服务器的配置。
你可以在 Kubernetes 中的 CoreDNS 版本 页面查看 kubeadm 为不同版本 Kubernetes 所安装的 CoreDNS 版本。
如果你只想升级 CoreDNS 或使用自己的定制镜像,也可以手动升级 CoreDNS。 参看指南和演练 文档了解如何平滑升级。 在升级你的集群过程中,请确保现有 CoreDNS 的配置("Corefile")被保留下来。
如果使用 kubeadm 工具来升级集群,则 kubeadm 可以自动处理保留现有 CoreDNS
配置这一事项。
当资源利用方面有问题时,优化 CoreDNS 的配置可能是有用的。 有关详细信息,请参阅有关扩缩 CoreDNS 的文档。
你可以通过修改 CoreDNS 的配置("Corefile")来配置 CoreDNS,
以支持比 kube-dns 更多的用例。
请参考 kubernetes CoreDNS 插件的文档
或者 CoreDNS 博客上的博文
Kubernetes 的自定义 DNS 条目,
以了解更多信息。
Kubernetes v1.18 [stable]
本页概述了 Kubernetes 中的 NodeLocal DNSCache 功能。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
NodeLocal DNSCache 通过在集群节点上作为 DaemonSet 运行 DNS 缓存代理来提高集群 DNS 性能。
在当今的体系结构中,运行在 'ClusterFirst' DNS 模式下的 Pod 可以连接到 kube-dns serviceIP 进行 DNS 查询。
通过 kube-proxy 添加的 iptables 规则将其转换为 kube-dns/CoreDNS 端点。
借助这种新架构,Pod 将可以访问在同一节点上运行的 DNS 缓存代理,从而避免 iptables DNAT 规则和连接跟踪。
本地缓存代理将查询 kube-dns 服务以获取集群主机名的缓存缺失(默认为 "cluster.local" 后缀)。
nf_conntrack_udp_timeout 是 30 秒)。启用 NodeLocal DNSCache 之后,DNS 查询所遵循的路径如下:

此图显示了 NodeLocal DNSCache 如何处理 DNS 查询。
NodeLocal DNSCache 的本地侦听 IP 地址可以是任何地址,只要该地址不和你的集群里现有的 IP 地址发生冲突。 推荐使用本地范围内的地址,例如,IPv4 链路本地区段 '169.254.0.0/16' 内的地址, 或者 IPv6 唯一本地地址区段 'fd00::/8' 内的地址。
可以使用以下步骤启动此功能:
nodelocaldns.yaml
准备一个清单,把它保存为 nodelocaldns.yaml。health [__PILLAR__LOCAL__DNS__]:8080"。把清单里的变量更改为正确的值:
kubedns=`kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}`
domain=<cluster-domain>
localdns=<node-local-address>
<cluster-domain> 的默认值是 "cluster.local"。<node-local-address> 是
NodeLocal DNSCache 选择的本地侦听 IP 地址。
如果 kube-proxy 运行在 IPTABLES 模式:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns.yaml
node-local-dns Pod 会设置 __PILLAR__CLUSTER__DNS__ 和 __PILLAR__UPSTREAM__SERVERS__。
在此模式下, node-local-dns Pod 会同时侦听 kube-dns 服务的 IP 地址和
<node-local-address> 的地址,以便 Pod 可以使用其中任何一个 IP 地址来查询 DNS 记录。
如果 kube-proxy 运行在 IPVS 模式:
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g; s/__PILLAR__DNS__DOMAIN__/$domain/g; s/,__PILLAR__DNS__SERVER__//g; s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns.yaml
在此模式下,node-local-dns Pod 只会侦听 <node-local-address> 的地址。
node-local-dns 接口不能绑定 kube-dns 的集群 IP 地址,因为 IPVS 负载均衡使用的接口已经占用了该地址。
node-local-dns Pod 会设置 __PILLAR__UPSTREAM__SERVERS__。
运行 kubectl create -f nodelocaldns.yaml
如果 kube-proxy 运行在 IPVS 模式,需要修改 kubelet 的 --cluster-dns 参数
NodeLocal DNSCache 正在侦听的 <node-local-address> 地址。
否则,不需要修改 --cluster-dns 参数,因为 NodeLocal DNSCache 会同时侦听
kube-dns 服务的 IP 地址和 <node-local-address> 的地址。
启用后,node-local-dns Pod 将在每个集群节点上的 kube-system 名字空间中运行。
此 Pod 在缓存模式下运行 CoreDNS,
因此每个节点都可以使用不同插件公开的所有 CoreDNS 指标。
如果要禁用该功能,你可以使用 kubectl delete -f <manifest> 来删除 DaemonSet。
你还应该回滚你对 kubelet 配置所做的所有改动。
node-local-dns Pod 能够自动读取 kube-system 名字空间中 kube-dns ConfigMap
中保存的 StubDomains 和上游服务器信息。ConfigMap
中的内容需要遵从此示例中所给的格式。
node-local-dns ConfigMap 也可被直接修改,使用 Corefile 格式设置 stubDomain 配置。
某些云厂商可能不允许直接修改 node-local-dns ConfigMap 的内容。
在这种情况下,可以更新 kube-dns ConfigMap。
node-local-dns Pod 使用内存来保存缓存项并处理查询。
由于它们并不监视 Kubernetes 对象变化,集群规模或者 Service/EndpointSlices
的数量都不会直接影响内存用量。内存用量会受到 DNS 查询模式的影响。
根据 CoreDNS 文档,
The default cache size is 10000 entries, which uses about 30 MB when completely filled. (默认的缓存大小是 10000 个表项,当完全填充时会使用约 30 MB 内存)
这一数值是(缓存完全被填充时)每个服务器块的内存用量。 通过设置小一点的缓存大小可以降低内存用量。
并发查询的数量会影响内存需求,因为用来处理查询请求而创建的 Go 协程都需要一定量的内存。
你可以在 forward 插件中使用 max_concurrent 选项设置并发查询数量上限。
如果一个 node-local-dns Pod 尝试使用的内存超出可提供的内存量
(因为系统资源总量的,或者所配置的资源约束)的原因,
操作系统可能会关闭这一 Pod 的容器。
发生这种情况时,被终止的("OOMKilled")容器不会清理其启动期间所添加的定制包过滤规则。
该 node-local-dns 容器应该会被重启(因其作为 DaemonSet 的一部分被管理),
但因上述原因可能每次容器失败时都会导致 DNS 有一小段时间不可用:
the packet filtering rules direct DNS queries to a local Pod that is unhealthy
(包过滤器规则将 DNS 查询转发到本地某个不健康的 Pod)。
通过不带限制地运行 node-local-dns Pod 并度量其内存用量峰值,你可以为其确定一个合适的内存限制值。
你也可以安装并使用一个运行在 “Recommender Mode(建议者模式)” 的
VerticalPodAutoscaler,
并查看该组件输出的建议信息。
Kubernetes v1.21 [stable]
本文档介绍如何通过 sysctl 接口在 Kubernetes 集群中配置和使用内核参数。
从 Kubernetes 1.23 版本开始,kubelet 支持使用 / 或 . 作为 sysctl 参数的分隔符。
从 Kubernetes 1.25 版本开始,支持为 Pod 设置 sysctl 时使用设置名字带有斜线的 sysctl。
例如,你可以使用点或者斜线作为分隔符表示相同的 sysctl 参数,以点作为分隔符表示为: kernel.shm_rmid_forced,
或者以斜线作为分隔符表示为:kernel/shm_rmid_forced。
更多 sysctl 参数转换方法详情请参考 Linux man-pages
sysctl.d(5)。
sysctl 是一个 Linux 特有的命令行工具,用于配置各种内核参数,
它在非 Linux 操作系统上无法使用。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
对一些步骤,你需要能够重新配置在你的集群里运行的 kubelet 命令行的选项。
在 Linux 中,管理员可以通过 sysctl 接口修改内核运行时的参数。在 /proc/sys/
虚拟文件系统下存放许多内核参数。这些参数涉及了多个内核子系统,如:
kernel.)net.)vm.)dev.)若要获取完整的参数列表,请执行以下命令:
sudo sysctl -a
Kubernetes 将 sysctl 参数分为 安全 和 非安全的。 安全 的 sysctl 参数除了需要设置恰当的命名空间外,在同一节点上的不同 Pod 之间也必须是 相互隔离的。这意味着 Pod 上设置 安全的 sysctl 参数时:
至今为止,大多数 有命名空间的 sysctl 参数不一定被认为是 安全 的。 以下几种 sysctl 参数是 安全的:
kernel.shm_rmid_forced;net.ipv4.ip_local_port_range;net.ipv4.tcp_syncookies;net.ipv4.ping_group_range(从 Kubernetes 1.18 开始);net.ipv4.ip_unprivileged_port_start(从 Kubernetes 1.22 开始);net.ipv4.ip_local_reserved_ports(从 Kubernetes 1.27 开始,需要 kernel 3.16+);net.ipv4.tcp_keepalive_time(从 Kubernetes 1.29 开始,需要 kernel 4.5+);net.ipv4.tcp_fin_timeout(从 Kubernetes 1.29 开始,需要 kernel 4.6+);net.ipv4.tcp_keepalive_intvl(从 Kubernetes 1.29 开始,需要 kernel 4.5+);net.ipv4.tcp_keepalive_probes(从 Kubernetes 1.29 开始,需要 kernel 4.5+)。安全 sysctl 参数有一些例外:
net.* sysctl 参数不允许在启用主机网络的情况下使用。net.ipv4.tcp_syncookies sysctl 参数在 Linux 内核 4.4 或更低的版本中是无命名空间的。在未来的 Kubernetes 版本中,若 kubelet 支持更好的隔离机制, 则上述列表中将会列出更多 安全的 sysctl 参数。
所有 安全的 sysctl 参数都默认启用。
所有 非安全的 sysctl 参数都默认禁用,且必须由集群管理员在每个节点上手动开启。 那些设置了不安全 sysctl 参数的 Pod 仍会被调度,但无法正常启动。
参考上述警告,集群管理员只有在一些非常特殊的情况下(如:高可用或实时应用调整), 才可以启用特定的 非安全的 sysctl 参数。 如需启用 非安全的 sysctl 参数,请你在每个节点上分别设置 kubelet 命令行参数,例如:
kubelet --allowed-unsafe-sysctls \
'kernel.msg*,net.core.somaxconn' ...
如果你使用 Minikube,可以通过 extra-config 参数来配置:
minikube start --extra-config="kubelet.allowed-unsafe-sysctls=kernel.msg*,net.core.somaxconn"...
只有 有命名空间的 sysctl 参数可以通过该方式启用。
目前,在 Linux 内核中,有许多的 sysctl 参数都是 有命名空间的。 这就意味着可以为节点上的每个 Pod 分别去设置它们的 sysctl 参数。 在 Kubernetes 中,只有那些有命名空间的 sysctl 参数可以通过 Pod 的 securityContext 对其进行配置。
以下列出有命名空间的 sysctl 参数,在未来的 Linux 内核版本中,此列表可能会发生变化。
kernel.shm*,kernel.msg*,kernel.sem,fs.mqueue.*,net.*。但是,也有例外(例如
net.netfilter.nf_conntrack_max 和 net.netfilter.nf_conntrack_expect_max
可以在容器网络命名空间中设置,但在 Linux 5.12.2 之前它们是无命名空间的)。没有命名空间的 sysctl 参数称为 节点级别的 sysctl 参数。 如果需要对其进行设置,则必须在每个节点的操作系统上手动地去配置它们, 或者通过在 DaemonSet 中运行特权模式容器来配置。
可使用 Pod 的 securityContext 来配置有命名空间的 sysctl 参数, securityContext 应用于同一个 Pod 中的所有容器。
此示例中,使用 Pod SecurityContext 来对一个安全的 sysctl 参数
kernel.shm_rmid_forced 以及两个非安全的 sysctl 参数
net.core.somaxconn 和 kernel.msgmax 进行设置。
在 Pod 规约中对 安全的 和 非安全的 sysctl 参数不做区分。
为了避免破坏操作系统的稳定性,请你在了解变更后果之后再修改 sysctl 参数。
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: kernel.shm_rmid_forced
value: "0"
- name: net.core.somaxconn
value: "1024"
- name: kernel.msgmax
value: "65536"
...
由于 非安全的 sysctl 参数其本身具有不稳定性,在使用 非安全的 sysctl 参数时可能会导致一些严重问题, 如容器的错误行为、机器资源不足或节点被完全破坏,用户需自行承担风险。
最佳实践方案是将集群中具有特殊 sysctl 设置的节点视为 有污点的,并且只调度需要使用到特殊 sysctl 设置的 Pod 到这些节点上。建议使用 Kubernetes 的污点和容忍度特性 来实现它。
设置了 非安全的 sysctl 参数的 Pod 在禁用了这两种 非安全的 sysctl 参数配置的节点上启动都会失败。 与 节点级别的 sysctl 一样, 建议开启污点和容忍度特性或 为节点配置污点以便将 Pod 调度到正确的节点之上。
Kubernetes v1.22 [beta]
Kubernetes 内存管理器(Memory Manager)为 Guaranteed
QoS 类
的 Pods 提供可保证的内存(及大页面)分配能力。
内存管理器使用提示生成协议来为 Pod 生成最合适的 NUMA 亲和性配置。 内存管理器将这类亲和性提示输入给中央管理器(即 Topology Manager)。 基于所给的提示和 Topology Manager(拓扑管理器)的策略设置,Pod 或者会被某节点接受,或者被该节点拒绝。
此外,内存管理器还确保 Pod 所请求的内存是从尽量少的 NUMA 节点分配而来。
内存管理器仅能用于 Linux 主机。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.21. 要获知版本信息,请输入kubectl version.
为了使得内存资源与 Pod 规约中所请求的其他资源对齐:
从 v1.22 开始,内存管理器通过特性门控
MemoryManager 默认启用。
在 v1.22 之前,kubelet 必须在启动时设置如下标志:
--feature-gates=MemoryManager=true
这样内存管理器特性才会被启用。
内存管理器目前为 Guaranteed QoS 类中的 Pod 提供可保证的内存(和大页面)分配能力。
若要立即将内存管理器启用,可参照内存管理器配置节中的指南,
之后按将 Pod 放入 Guaranteed QoS 类
节中所展示的,准备并部署一个 Guaranteed Pod。
内存管理器是一个提示驱动组件(Hint Provider),负责为拓扑管理器提供拓扑提示,
后者根据这些拓扑提示对所请求的资源执行对齐操作。
内存管理器也会为 Pods 应用 cgroups 设置(即 cpuset.mems)。
与 Pod 准入和部署流程相关的完整流程图在Memory Manager KEP: Design Overview,
下面也有说明。

在这个过程中,内存管理器会更新其内部存储于节点映射和内存映射中的计数器, 从而管理有保障的内存分配。
内存管理器在启动和运行期间按下述逻辑更新节点映射(Node Map)。
当节点管理员应用 --reserved-memory 预留内存标志时执行此逻辑。
这时,节点映射会被更新以反映内存的预留,如
Memory Manager KEP: Memory Maps at start-up (with examples)
所说明。
当配置了 Static 策略时,管理员必须提供 --reserved-memory 标志设置。
参考文献 Memory Manager KEP: Memory Maps at runtime (with examples) 中说明了成功的 Pod 部署是如何影响节点映射的,该文档也解释了可能发生的内存不足 (Out-of-memory,OOM)情况是如何进一步被 Kubernetes 或操作系统处理的。
在内存管理器运作的语境中,一个重要的话题是对 NUMA 分组的管理。 每当 Pod 的内存请求超出单个 NUMA 节点容量时,内存管理器会尝试创建一个包含多个 NUMA 节点的分组,从而扩展内存容量。解决这个问题的详细描述在文档 Memory Manager KEP: How to enable the guaranteed memory allocation over many NUMA nodes? 中。同时,关于 NUMA 分组是如何管理的,你还可以参考文档 Memory Manager KEP: Simulation - how the Memory Manager works? (by examples)。
其他管理器也要预先配置。接下来,内存管理器特性需要被启用,
并且采用 Static 策略(静态策略)运行。
作为可选操作,可以预留一定数量的内存给系统或者 kubelet 进程以增强节点的稳定性
(预留内存标志)。
内存管理器支持两种策略。你可以通过 kubelet 标志 --memory-manager-policy
来选择一种策略:
None (默认)Static这是默认的策略,并且不会以任何方式影响内存分配。该策略的行为好像内存管理器不存在一样。
None 策略返回默认的拓扑提示信息。这种特殊的提示会表明拓扑驱动组件(Hint Provider)
(在这里是内存管理器)对任何资源都没有与 NUMA 亲和性关联的偏好。
对 Guaranteed Pod 而言,Static 内存管理器策略会返回拓扑提示信息,
该信息与内存分配有保障的 NUMA 节点集合有关,并且内存管理器还通过更新内部的节点映射
对象来完成内存预留。
对 BestEffort 或 Burstable Pod 而言,因为不存在对有保障的内存资源的请求,
Static 内存管理器策略会返回默认的拓扑提示,并且不会通过内部的节点映射对象来预留内存。
节点可分配机制通常被节点管理员用来为 kubelet 或操作系统进程预留 K8S 节点上的系统资源,目的是提高节点稳定性。 有一组专用的标志可用于这个目的,为节点设置总的预留内存量。 此预配置的值接下来会被用来计算节点上对 Pods “可分配的”内存。
Kubernetes 调度器在优化 Pod 调度过程时,会考虑“可分配的”内存。
前面提到的标志包括 --kube-reserved、--system-reserved 和 --eviction-threshold。
这些标志值的综合计作预留内存的总量。
为内存管理器而新增加的 --reserved-memory 标志可以(让节点管理员)将总的预留内存进行划分,
并完成跨 NUMA 节点的预留操作。
标志设置的值是一个按 NUMA 节点的不同内存类型所给的内存预留的值的列表,用逗号分开。 可以使用分号作为分隔符来指定跨多个 NUMA 节点的内存预留。 只有在内存管理器特性被启用的语境下,这个参数才有意义。 内存管理器不会使用这些预留的内存来为容器负载分配内存。
例如,如果你有一个可用内存为 10Gi 的 NUMA 节点 "NUMA0",而参数 --reserved-memory
被设置成要在 "NUMA0" 上预留 1Gi 的内存,那么内存管理器会假定节点上只有 9Gi
内存可用于容器负载。
你也可以忽略此参数,不过这样做时,你要清楚,所有 NUMA
节点上预留内存的数量要等于节点可分配特性
所设定的内存量。如果至少有一个节点可分配参数值为非零,你就需要至少为一个 NUMA
节点设置 --reserved-memory。实际上,eviction-hard 阈值默认为 100Mi,
所以当使用 Static 策略时,--reserved-memory 是必须设置的。
此外,应尽量避免如下配置:
memory 或 hugepages-<size> 的内存类型名称
(特定的 <size> 的大页面也必须存在)。语法:
--reserved-memory N:memory-type1=value1,memory-type2=value2,...
N(整数)- NUMA 节点索引,例如,0memory-type(字符串)- 代表内存类型:
memory - 常规内存;hugepages-2Mi 或 hugepages-1Gi - 大页面value(字符串) - 预留内存的量,例如 1Gi用法示例:
--reserved-memory 0:memory=1Gi,hugepages-1Gi=2Gi
或者
--reserved-memory 0:memory=1Gi --reserved-memory 1:memory=2Gi
--reserved-memory '0:memory=1Gi;1:memory=2Gi'
当你为 --reserved-memory 标志指定取值时,必须要遵从之前通过节点可分配特性标志所设置的值。
换言之,对每种内存类型而言都要遵从下面的规则:
sum(reserved-memory(i)) = kube-reserved + system-reserved + eviction-threshold
其中,i 是 NUMA 节点的索引。
如果你不遵守上面的公式,内存管理器会在启动时输出错误信息。
换言之,上面的例子我们一共要预留 3Gi 的常规内存(type=memory),即:
sum(reserved-memory(i)) = reserved-memory(0) + reserved-memory(1) = 1Gi + 2Gi = 3Gi
下面的例子中给出与节点可分配配置相关的 kubelet 命令行参数:
--kube-reserved=cpu=500m,memory=50Mi--system-reserved=cpu=123m,memory=333Mi--eviction-hard=memory.available<500Mi默认的硬性驱逐阈值是 100MiB,不是零。
请记得在使用 --reserved-memory 设置要预留的内存量时,加上这个硬性驱逐阈值。
否则 kubelet 不会启动内存管理器,而会输出一个错误信息。
下面是一个正确配置的示例:
--feature-gates=MemoryManager=true
--kube-reserved=cpu=4,memory=4Gi
--system-reserved=cpu=1,memory=1Gi
--memory-manager-policy=Static
--reserved-memory '0:memory=3Gi;1:memory=2148Mi'
我们对上面的配置做一个检查:
kube-reserved + system-reserved + eviction-hard(default) = reserved-memory(0) + reserved-memory(1)4GiB + 1GiB + 100MiB = 3GiB + 2148MiB5120MiB + 100MiB = 3072MiB + 2148MiB5220MiB = 5220MiB (这是对的)若所选择的策略不是 None,则内存管理器会辨识处于 Guaranteed QoS 类中的 Pod。
内存管理器为每个 Guaranteed Pod 向拓扑管理器提供拓扑提示信息。
对于不在 Guaranteed QoS 类中的其他 Pod,内存管理器向拓扑管理器提供默认的拓扑提示信息。
下面的来自 Pod 清单的片段将 Pod 加入到 Guaranteed QoS 类中。
当 Pod 的 CPU requests 等于 limits 且为整数值时,Pod 将运行在 Guaranteed QoS 类中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
此外,共享 CPU 的 Pods 在 requests 等于 limits 值时也运行在 Guaranteed QoS 类中。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "300m"
example.com/device: "1"
要注意的是,只有 CPU 和内存请求都被设置时,Pod 才会进入 Guaranteed QoS 类。
下面的方法可用来排查为什么 Pod 无法被调度或者被节点拒绝:
这类错误通常在以下情形出现:
错误信息会出现在 Pod 的状态中:
kubectl get pods
NAME READY STATUS RESTARTS AGE
guaranteed 0/1 TopologyAffinityError 0 113s
使用 kubectl describe pod <id> 或 kubectl get events 可以获得详细的错误信息。
Warning TopologyAffinityError 10m kubelet, dell8 Resources cannot be allocated with Topology locality
针对特定的 Pod 搜索系统日志。
内存管理器为 Pod 所生成的提示信息可以在日志中找到。 此外,日志中应该也存在 CPU 管理器所生成的提示信息。
拓扑管理器将这些提示信息进行合并,计算得到唯一的最合适的提示数据。 此最佳提示数据也应该出现在日志中。
最佳提示表明要在哪里分配所有的资源。拓扑管理器会用当前的策略来测试此数据, 并基于得出的结论或者接纳 Pod 到节点,或者将其拒绝。
此外,你可以搜索日志查找与内存管理器相关的其他条目,例如 cgroups 和
cpuset.mems 的更新信息等。
我们首先部署一个 Guaranteed Pod 示例,其规约如下所示:
apiVersion: v1
kind: Pod
metadata:
name: guaranteed
spec:
containers:
- name: guaranteed
image: consumer
imagePullPolicy: Never
resources:
limits:
cpu: "2"
memory: 150Gi
requests:
cpu: "2"
memory: 150Gi
command: ["sleep","infinity"]
接下来,我们登录到 Pod 运行所在的节点,检查位于
/var/lib/kubelet/memory_manager_state 的状态文件:
{
"policyName":"Static",
"machineState":{
"0":{
"numberOfAssignments":1,
"memoryMap":{
"hugepages-1Gi":{
"total":0,
"systemReserved":0,
"allocatable":0,
"reserved":0,
"free":0
},
"memory":{
"total":134987354112,
"systemReserved":3221225472,
"allocatable":131766128640,
"reserved":131766128640,
"free":0
}
},
"nodes":[
0,
1
]
},
"1":{
"numberOfAssignments":1,
"memoryMap":{
"hugepages-1Gi":{
"total":0,
"systemReserved":0,
"allocatable":0,
"reserved":0,
"free":0
},
"memory":{
"total":135286722560,
"systemReserved":2252341248,
"allocatable":133034381312,
"reserved":29295144960,
"free":103739236352
}
},
"nodes":[
0,
1
]
}
},
"entries":{
"fa9bdd38-6df9-4cf9-aa67-8c4814da37a8":{
"guaranteed":[
{
"numaAffinity":[
0,
1
],
"type":"memory",
"size":161061273600
}
]
}
},
"checksum":4142013182
}
从这个状态文件,可以推断 Pod 被同时绑定到两个 NUMA 节点,即:
"numaAffinity":[
0,
1
],
术语绑定(pinned)意味着 Pod 的内存使用被(通过 cgroups 配置)限制到这些 NUMA 节点。
这也直接意味着内存管理器已经创建了一个 NUMA 分组,由这两个 NUMA 节点组成,
即索引值分别为 0 和 1 的 NUMA 节点。
注意 NUMA 分组的管理是有一个相对复杂的管理器处理的, 相关逻辑的进一步细节可在内存管理器的 KEP 中示例1和跨 NUMA 节点节找到。
为了分析 NUMA 组中可用的内存资源,必须对分组内 NUMA 节点对应的条目进行汇总。
例如,NUMA 分组中空闲的“常规”内存的总量可以通过将分组内所有 NUMA
节点上空闲内存加和来计算,即将 NUMA 节点 0 和 NUMA 节点 1 的 "memory" 节
(分别是 "free":0 和 "free": 103739236352)相加,得到此分组中空闲的“常规”
内存总量为 0 + 103739236352 字节。
"systemReserved": 3221225472 这一行表明节点的管理员使用 --reserved-memory 为 NUMA
节点 0 上运行的 kubelet 和系统进程预留了 3221225472 字节 (即 3Gi)。
kubelet 提供了一个 PodResourceLister gRPC 服务来启用对资源和相关元数据的检测。
通过使用它的
List gRPC 端点,
可以获得每个容器的预留内存信息,该信息位于 protobuf 协议的 ContainerMemory 消息中。
只能针对 Guaranteed QoS 类中的 Pod 来检索此信息。
Kubernetes v1.24 [alpha]
你需要安装以下工具:
Kubernetes 发布过程使用 cosign 的无密钥签名对所有二进制工件(压缩包、 SPDX 文件、 独立的二进制文件)签名。要验证一个特定的二进制文件, 获取组件时要包含其签名和证书:
URL=https://dl.k8s.io/release/v1.29.2/bin/linux/amd64
BINARY=kubectl
FILES=(
"$BINARY"
"$BINARY.sig"
"$BINARY.cert"
)
for FILE in "${FILES[@]}"; do
curl -sSfL --retry 3 --retry-delay 3 "$URL/$FILE" -o "$FILE"
done
然后使用 cosign verify-blob 验证二进制文件:
cosign verify-blob "$BINARY" \
--signature "$BINARY".sig \
--certificate "$BINARY".cert \
--certificate-identity krel-staging@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com
Cosign 2.0 需要指定 --certificate-identity 和 --certificate-oidc-issuer 选项。
想要进一步了解无密钥签名,请参考 Keyless Signatures。
Cosign 的早期版本还需要设置 COSIGN_EXPERIMENTAL=1。
如需更多信息,请参考 sigstore Blog
完整的镜像签名列表请参见发行版本。
从这个列表中选择一个镜像,并使用 cosign verify 命令来验证它的签名:
cosign verify registry.k8s.io/kube-apiserver-amd64:v1.29.2 \
--certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
| jq .
验证最新稳定版(v1.29.2)所有已签名的控制平面组件镜像, 请运行以下命令:
curl -Ls "https://sbom.k8s.io/$(curl -Ls https://dl.k8s.io/release/stable.txt)/release" \
| grep "SPDXID: SPDXRef-Package-registry.k8s.io" \
| grep -v sha256 | cut -d- -f3- | sed 's/-/\//' | sed 's/-v1/:v1/' \
| sort > images.txt
input=images.txt
while IFS= read -r image
do
cosign verify "$image" \
--certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
| jq .
done < "$input"
当你完成某个镜像的验证时,可以在你的 Pod 清单通过摘要值来指定该镜像,例如:
registry-url/image-name@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2
要了解更多信息,请参考镜像拉取策略章节。
有一些非控制平面镜像
(例如 conformance 镜像),
也可以在部署时使用
sigstore policy-controller
控制器验证其签名。以下是一些有助于你开始使用 policy-controller 的资源:
你可以使用 sigstore 证书和签名或相应的 SHA 文件来验证 Kubernetes 软件物料清单(SBOM):
# 检索最新可用的 Kubernetes 发行版本
VERSION=$(curl -Ls https://dl.k8s.io/release/stable.txt)
# 验证 SHA512 sum
curl -Ls "https://sbom.k8s.io/$VERSION/release" -o "$VERSION.spdx"
echo "$(curl -Ls "https://sbom.k8s.io/$VERSION/release.sha512") $VERSION.spdx" | sha512sum --check
# 验证 SHA256 sum
echo "$(curl -Ls "https://sbom.k8s.io/$VERSION/release.sha256") $VERSION.spdx" | sha256sum --check
# 检索 sigstore 签名和证书
curl -Ls "https://sbom.k8s.io/$VERSION/release.sig" -o "$VERSION.spdx.sig"
curl -Ls "https://sbom.k8s.io/$VERSION/release.cert" -o "$VERSION.spdx.cert"
# 验证 sigstore 签名
cosign verify-blob \
--certificate "$VERSION.spdx.cert" \
--signature "$VERSION.spdx.sig" \
--certificate-identity krel-staging@k8s-releng-prod.iam.gserviceaccount.com \
--certificate-oidc-issuer https://accounts.google.com \
"$VERSION.spdx"
此页面展示如何将内存请求(request)和内存限制(limit)分配给一个容器。 我们保障容器拥有它请求数量的内存,但不允许使用超过限制数量的内存。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
你集群中的每个节点必须拥有至少 300 MiB 的内存。
该页面上的一些步骤要求你在集群中运行 metrics-server 服务。 如果你已经有在运行中的 metrics-server,则可以跳过这些步骤。
如果你运行的是 Minikube,可以运行下面的命令启用 metrics-server:
minikube addons enable metrics-server
要查看 metrics-server 或资源指标 API (metrics.k8s.io) 是否已经运行,请运行以下命令:
kubectl get apiservices
如果资源指标 API 可用,则输出结果将包含对 metrics.k8s.io 的引用信息。
NAME
v1beta1.metrics.k8s.io
创建一个命名空间,以便将本练习中创建的资源与集群的其余部分隔离。
kubectl create namespace mem-example
要为容器指定内存请求,请在容器资源清单中包含 resources: requests 字段。
同理,要指定内存限制,请包含 resources: limits。
在本练习中,你将创建一个拥有一个容器的 Pod。 容器将会请求 100 MiB 内存,并且内存会被限制在 200 MiB 以内。 这是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
配置文件的 args 部分提供了容器启动时的参数。
"--vm-bytes", "150M" 参数告知容器尝试分配 150 MiB 内存。
开始创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit.yaml --namespace=mem-example
验证 Pod 中的容器是否已运行:
kubectl get pod memory-demo --namespace=mem-example
查看 Pod 相关的详细信息:
kubectl get pod memory-demo --output=yaml --namespace=mem-example
输出结果显示:该 Pod 中容器的内存请求为 100 MiB,内存限制为 200 MiB。
...
resources:
requests:
memory: 100Mi
limits:
memory: 200Mi
...
运行 kubectl top 命令,获取该 Pod 的指标数据:
kubectl top pod memory-demo --namespace=mem-example
输出结果显示:Pod 正在使用的内存大约为 162,900,000 字节,约为 150 MiB。 这大于 Pod 请求的 100 MiB,但在 Pod 限制的 200 MiB之内。
NAME CPU(cores) MEMORY(bytes)
memory-demo <something> 162856960
删除 Pod:
kubectl delete pod memory-demo --namespace=mem-example
当节点拥有足够的可用内存时,容器可以使用其请求的内存。 但是,容器不允许使用超过其限制的内存。 如果容器分配的内存超过其限制,该容器会成为被终止的候选容器。 如果容器继续消耗超出其限制的内存,则终止容器。 如果终止的容器可以被重启,则 kubelet 会重新启动它,就像其他任何类型的运行时失败一样。
在本练习中,你将创建一个 Pod,尝试分配超出其限制的内存。 这是一个 Pod 的配置文件,其拥有一个容器,该容器的内存请求为 50 MiB,内存限制为 100 MiB:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: mem-example
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
在配置文件的 args 部分中,你可以看到容器会尝试分配 250 MiB 内存,这远高于 100 MiB 的限制。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit-2.yaml --namespace=mem-example
查看 Pod 相关的详细信息:
kubectl get pod memory-demo-2 --namespace=mem-example
此时,容器可能正在运行或被杀死。重复前面的命令,直到容器被杀掉:
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 24s
获取容器更详细的状态信息:
kubectl get pod memory-demo-2 --output=yaml --namespace=mem-example
输出结果显示:由于内存溢出(OOM),容器已被杀掉:
lastState:
terminated:
containerID: 65183c1877aaec2e8427bc95609cc52677a454b56fcb24340dbd22917c23b10f
exitCode: 137
finishedAt: 2017-06-20T20:52:19Z
reason: OOMKilled
startedAt: null
本练习中的容器可以被重启,所以 kubelet 会重启它。 多次运行下面的命令,可以看到容器在反复的被杀死和重启:
kubectl get pod memory-demo-2 --namespace=mem-example
输出结果显示:容器被杀掉、重启、再杀掉、再重启……:
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 37s
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 1/1 Running 2 40s
查看关于该 Pod 历史的详细信息:
kubectl describe pod memory-demo-2 --namespace=mem-example
输出结果显示:该容器反复的在启动和失败:
... Normal Created Created container with id 66a3a20aa7980e61be4922780bf9d24d1a1d8b7395c09861225b0eba1b1f8511
... Warning BackOff Back-off restarting failed container
查看关于集群节点的详细信息:
kubectl describe nodes
输出结果包含了一条练习中的容器由于内存溢出而被杀掉的记录:
Warning OOMKilling Memory cgroup out of memory: Kill process 4481 (stress) score 1994 or sacrifice child
删除 Pod:
kubectl delete pod memory-demo-2 --namespace=mem-example
内存请求和限制是与容器关联的,但将 Pod 视为具有内存请求和限制,也是很有用的。 Pod 的内存请求是 Pod 中所有容器的内存请求之和。 同理,Pod 的内存限制是 Pod 中所有容器的内存限制之和。
Pod 的调度基于请求。只有当节点拥有足够满足 Pod 内存请求的内存时,才会将 Pod 调度至节点上运行。
在本练习中,你将创建一个 Pod,其内存请求超过了你集群中的任意一个节点所拥有的内存。 这是该 Pod 的配置文件,其拥有一个请求 1000 GiB 内存的容器,这应该超过了你集群中任何节点的容量。
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-3
namespace: mem-example
spec:
containers:
- name: memory-demo-3-ctr
image: polinux/stress
resources:
requests:
memory: "1000Gi"
limits:
memory: "1000Gi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/memory-request-limit-3.yaml --namespace=mem-example
查看 Pod 状态:
kubectl get pod memory-demo-3 --namespace=mem-example
输出结果显示:Pod 处于 PENDING 状态。 这意味着,该 Pod 没有被调度至任何节点上运行,并且它会无限期的保持该状态:
kubectl get pod memory-demo-3 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 25s
查看关于 Pod 的详细信息,包括事件:
kubectl describe pod memory-demo-3 --namespace=mem-example
输出结果显示:由于节点内存不足,该容器无法被调度:
Events:
... Reason Message
------ -------
... FailedScheduling No nodes are available that match all of the following predicates:: Insufficient memory (3).
内存资源的基本单位是字节(byte)。你可以使用这些后缀之一,将内存表示为 纯整数或定点整数:E、P、T、G、M、K、Ei、Pi、Ti、Gi、Mi、Ki。 例如,下面是一些近似相同的值:
128974848, 129e6, 129M, 123Mi
删除 Pod:
kubectl delete pod memory-demo-3 --namespace=mem-example
如果你没有为一个容器指定内存限制,则自动遵循以下情况之一:
容器可无限制地使用内存。容器可以使用其所在节点所有的可用内存, 进而可能导致该节点调用 OOM Killer。 此外,如果发生 OOM Kill,没有资源限制的容器将被杀掉的可行性更大。
运行的容器所在命名空间有默认的内存限制,那么该容器会被自动分配默认限制。 集群管理员可用使用 LimitRange 来指定默认的内存限制。
通过为集群中运行的容器配置内存请求和限制,你可以有效利用集群节点上可用的内存资源。 通过将 Pod 的内存请求保持在较低水平,你可以更好地安排 Pod 调度。 通过让内存限制大于内存请求,你可以完成两件事:
删除命名空间。下面的命令会删除你根据这个任务创建的所有 Pod:
kubectl delete namespace mem-example
本页面展示如何为容器设置 CPU request(请求) 和 CPU limit(限制)。 容器使用的 CPU 不能超过所配置的限制。 如果系统有空闲的 CPU 时间,则可以保证给容器分配其所请求数量的 CPU 资源。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
你的集群必须至少有 1 个 CPU 可用才能运行本任务中的示例。
本页的一些步骤要求你在集群中运行 metrics-server 服务。如果你的集群中已经有正在运行的 metrics-server 服务,可以跳过这些步骤。
如果你正在运行 Minikube,请运行以下命令启用 metrics-server:
minikube addons enable metrics-server
查看 metrics-server(或者其他资源指标 API metrics.k8s.io 服务提供者)是否正在运行,
请键入以下命令:
kubectl get apiservices
如果资源指标 API 可用,则会输出将包含一个对 metrics.k8s.io 的引用。
NAME
v1beta1.metrics.k8s.io
创建一个名字空间,以便将 本练习中创建的资源与集群的其余部分资源隔离。
kubectl create namespace cpu-example
要为容器指定 CPU 请求,请在容器资源清单中包含 resources: requests 字段。
要指定 CPU 限制,请包含 resources:limits。
在本练习中,你将创建一个具有一个容器的 Pod。容器将会请求 0.5 个 CPU,而且最多限制使用 1 个 CPU。 这是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
- -cpus
- "2"
配置文件的 args 部分提供了容器启动时的参数。
-cpus "2" 参数告诉容器尝试使用 2 个 CPU。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/cpu-request-limit.yaml --namespace=cpu-example
验证所创建的 Pod 处于 Running 状态
kubectl get pod cpu-demo --namespace=cpu-example
查看显示关于 Pod 的详细信息:
kubectl get pod cpu-demo --output=yaml --namespace=cpu-example
输出显示 Pod 中的一个容器的 CPU 请求为 500 milliCPU,并且 CPU 限制为 1 个 CPU。
resources:
limits:
cpu: "1"
requests:
cpu: 500m
使用 kubectl top 命令来获取该 Pod 的指标:
kubectl top pod cpu-demo --namespace=cpu-example
此示例输出显示 Pod 使用的是 974 milliCPU,即略低于 Pod 配置中指定的 1 个 CPU 的限制。
NAME CPU(cores) MEMORY(bytes)
cpu-demo 974m <something>
回想一下,通过设置 -cpu "2",你将容器配置为尝试使用 2 个 CPU,
但是容器只被允许使用大约 1 个 CPU。
容器的 CPU 用量受到限制,因为该容器正尝试使用超出其限制的 CPU 资源。
CPU 使用率低于 1.0 的另一种可能的解释是,节点可能没有足够的 CPU 资源可用。 回想一下,此练习的先决条件需要你的集群至少具有 1 个 CPU 可用。 如果你的容器在只有 1 个 CPU 的节点上运行,则容器无论为容器指定的 CPU 限制如何, 都不能使用超过 1 个 CPU。
CPU 资源以 CPU 单位度量。Kubernetes 中的一个 CPU 等同于:
小数值是可以使用的。一个请求 0.5 CPU 的容器保证会获得请求 1 个 CPU 的容器的 CPU 的一半。
你可以使用后缀 m 表示毫。例如 100m CPU、100 milliCPU 和 0.1 CPU 都相同。
精度不能超过 1m。
CPU 请求只能使用绝对数量,而不是相对数量。0.1 在单核、双核或 48 核计算机上的 CPU 数量值是一样的。
删除 Pod:
kubectl delete pod cpu-demo --namespace=cpu-example
CPU 请求和限制与都与容器相关,但是我们可以考虑一下 Pod 具有对应的 CPU 请求和限制这样的场景。 Pod 对 CPU 用量的请求等于 Pod 中所有容器的请求数量之和。 同样,Pod 的 CPU 资源限制等于 Pod 中所有容器 CPU 资源限制数之和。
Pod 调度是基于资源请求值来进行的。 仅在某节点具有足够的 CPU 资源来满足 Pod CPU 请求时,Pod 将会在对应节点上运行:
在本练习中,你将创建一个 Pod,该 Pod 的 CPU 请求对于集群中任何节点的容量而言都会过大。 下面是 Pod 的配置文件,其中有一个容器。容器请求 100 个 CPU,这可能会超出集群中任何节点的容量。
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo-2
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr-2
image: vish/stress
resources:
limits:
cpu: "100"
requests:
cpu: "100"
args:
- -cpus
- "2"
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/cpu-request-limit-2.yaml --namespace=cpu-example
查看该 Pod 的状态:
kubectl get pod cpu-demo-2 --namespace=cpu-example
输出显示 Pod 状态为 Pending。也就是说,Pod 未被调度到任何节点上运行, 并且 Pod 将无限期地处于 Pending 状态:
NAME READY STATUS RESTARTS AGE
cpu-demo-2 0/1 Pending 0 7m
查看有关 Pod 的详细信息,包含事件:
kubectl describe pod cpu-demo-2 --namespace=cpu-example
输出显示由于节点上的 CPU 资源不足,无法调度容器:
Events:
Reason Message
------ -------
FailedScheduling No nodes are available that match all of the following predicates:: Insufficient cpu (3).
删除你的 Pod:
kubectl delete pod cpu-demo-2 --namespace=cpu-example
如果你没有为容器指定 CPU 限制,则会发生以下情况之一:
容器在可以使用的 CPU 资源上没有上限。因而可以使用所在节点上所有的可用 CPU 资源。
容器在具有默认 CPU 限制的名字空间中运行,系统会自动为容器设置默认限制。 集群管理员可以使用 LimitRange 指定 CPU 限制的默认值。
如果你为容器指定了 CPU 限制值但未为其设置 CPU 请求,Kubernetes 会自动为其 设置与 CPU 限制相同的 CPU 请求值。类似的,如果容器设置了内存限制值但未设置 内存请求值,Kubernetes 也会为其设置与内存限制值相同的内存请求。
通过配置你的集群中运行的容器的 CPU 请求和限制,你可以有效利用集群上可用的 CPU 资源。 通过将 Pod CPU 请求保持在较低水平,可以使 Pod 更有机会被调度。 通过使 CPU 限制大于 CPU 请求,你可以完成两件事:
Pod 可能会有突发性的活动,它可以利用碰巧可用的 CPU 资源。
Pod 在突发负载期间可以使用的 CPU 资源数量仍被限制为合理的数量。
删除名字空间:
kubectl delete namespace cpu-example
Kubernetes v1.27 [alpha]
本页假定你已经熟悉了 Kubernetes Pod 的服务质量。
本页说明如何在不重启 Pod 或其容器的情况下调整分配给运行中 Pod 容器的 CPU 和内存资源。
Kubernetes 节点会基于 Pod 的 requests 为 Pod 分配资源,
并基于 Pod 的容器中指定的 limits 限制 Pod 的资源使用。
对于原地调整 Pod 资源而言:
requests 和 limits 是可变更的。containerStatuses 的 allocatedResources 字段反映了分配给 Pod 容器的资源。containerStatuses 的 resources
字段反映了如同容器运行时所报告的、针对正运行的容器配置的实际资源 requests 和 limits。resize 字段显示上次请求待处理的调整状态。此字段可以具有以下值:
Proposed:此值表示请求调整已被确认,并且请求已被验证和记录。InProgress:此值表示节点已接受调整请求,并正在将其应用于 Pod 的容器。Deferred:此值意味着在此时无法批准请求的调整,节点将继续重试。
当其他 Pod 退出并释放节点资源时,调整可能会被真正实施。Infeasible:此值是一种信号,表示节点无法承接所请求的调整值。
如果所请求的调整超过节点可分配给 Pod 的最大资源,则可能会发生这种情况。你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.27. 要获知版本信息,请输入kubectl version.
调整策略允许更精细地控制 Pod 中的容器如何针对 CPU 和内存资源进行调整。 例如,容器的应用程序可以处理 CPU 资源的调整而不必重启, 但是调整内存可能需要应用程序重启,因此容器也必须重启。
为了实现这一点,容器规约允许用户指定 resizePolicy。
针对调整 CPU 和内存可以设置以下重启策略:
NotRequired:在运行时调整容器的资源。RestartContainer:重启容器并在重启后应用新资源。如果未指定 resizePolicy[*].restartPolicy,则默认为 NotRequired。
如果 Pod 的 restartPolicy 为 Never,则 Pod 中所有容器的调整重启策略必须被设置为 NotRequired。
下面的示例显示了一个 Pod,其中 CPU 可以在不重启容器的情况下进行调整,但是内存调整需要重启容器。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-5
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr-5
image: nginx
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: RestartContainer
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
在上述示例中,如果所需的 CPU 和内存请求或限制已更改,则容器将被重启以调整其内存。
你可以通过为 Pod 的容器指定请求和/或限制来创建 Guaranteed 或 Burstable 服务质量类的 Pod。
考虑以下包含一个容器的 Pod 的清单。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-5
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr-5
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
在 qos-example 名字空间中创建该 Pod:
kubectl create namespace qos-example
kubectl create -f https://k8s.io/examples/pods/qos/qos-pod-5.yaml --namespace=qos-example
此 Pod 被分类为 Guaranteed QoS 类,请求 700m CPU 和 200Mi 内存。
查看有关 Pod 的详细信息:
kubectl get pod qos-demo-5 --output=yaml --namespace=qos-example
另请注意,resizePolicy[*].restartPolicy 的值默认为 NotRequired,
表示可以在容器运行的情况下调整 CPU 和内存大小。
spec:
containers:
...
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: NotRequired
resources:
limits:
cpu: 700m
memory: 200Mi
requests:
cpu: 700m
memory: 200Mi
...
containerStatuses:
...
name: qos-demo-ctr-5
ready: true
...
allocatedResources:
cpu: 700m
memory: 200Mi
resources:
limits:
cpu: 700m
memory: 200Mi
requests:
cpu: 700m
memory: 200Mi
restartCount: 0
started: true
...
qosClass: Guaranteed
假设要求的 CPU 需求已上升,现在需要 0.8 CPU。这通常由 VerticalPodAutoscaler (VPA) 这样的实体确定并可能以编程方式应用。
尽管你可以更改 Pod 的请求和限制以表示新的期望资源, 但无法更改 Pod 创建时所归属的 QoS 类。
现在对 Pod 的 Container 执行 patch 命令,将容器的 CPU 请求和限制均设置为 800m:
kubectl -n qos-example patch pod qos-demo-5 --patch '{"spec":{"containers":[{"name":"qos-demo-ctr-5", "resources":{"requests":{"cpu":"800m"}, "limits":{"cpu":"800m"}}}]}}'
在 Pod 已打补丁后查询其详细信息。
kubectl get pod qos-demo-5 --output=yaml --namespace=qos-example
以下 Pod 规约反映了更新后的 CPU 请求和限制。
spec:
containers:
...
resources:
limits:
cpu: 800m
memory: 200Mi
requests:
cpu: 800m
memory: 200Mi
...
containerStatuses:
...
allocatedResources:
cpu: 800m
memory: 200Mi
resources:
limits:
cpu: 800m
memory: 200Mi
requests:
cpu: 800m
memory: 200Mi
restartCount: 0
started: true
观察到 allocatedResources 的值已更新,反映了新的预期 CPU 请求。
这表明节点能够容纳提高后的 CPU 资源需求。
在 Container 状态中,更新的 CPU 资源值显示已应用新的 CPU 资源。
Container 的 restartCount 保持不变,表示已在无需重启容器的情况下调整了容器的 CPU 资源。
删除你的名字空间:
kubectl delete namespace qos-example
Kubernetes v1.18 [stable]
本页展示如何为将运行在 Windows 节点上的 Pod 和容器配置 组管理的服务账号(Group Managed Service Accounts,GMSA)。 组管理的服务账号是活动目录(Active Directory)的一种特殊类型, 提供自动化的密码管理、简化的服务主体名称(Service Principal Name,SPN) 管理以及跨多个服务器将管理操作委派给其他管理员等能力。
在 Kubernetes 环境中,GMSA 凭据规约配置为 Kubernetes 集群范围的自定义资源 (Custom Resources)形式。Windows Pod 以及各 Pod 中的每个容器可以配置为使用 GMSA 来完成基于域(Domain)的操作(例如,Kerberos 身份认证),以便与其他 Windows 服务相交互。
你需要一个 Kubernetes 集群,以及 kubectl 命令行工具,
且工具必须已配置为能够与你的集群通信。集群预期包含 Windows 工作节点。
本节讨论需要为每个集群执行一次的初始操作。
你需要在集群上配置一个用于 GMSA 凭据规约资源的
CustomResourceDefinition(CRD),
以便定义类型为 GMSACredentialSpec 的自定义资源。首先下载 GMSA CRD
YAML
并将其保存为 gmsa-crd.yaml。接下来执行 kubectl apply -f gmsa-crd.yaml 安装 CRD。
你需要为 Kubernetes 集群配置两个 Webhook,在 Pod 或容器级别填充和检查 GMSA 凭据规约引用。
一个修改模式(Mutating)的 Webhook,将对 GMSA 的引用(在 Pod 规约中体现为名字) 展开为完整凭据规约的 JSON 形式,并保存回 Pod 规约中。
一个验证模式(Validating)的 Webhook,确保对 GMSA 的所有引用都是已经授权给 Pod 的服务账号使用的。
安装以上 Webhook 及其相关联的对象需要执行以下步骤:
创建一个证书密钥对(用于允许 Webhook 容器与集群通信)
安装一个包含如上证书的 Secret
创建一个包含核心 Webhook 逻辑的 Deployment
创建引用该 Deployment 的 Validating Webhook 和 Mutating Webhook 配置
你可以使用这个脚本
来部署和配置上述 GMSA Webhook 及相关联的对象。你还可以在运行脚本时设置 --dry-run=server
选项以便审查脚本将会对集群做出的变更。
脚本所使用的 YAML 模板 也可用于手动部署 Webhook 及相关联的对象,不过需要对其中的参数作适当替换。
在配置 Kubernetes 中的 Pod 以使用 GMSA 之前,需要按 Windows GMSA 文档 中描述的那样先在活动目录中准备好期望的 GMSA。 Windows 工作节点(作为 Kubernetes 集群的一部分)需要被配置到活动目录中,以便访问与期望的 GSMA 相关联的秘密凭据数据。这一操作的描述位于 Windows GMSA 文档 中。
当(如前所述)安装了 GMSACredentialSpec CRD 之后,你就可以配置包含 GMSA 凭据规约的自定义资源了。GMSA 凭据规约中并不包含秘密或敏感数据。 其中包含的信息主要用于容器运行时,便于后者向 Windows 描述容器所期望的 GMSA。 GMSA 凭据规约可以使用 PowerShell 脚本 以 YAML 格式生成。
下面是手动以 JSON 格式生成 GMSA 凭据规约并对其进行 YAML 转换的步骤:
导入 CredentialSpec 模块:ipmo CredentialSpec.psm1
使用 New-CredentialSpec 来创建一个 JSON 格式的凭据规约。
要创建名为 WebApp1 的 GMSA 凭据规约,调用
New-CredentialSpec -Name WebApp1 -AccountName WebApp1 -Domain $(Get-ADDomain -Current LocalComputer)。
使用 Get-CredentialSpec 来显示 JSON 文件的路径。
将凭据规约从 JSON 格式转换为 YAML 格式,并添加必要的头部字段
apiVersion、kind、metadata 和 credspec,使其成为一个可以在
Kubernetes 中配置的 GMSACredentialSpec 自定义资源。
下面的 YAML 配置描述的是一个名为 gmsa-WebApp1 的 GMSA 凭据规约:
apiVersion: windows.k8s.io/v1
kind: GMSACredentialSpec
metadata:
name: gmsa-WebApp1 # 这是随意起的一个名字,将用作引用
credspec:
ActiveDirectoryConfig:
GroupManagedServiceAccounts:
- Name: WebApp1 # GMSA 账号的用户名
Scope: CONTOSO # NETBIOS 域名
- Name: WebApp1 # GMSA 账号的用户名
Scope: contoso.com # DNS 域名
CmsPlugins:
- ActiveDirectory
DomainJoinConfig:
DnsName: contoso.com # DNS 域名
DnsTreeName: contoso.com # DNS 域名根
Guid: 244818ae-87ac-4fcd-92ec-e79e5252348a # GUID
MachineAccountName: WebApp1 # GMSA 账号的用户名
NetBiosName: CONTOSO # NETBIOS 域名
Sid: S-1-5-21-2126449477-2524075714-3094792973 # GMSA 的 SID
上面的凭据规约资源可以保存为 gmsa-Webapp1-credspec.yaml,之后使用
kubectl apply -f gmsa-Webapp1-credspec.yml 应用到集群上。
你需要为每个 GMSA 凭据规约资源定义集群角色。
该集群角色授权某主体(通常是一个服务账号)对特定的 GMSA 资源执行 use 动作。
下面的示例显示的是一个集群角色,对前文创建的凭据规约 gmsa-WebApp1 执行鉴权。
将此文件保存为 gmsa-webapp1-role.yaml 并执行 kubectl apply -f gmsa-webapp1-role.yaml。
# 创建集群角色读取凭据规约
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: webapp1-role
rules:
- apiGroups: ["windows.k8s.io"]
resources: ["gmsacredentialspecs"]
verbs: ["use"]
resourceNames: ["gmsa-WebApp1"]
你需要将某个服务账号(Pod 配置所对应的那个)绑定到前文创建的集群角色上。
这一绑定操作实际上授予该服务账号使用所指定的 GMSA 凭据规约资源的访问权限。
下面显示的是一个绑定到集群角色 webapp1-role 上的 default 服务账号,
使之能够使用前面所创建的 gmsa-WebApp1 凭据规约资源。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: allow-default-svc-account-read-on-gmsa-WebApp1
namespace: default
subjects:
- kind: ServiceAccount
name: default
namespace: default
roleRef:
kind: ClusterRole
name: webapp1-role
apiGroup: rbac.authorization.k8s.io
Pod 规约字段 securityContext.windowsOptions.gmsaCredentialSpecName
可用来设置对指定 GMSA 凭据规约自定义资源的引用。
设置此引用将会配置 Pod 中的所有容器使用所给的 GMSA。
下面是一个 Pod 规约示例,其中包含了对 gmsa-WebApp1 凭据规约的引用:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: with-creds
name: with-creds
namespace: default
spec:
replicas: 1
selector:
matchLabels:
run: with-creds
template:
metadata:
labels:
run: with-creds
spec:
securityContext:
windowsOptions:
gmsaCredentialSpecName: gmsa-webapp1
containers:
- image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
imagePullPolicy: Always
name: iis
nodeSelector:
kubernetes.io/os: windows
Pod 中的各个容器也可以使用对应容器的 securityContext.windowsOptions.gmsaCredentialSpecName
字段来设置期望使用的 GMSA 凭据规约。例如:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: with-creds
name: with-creds
namespace: default
spec:
replicas: 1
selector:
matchLabels:
run: with-creds
template:
metadata:
labels:
run: with-creds
spec:
containers:
- image: mcr.microsoft.com/windows/servercore/iis:windowsservercore-ltsc2019
imagePullPolicy: Always
name: iis
securityContext:
windowsOptions:
gmsaCredentialSpecName: gmsa-Webapp1
nodeSelector:
kubernetes.io/os: windows
当 Pod 规约中填充了 GMSA 相关字段(如上所述),在集群中应用 Pod 规约时会依次发生以下事件:
Mutating Webhook 解析对 GMSA 凭据规约资源的引用,并将其全部展开, 得到 GMSA 凭据规约的实际内容。
Validating Webhook 确保与 Pod 相关联的服务账号有权在所给的 GMSA 凭据规约上执行 use 动作。
容器运行时为每个 Windows 容器配置所指定的 GMSA 凭据规约, 这样容器就可以以活动目录中该 GMSA 所代表的身份来执行操作,使用该身份来访问域中的服务。
如果你在使用主机名或 FQDN 从 Pod 连接到 SMB 共享时遇到问题,但能够通过其 IPv4 地址访问共享, 请确保在 Windows 节点上设置了以下注册表项。
reg add "HKLM\SYSTEM\CurrentControlSet\Services\hns\State" /v EnableCompartmentNamespace /t REG_DWORD /d 1
然后需要重新创建正在运行的 Pod 以使行为更改生效。有关如何使用此注册表项的更多信息, 请参见此处。
如果在你的环境中配置 GMSA 时遇到了困难,你可以采取若干步骤来排查可能的故障。
首先,确保 credspec 已传递给 Pod。为此,你需要先运行 exec
进入到你的一个 Pod 中并检查 nltest.exe /parentdomain 命令的输出。
在下面的例子中,Pod 未能正确地获得凭据规约:
kubectl exec -it iis-auth-7776966999-n5nzr powershell.exe
nltest.exe /parentdomain 导致以下错误:
Getting parent domain failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
如果 Pod 未能正确获得凭据规约,则下一步就要检查与域之间的通信。 首先,从 Pod 内部快速执行一个 nslookup 操作,找到域根。
这一操作会告诉我们三件事情:
如果 DNS 和通信测试通过,接下来你需要检查是否 Pod 已经与域之间建立了安全通信通道。
要执行这一检查,你需要再次通过 exec 进入到你的 Pod 中并执行 nltest.exe /query 命令。
nltest.exe /query
结果输出如下:
I_NetLogonControl failed: Status = 1722 0x6ba RPC_S_SERVER_UNAVAILABLE
这告诉我们,由于某种原因,Pod 无法使用 credspec 中指定的帐户登录到域。 你可以尝试通过运行以下命令来修复安全通道:
nltest /sc_reset:domain.example
如果命令成功,你将看到类似以下内容的输出:
Flags: 30 HAS_IP HAS_TIMESERV
Trusted DC Name \\dc10.domain.example
Trusted DC Connection Status Status = 0 0x0 NERR_Success
The command completed successfully
如果以上命令修复了错误,你可以通过将以下生命周期回调添加到你的 Pod 规约中来自动执行该步骤。 如果这些操作没有修复错误,你将需要再次检查你的 credspec 并确认它是正确和完整的。
image: registry.domain.example/iis-auth:1809v1
lifecycle:
postStart:
exec:
command: ["powershell.exe","-command","do { Restart-Service -Name netlogon } while ( $($Result = (nltest.exe /query); if ($Result -like '*0x0 NERR_Success*') {return $true} else {return $false}) -eq $false)"]
imagePullPolicy: IfNotPresent
如果你向你的 Pod 规约中添加如上所示的 lifecycle 节,则 Pod
会自动执行所列举的命令来重启 netlogon 服务,直到 nltest.exe /query
命令返回时没有错误信息。
Kubernetes v1.18 [stable]
本页展示如何为运行为在 Windows 节点上运行的 Pod 和容器配置 RunAsUserName。
大致相当于 Linux 上的 runAsUser,允许在容器中以与默认值不同的用户名运行应用。
你必须有一个 Kubernetes 集群,并且 kubectl 必须能和集群通信。 集群应该要有 Windows 工作节点,将在其中调度运行 Windows 工作负载的 pod 和容器。
要指定运行 Pod 容器时所使用的用户名,请在 Pod 声明中包含 securityContext
(PodSecurityContext) 字段,
并在其内部包含 windowsOptions
(WindowsSecurityContextOptions)
字段的 runAsUserName 字段。
你为 Pod 指定的 Windows SecurityContext 选项适用于该 Pod 中(包括 init 容器)的所有容器。
这儿有一个已经设置了 runAsUserName 字段的 Windows Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: run-as-username-pod-demo
spec:
securityContext:
windowsOptions:
runAsUserName: "ContainerUser"
containers:
- name: run-as-username-demo
image: mcr.microsoft.com/windows/servercore:ltsc2019
command: ["ping", "-t", "localhost"]
nodeSelector:
kubernetes.io/os: windows
创建 Pod:
kubectl apply -f https://k8s.io/examples/windows/run-as-username-pod.yaml
验证 Pod 容器是否在运行:
kubectl get pod run-as-username-pod-demo
获取该容器的 shell:
kubectl exec -it run-as-username-pod-demo -- powershell
检查运行 shell 的用户的用户名是否正确:
echo $env:USERNAME
输出结果应该是这样:
ContainerUser
要指定运行容器时所使用的用户名,请在容器清单中包含 securityContext
(SecurityContext)
字段,并在其内部包含 windowsOptions
(WindowsSecurityContextOptions)
字段的 runAsUserName 字段。
你为容器指定的 Windows SecurityContext 选项仅适用于该容器,并且它会覆盖 Pod 级别设置。
这里有一个 Pod 的配置文件,其中只有一个容器,并且在 Pod 级别和容器级别都设置了 runAsUserName:
apiVersion: v1
kind: Pod
metadata:
name: run-as-username-container-demo
spec:
securityContext:
windowsOptions:
runAsUserName: "ContainerUser"
containers:
- name: run-as-username-demo
image: mcr.microsoft.com/windows/servercore:ltsc2019
command: ["ping", "-t", "localhost"]
securityContext:
windowsOptions:
runAsUserName: "ContainerAdministrator"
nodeSelector:
kubernetes.io/os: windows
创建 Pod:
kubectl apply -f https://k8s.io/examples/windows/run-as-username-container.yaml
验证 Pod 容器是否在运行:
kubectl get pod run-as-username-container-demo
获取该容器的 shell:
kubectl exec -it run-as-username-container-demo -- powershell
检查运行 shell 的用户的用户名是否正确(应该是容器级别设置的那个):
echo $env:USERNAME
输出结果应该是这样:
ContainerAdministrator
想要使用此功能,在 runAsUserName 字段中设置的值必须是有效的用户名。
它必须是 DOMAIN\USER 这种格式,其中 DOMAIN\ 是可选的。
Windows 用户名不区分大小写。此外,关于 DOMAIN 和 USER 还有一些限制:
runAsUserName 字段不能为空,并且不能包含控制字符(ASCII 值:0x00-0x1F、0x7F)DOMAIN 必须是 NetBios 名称或 DNS 名称,每种名称都有各自的局限性:
.(点)开头,并且不能包含以下字符:\ / : * ? " < > |.(点)或 -(中划线)开头和结尾。USER 最多不超过 20 个字符,不能只包含点或空格,并且不能包含以下字符:" / \ [ ] : ; | = , + * ? < > @runAsUserName 字段接受的值的一些示例:ContainerAdministrator、ContainerUser、
NT AUTHORITY\NETWORK SERVICE、NT AUTHORITY\LOCAL SERVICE。
Kubernetes v1.26 [stable]
Windows HostProcess 容器让你能够在 Windows 主机上运行容器化负载。 这类容器以普通的进程形式运行,但能够在具有合适用户特权的情况下, 访问主机网络名字空间、存储和设备。HostProcess 容器可用来在 Windows 节点上部署网络插件、存储配置、设备插件、kube-proxy 以及其他组件, 同时不需要配置专用的代理或者直接安装主机服务。
类似于安装安全补丁、事件日志收集等这类管理性质的任务可以在不需要集群操作员登录到每个 Windows 节点的前提下执行。HostProcess 容器可以以主机上存在的任何用户账号来运行, 也可以以主机所在域中的用户账号运行,这样管理员可以通过用户许可权限来限制资源访问。 尽管文件系统和进程隔离都不支持,在启动容器时会在主机上创建一个新的卷, 为其提供一个干净的、整合的工作空间。HostProcess 容器也可以基于现有的 Windows 基础镜像来制作,并且不再有 Windows 服务器容器所带有的那些 兼容性需求, 这意味着基础镜像的版本不必与主机操作系统的版本匹配。 不过,仍然建议你像使用 Windows 服务器容器负载那样,使用相同的基础镜像版本, 这样你就不会有一些未使用的镜像占用节点上的存储空间。HostProcess 容器也支持 在容器卷内执行卷挂载。
本任务指南是特定于 Kubernetes v1.29 的。 如果你运行的不是 Kubernetes v1.29,请移步访问正确 版本的 Kubernetes 文档。
在 Kubernetes v1.29 中,HostProcess 容器功能特性默认是启用的。 kubelet 会直接与 containerd 通信,通过 CRI 将主机进程标志传递过去。 你可以使用 containerd 的最新版本(v1.6+)来运行 HostProcess 容器。 参阅如何安装 containerd。
以下限制是与 Kubernetes v1.29 相关的:
启用 Windows HostProcess Pod 需要在 Pod 安全配置中设置合适的选项。 在 Pod 安全标准中所定义的策略中, HostProcess Pod 默认是不被 basline 和 restricted 策略支持的。因此建议 HostProcess 运行在与 privileged 模式相看齐的策略下。
当运行在 privileged 策略下时,下面是要启用 HostProcess Pod 创建所需要设置的选项:
| 控制 | 策略 |
|---|---|
| securityContext.windowsOptions.hostProcess |
Windows Pods 提供运行 HostProcess 容器的能力,这类容器能够具有对 Windows 节点的特权访问权限。 可选值
|
| hostNetwork |
Pod 容器 HostProcess 容器必须使用主机的网络名字空间。 可选值
|
| securityContext.windowsOptions.runAsUserName |
关于 HostProcess 容器所要使用的用户的规约,需要设置在 Pod 的规约中。 可选值
|
| runAsNonRoot |
因为 HostProcess 容器有访问主机的特权,runAsNonRoot 字段不可以设置为 true。 可选值
|
spec:
securityContext:
windowsOptions:
hostProcess: true
runAsUserName: "NT AUTHORITY\\Local service"
hostNetwork: true
containers:
- name: test
image: image1:latest
command:
- ping
- -t
- 127.0.0.1
nodeSelector:
"kubernetes.io/os": windows
HostProcess 容器支持在容器卷空间中挂载卷的能力。 卷挂载行为将因节点所使用的 containerd 运行时版本而异。
在容器内运行的应用能够通过相对或者绝对路径直接访问卷挂载。
环境变量 $CONTAINER_SANDBOX_MOUNT_POINT 在容器创建时被设置为指向容器卷的绝对主机路径。
相对路径是基于 .spec.containers.volumeMounts.mountPath 配置来推导的。
容器内支持通过下面的路径结构来访问服务账号令牌:
.\var\run\secrets\kubernetes.io\serviceaccount\$CONTAINER_SANDBOX_MOUNT_POINT\var\run\secrets\kubernetes.io\serviceaccount\容器内运行的应用可以通过 volumeMount 指定的 mountPath 直接访问卷挂载
(就像 Linux 和非 HostProcess Windows 容器一样)。
为了向后兼容性,卷也可以通过使用由 containerd v1.6 配置的相同相对路径进行访问。
例如,要在容器中访问服务帐户令牌,你将使用以下路径之一:
c:\var\run\secrets\kubernetes.io\serviceaccount/var/run/secrets/kubernetes.io/serviceaccount/$CONTAINER_SANDBOX_MOUNT_POINT\var\run\secrets\kubernetes.io\serviceaccount\资源限制(磁盘、内存、CPU 个数)作用到任务之上,并在整个任务上起作用。 例如,如果内存限制设置为 10MB,任何 HostProcess 任务对象所分配的内存不会超过 10MB。 这一行为与其他 Windows 容器类型相同。资源限制的设置方式与编排系统或容器运行时无关。 唯一的区别是用来跟踪资源所进行的磁盘资源用量的计算,出现差异的原因是因为 HostProcess 容器启动引导的方式造成的。
默认情况下,HostProcess 容器支持以三种被支持的 Windows 服务账号之一来运行:
你应该为每个 HostProcess 容器选择一个合适的 Windows 服务账号,尝试限制特权范围, 避免给主机代理意外的(甚至是恶意的)伤害。LocalSystem 服务账号的特权级 在三者之中最高,只有在绝对需要的时候才应该使用。只要可能,应该使用 LocalService 服务账号,因为该账号在三者中特权最低。
取决于配置,HostProcess 容器也能够以本地用户账号运行, 从而允许节点操作员为工作负载提供细粒度的访问权限。
要以本地用户运行 HostProcess 容器,必须首先在节点上创建一个本地用户组,
并在部署中在 runAsUserName 字段中指定该本地用户组的名称。
在初始化 HostProcess 容器之前,将创建一个新的临时本地用户账号,并加入到指定的用户组中,
使用这个账号来运行容器。这样做有许多好处,包括不再需要管理本地用户账号的密码。
作为服务账号运行的初始 HostProcess 容器可用于准备用户组,以供后续的 HostProcess 容器使用。
以本地用户账号运行 HostProcess 容器需要 containerd v1.7+。
例如:
在节点上创建本地用户组(这可以在另一个 HostProcess 容器中完成)。
net localgroup hpc-localgroup /add
针对 Pod 或个别容器,将 runAsUserName 设置为本地用户组的名称。
securityContext:
windowsOptions:
hostProcess: true
runAsUserName: hpc-localgroup
HostProcess 容器可以基于任何现有的 Windows Container 基础镜像进行构建。
此外,还专为 HostProcess 容器创建了一个新的基础镜像!有关更多信息,请查看 windows-host-process-containers-base-image github 项目。
HostProcess 容器因
failed to create user process token: failed to logon user: Access is denied.: unknown
启动失败。
确保 containerd 以 LocalSystem 或 LocalService 服务帐户运行。
用户账号(即使是管理员账号)没有权限为任何支持的用户账号创建登录令牌。
本页介绍怎样配置 Pod 以让其归属于特定的 服务质量类(Quality of Service class,QoS class). Kubernetes 在 Node 资源不足时使用 QoS 类来就驱逐 Pod 作出决定。
Kubernetes 创建 Pod 时,会将如下 QoS 类之一设置到 Pod 上:
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你还需要能够创建和删除名字空间。
创建一个名字空间,以便将本练习所创建的资源与集群的其余资源相隔离。
kubectl create namespace qos-example
对于 QoS 类为 Guaranteed 的 Pod:
这些限制同样适用于初始化容器和应用程序容器。 临时容器(Ephemeral Container) 无法定义资源,因此不受这些约束限制。
下面是包含一个 Container 的 Pod 清单。该 Container 设置了内存请求和内存限制,值都是 200 MiB。 该 Container 设置了 CPU 请求和 CPU 限制,值都是 700 milliCPU:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod.yaml --namespace=qos-example
查看 Pod 详情:
kubectl get pod qos-demo --namespace=qos-example --output=yaml
结果表明 Kubernetes 为 Pod 配置的 QoS 类为 Guaranteed。
结果也确认了 Pod 容器设置了与内存限制匹配的内存请求,设置了与 CPU 限制匹配的 CPU 请求。
spec:
containers:
...
resources:
limits:
cpu: 700m
memory: 200Mi
requests:
cpu: 700m
memory: 200Mi
...
status:
qosClass: Guaranteed
如果某 Container 指定了自己的内存限制,但没有指定内存请求,Kubernetes 会自动为它指定与内存限制相等的内存请求。同样,如果容器指定了自己的 CPU 限制, 但没有指定 CPU 请求,Kubernetes 会自动为它指定与 CPU 限制相等的 CPU 请求。
删除 Pod:
kubectl delete pod qos-demo --namespace=qos-example
如果满足下面条件,Kubernetes 将会指定 Pod 的 QoS 类为 Burstable:
Guaranteed QoS 类的标准。下面是包含一个 Container 的 Pod 清单。该 Container 设置的内存限制为 200 MiB, 内存请求为 100 MiB。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-2.yaml --namespace=qos-example
查看 Pod 详情:
kubectl get pod qos-demo-2 --namespace=qos-example --output=yaml
结果表明 Kubernetes 为 Pod 配置的 QoS 类为 Burstable:
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: qos-demo-2-ctr
resources:
limits:
memory: 200Mi
requests:
memory: 100Mi
...
status:
qosClass: Burstable
删除 Pod:
kubectl delete pod qos-demo-2 --namespace=qos-example
对于 QoS 类为 BestEffort 的 Pod,Pod 中的 Container 必须没有设置内存和 CPU 限制或请求。
下面是包含一个 Container 的 Pod 清单。该 Container 没有设置内存和 CPU 限制或请求。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-3.yaml --namespace=qos-example
查看 Pod 详情:
kubectl get pod qos-demo-3 --namespace=qos-example --output=yaml
结果表明 Kubernetes 为 Pod 配置的 QoS 类为 BestEffort。
spec:
containers:
...
resources: {}
...
status:
qosClass: BestEffort
删除 Pod:
kubectl delete pod qos-demo-3 --namespace=qos-example
下面是包含两个 Container 的 Pod 清单。一个 Container 指定内存请求为 200 MiB。 另外一个 Container 没有指定任何请求或限制。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-4
namespace: qos-example
spec:
containers:
- name: qos-demo-4-ctr-1
image: nginx
resources:
requests:
memory: "200Mi"
- name: qos-demo-4-ctr-2
image: redis
注意此 Pod 满足 Burstable QoS 类的标准。也就是说它不满足 Guaranteed QoS 类标准,
因为它的 Container 之一设有内存请求。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/qos/qos-pod-4.yaml --namespace=qos-example
查看 Pod 详情:
kubectl get pod qos-demo-4 --namespace=qos-example --output=yaml
结果表明 Kubernetes 为 Pod 配置的 QoS 类为 Burstable:
spec:
containers:
...
name: qos-demo-4-ctr-1
resources:
requests:
memory: 200Mi
...
name: qos-demo-4-ctr-2
resources: {}
...
status:
qosClass: Burstable
你也可以只查看你所需要的字段,而不是查看所有字段:
kubectl --namespace=qos-example get pod qos-demo-4 -o jsonpath='{ .status.qosClass}{"\n"}'
Burstable
删除名字空间:
kubectl delete namespace qos-example
Kubernetes v1.29 [stable]
本文介绍如何为容器指定扩展资源。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
在你开始此练习前,请先练习 为节点广播扩展资源。 在那个练习中将配置你的一个节点来广播 dongle 资源。
要请求扩展资源,需要在你的容器清单中包括 resources:requests 字段。
扩展资源可以使用任何完全限定名称,只是不能使用 *.kubernetes.io/。
有效的扩展资源名的格式为 example.com/foo,其中 example.com 应被替换为
你的组织的域名,而 foo 则是描述性的资源名称。
下面是包含一个容器的 Pod 配置文件:
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo
spec:
containers:
- name: extended-resource-demo-ctr
image: nginx
resources:
requests:
example.com/dongle: 3
limits:
example.com/dongle: 3
在配置文件中,你可以看到容器请求了 3 个 dongles。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod.yaml
检查 Pod 是否运行正常:
kubectl get pod extended-resource-demo
描述 Pod:
kubectl describe pod extended-resource-demo
输出结果显示 dongle 请求如下:
Limits:
example.com/dongle: 3
Requests:
example.com/dongle: 3
下面是包含一个容器的 Pod 配置文件,容器请求了 2 个 dongles。
apiVersion: v1
kind: Pod
metadata:
name: extended-resource-demo-2
spec:
containers:
- name: extended-resource-demo-2-ctr
image: nginx
resources:
requests:
example.com/dongle: 2
limits:
example.com/dongle: 2
Kubernetes 将不能满足 2 个 dongles 的请求,因为第一个 Pod 已经使用了 4 个可用 dongles 中的 3 个。
尝试创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/resource/extended-resource-pod-2.yaml
描述 Pod:
kubectl describe pod extended-resource-demo-2
输出结果表明 Pod 不能被调度,因为没有一个节点上存在两个可用的 dongles。
Conditions:
Type Status
PodScheduled False
...
Events:
...
... Warning FailedScheduling pod (extended-resource-demo-2) failed to fit in any node
fit failure summary on nodes : Insufficient example.com/dongle (1)
查看 Pod 的状态:
kubectl get pod extended-resource-demo-2
输出结果表明 Pod 虽然被创建了,但没有被调度到节点上正常运行。Pod 的状态为 Pending:
NAME READY STATUS RESTARTS AGE
extended-resource-demo-2 0/1 Pending 0 6m
删除本练习中创建的 Pod:
kubectl delete pod extended-resource-demo
kubectl delete pod extended-resource-demo-2
此页面展示了如何配置 Pod 以使用卷进行存储。
只要容器存在,容器的文件系统就会存在,因此当一个容器终止并重新启动,对该容器的文件系统改动将丢失。 对于独立于容器的持久化存储,你可以使用卷。 这对于有状态应用程序尤为重要,例如键值存储(如 Redis)和数据库。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
在本练习中,你将创建一个运行 Pod,该 Pod 仅运行一个容器并拥有一个类型为 emptyDir 的卷, 在整个 Pod 生命周期中一直存在,即使 Pod 中的容器被终止和重启。以下是 Pod 的配置:
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts:
- name: redis-storage
mountPath: /data/redis
volumes:
- name: redis-storage
emptyDir: {}
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/storage/redis.yaml
验证 Pod 中的容器是否正在运行,然后留意 Pod 的更改:
kubectl get pod redis --watch
输出如下:
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 13s
在另一个终端,用 Shell 连接正在运行的容器:
kubectl exec -it redis -- /bin/bash
在你的 Shell 中,切换到 /data/redis 目录下,然后创建一个文件:
root@redis:/data# cd /data/redis/
root@redis:/data/redis# echo Hello > test-file
在你的 Shell 中,列出正在运行的进程:
root@redis:/data/redis# apt-get update
root@redis:/data/redis# apt-get install procps
root@redis:/data/redis# ps aux
输出类似于:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
redis 1 0.1 0.1 33308 3828 ? Ssl 00:46 0:00 redis-server *:6379
root 12 0.0 0.0 20228 3020 ? Ss 00:47 0:00 /bin/bash
root 15 0.0 0.0 17500 2072 ? R+ 00:48 0:00 ps aux
在你的 Shell 中,结束 Redis 进程:
root@redis:/data/redis# kill <pid>
其中 <pid> 是 Redis 进程的 ID (PID)。
在你原先终端中,留意 Redis Pod 的更改。最终你将会看到和下面类似的输出:
NAME READY STATUS RESTARTS AGE
redis 1/1 Running 0 13s
redis 0/1 Completed 0 6m
redis 1/1 Running 1 6m
此时,容器已经终止并重新启动。这是因为 Redis Pod 的
restartPolicy
为 Always。
用 Shell 进入重新启动的容器中:
kubectl exec -it redis -- /bin/bash
在你的 Shell 中,进入到 /data/redis 目录下,并确认 test-file 文件是否仍然存在。
root@redis:/data/redis# cd /data/redis/
root@redis:/data/redis# ls
test-file
删除为此练习所创建的 Pod:
kubectl delete pod redis
本文将向你介绍如何配置 Pod 使用 PersistentVolumeClaim 作为存储。 以下是该过程的总结:
你作为集群管理员创建由物理存储支持的 PersistentVolume。你不会将该卷与任何 Pod 关联。
你现在以开发人员或者集群用户的角色创建一个 PersistentVolumeClaim, 它将自动绑定到合适的 PersistentVolume。
你创建一个使用以上 PersistentVolumeClaim 作为存储的 Pod。
打开集群中的某个节点的 Shell。
如何打开 Shell 取决于集群的设置。
例如,如果你正在使用 Minikube,那么可以通过输入 minikube ssh 来打开节点的 Shell。
在该节点的 Shell 中,创建一个 /mnt/data 目录:
# 这里假定你的节点使用 "sudo" 来以超级用户角色执行命令
sudo mkdir /mnt/data
在 /mnt/data 目录中创建一个 index.html 文件:
# 这里再次假定你的节点使用 "sudo" 来以超级用户角色执行命令
sudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"
如果你的节点使用某工具而不是 sudo 来完成超级用户访问,你可以将上述命令中的 sudo 替换为该工具的名称。
测试 index.html 文件确实存在:
cat /mnt/data/index.html
输出应该是:
Hello from Kubernetes storage
现在你可以关闭节点的 Shell 了。
在本练习中,你将创建一个 hostPath 类型的 PersistentVolume。 Kubernetes 支持用于在单节点集群上开发和测试的 hostPath 类型的 PersistentVolume。 hostPath 类型的 PersistentVolume 使用节点上的文件或目录来模拟网络附加存储。
在生产集群中,你不会使用 hostPath。 集群管理员会提供网络存储资源,比如 Google Compute Engine 持久盘卷、NFS 共享卷或 Amazon Elastic Block Store 卷。 集群管理员还可以使用 StorageClass 来设置动态制备存储。
下面是 hostPath PersistentVolume 的配置文件:
apiVersion: v1
kind: PersistentVolume
metadata:
name: task-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
此配置文件指定卷位于集群节点上的 /mnt/data 路径。
其配置还指定了卷的容量大小为 10 GB,访问模式为 ReadWriteOnce,
这意味着该卷可以被单个节点以读写方式安装。
此配置文件还在 PersistentVolume 中定义了
StorageClass 的名称为 manual。
它将用于将 PersistentVolumeClaim 的请求绑定到此 PersistentVolume。
为了简化,本示例采用了 ReadWriteOnce 访问模式。然而对于生产环境,
Kubernetes 项目建议改用 ReadWriteOncePod 访问模式。
创建 PersistentVolume:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-volume.yaml
查看 PersistentVolume 的信息:
kubectl get pv task-pv-volume
输出结果显示该 PersistentVolume 的状态(STATUS)为 Available。
这意味着它还没有被绑定给 PersistentVolumeClaim。
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Available manual 4s
下一步是创建一个 PersistentVolumeClaim。 Pod 使用 PersistentVolumeClaim 来请求物理存储。 在本练习中,你将创建一个 PersistentVolumeClaim,它请求至少 3 GB 容量的卷, 该卷一次最多可以为一个节点提供读写访问。
下面是 PersistentVolumeClaim 的配置文件:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: task-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
创建 PersistentVolumeClaim:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-claim.yaml
创建 PersistentVolumeClaim 之后,Kubernetes 控制平面将查找满足申领要求的 PersistentVolume。 如果控制平面找到具有相同 StorageClass 的适当的 PersistentVolume, 则将 PersistentVolumeClaim 绑定到该 PersistentVolume 上。
再次查看 PersistentVolume 信息:
kubectl get pv task-pv-volume
现在输出的 STATUS 为 Bound。
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Bound default/task-pv-claim manual 2m
查看 PersistentVolumeClaim:
kubectl get pvc task-pv-claim
输出结果表明该 PersistentVolumeClaim 绑定了你的 PersistentVolume task-pv-volume。
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
task-pv-claim Bound task-pv-volume 10Gi RWO manual 30s
下一步是创建一个使用你的 PersistentVolumeClaim 作为存储卷的 Pod。
下面是此 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: task-pv-pod
spec:
volumes:
- name: task-pv-storage
persistentVolumeClaim:
claimName: task-pv-claim
containers:
- name: task-pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: task-pv-storage
注意 Pod 的配置文件指定了 PersistentVolumeClaim,但没有指定 PersistentVolume。 对 Pod 而言,PersistentVolumeClaim 就是一个存储卷。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/storage/pv-pod.yaml
检查 Pod 中的容器是否运行正常:
kubectl get pod task-pv-pod
打开一个 Shell 访问 Pod 中的容器:
kubectl exec -it task-pv-pod -- /bin/bash
在 Shell 中,验证 Nginx 是否正在从 hostPath 卷提供 index.html 文件:
# 一定要在上一步 "kubectl exec" 所返回的 Shell 中执行下面三个命令
apt update
apt install curl
curl http://localhost/
输出结果是你之前写到 hostPath 卷中的 index.html 文件中的内容:
Hello from Kubernetes storage
如果你看到此消息,则证明你已经成功地配置了 Pod 使用 PersistentVolumeClaim 的存储。
删除 Pod、PersistentVolumeClaim 和 PersistentVolume 对象:
kubectl delete pod task-pv-pod
kubectl delete pvc task-pv-claim
kubectl delete pv task-pv-volume
如果你还没有连接到集群中节点的 Shell,可以按之前所做操作,打开一个新的 Shell。
在节点的 Shell 上,删除你所创建的目录和文件:
# 这里假定你使用 "sudo" 来以超级用户的角色执行命令
sudo rm /mnt/data/index.html
sudo rmdir /mnt/data
你现在可以关闭连接到节点的 Shell。
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- name: test
image: nginx
volumeMounts:
# 网站数据挂载
- name: config
mountPath: /usr/share/nginx/html
subPath: html
# Nginx 配置挂载
- name: config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
volumes:
- name: config
persistentVolumeClaim:
claimName: test-nfs-claim
你可以在 nginx 容器上执行两个卷挂载:
/usr/share/nginx/html 用于静态网站/etc/nginx/nginx.conf 作为默认配置使用组 ID(GID)配置的存储仅允许 Pod 使用相同的 GID 进行写入。 GID 不匹配或缺失将会导致无权访问错误。 为了减少与用户的协调,管理员可以对 PersistentVolume 添加 GID 注解。 这样 GID 就能自动添加到使用 PersistentVolume 的任何 Pod 中。
使用 pv.beta.kubernetes.io/gid 注解的方法如下所示:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
annotations:
pv.beta.kubernetes.io/gid: "1234"
当 Pod 使用带有 GID 注解的 PersistentVolume 时,注解的 GID 会被应用于 Pod 中的所有容器, 应用的方法与 Pod 的安全上下文中指定的 GID 相同。 每个 GID,无论是来自 PersistentVolume 注解还是来自 Pod 规约,都会被应用于每个容器中运行的第一个进程。
当 Pod 使用 PersistentVolume 时,与 PersistentVolume 关联的 GID 不会在 Pod 资源本身的对象上出现。
本文介绍怎样通过 projected 卷将现有的多个卷资源挂载到相同的目录。
当前,secret、configMap、downwardAPI 和 serviceAccountToken 卷可以被投射。
serviceAccountToken 不是一种卷类型。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
本练习中,你将使用本地文件来创建用户名和密码 Secret,
然后创建运行一个容器的 Pod,
该 Pod 使用projected 卷将 Secret 挂载到相同的路径下。
下面是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-projected-volume
image: busybox:1.28
args:
- sleep
- "86400"
volumeMounts:
- name: all-in-one
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: all-in-one
projected:
sources:
- secret:
name: user
- secret:
name: pass
创建 Secret:
# 创建包含用户名和密码的文件:
echo -n "admin" > ./username.txt
echo -n "1f2d1e2e67df" > ./password.txt
# 在 Secret 中引用上述文件
kubectl create secret generic user --from-file=./username.txt
kubectl create secret generic pass --from-file=./password.txt
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/storage/projected.yaml
确认 Pod 中的容器运行正常,然后监视 Pod 的变化:
kubectl get --watch pod test-projected-volume
输出结果和下面类似:
NAME READY STATUS RESTARTS AGE
test-projected-volume 1/1 Running 0 14s
在另外一个终端中,打开容器的 shell:
kubectl exec -it test-projected-volume -- /bin/sh
在 shell 中,确认 projected-volume 目录包含你的投射源:
ls /projected-volume/
删除 Pod 和 Secret:
kubectl delete pod test-projected-volume
kubectl delete secret user pass
安全上下文(Security Context)定义 Pod 或 Container 的特权与访问控制设置。 安全上下文包括但不限于:
自主访问控制(Discretionary Access Control): 基于用户 ID(UID)和组 ID(GID) 来判定对对象(例如文件)的访问权限。
安全性增强的 Linux(SELinux): 为对象赋予安全性标签。
以特权模式或者非特权模式运行。
Linux 权能: 为进程赋予 root 用户的部分特权而非全部特权。
AppArmor:使用程序配置来限制个别程序的权能。
Seccomp:过滤进程的系统调用。
allowPrivilegeEscalation:控制进程是否可以获得超出其父进程的特权。
此布尔值直接控制是否为容器进程设置
no_new_privs标志。
当容器满足一下条件之一时,allowPrivilegeEscalation 总是为 true:
CAP_SYS_ADMIN 权能readOnlyRootFilesystem:以只读方式加载容器的根文件系统。
以上条目不是安全上下文设置的完整列表 -- 请参阅 SecurityContext 了解其完整列表。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
要为 Pod 设置安全性设置,可在 Pod 规约中包含 securityContext 字段。securityContext 字段值是一个
PodSecurityContext
对象。你为 Pod 所设置的安全性配置会应用到 Pod 中所有 Container 上。
下面是一个 Pod 的配置文件,该 Pod 定义了 securityContext 和一个 emptyDir 卷:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: busybox:1.28
command: [ "sh", "-c", "sleep 1h" ]
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: false
在配置文件中,runAsUser 字段指定 Pod 中的所有容器内的进程都使用用户 ID 1000
来运行。runAsGroup 字段指定所有容器中的进程都以主组 ID 3000 来运行。
如果忽略此字段,则容器的主组 ID 将是 root(0)。
当 runAsGroup 被设置时,所有创建的文件也会划归用户 1000 和组 3000。
由于 fsGroup 被设置,容器中所有进程也会是附组 ID 2000 的一部分。
卷 /data/demo 及在该卷中创建的任何文件的属主都会是组 ID 2000。
创建该 Pod:
kubectl apply -f https://k8s.io/examples/pods/security/security-context.yaml
检查 Pod 的容器处于运行状态:
kubectl get pod security-context-demo
开启一个 Shell 进入到运行中的容器:
kubectl exec -it security-context-demo -- sh
在你的 Shell 中,列举运行中的进程:
ps
输出显示进程以用户 1000 运行,即 runAsUser 所设置的值:
PID USER TIME COMMAND
1 1000 0:00 sleep 1h
6 1000 0:00 sh
...
在你的 Shell 中,进入 /data 目录列举其内容:
cd /data
ls -l
输出显示 /data/demo 目录的组 ID 为 2000,即 fsGroup 的设置值:
drwxrwsrwx 2 root 2000 4096 Jun 6 20:08 demo
在你的 Shell 中,进入到 /data/demo 目录下创建一个文件:
cd demo
echo hello > testfile
列举 /data/demo 目录下的文件:
ls -l
输出显示 testfile 的组 ID 为 2000,也就是 fsGroup 所设置的值:
-rw-r--r-- 1 1000 2000 6 Jun 6 20:08 testfile
运行下面的命令:
id
输出类似于:
uid=1000 gid=3000 groups=2000
从输出中你会看到 gid 值为 3000,也就是 runAsGroup 字段的值。
如果 runAsGroup 被忽略,则 gid 会取值 0(root),而进程就能够与 root
用户组所拥有以及要求 root 用户组访问权限的文件交互。
退出你的 Shell:
exit
Kubernetes v1.23 [stable]
默认情况下,Kubernetes 在挂载一个卷时,会递归地更改每个卷中的内容的属主和访问权限,
使之与 Pod 的 securityContext 中指定的 fsGroup 匹配。
对于较大的数据卷,检查和变更属主与访问权限可能会花费很长时间,降低 Pod 启动速度。
你可以在 securityContext 中使用 fsGroupChangePolicy 字段来控制 Kubernetes
检查和管理卷属主和访问权限的方式。
fsGroupChangePolicy - fsGroupChangePolicy 定义在卷被暴露给 Pod 内部之前对其
内容的属主和访问许可进行变更的行为。此字段仅适用于那些支持使用 fsGroup 来
控制属主与访问权限的卷类型。此字段的取值可以是:
OnRootMismatch:只有根目录的属主与访问权限与卷所期望的权限不一致时,
才改变其中内容的属主和访问权限。这一设置有助于缩短更改卷的属主与访问
权限所需要的时间。Always:在挂载卷时总是更改卷中内容的属主和访问权限。例如:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
fsGroupChangePolicy: "OnRootMismatch"
Kubernetes v1.26 [stable]
如果你部署了一个容器存储接口 (CSI)
驱动,而该驱动支持 VOLUME_MOUNT_GROUP NodeServiceCapability,
在 securityContext 中指定 fsGroup 来设置文件所有权和权限的过程将由 CSI
驱动而不是 Kubernetes 来执行。在这种情况下,由于 Kubernetes 不执行任何所有权和权限更改,
fsGroupChangePolicy 不会生效,并且按照 CSI 的规定,CSI 驱动应该使用所指定的
fsGroup 来挂载卷,从而生成了一个对 fsGroup 可读/可写的卷.
若要为 Container 设置安全性配置,可以在 Container 清单中包含 securityContext
字段。securityContext 字段的取值是一个
SecurityContext
对象。你为 Container 设置的安全性配置仅适用于该容器本身,并且所指定的设置在与
Pod 层面设置的内容发生重叠时,会重写 Pod 层面的设置。Container 层面的设置不会影响到 Pod 的卷。
下面是一个 Pod 的配置文件,其中包含一个 Container。Pod 和 Container 都有
securityContext 字段:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo-2
spec:
securityContext:
runAsUser: 1000
containers:
- name: sec-ctx-demo-2
image: gcr.io/google-samples/node-hello:1.0
securityContext:
runAsUser: 2000
allowPrivilegeEscalation: false
创建该 Pod:
kubectl apply -f https://k8s.io/examples/pods/security/security-context-2.yaml
验证 Pod 中的容器处于运行状态:
kubectl get pod security-context-demo-2
启动一个 Shell 进入到运行中的容器内:
kubectl exec -it security-context-demo-2 -- sh
在你的 Shell 中,列举运行中的进程:
ps aux
输出显示进程以用户 2000 运行。该值是在 Container 的 runAsUser 中设置的。
该设置值重写了 Pod 层面所设置的值 1000。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
2000 1 0.0 0.0 4336 764 ? Ss 20:36 0:00 /bin/sh -c node server.js
2000 8 0.1 0.5 772124 22604 ? Sl 20:36 0:00 node server.js
...
退出你的 Shell:
exit
使用 Linux 权能,
你可以赋予进程 root 用户所拥有的某些特权,但不必赋予其全部特权。
要为 Container 添加或移除 Linux 权能,可以在 Container 清单的 securityContext
节包含 capabilities 字段。
首先,看一下不包含 capabilities 字段时候会发生什么。
下面是一个配置文件,其中没有添加或移除容器的权能:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo-3
spec:
containers:
- name: sec-ctx-3
image: gcr.io/google-samples/node-hello:1.0
创建该 Pod:
kubectl apply -f https://k8s.io/examples/pods/security/security-context-3.yaml
验证 Pod 的容器处于运行状态:
kubectl get pod security-context-demo-3
启动一个 Shell 进入到运行中的容器:
kubectl exec -it security-context-demo-3 -- sh
在你的 Shell 中,列举运行中的进程:
ps aux
输出显示容器中进程 ID(PIDs):
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 4336 796 ? Ss 18:17 0:00 /bin/sh -c node server.js
root 5 0.1 0.5 772124 22700 ? Sl 18:17 0:00 node server.js
在你的 Shell 中,查看进程 1 的状态:
cd /proc/1
cat status
输出显示进程的权能位图:
...
CapPrm: 00000000a80425fb
CapEff: 00000000a80425fb
...
记下进程权能位图,之后退出你的 Shell:
exit
接下来运行一个与前例中容器相同的容器,只是这个容器有一些额外的权能设置。
下面是一个 Pod 的配置,其中运行一个容器。配置为容器添加 CAP_NET_ADMIN 和
CAP_SYS_TIME 权能:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo-4
spec:
containers:
- name: sec-ctx-4
image: gcr.io/google-samples/node-hello:1.0
securityContext:
capabilities:
add: ["NET_ADMIN", "SYS_TIME"]
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/security/security-context-4.yaml
启动一个 Shell,进入到运行中的容器:
kubectl exec -it security-context-demo-4 -- sh
在你的 Shell 中,查看进程 1 的权能:
cd /proc/1
cat status
输出显示的是进程的权能位图:
...
CapPrm: 00000000aa0435fb
CapEff: 00000000aa0435fb
...
比较两个容器的权能位图:
00000000a80425fb
00000000aa0435fb
在第一个容器的权能位图中,位 12 和 25 是没有设置的。在第二个容器中,位 12
和 25 是设置了的。位 12 是 CAP_NET_ADMIN 而位 25 则是 CAP_SYS_TIME。
参见 capability.h
了解权能常数的定义。
CAP_XXX。但是你在 container 清单中列举权能时,
要将权能名称中的 CAP_ 部分去掉。例如,要添加 CAP_SYS_TIME,
可在权能列表中添加 SYS_TIME。
若要为容器设置 Seccomp 配置(Profile),可在你的 Pod 或 Container 清单的
securityContext 节中包含 seccompProfile 字段。该字段是一个
SeccompProfile
对象,包含 type 和 localhostProfile 属性。
type 的合法选项包括 RuntimeDefault、Unconfined 和 Localhost。
localhostProfile 只能在 type: Localhost 配置下才可以设置。
该字段标明节点上预先设定的配置的路径,路径是相对于 kubelet 所配置的
Seccomp 配置路径(使用 --root-dir 设置)而言的。
下面是一个例子,设置容器使用节点上容器运行时的默认配置作为 Seccomp 配置:
...
securityContext:
seccompProfile:
type: RuntimeDefault
下面是另一个例子,将 Seccomp 的样板设置为位于
<kubelet-根目录>/seccomp/my-profiles/profile-allow.json
的一个预先配置的文件。
...
securityContext:
seccompProfile:
type: Localhost
localhostProfile: my-profiles/profile-allow.json
若要给 Container 设置 SELinux 标签,可以在 Pod 或 Container 清单的
securityContext 节包含 seLinuxOptions 字段。
seLinuxOptions 字段的取值是一个
SELinuxOptions
对象。下面是一个应用 SELinux 标签的例子:
...
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
Kubernetes v1.27 [beta]
默认情况下,容器运行时递归地将 SELinux 标签赋予所有 Pod 卷上的所有文件。
为了加快该过程,Kubernetes 使用挂载可选项 -o context=<label> 可以立即改变卷的 SELinux 标签。
要使用这项加速功能,必须满足下列条件:
ReadWriteOncePod 和 SELinuxMountReadWriteOncePod
特性门控。accessModes: ["ReadWriteOncePod"] 模式使用 PersistentVolumeClaim。seLinuxOptions。iscsi、rbd 或 fs 卷类型的卷。spec.seLinuxMount: true
以支持 -o context 挂载。对于所有其他卷类型,重打 SELinux 标签的方式有所不同: 容器运行时为卷中的所有节点(文件和目录)递归地修改 SELinux 标签。 卷中的文件和目录越多,重打标签需要耗费的时间就越长。
如果你的 Kubernetes 版本是 v1.25,请参阅此任务页面的 v1.25 版本: 为 Pod 或 Container 配置安全上下文(v1.25)。 该文档中有一个重要的说明:kubelet 在重启后会丢失对卷标签的追踪记录。 这个缺陷已经在 Kubernetes 1.26 中修复。
Pod 的安全上下文适用于 Pod 中的容器,也适用于 Pod 所挂载的卷(如果有的话)。
尤其是,fsGroup 和 seLinuxOptions 按下面的方式应用到挂载卷上:
fsGroup:支持属主管理的卷会被修改,将其属主变更为 fsGroup 所指定的 GID,
并且对该 GID 可写。进一步的细节可参阅
属主变更设计文档。
seLinuxOptions:支持 SELinux 标签的卷会被重新打标签,以便可被 seLinuxOptions
下所设置的标签访问。通常你只需要设置 level 部分。
该部分设置的是赋予 Pod 中所有容器及卷的
多类别安全性(Multi-Category Security,MCS)标签。
删除之前创建的所有 Pod:
kubectl delete pod security-context-demo
kubectl delete pod security-context-demo-2
kubectl delete pod security-context-demo-3
kubectl delete pod security-context-demo-4
Kubernetes 提供两种完全不同的方式来为客户端提供支持,这些客户端可能运行在你的集群中, 也可能与你的集群的控制面相关, 需要向 API 服务器完成身份认证。
服务账号(Service Account) 为 Pod 中运行的进程提供身份标识, 并映射到 ServiceAccount 对象。当你向 API 服务器执行身份认证时, 你会将自己标识为某个用户(User)。Kubernetes 能够识别用户的概念, 但是 Kubernetes 自身并不提供 User API。
本服务是关于 ServiceAccount 的,而 ServiceAccount 则确实存在于 Kubernetes 的 API 中。 本指南为你展示为 Pod 配置 ServiceAccount 的一些方法。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
当 Pod 与 API 服务器联系时,Pod 会被认证为某个特定的 ServiceAccount(例如:default)。
在每个名字空间中,至少存在一个
ServiceAccount。
每个 Kubernetes 名字空间至少包含一个 ServiceAccount:也就是该名字空间的默认服务账号,
名为 default。如果你在创建 Pod 时没有指定 ServiceAccount,Kubernetes 会自动将该名字空间中名为
default 的 ServiceAccount 分配给该 Pod。
你可以检视你刚刚创建的 Pod 的细节。例如:
kubectl get pods/<podname> -o yaml
在输出中,你可以看到字段 spec.serviceAccountName。当你在创建 Pod 时未设置该字段时,
Kubernetes 自动为 Pod 设置这一属性的取值。
Pod 中运行的应用可以使用这一自动挂载的服务账号凭据来访问 Kubernetes API。 参阅访问集群以进一步了解。
当 Pod 被身份认证为某个 ServiceAccount 时, 其访问能力取决于所使用的鉴权插件和策略。
如果你不希望 kubelet 自动挂载某
ServiceAccount 的 API 访问凭据,你可以选择不采用这一默认行为。
通过在 ServiceAccount 对象上设置 automountServiceAccountToken: false,可以放弃在
/var/run/secrets/kubernetes.io/serviceaccount/token 处自动挂载该服务账号的 API 凭据。
例如:
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-robot
automountServiceAccountToken: false
...
你也可以选择不给特定 Pod 自动挂载 API 凭据:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
serviceAccountName: build-robot
automountServiceAccountToken: false
...
如果 ServiceAccount 和 Pod 的 .spec 都设置了 automountServiceAccountToken 值,
则 Pod 上 spec 的设置优先于服务账号的设置。
每个名字空间都至少有一个 ServiceAccount:名为 default 的默认 ServiceAccount 资源。
你可以用下面的命令列举你当前名字空间
中的所有 ServiceAccount 资源:
kubectl get serviceaccounts
输出类似于:
NAME SECRETS AGE
default 1 1d
你可以像这样来创建额外的 ServiceAccount 对象:
kubectl apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-robot
EOF
ServiceAccount 对象的名字必须是一个有效的 DNS 子域名。
如果你查询服务账号对象的完整信息,如下所示:
kubectl get serviceaccounts/build-robot -o yaml
输出类似于:
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2019-06-16T00:12:34Z
name: build-robot
namespace: default
resourceVersion: "272500"
uid: 721ab723-13bc-11e5-aec2-42010af0021e
你可以使用鉴权插件来设置服务账号的访问许可。
要使用非默认的服务账号,将 Pod 的 spec.serviceAccountName 字段设置为你想用的服务账号名称。
只能在创建 Pod 时或者为新 Pod 指定模板时,你才可以设置 serviceAccountName。
你不能更新已经存在的 Pod 的 .spec.serviceAccountName 字段。
.spec.serviceAccount 字段是 .spec.serviceAccountName 的已弃用别名。
如果要从工作负载资源中删除这些字段,请在
Pod 模板上将这两个字段显式设置为空。
如果你尝试了创建前文示例中所给的 build-robot ServiceAccount,
你可以通过运行下面的命令来完成清理操作:
kubectl delete serviceaccount/build-robot
假设你已经有了一个前文所提到的名为 "build-robot" 的服务账号。
你可以使用 kubectl 为该 ServiceAccount 获得一个有时限的 API 令牌:
kubectl create token build-robot
这一命令的输出是一个令牌,你可以使用该令牌来将身份认证为对应的 ServiceAccount。
你可以使用 kubectl create token 命令的 --duration 参数来请求特定的令牌有效期
(实际签发的令牌的有效期可能会稍短一些,也可能会稍长一些)。
当启用了 ServiceAccountTokenNodeBinding 和 ServiceAccountTokenNodeBindingValidation
特性,并将 KUBECTL_NODE_BOUND_TOKENS 环境变量设置为 true 时,
可以创建一个直接绑定到 Node 的服务账号令牌:
KUBECTL_NODE_BOUND_TOKENS=true kubectl create token build-robot --bound-object-kind Node --bound-object-name node-001 --bound-object-uid 123...456
此令牌将有效直至其过期或关联的 Node 或服务账户被删除。
Kubernetes 在 v1.22 版本之前自动创建用来访问 Kubernetes API 的长期凭据。 这一较老的机制是基于创建令牌 Secret 对象来实现的,Secret 对象可被挂载到运行中的 Pod 内。 在最近的版本中,包括 Kubernetes v1.29,API 凭据可以直接使用 TokenRequest API 来获得,并使用一个投射卷挂载到 Pod 中。使用此方法获得的令牌具有受限的生命期长度,并且能够在挂载它们的 Pod 被删除时自动被废弃。
你仍然可以通过手动方式来创建服务账号令牌 Secret 对象,例如你需要一个永远不过期的令牌时。 不过,使用 TokenRequest 子资源来获得访问 API 的令牌的做法仍然是推荐的方式。
如果你需要为 ServiceAccount 获得一个 API 令牌,你可以创建一个新的、带有特殊注解
kubernetes.io/service-account.name 的 Secret 对象。
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: build-robot-secret
annotations:
kubernetes.io/service-account.name: build-robot
type: kubernetes.io/service-account-token
EOF
如果你通过下面的命令来查看 Secret:
kubectl get secret/build-robot-secret -o yaml
你可以看到 Secret 中现在包含针对 "build-robot" ServiceAccount 的 API 令牌。
鉴于你所设置的注解,控制面会自动为该 ServiceAccount 生成一个令牌,并将其保存到相关的 Secret 中。控制面也会为已删除的 ServiceAccount 执行令牌清理操作。
kubectl describe secrets/build-robot-secret
输出类似于这样:
Name: build-robot-secret
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: build-robot
kubernetes.io/service-account.uid: da68f9c6-9d26-11e7-b84e-002dc52800da
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1338 bytes
namespace: 7 bytes
token: ...
这里将 token 的内容抹去了。
注意在你的终端或者计算机屏幕可能被旁观者看到的场合,不要显示
kubernetes.io/service-account-token 的内容。
当你删除一个与某 Secret 相关联的 ServiceAccount 时,Kubernetes 的控制面会自动清理该 Secret 中长期有效的令牌。
如果你使用以下命令查看 ServiceAccount:
kubectl get serviceaccount build-robot -o yaml
在 ServiceAccount API 对象中看不到 build-robot-secret Secret,
.secrets 字段,
因为该字段只会填充自动生成的 Secret。
首先,生成一个 imagePullSecret; 接下来,验证该 Secret 已被创建。例如:
按为 Pod 设置 imagePullSecret 所描述的,生成一个镜像拉取 Secret:
kubectl create secret docker-registry myregistrykey --docker-server=<registry name> \
--docker-username=DUMMY_USERNAME --docker-password=DUMMY_DOCKER_PASSWORD \
--docker-email=DUMMY_DOCKER_EMAIL
检查该 Secret 已经被创建。
kubectl get secrets myregistrykey
输出类似于这样:
NAME TYPE DATA AGE
myregistrykey kubernetes.io/.dockerconfigjson 1 1d
接下来更改名字空间的默认服务账号,将该 Secret 用作 imagePullSecret。
kubectl patch serviceaccount default -p '{"imagePullSecrets": [{"name": "myregistrykey"}]}'
你也可以通过手动编辑该对象来实现同样的效果:
kubectl edit serviceaccount/default
sa.yaml 文件的输出类似于:
你所选择的文本编辑器会被打开,展示如下所示的配置:
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2021-07-07T22:02:39Z
name: default
namespace: default
resourceVersion: "243024"
uid: 052fb0f4-3d50-11e5-b066-42010af0d7b6
使用你的编辑器,删掉包含 resourceVersion 主键的行,添加包含 imagePullSecrets:
的行并保存文件。对于 uid 而言,保持其取值与你读到的值一样。
当你完成这些变更之后,所编辑的 ServiceAccount 看起来像是这样:
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: 2021-07-07T22:02:39Z
name: default
namespace: default
uid: 052fb0f4-3d50-11e5-b066-42010af0d7b6
imagePullSecrets:
- name: myregistrykey
现在,在当前名字空间中创建新 Pod 并使用默认 ServiceAccount 时,
新 Pod 的 spec.imagePullSecrets 会被自动设置。
kubectl run nginx --image=<registry name>/nginx --restart=Never
kubectl get pod nginx -o=jsonpath='{.spec.imagePullSecrets[0].name}{"\n"}'
输出为:
myregistrykey
Kubernetes v1.20 [stable]
为了启用令牌请求投射,你必须为 kube-apiserver 设置以下命令行参数:
--service-account-issuer--service-account-issuer 参数,对于需要变更发放者而又不想带来业务中断的场景,
这样做是有用的。如果这个参数被多次指定,其第一个参数值会被用来生成令牌,
而所有参数值都会被用来确定哪些发放者是可接受的。你所运行的 Kubernetes
集群必须是 v1.22 或更高版本才能多次指定 --service-account-issuer。--service-account-key-file--service-account-signing-key-file--api-audiences(可以省略)api-audiences 被多次指定,则针对所给的多个受众中任何目标的令牌都会被
Kubernetes API 服务器当做合法的令牌。如果你指定了 --service-account-issuer
参数,但沒有設置 --api-audiences,则控制面认为此参数的默认值为一个只有一个元素的列表,
且该元素为令牌发放者的 URL。kubelet 还可以将 ServiceAccount 令牌投射到 Pod 中。你可以指定令牌的期望属性, 例如受众和有效期限。这些属性在 default ServiceAccount 令牌上无法配置。 当 Pod 或 ServiceAccount 被删除时,该令牌也将对 API 无效。
你可以使用类型为 ServiceAccountToken 的投射卷来为
Pod 的 spec 配置此行为。
来自此投射卷的令牌是一个 JSON Web Token (JWT)。 此令牌的 JSON 载荷遵循明确定义的模式,绑定到 Pod 的令牌的示例载荷如下:
{
"aud": [ # 匹配请求的受众,或当没有明确请求时匹配 API 服务器的默认受众
"https://kubernetes.default.svc"
],
"exp": 1731613413,
"iat": 1700077413,
"iss": "https://kubernetes.default.svc", # 匹配传递到 --service-account-issuer 标志的第一个值
"jti": "ea28ed49-2e11-4280-9ec5-bc3d1d84661a", # ServiceAccountTokenJTI 特性必须被启用才能出现此申领
"kubernetes.io": {
"namespace": "kube-system",
"node": { # ServiceAccountTokenPodNodeInfo 特性必须被启用,API 服务器才会添加此节点引用申领
"name": "127.0.0.1",
"uid": "58456cb0-dd00-45ed-b797-5578fdceaced"
},
"pod": {
"name": "coredns-69cbfb9798-jv9gn",
"uid": "778a530c-b3f4-47c0-9cd5-ab018fb64f33"
},
"serviceaccount": {
"name": "coredns",
"uid": "a087d5a0-e1dd-43ec-93ac-f13d89cd13af"
},
"warnafter": 1700081020
},
"nbf": 1700077413,
"sub": "system:serviceaccount:kube-system:coredns"
}
要为某 Pod 提供一个受众为 vault 并且有效期限为 2 小时的令牌,你可以定义一个与下面类似的
Pod 清单:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
volumeMounts:
- mountPath: /var/run/secrets/tokens
name: vault-token
serviceAccountName: build-robot
volumes:
- name: vault-token
projected:
sources:
- serviceAccountToken:
path: vault-token
expirationSeconds: 7200
audience: vault
创建此 Pod:
kubectl create -f https://k8s.io/examples/pods/pod-projected-svc-token.yaml
kubelet 组件会替 Pod 请求令牌并将其保存起来;通过将令牌存储到一个可配置的路径以使之在 Pod 内可用;在令牌快要到期的时候刷新它。kubelet 会在令牌存在期达到其 TTL 的 80% 的时候或者令牌生命期超过 24 小时的时候主动请求将其轮换掉。
应用负责在令牌被轮换时重新加载其内容。通常而言,周期性地(例如,每隔 5 分钟) 重新加载就足够了,不必跟踪令牌的实际过期时间。
Kubernetes v1.21 [stable]
如果你在你的集群中已经为 ServiceAccount 启用了令牌投射, 那么你也可以利用其发现能力。Kubernetes 提供一种方式来让客户端将一个或多个外部系统进行联邦, 作为标识提供者(Identity Provider),而这些外部系统的角色是依赖方(Relying Party)。
分发者的 URL 必须遵从
OIDC 发现规范。
实现上,这意味着 URL 必须使用 https 模式,并且必须在路径
{service-account-issuer}/.well-known/openid-configuration
处给出 OpenID 提供者(Provider)的配置信息。
如果 URL 没有遵从这一规范,ServiceAccount 分发者发现末端末端就不会被注册也无法访问。
当此特性被启用时,Kubernetes API 服务器会通过 HTTP 发布一个 OpenID 提供者配置文档。
该配置文档发布在 /.well-known/openid-configuration 路径。
这里的 OpenID 提供者配置(OpenID Provider Configuration)有时候也被称作
“发现文档(Discovery Document)”。
Kubernetes API 服务器也通过 HTTP 在 /openid/v1/jwks 处发布相关的
JSON Web Key Set(JWKS)。
对于在 /.well-known/openid-configuration 和 /openid/v1/jwks 上给出的响应而言,
其设计上是保证与 OIDC 兼容的,但并不严格遵从 OIDC 的规范。
响应中所包含的文档进包含对 Kubernetes 服务账号令牌进行校验所必需的参数。
使用 RBAC 的集群都包含一个的默认
RBAC ClusterRole, 名为 system:service-account-issuer-discovery。
默认的 RBAC ClusterRoleBinding 将此角色分配给 system:serviceaccounts 组,
所有 ServiceAccount 隐式属于该组。这使得集群上运行的 Pod
能够通过它们所挂载的服务账号令牌访问服务账号发现文档。
此外,管理员可以根据其安全性需要以及期望集成的外部系统,选择是否将该角色绑定到
system:authenticated 或 system:unauthenticated。
JWKS 响应包含依赖方可以用来验证 Kubernetes 服务账号令牌的公钥数据。
依赖方先会查询 OpenID 提供者配置,之后使用返回响应中的 jwks_uri 来查找 JWKS。
在很多场合,Kubernetes API 服务器都不会暴露在公网上,不过对于缓存并向外提供 API
服务器响应数据的公开末端而言,用户或者服务提供商可以选择将其暴露在公网上。
在这种环境中,可能会重载 OpenID 提供者配置中的
jwks_uri,使之指向公网上可用的末端地址,而不是 API 服务器的地址。
这时需要向 API 服务器传递 --service-account-jwks-uri 参数。
与分发者 URL 类似,此 JWKS URI 也需要使用 https 模式。
另请参见:
本文介绍如何使用 Secret 从私有的镜像仓库或代码仓库拉取镜像来创建 Pod。 有很多私有镜像仓库正在使用中。这个任务使用的镜像仓库是 Docker Hub。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
docker 命令行工具和一个知道密码的
Docker ID。在个人电脑上,要想拉取私有镜像必须在镜像仓库上进行身份验证。
使用 docker 命令工具来登录到 Docker Hub。
更多详细信息,请查阅
Docker ID accounts 中的 log in 部分。
docker login
当出现提示时,输入你的 Docker ID 和登录凭据(访问令牌或 Docker ID 的密码)。
登录过程会创建或更新保存有授权令牌的 config.json 文件。
查看 Kubernetes 如何解析这个文件。
查看 config.json 文件:
cat ~/.docker/config.json
输出结果包含类似于以下内容的部分:
{
"auths": {
"https://index.docker.io/v1/": {
"auth": "c3R...zE2"
}
}
}
如果使用 Docker 凭据仓库,则不会看到 auth 条目,看到的将是以仓库名称作为值的 credsStore 条目。
在这种情况下,你可以直接创建一个 Secret。
请参阅在命令行上提供凭据来创建 Secret。
Kubernetes 集群使用 kubernetes.io/dockerconfigjson 类型的
Secret 来通过镜像仓库的身份验证,进而提取私有镜像。
如果你已经运行了 docker login 命令,你可以复制该镜像仓库的凭据到 Kubernetes:
kubectl create secret generic regcred \
--from-file=.dockerconfigjson=<path/to/.docker/config.json> \
--type=kubernetes.io/dockerconfigjson
如果你需要更多的设置(例如,为新 Secret 设置名字空间或标签), 则可以在存储 Secret 之前对它进行自定义。 请务必:
.dockerconfigjsondata[".dockerconfigjson"] 的值type 设置为 kubernetes.io/dockerconfigjson示例:
apiVersion: v1
kind: Secret
metadata:
name: myregistrykey
namespace: awesomeapps
data:
.dockerconfigjson: UmVhbGx5IHJlYWxseSByZWVlZWVlZWVlZWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGx5eXl5eXl5eXl5eXl5eXl5eXl5eSBsbGxsbGxsbGxsbGxsbG9vb29vb29vb29vb29vb29vb29vb29vb29vb25ubm5ubm5ubm5ubm5ubm5ubm5ubm5ubmdnZ2dnZ2dnZ2dnZ2dnZ2dnZ2cgYXV0aCBrZXlzCg==
type: kubernetes.io/dockerconfigjson
如果你收到错误消息:error: no objects passed to create,
这可能意味着 base64 编码的字符串是无效的。如果你收到类似
Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ...
的错误消息,则表示数据中的 base64 编码字符串已成功解码,
但无法解析为 .docker/config.json 文件。
创建 Secret,命名为 regcred:
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
在这里:
<your-registry-server> 是你的私有 Docker 仓库全限定域名(FQDN)。
DockerHub 使用 https://index.docker.io/v1/。<your-name> 是你的 Docker 用户名。<your-pword> 是你的 Docker 密码。<your-email> 是你的 Docker 邮箱。这样你就成功地将集群中的 Docker 凭据设置为名为 regcred 的 Secret。
在命令行上键入 Secret 可能会将它们存储在你的 Shell 历史记录中而不受保护,
并且这些 Secret 信息也可能在 kubectl 运行期间对你 PC 上的其他用户可见。
regcred 要了解你创建的 regcred Secret 的内容,可以用 YAML 格式进行查看:
kubectl get secret regcred --output=yaml
输出和下面类似:
apiVersion: v1
kind: Secret
metadata:
...
name: regcred
...
data:
.dockerconfigjson: eyJodHRwczovL2luZGV4L ... J0QUl6RTIifX0=
type: kubernetes.io/dockerconfigjson
.dockerconfigjson 字段的值是 Docker 凭据的 base64 表示。
要了解 dockerconfigjson 字段中的内容,请将 Secret 数据转换为可读格式:
kubectl get secret regcred --output="jsonpath={.data.\.dockerconfigjson}" | base64 --decode
输出和下面类似:
{"auths":{"your.private.registry.example.com":{"username":"janedoe","password":"xxxxxxxxxxx","email":"jdoe@example.com","auth":"c3R...zE2"}}}
要了解 auth 字段中的内容,请将 base64 编码过的数据转换为可读格式:
echo "c3R...zE2" | base64 --decode
输出结果中,用户名和密码用 : 链接,类似下面这样:
janedoe:xxxxxxxxxxx
注意,Secret 数据包含与本地 ~/.docker/config.json 文件类似的授权令牌。
这样你就已经成功地将 Docker 凭据设置为集群中的名为 regcred 的 Secret。
下面是一个 Pod 配置清单示例,该示例中 Pod 需要访问你的 Docker 凭据 regcred:
apiVersion: v1
kind: Pod
metadata:
name: private-reg
spec:
containers:
- name: private-reg-container
image: <your-private-image>
imagePullSecrets:
- name: regcred
将上述文件下载到你的计算机中:
curl -L -o my-private-reg-pod.yaml https://k8s.io/examples/pods/private-reg-pod.yaml
在 my-private-reg-pod.yaml 文件中,使用私有仓库的镜像路径替换 <your-private-image>,例如:
your.private.registry.example.com/janedoe/jdoe-private:v1
要从私有仓库拉取镜像,Kubernetes 需要凭据。
配置文件中的 imagePullSecrets 字段表明 Kubernetes 应该通过名为 regcred 的 Secret 获取凭据。
创建使用了你的 Secret 的 Pod,并检查它是否正常运行:
kubectl apply -f my-private-reg-pod.yaml
kubectl get pod private-reg
要为 Pod(或 Deployment,或其他有 Pod 模板的对象)使用镜像拉取 Secret, 你需要确保合适的 Secret 确实存在于正确的名字空间中。 要使用的是你定义 Pod 时所用的名字空间。
此外,如果 Pod 启动失败,状态为 ImagePullBackOff,查看 Pod 事件:
kubectl describe pod private-reg
如果你看到一个原因设为 FailedToRetrieveImagePullSecret 的事件,
那么 Kubernetes 找不到指定名称(此例中为 regcred)的 Secret。
如果你指定 Pod 需要拉取镜像凭据,kubelet 在尝试拉取镜像之前会检查是否可以访问该 Secret。
确保你指定的 Secret 存在,并且其名称拼写正确。
Events:
... Reason ... Message
------ -------
... FailedToRetrieveImagePullSecret ... Unable to retrieve some image pull secrets (<regcred>); attempting to pull the image may not succeed.
imagePullSecrets 字段这篇文章介绍如何给容器配置存活(Liveness)、就绪(Readiness)和启动(Startup)探针。
kubelet 使用存活探针来确定什么时候要重启容器。 例如,存活探针可以探测到应用死锁(应用在运行,但是无法继续执行后面的步骤)情况。 重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。
存活探针的常见模式是为就绪探针使用相同的低成本 HTTP 端点,但具有更高的 failureThreshold。 这样可以确保在硬性终止 Pod 之前,将观察到 Pod 在一段时间内处于非就绪状态。
kubelet 使用就绪探针可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。
kubelet 使用启动探针来了解应用容器何时启动。 如果配置了这类探针,存活探针和就绪探针成功之前不会重启,确保这些探针不会影响应用的启动。 启动探针可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
存活探针是一种从应用故障中恢复的强劲方式,但应谨慎使用。 你必须仔细配置存活探针,确保它能真正标示出不可恢复的应用故障,例如死锁。
错误的存活探针可能会导致级联故障。 这会导致在高负载下容器重启;例如由于应用无法扩展,导致客户端请求失败;以及由于某些 Pod 失败而导致剩余 Pod 的工作负载增加。了解就绪探针和存活探针之间的区别, 以及何时为应用配置使用它们非常重要。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
许多长时间运行的应用最终会进入损坏状态,除非重新启动,否则无法被恢复。 Kubernetes 提供了存活探针来发现并处理这种情况。
在本练习中,你会创建一个 Pod,其中运行一个基于 registry.k8s.io/busybox 镜像的容器。
下面是这个 Pod 的配置文件。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
在这个配置文件中,可以看到 Pod 中只有一个 Container。
periodSeconds 字段指定了 kubelet 应该每 5 秒执行一次存活探测。
initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 5 秒。
kubelet 在容器内执行命令 cat /tmp/healthy 来进行探测。
如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。
如果这个命令返回非 0 值,kubelet 会杀死这个容器并重新启动它。
当容器启动时,执行如下的命令:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600"
这个容器生命的前 30 秒,/tmp/healthy 文件是存在的。
所以在这最开始的 30 秒内,执行命令 cat /tmp/healthy 会返回成功代码。
30 秒之后,执行命令 cat /tmp/healthy 就会返回失败代码。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
在 30 秒内,查看 Pod 的事件:
kubectl describe pod liveness-exec
输出结果表明还没有存活探针失败:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11s default-scheduler Successfully assigned default/liveness-exec to node01
Normal Pulling 9s kubelet, node01 Pulling image "registry.k8s.io/busybox"
Normal Pulled 7s kubelet, node01 Successfully pulled image "registry.k8s.io/busybox"
Normal Created 7s kubelet, node01 Created container liveness
Normal Started 7s kubelet, node01 Started container liveness
35 秒之后,再来看 Pod 的事件:
kubectl describe pod liveness-exec
在输出结果的最下面,有信息显示存活探针失败了,这个失败的容器被杀死并且被重建了。
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 57s default-scheduler Successfully assigned default/liveness-exec to node01
Normal Pulling 55s kubelet, node01 Pulling image "registry.k8s.io/busybox"
Normal Pulled 53s kubelet, node01 Successfully pulled image "registry.k8s.io/busybox"
Normal Created 53s kubelet, node01 Created container liveness
Normal Started 53s kubelet, node01 Started container liveness
Warning Unhealthy 10s (x3 over 20s) kubelet, node01 Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 10s kubelet, node01 Container liveness failed liveness probe, will be restarted
再等 30 秒,确认这个容器被重启了:
kubectl get pod liveness-exec
输出结果显示 RESTARTS 的值增加了 1。
请注意,一旦失败的容器恢复为运行状态,RESTARTS 计数器就会增加 1:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
另外一种类型的存活探测方式是使用 HTTP GET 请求。
下面是一个 Pod 的配置文件,其中运行一个基于 registry.k8s.io/liveness 镜像的容器。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
在这个配置文件中,你可以看到 Pod 也只有一个容器。
periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。
initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3 秒。
kubelet 会向容器内运行的服务(服务在监听 8080 端口)发送一个 HTTP GET 请求来执行探测。
如果服务器上 /healthz 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。
如果处理程序返回失败代码,则 kubelet 会杀死这个容器并将其重启。
返回大于或等于 200 并且小于 400 的任何代码都标示成功,其它返回代码都标示失败。
你可以访问 server.go
阅读服务的源码。
容器存活期间的最开始 10 秒中,/healthz 处理程序返回 200 的状态码。
之后处理程序返回 500 的状态码。
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
kubelet 在容器启动之后 3 秒开始执行健康检测。所以前几次健康检查都是成功的。 但是 10 秒之后,健康检查会失败,并且 kubelet 会杀死容器再重新启动容器。
创建一个 Pod 来测试 HTTP 的存活检测:
kubectl apply -f https://k8s.io/examples/pods/probe/http-liveness.yaml
10 秒之后,通过查看 Pod 事件来确认存活探针已经失败,并且容器被重新启动了。
kubectl describe pod liveness-http
在 1.13 之后的版本中,设置本地的 HTTP 代理环境变量不会影响 HTTP 的存活探测。
第三种类型的存活探测是使用 TCP 套接字。 使用这种配置时,kubelet 会尝试在指定端口和容器建立套接字链接。 如果能建立连接,这个容器就被看作是健康的,如果不能则这个容器就被看作是有问题的。
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
如你所见,TCP 检测的配置和 HTTP 检测非常相似。
下面这个例子同时使用就绪和存活探针。kubelet 会在容器启动 15 秒后发送第一个就绪探针。
探针会尝试连接 goproxy 容器的 8080 端口。
如果探测成功,这个 Pod 会被标记为就绪状态,kubelet 将继续每隔 10 秒运行一次探测。
除了就绪探针,这个配置包括了一个存活探针。
kubelet 会在容器启动 15 秒后进行第一次存活探测。
与就绪探针类似,存活探针会尝试连接 goproxy 容器的 8080 端口。
如果存活探测失败,容器会被重新启动。
kubectl apply -f https://k8s.io/examples/pods/probe/tcp-liveness-readiness.yaml
15 秒之后,通过看 Pod 事件来检测存活探针:
kubectl describe pod goproxy
Kubernetes v1.27 [stable]
如果你的应用实现了
gRPC 健康检查协议,
kubelet 可以配置为使用该协议来执行应用存活性检查。
你必须启用 GRPCContainerProbe
特性门控
才能配置依赖于 gRPC 的检查机制。
这个例子展示了如何配置 Kubernetes 以将其用于应用的存活性检查。 类似地,你可以配置就绪探针和启动探针。
下面是一个示例清单:
apiVersion: v1
kind: Pod
metadata:
name: etcd-with-grpc
spec:
containers:
- name: etcd
image: registry.k8s.io/etcd:3.5.1-0
command: [ "/usr/local/bin/etcd", "--data-dir", "/var/lib/etcd", "--listen-client-urls", "http://0.0.0.0:2379", "--advertise-client-urls", "http://127.0.0.1:2379", "--log-level", "debug"]
ports:
- containerPort: 2379
livenessProbe:
grpc:
port: 2379
initialDelaySeconds: 10
要使用 gRPC 探针,必须配置 port 属性。
如果要区分不同类型的探针和不同功能的探针,可以使用 service 字段。
你可以将 service 设置为 liveness,并使你的 gRPC
健康检查端点对该请求的响应与将 service 设置为 readiness 时不同。
这使你可以使用相同的端点进行不同类型的容器健康检查而不是监听两个不同的端口。
如果你想指定自己的自定义服务名称并指定探测类型,Kubernetes
项目建议你使用使用一个可以关联服务和探测类型的名称来命名。
例如:myservice-liveness(使用 - 作为分隔符)。
与 HTTP 和 TCP 探针不同,gRPC 探测不能使用按名称指定端口, 也不能自定义主机名。
配置问题(例如:错误的 port 或 service、未实现健康检查协议)
都被认作是探测失败,这一点与 HTTP 和 TCP 探针类似。
kubectl apply -f https://k8s.io/examples/pods/probe/grpc-liveness.yaml
15 秒钟之后,查看 Pod 事件确认存活性检查并未失败:
kubectl describe pod etcd-with-grpc
当使用 gRPC 探针时,需要注意以下一些技术细节:
-tls)。ExecProbeTimeout 特性门控被设置为 false,则 grpc-health-probe
不会考虑 timeoutSeconds 设置状态(默认值为 1s),
而内置探针则会在超时时返回失败。对于 HTTP 和 TCP 存活检测可以使用命名的
port(gRPC 探针不支持使用命名端口)。
例如:
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
有时候,会有一些现有的应用在启动时需要较长的初始化时间。
要这种情况下,若要不影响对死锁作出快速响应的探测,设置存活探测参数是要技巧的。
技巧就是使用相同的命令来设置启动探测,针对 HTTP 或 TCP 检测,可以通过将
failureThreshold * periodSeconds 参数设置为足够长的时间来应对最糟糕情况下的启动时间。
这样,前面的例子就变成了:
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10
幸亏有启动探测,应用将会有最多 5 分钟(30 * 10 = 300s)的时间来完成其启动过程。
一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁作出快速响应。
如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy
来执行进一步处置。
有时候,应用会暂时性地无法为请求提供服务。 例如,应用在启动时可能需要加载大量的数据或配置文件,或是启动后要依赖等待外部服务。 在这种情况下,既不想杀死应用,也不想给它发送请求。 Kubernetes 提供了就绪探针来发现并缓解这些情况。 容器所在 Pod 上报还未就绪的信息,并且不接受通过 Kubernetes Service 的流量。
就绪探针在容器的整个生命周期中保持运行状态。
存活探针与就绪性探针相互间不等待对方成功。
如果要在执行就绪性探针之前等待,应该使用 initialDelaySeconds 或 startupProbe。
就绪探针的配置和存活探针的配置相似。
唯一区别就是要使用 readinessProbe 字段,而不是 livenessProbe 字段。
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
HTTP 和 TCP 的就绪探针配置也和存活探针的配置完全相同。
就绪和存活探测可以在同一个容器上并行使用。 两者共同使用,可以确保流量不会发给还未就绪的容器,当这些探测失败时容器会被重新启动。
Probe 有很多配置字段,可以使用这些字段精确地控制启动、存活和就绪检测的行为:
initialDelaySeconds:容器启动后要等待多少秒后才启动启动、存活和就绪探针。
如果定义了启动探针,则存活探针和就绪探针的延迟将在启动探针已成功之后才开始计算。
如果 periodSeconds 的值大于 initialDelaySeconds,则 initialDelaySeconds
将被忽略。默认是 0 秒,最小值是 0。periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold:探针在失败后,被视为成功的最小连续成功数。默认值是 1。
存活和启动探测的这个值必须是 1。最小值是 1。failureThreshold:探针连续失败了 failureThreshold 次之后,
Kubernetes 认为总体上检查已失败:容器状态未就绪、不健康、不活跃。
对于启动探针或存活探针而言,如果至少有 failureThreshold 个探针已失败,
Kubernetes 会将容器视为不健康并为这个特定的容器触发重启操作。
kubelet 遵循该容器的 terminationGracePeriodSeconds 设置。
对于失败的就绪探针,kubelet 继续运行检查失败的容器,并继续运行更多探针;
因为检查失败,kubelet 将 Pod 的 Ready
状况设置为 false。terminationGracePeriodSeconds:为 kubelet
配置从为失败的容器触发终止操作到强制容器运行时停止该容器之前等待的宽限时长。
默认值是继承 Pod 级别的 terminationGracePeriodSeconds 值(如果不设置则为 30 秒),最小值为 1。
更多细节请参见探针级别 terminationGracePeriodSeconds。如果就绪态探针的实现不正确,可能会导致容器中进程的数量不断上升。 如果不对其采取措施,很可能导致资源枯竭的状况。
HTTP Probes
允许针对 httpGet 配置额外的字段:
host:连接使用的主机名,默认是 Pod 的 IP。也可以在 HTTP 头中设置 "Host" 来代替。scheme:用于设置连接主机的方式(HTTP 还是 HTTPS)。默认是 "HTTP"。path:访问 HTTP 服务的路径。默认值为 "/"。httpHeaders:请求中自定义的 HTTP 头。HTTP 头字段允许重复。port:访问容器的端口号或者端口名。如果数字必须在 1~65535 之间。对于 HTTP 探测,kubelet 发送一个 HTTP 请求到指定的端口和路径来执行检测。
除非 httpGet 中的 host 字段设置了,否则 kubelet 默认是给 Pod 的 IP 地址发送探测。
如果 scheme 字段设置为了 HTTPS,kubelet 会跳过证书验证发送 HTTPS 请求。
大多数情况下,不需要设置 host 字段。
这里有个需要设置 host 字段的场景,假设容器监听 127.0.0.1,并且 Pod 的 hostNetwork
字段设置为了 true。那么 httpGet 中的 host 字段应该设置为 127.0.0.1。
可能更常见的情况是如果 Pod 依赖虚拟主机,你不应该设置 host 字段,而是应该在
httpHeaders 中设置 Host。
针对 HTTP 探针,kubelet 除了必需的 Host 头部之外还发送两个请求头部字段:
User-Agent:默认值是 kube-probe/1.29,其中 1.29 是 kubelet 的版本号。Accept:默认值 */*。你可以通过为探测设置 httpHeaders 来重载默认的头部字段值。例如:
livenessProbe:
httpGet:
httpHeaders:
- name: Accept
value: application/json
startupProbe:
httpGet:
httpHeaders:
- name: User-Agent
value: MyUserAgent
你也可以通过将这些头部字段定义为空值,从请求中去掉这些头部字段。
livenessProbe:
httpGet:
httpHeaders:
- name: Accept
value: ""
startupProbe:
httpGet:
httpHeaders:
- name: User-Agent
value: ""
当 kubelet 使用 HTTP 探测 Pod 时,仅当重定向到同一主机时,它才会遵循重定向。 如果 kubelet 在探测期间收到 11 个或更多重定向,则认为探测成功并创建相关事件:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 29m default-scheduler Successfully assigned default/httpbin-7b8bc9cb85-bjzwn to daocloud
Normal Pulling 29m kubelet Pulling image "docker.io/kennethreitz/httpbin"
Normal Pulled 24m kubelet Successfully pulled image "docker.io/kennethreitz/httpbin" in 5m12.402735213s
Normal Created 24m kubelet Created container httpbin
Normal Started 24m kubelet Started container httpbin
Warning ProbeWarning 4m11s (x1197 over 24m) kubelet Readiness probe warning: Probe terminated redirects
如果 kubelet 收到主机名与请求不同的重定向,则探测结果将被视为成功,并且 kubelet 将创建一个事件来报告重定向失败。
对于 TCP 探测而言,kubelet 在节点上(不是在 Pod 里面)发起探测连接,
这意味着你不能在 host 参数上配置服务名称,因为 kubelet 不能解析服务名称。
terminationGracePeriodSecondsKubernetes v1.28 [stable]
在 1.25 及以上版本中,用户可以指定一个探针层面的 terminationGracePeriodSeconds
作为探针规约的一部分。
当 Pod 层面和探针层面的 terminationGracePeriodSeconds
都已设置,kubelet 将使用探针层面设置的值。
当设置 terminationGracePeriodSeconds 时,请注意以下事项:
terminationGracePeriodSeconds 字段
(如果它存在于 Pod 上)。terminationGracePeriodSeconds
字段并且不再希望使用针对每个探针的终止宽限期,则必须删除现有的这类 Pod。例如:
spec:
terminationGracePeriodSeconds: 3600 # Pod 级别设置
containers:
- name: test
image: ...
ports:
- name: liveness-port
containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 60
# 重载 Pod 级别的 terminationGracePeriodSeconds
terminationGracePeriodSeconds: 60
探针层面的 terminationGracePeriodSeconds 不能用于就绪态探针。
这一设置将被 API 服务器拒绝。
你也可以阅读以下的 API 参考资料:
此页面显示如何将 Kubernetes Pod 指派给 Kubernetes 集群中的特定节点。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
列出你的集群中的节点, 包括这些节点上的标签:
kubectl get nodes --show-labels
输出类似如下:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
从你的节点中选择一个,为它添加标签:
kubectl label nodes <your-node-name> disktype=ssd
<your-node-name> 是你选择的节点的名称。
验证你选择的节点确实带有 disktype=ssd 标签:
kubectl get nodes --show-labels
输出类似如下:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
在前面的输出中,你可以看到 worker0 节点有 disktype=ssd 标签。
此 Pod 配置文件描述了一个拥有节点选择器 disktype: ssd 的 Pod。这表明该 Pod
将被调度到有 disktype=ssd 标签的节点。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
使用该配置文件创建一个 Pod,该 Pod 将被调度到你选择的节点上:
kubectl create -f https://k8s.io/examples/pods/pod-nginx.yaml
验证 Pod 确实运行在你选择的节点上:
kubectl get pods --output=wide
输出类似如下:
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
你也可以通过设置 nodeName 将某个 Pod 调度到特定的节点。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
nodeName: foo-node # 调度 Pod 到特定的节点
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
使用此配置文件来创建一个 Pod,该 Pod 将只能被调度到 foo-node 节点。
本页展示在 Kubernetes 集群中,如何使用节点亲和性把 Kubernetes Pod 分配到特定节点。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.10. 要获知版本信息,请输入kubectl version.
列出集群中的节点及其标签:
kubectl get nodes --show-labels
输出类似于此:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
选择一个节点,给它添加一个标签:
kubectl label nodes <your-node-name> disktype=ssd
其中 <your-node-name> 是你所选节点的名称。
验证你所选节点具有 disktype=ssd 标签:
kubectl get nodes --show-labels
输出类似于此:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
在前面的输出中,可以看到 worker0 节点有一个 disktype=ssd 标签。
下面清单描述了一个 Pod,它有一个节点亲和性配置 requiredDuringSchedulingIgnoredDuringExecution,disktype=ssd。
这意味着 pod 只会被调度到具有 disktype=ssd 标签的节点上。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
执行(Apply)此清单来创建一个调度到所选节点上的 Pod:
kubectl apply -f https://k8s.io/examples/pods/pod-nginx-required-affinity.yaml
验证 Pod 已经在所选节点上运行:
kubectl get pods --output=wide
输出类似于此:
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
本清单描述了一个 Pod,它有一个节点亲和性设置 preferredDuringSchedulingIgnoredDuringExecution,disktype: ssd。
这意味着 Pod 将首选具有 disktype=ssd 标签的节点。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
执行此清单创建一个会调度到所选节点上的 Pod:
kubectl apply -f https://k8s.io/examples/pods/pod-nginx-preferred-affinity.yaml
验证 Pod 是否在所选节点上运行:
kubectl get pods --output=wide
输出类似于此:
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
进一步了解节点亲和性。
本文介绍在应用容器运行前,怎样利用 Init 容器初始化 Pod。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
本例中你将创建一个包含一个应用容器和一个 Init 容器的 Pod。Init 容器在应用容器启动前运行完成。
下面是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: init-demo
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
# 这些容器在 Pod 初始化期间运行
initContainers:
- name: install
image: busybox:1.28
command:
- wget
- "-O"
- "/work-dir/index.html"
- http://info.cern.ch
volumeMounts:
- name: workdir
mountPath: "/work-dir"
dnsPolicy: Default
volumes:
- name: workdir
emptyDir: {}
配置文件中,你可以看到应用容器和 Init 容器共享了一个卷。
Init 容器将共享卷挂载到了 /work-dir 目录,应用容器将共享卷挂载到了 /usr/share/nginx/html 目录。
Init 容器执行完下面的命令就终止:
wget -O /work-dir/index.html http://info.cern.ch
请注意 Init 容器在 nginx 服务器的根目录写入 index.html。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/init-containers.yaml
检查 nginx 容器运行正常:
kubectl get pod init-demo
结果表明 nginx 容器运行正常:
NAME READY STATUS RESTARTS AGE
init-demo 1/1 Running 0 1m
通过 shell 进入 init-demo Pod 中的 nginx 容器:
kubectl exec -it init-demo -- /bin/bash
在 shell 中,发送个 GET 请求到 nginx 服务器:
root@nginx:~# apt-get update
root@nginx:~# apt-get install curl
root@nginx:~# curl localhost
结果表明 nginx 正在为 Init 容器编写的 web 页面服务:
<html><head></head><body><header>
<title>http://info.cern.ch</title>
</header>
<h1>http://info.cern.ch - home of the first website</h1>
...
<li><a href="http://info.cern.ch/hypertext/WWW/TheProject.html">Browse the first website</a></li>
...
这个页面将演示如何为容器的生命周期事件挂接处理函数。Kubernetes 支持 postStart 和 preStop 事件。 当一个容器启动后,Kubernetes 将立即发送 postStart 事件;在容器被终结之前, Kubernetes 将发送一个 preStop 事件。容器可以为每个事件指定一个处理程序。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
在本练习中,你将创建一个包含一个容器的 Pod,该容器为 postStart 和 preStop 事件提供对应的处理函数。
下面是对应 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
在上述配置文件中,你可以看到 postStart 命令在容器的 /usr/share 目录下写入文件 message。
命令 preStop 负责优雅地终止 nginx 服务。当因为失效而导致容器终止时,这一处理方式很有用。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/lifecycle-events.yaml
验证 Pod 中的容器已经运行:
kubectl get pod lifecycle-demo
使用 shell 连接到你的 Pod 里的容器:
kubectl exec -it lifecycle-demo -- /bin/bash
在 shell 中,验证 postStart 处理函数创建了 message 文件:
root@lifecycle-demo:/# cat /usr/share/message
命令行输出的是 postStart 处理函数所写入的文本:
Hello from the postStart handler
Kubernetes 在容器创建后立即发送 postStart 事件。 然而,postStart 处理函数的调用不保证早于容器的入口点(entrypoint) 的执行。postStart 处理函数与容器的代码是异步执行的,但 Kubernetes 的容器管理逻辑会一直阻塞等待 postStart 处理函数执行完毕。 只有 postStart 处理函数执行完毕,容器的状态才会变成 RUNNING。
Kubernetes 在容器结束前立即发送 preStop 事件。除非 Pod 宽限期限超时, Kubernetes 的容器管理逻辑会一直阻塞等待 preStop 处理函数执行完毕。 更多细节请参阅 Pod 的生命周期。
Kubernetes 只有在一个 Pod 或该 Pod 中的容器结束(Terminated) 的时候才会发送 preStop 事件, 这意味着在 Pod 完成(Completed) 时 preStop 的事件处理逻辑不会被触发。有关这个限制, 请参阅容器回调了解详情。
很多应用在其初始化或运行期间要依赖一些配置信息。 大多数时候,存在要调整配置参数所设置的数值的需求。 ConfigMap 是 Kubernetes 的一种机制,可让你将配置数据注入到应用的 Pod 内部。
ConfigMap 概念允许你将配置清单与镜像内容分离,以保持容器化的应用程序的可移植性。 例如,你可以下载并运行相同的容器镜像来启动容器, 用于本地开发、系统测试或运行实时终端用户工作负载。
本页提供了一系列使用示例,这些示例演示了如何创建 ConfigMap 以及配置 Pod 使用存储在 ConfigMap 中的数据。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你需要安装 wget 工具。如果你有不同的工具,例如 curl,而没有 wget,
则需要调整下载示例数据的步骤。
你可以使用 kubectl create configmap 或者在 kustomization.yaml 中的 ConfigMap
生成器来创建 ConfigMap。
kubectl create configmap 创建 ConfigMap 你可以使用 kubectl create configmap 命令基于目录、
文件或者字面值来创建
ConfigMap:
kubectl create configmap <映射名称> <数据源>
其中,<映射名称> 是为 ConfigMap 指定的名称,<数据源> 是要从中提取数据的目录、
文件或者字面值。ConfigMap 对象的名称必须是合法的
DNS 子域名。
在你基于文件来创建 ConfigMap 时,<数据源> 中的键名默认取自文件的基本名,
而对应的值则默认为文件的内容。
你可以使用 kubectl describe 或者
kubectl get 获取有关 ConfigMap 的信息。
你可以使用 kubectl create configmap 基于同一目录中的多个文件创建 ConfigMap。
当你基于目录来创建 ConfigMap 时,kubectl 识别目录下文件名可以作为合法键名的文件,
并将这些文件打包到新的 ConfigMap 中。普通文件之外的所有目录项都会被忽略
(例如:子目录、符号链接、设备、管道等等)。
用于创建 ConfigMap 的每个文件名必须由可接受的字符组成,即:字母(A 到 Z 和
a 到 z)、数字(0 到 9)、'-'、'_' 或 '.'。
如果在一个目录中使用 kubectl create configmap,而其中任一文件名包含不可接受的字符,
则 kubectl 命令可能会失败。
kubectl 命令在遇到不合法的文件名时不会打印错误。
创建本地目录:
mkdir -p configure-pod-container/configmap/
现在,下载示例的配置并创建 ConfigMap:
# 将示例文件下载到 `configure-pod-container/configmap/` 目录
wget https://kubernetes.io/examples/configmap/game.properties -O configure-pod-container/configmap/game.properties
wget https://kubernetes.io/examples/configmap/ui.properties -O configure-pod-container/configmap/ui.properties
# 创建 ConfigMap
kubectl create configmap game-config --from-file=configure-pod-container/configmap/
以上命令将 configure-pod-container/configmap 目录下的所有文件,也就是
game.properties 和 ui.properties 打包到 game-config ConfigMap
中。你可以使用下面的命令显示 ConfigMap 的详细信息:
kubectl describe configmaps game-config
输出类似以下内容:
Name: game-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
configure-pod-container/configmap/ 目录中的 game.properties 和 ui.properties
文件出现在 ConfigMap 的 data 部分。
kubectl get configmaps game-config -o yaml
输出类似以下内容:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2022-02-18T18:52:05Z
name: game-config
namespace: default
resourceVersion: "516"
uid: b4952dc3-d670-11e5-8cd0-68f728db1985
data:
game.properties: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
你可以使用 kubectl create configmap 基于单个文件或多个文件创建 ConfigMap。
例如:
kubectl create configmap game-config-2 --from-file=configure-pod-container/configmap/game.properties
将产生以下 ConfigMap:
kubectl describe configmaps game-config-2
输出类似以下内容:
Name: game-config-2
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
你可以多次使用 --from-file 参数,从多个数据源创建 ConfigMap。
kubectl create configmap game-config-2 --from-file=configure-pod-container/configmap/game.properties --from-file=configure-pod-container/configmap/ui.properties
你可以使用以下命令显示 game-config-2 ConfigMap 的详细信息:
kubectl describe configmaps game-config-2
输出类似以下内容:
Name: game-config-2
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
使用 --from-env-file 选项基于 env 文件创建 ConfigMap,例如:
# Env 文件包含环境变量列表。其中适用以下语法规则:
# 这些语法规则适用:
# Env 文件中的每一行必须为 VAR=VAL 格式。
# 以#开头的行(即注释)将被忽略。
# 空行将被忽略。
# 引号不会被特殊处理(即它们将成为 ConfigMap 值的一部分)。
# 将示例文件下载到 `configure-pod-container/configmap/` 目录
wget https://kubernetes.io/examples/configmap/game-env-file.properties -O configure-pod-container/configmap/game-env-file.properties
wget https://kubernetes.io/examples/configmap/ui-env-file.properties -O configure-pod-container/configmap/ui-env-file.properties
# Env 文件 `game-env-file.properties` 如下所示
cat configure-pod-container/configmap/game-env-file.properties
enemies=aliens
lives=3
allowed="true"
# 此注释和上方的空行将被忽略
kubectl create configmap game-config-env-file \
--from-env-file=configure-pod-container/configmap/game-env-file.properties
将产生以下 ConfigMap。查看 ConfigMap:
kubectl get configmap game-config-env-file -o yaml
输出类似以下内容:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2019-12-27T18:36:28Z
name: game-config-env-file
namespace: default
resourceVersion: "809965"
uid: d9d1ca5b-eb34-11e7-887b-42010a8002b8
data:
allowed: '"true"'
enemies: aliens
lives: "3"
从 Kubernetes 1.23 版本开始,kubectl 支持多次指定 --from-env-file 参数来从多个数据源创建
ConfigMap。
kubectl create configmap config-multi-env-files \
--from-env-file=configure-pod-container/configmap/game-env-file.properties \
--from-env-file=configure-pod-container/configmap/ui-env-file.properties
将产生以下 ConfigMap:
kubectl get configmap config-multi-env-files -o yaml
输出类似以下内容:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2019-12-27T18:38:34Z
name: config-multi-env-files
namespace: default
resourceVersion: "810136"
uid: 252c4572-eb35-11e7-887b-42010a8002b8
data:
allowed: '"true"'
color: purple
enemies: aliens
how: fairlyNice
lives: "3"
textmode: "true"
在使用 --from-file 参数时,你可以定义在 ConfigMap 的 data 部分出现键名,
而不是按默认行为使用文件名:
kubectl create configmap game-config-3 --from-file=<我的键名>=<文件路径>
<我的键名> 是你要在 ConfigMap 中使用的键名,<文件路径> 是你想要键所表示的数据源文件的位置。
例如:
kubectl create configmap game-config-3 --from-file=game-special-key=configure-pod-container/configmap/game.properties
将产生以下 ConfigMap:
kubectl get configmaps game-config-3 -o yaml
输出类似以下内容:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2022-02-18T18:54:22Z
name: game-config-3
namespace: default
resourceVersion: "530"
uid: 05f8da22-d671-11e5-8cd0-68f728db1985
data:
game-special-key: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
你可以将 kubectl create configmap 与 --from-literal 参数一起使用,
通过命令行定义文字值:
kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm
你可以传入多个键值对。命令行中提供的每对键值在 ConfigMap 的 data 部分中均表示为单独的条目。
kubectl get configmaps special-config -o yaml
输出类似以下内容:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2022-02-18T19:14:38Z
name: special-config
namespace: default
resourceVersion: "651"
uid: dadce046-d673-11e5-8cd0-68f728db1985
data:
special.how: very
special.type: charm
你还可以基于生成器(Generators)创建 ConfigMap,然后将其应用于集群的 API 服务器上创建对象。
生成器应在目录内的 kustomization.yaml 中指定。
例如,要基于 configure-pod-container/configmap/game.properties
文件生成一个 ConfigMap:
# 创建包含 ConfigMapGenerator 的 kustomization.yaml 文件
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-4
options:
labels:
game-config: config-4
files:
- configure-pod-container/configmap/game.properties
EOF
应用(Apply)kustomization 目录创建 ConfigMap 对象:
kubectl apply -k .
configmap/game-config-4-m9dm2f92bt created
你可以像这样检查 ConfigMap 已经被创建:
kubectl get configmap
NAME DATA AGE
game-config-4-m9dm2f92bt 1 37s
也可以这样:
kubectl describe configmaps/game-config-4-m9dm2f92bt
Name: game-config-4-m9dm2f92bt
Namespace: default
Labels: game-config=config-4
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","data":{"game.properties":"enemies=aliens\nlives=3\nenemies.cheat=true\nenemies.cheat.level=noGoodRotten\nsecret.code.p...
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
Events: <none>
请注意,生成的 ConfigMap 名称具有通过对内容进行散列而附加的后缀, 这样可以确保每次修改内容时都会生成新的 ConfigMap。
在 ConfigMap 生成器中,你可以定义一个非文件名的键名。
例如,从 configure-pod-container/configmap/game.properties 文件生成 ConfigMap,
但使用 game-special-key 作为键名:
# 创建包含 ConfigMapGenerator 的 kustomization.yaml 文件
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-5
options:
labels:
game-config: config-5
files:
- game-special-key=configure-pod-container/configmap/game.properties
EOF
应用 Kustomization 目录创建 ConfigMap 对象。
kubectl apply -k .
configmap/game-config-5-m67dt67794 created
此示例向你展示如何使用 Kustomize 和 kubectl,基于两个字面键/值对
special.type=charm 和 special.how=very 创建一个 ConfigMap。
为了实现这一点,你可以配置 ConfigMap 生成器。
创建(或替换)kustomization.yaml,使其具有以下内容。
---
# 基于字面创建 ConfigMap 的 kustomization.yaml 内容
configMapGenerator:
- name: special-config-2
literals:
- special.how=very
- special.type=charm
EOF
应用 Kustomization 目录创建 ConfigMap 对象。
kubectl apply -k .
configmap/special-config-2-c92b5mmcf2 created
在继续之前,清理你创建的一些 ConfigMap:
kubectl delete configmap special-config
kubectl delete configmap env-config
kubectl delete configmap -l 'game-config in (config-4,config-5)'
现在你已经学会了定义 ConfigMap,你可以继续下一节,学习如何将这些对象与 Pod 一起使用。
在 ConfigMap 中将环境变量定义为键值对:
kubectl create configmap special-config --from-literal=special.how=very
将 ConfigMap 中定义的 special.how 赋值给 Pod 规约中的 SPECIAL_LEVEL_KEY 环境变量。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
# 定义环境变量
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
# ConfigMap 包含你要赋给 SPECIAL_LEVEL_KEY 的值
name: special-config
# 指定与取值相关的键名
key: special.how
restartPolicy: Never
创建 Pod:
kubectl create -f https://kubernetes.io/examples/pods/pod-single-configmap-env-variable.yaml
现在,Pod 的输出包含环境变量 SPECIAL_LEVEL_KEY=very。
与前面的示例一样,首先创建 ConfigMap。 这是你将使用的清单:
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
---
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO
创建 ConfigMap:
kubectl create -f https://kubernetes.io/examples/configmap/configmaps.yaml
在 Pod 规约中定义环境变量。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: env-config
key: log_level
restartPolicy: Never
创建 Pod:
kubectl create -f https://kubernetes.io/examples/pods/pod-multiple-configmap-env-variable.yaml
现在,Pod 的输出包含环境变量 SPECIAL_LEVEL_KEY=very 和 LOG_LEVEL=INFO。
一旦你乐意继续前进,删除该 Pod:
kubectl delete pod dapi-test-pod --now
创建一个包含多个键值对的 ConfigMap。
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
SPECIAL_LEVEL: very
SPECIAL_TYPE: charm
创建 ConfigMap:
kubectl create -f https://kubernetes.io/examples/configmap/configmap-multikeys.yaml
使用 envFrom 将所有 ConfigMap 的数据定义为容器环境变量,ConfigMap
中的键成为 Pod 中的环境变量名称。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "env" ]
envFrom:
- configMapRef:
name: special-config
restartPolicy: Never
创建 Pod:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-envFrom.yaml
现在,Pod 的输出包含环境变量 SPECIAL_LEVEL=very 和 SPECIAL_TYPE=charm。
一旦你乐意继续前进,删除该 Pod:
kubectl delete pod dapi-test-pod --now
你可以使用 $(VAR_NAME) Kubernetes 替换语法在容器的 command 和 args
属性中使用 ConfigMap 定义的环境变量。
例如,以下 Pod 清单:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/echo", "$(SPECIAL_LEVEL_KEY) $(SPECIAL_TYPE_KEY)" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: SPECIAL_LEVEL
- name: SPECIAL_TYPE_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: SPECIAL_TYPE
restartPolicy: Never
通过运行下面命令创建该 Pod:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-env-var-valueFrom.yaml
此 Pod 在 test-container 容器中产生以下输出:
kubectl logs dapi-test-pod
very charm
一旦你乐意继续前进,删除该 Pod:
kubectl delete pod dapi-test-pod --now
如基于文件创建 ConfigMap 中所述,当你使用
--from-file 创建 ConfigMap 时,文件名成为存储在 ConfigMap 的 data 部分中的键,
文件内容成为键对应的值。
本节中的示例引用了一个名为 special-config 的 ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
SPECIAL_LEVEL: very
SPECIAL_TYPE: charm
创建 ConfigMap:
kubectl create -f https://kubernetes.io/examples/configmap/configmap-multikeys.yaml
在 Pod 规约的 volumes 部分下添加 ConfigMap 名称。
这会将 ConfigMap 数据添加到 volumeMounts.mountPath 所指定的目录
(在本例中为 /etc/config)。
command 部分列出了名称与 ConfigMap 中的键匹配的目录文件。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh", "-c", "ls /etc/config/" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
# 提供包含要添加到容器中的文件的 ConfigMap 的名称
name: special-config
restartPolicy: Never
创建 Pod:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-volume.yaml
Pod 运行时,命令 ls /etc/config/ 产生下面的输出:
SPECIAL_LEVEL
SPECIAL_TYPE
文本数据会展现为 UTF-8 字符编码的文件。如果使用其他字符编码,
可以使用 binaryData(详情参阅 ConfigMap 对象)。
如果该容器镜像的 /etc/config
目录中有一些文件,卷挂载将使该镜像中的这些文件无法访问。
一旦你乐意继续前进,删除该 Pod:
kubectl delete pod dapi-test-pod --now
使用 path 字段为特定的 ConfigMap 项目指定预期的文件路径。
在这里,ConfigMap 中键 SPECIAL_LEVEL 的内容将挂载在 config-volume
卷中 /etc/config/keys 文件中。
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "/bin/sh","-c","cat /etc/config/keys" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
items:
- key: SPECIAL_LEVEL
path: keys
restartPolicy: Never
创建 Pod:
kubectl create -f https://kubernetes.io/examples/pods/pod-configmap-volume-specific-key.yaml
当 Pod 运行时,命令 cat /etc/config/keys 产生以下输出:
very
如前,/etc/config/ 目录中所有先前的文件都将被删除。
删除该 Pod:
kubectl delete pod dapi-test-pod --now
你可以将密钥投射到特定路径,语法请参阅 Secret 指南中的相应部分。 你可以设置密钥的 POSIX 权限,语法请参阅 Secret 指南中的相应部分。
你可以将指定键名投射到特定目录,也可以逐个文件地设定访问权限。 Secret 指南中为这一语法提供了解释。
ConfigMap 引用可以被标记为可选。 如果 ConfigMap 不存在,则挂载的卷将为空。 如果 ConfigMap 存在,但引用的键不存在,则挂载点下的路径将不存在。 有关更多信息,请参阅可选 ConfigMap 细节。
当已挂载的 ConfigMap 被更新时,所投射的内容最终也会被更新。 这适用于 Pod 启动后可选引用的 ConfigMap 重新出现的情况。
Kubelet 在每次定期同步时都会检查所挂载的 ConfigMap 是否是最新的。 然而,它使用其基于 TTL 机制的本地缓存来获取 ConfigMap 的当前值。 因此,从 ConfigMap 更新到新键映射到 Pod 的总延迟可能与 kubelet 同步周期(默认为 1 分钟)+ kubelet 中 ConfigMap 缓存的 TTL(默认为 1 分钟)一样长。 你可以通过更新 Pod 的一个注解来触发立即刷新。
使用 ConfigMap 作为 subPath 卷的容器将不会收到 ConfigMap 更新。
ConfigMap API 资源将配置数据存储为键值对。 数据可以在 Pod 中使用,也可以用来提供系统组件(如控制器)的配置。 ConfigMap 与 Secret 类似, 但是提供的是一种处理不含敏感信息的字符串的方法。 用户和系统组件都可以在 ConfigMap 中存储配置数据。
ConfigMap 应该引用属性文件,而不是替换它们。可以将 ConfigMap 理解为类似于 Linux
/etc 目录及其内容的东西。例如,如果你基于 ConfigMap 创建
Kubernetes 卷,则 ConfigMap
中的每个数据项都由该数据卷中的某个独立的文件表示。
ConfigMap 的 data 字段包含配置数据。如下例所示,它可以简单
(如用 --from-literal 的单个属性定义)或复杂
(如用 --from-file 的配置文件或 JSON blob 定义)。
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: 2016-02-18T19:14:38Z
name: example-config
namespace: default
data:
# 使用 --from-literal 定义的简单属性
example.property.1: hello
example.property.2: world
# 使用 --from-file 定义复杂属性的例子
example.property.file: |-
property.1=value-1
property.2=value-2
property.3=value-3
当 kubectl 从非 ASCII 或 UTF-8 编码的输入创建 ConfigMap 时,
该工具将这些输入放入 ConfigMap 的 binaryData 字段,而不是 data 字段。
文本和二进制数据源都可以组合在一个 ConfigMap 中。
如果你想查看 ConfigMap 中的 binaryData 键(及其值),
可以运行 kubectl get configmap -o jsonpath='{.binaryData}' <name>。
Pod 可以从使用 data 或 binaryData 的 ConfigMap 中加载数据。
你可以在 Pod 规约中将对 ConfigMap 的引用标记为可选(optional)。 如果 ConfigMap 不存在,那么它在 Pod 中为其提供数据的配置(例如:环境变量、挂载的卷)将为空。 如果 ConfigMap 存在,但引用的键不存在,那么数据也是空的。
例如,以下 Pod 规约将 ConfigMap 中的环境变量标记为可选:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: ["/bin/sh", "-c", "env"]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: a-config
key: akey
optional: true # 将环境变量标记为可选
restartPolicy: Never
当你运行这个 Pod 并且名称为 a-config 的 ConfigMap 不存在时,输出空值。
当你运行这个 Pod 并且名称为 a-config 的 ConfigMap 存在,
但是在 ConfigMap 中没有名称为 akey 的键时,控制台输出也会为空。
如果你确实在名为 a-config 的 ConfigMap 中为 akey 设置了键值,
那么这个 Pod 会打印该值,然后终止。
你也可以在 Pod 规约中将 ConfigMap 提供的卷和文件标记为可选。 此时 Kubernetes 将总是为卷创建挂载路径,即使引用的 ConfigMap 或键不存在。 例如,以下 Pod 规约将所引用得 ConfigMap 的卷标记为可选:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: ["/bin/sh", "-c", "ls /etc/config"]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: no-config
optional: true # 将引用的 ConfigMap 的卷标记为可选
restartPolicy: Never
ConfigMap 之前,必须先创建这个对象,
或者在 Pod 规约中将 ConfigMap 标记为 optional(请参阅可选的 ConfigMaps)。
如果所引用的 ConfigMap 不存在,并且没有将应用标记为 optional 则 Pod 将无法启动。
同样,引用 ConfigMap 中不存在的主键也会令 Pod 无法启动,除非你将 Configmap 标记为 optional。如果你使用 envFrom 来基于 ConfigMap 定义环境变量,那么无效的键将被忽略。
Pod 可以被启动,但无效名称将被记录在事件日志中(InvalidVariableNames)。
日志消息列出了每个被跳过的键。例如:
kubectl get events
输出与此类似:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames {kubelet, 127.0.0.1} Keys [1badkey, 2alsobad] from the EnvFrom configMap default/myconfig were skipped since they are considered invalid environment variable names.
删除你创建那些的 ConfigMap 和 Pod:
kubectl delete configmaps/game-config configmaps/game-config-2 configmaps/game-config-3 \
configmaps/game-config-env-file
kubectl delete pod dapi-test-pod --now
# 你可能已经删除了下一组内容
kubectl delete configmaps/special-config configmaps/env-config
kubectl delete configmap -l 'game-config in (config-4,config-5)'
如果你创建了一个目录 configure-pod-container 并且不再需要它,你也应该删除这个目录,
或者将该目录移动到回收站/删除文件的位置。
此页面展示如何为 Pod 配置进程命名空间共享。 当启用进程命名空间共享时,容器中的进程对同一 Pod 中的所有其他容器都是可见的。
你可以使用此功能来配置协作容器,比如日志处理 sidecar 容器, 或者对那些不包含诸如 shell 等调试实用工具的镜像进行故障排查。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
使用 Pod .spec 中的 shareProcessNamespace 字段可以启用进程命名空间共享。例如:
在集群中创建 nginx Pod:
kubectl apply -f https://k8s.io/examples/pods/share-process-namespace.yaml
获取容器 shell,执行 ps:
kubectl attach -it nginx -c shell
如果没有看到命令提示符,请按 enter 回车键。在容器 shell 中:
# 在 “shell” 容器中运行以下命令
ps ax
输出类似于:
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
14 101 0:00 nginx: worker process
15 root 0:00 sh
21 root 0:00 ps ax
你可以在其他容器中对进程发出信号。例如,发送 SIGHUP 到 nginx 以重启工作进程。
此操作需要 SYS_PTRACE 权能。
# 在 “shell” 容器中运行以下命令
kill -HUP 8 # 如有必要,更改 “8” 以匹配 nginx 领导进程的 PID
ps ax
输出类似于:
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
15 root 0:00 sh
22 101 0:00 nginx: worker process
23 root 0:00 ps ax
甚至可以使用 /proc/$pid/root 链接访问另一个容器的文件系统。
# 在 “shell” 容器中运行以下命令
# 如有必要,更改 “8” 为 Nginx 进程的 PID
head /proc/8/root/etc/nginx/nginx.conf
输出类似于:
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
Pod 共享许多资源,因此它们共享进程命名空间是很有意义的。 不过,有些容器可能希望与其他容器隔离,因此了解这些差异很重要:
systemd 的容器),或者拒绝执行 kill -HUP 1 之类的命令来通知容器进程。
在具有共享进程命名空间的 Pod 中,kill -HUP 1 将通知 Pod 沙箱(在上面的例子中是 /pause)。/proc 中可见的所有信息,
例如作为参数或环境变量传递的密码。这些仅受常规 Unix 权限的保护。/proc/$pid/root 链接对 Pod 中的其他容器可见。 这使调试更加容易,
但也意味着文件系统安全性只受文件系统权限的保护。Kubernetes v1.25 [alpha]
本页展示如何为无状态 Pod 配置用户名字空间。可以将容器内的用户与主机上的用户隔离开来。
在容器中以 root 用户运行的进程可以以不同的(非 root)用户在宿主机上运行;换句话说, 进程在用户名字空间内部拥有执行操作的全部特权,但在用户名字空间外部并没有执行操作的特权。
你可以使用这个特性来减少有害的容器对同一宿主机上其他容器的影响。 有些安全脆弱性问题被评为 HIGH or CRITICAL,但当用户名字空间被启用时, 它们是无法被利用的。相信用户名字空间也能减轻一些未来的漏洞的影响。
在不使用用户名字空间的情况下,对于以 root 用户运行的容器而言,发生容器逃逸时, 容器将拥有在宿主机上的 root 特权。如果容器被赋予了某些权限,则这些权限在宿主机上同样有效。 当使用用户名字空间时这些都不可能发生。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.25. 要获知版本信息,请输入kubectl version.
UserNamespacesSupport 特性门控。在用户名字空间原来仅支持无状态的 Pod 时,启用用户名字空间的特性门控先前被命名为 UserNamespacesStatelessPodsSupport。
只有 Kubernetes v1.25 到 v1.27 才能识别 UserNamespacesStatelessPodsSupport。
你所使用的集群必须包括至少一个符合 要求 的节点,以便为 Pod 配置用户名字空间。
如果你有混合节点,并且只有部分节点支持为 Pod 配置用户名字空间, 你还需要确保配置了用户名字空间的 Pod 被调度到合适的节点。
请注意 如果你的容器运行时环境不支持用户名字空间,那么 Pod 规约中的 hostUsers 字段将被静默忽略,
并且系统会在没有用户名字空间的环境中创建 Pod。
为一个 Pod 启用用户名字空间需要设置 .spec 的 hostUsers 字段为 false. 例如:
apiVersion: v1
kind: Pod
metadata:
name: userns
spec:
hostUsers: false
containers:
- name: shell
command: ["sleep", "infinity"]
image: debian
在你的集群上创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/user-namespaces-stateless.yaml
挂接到容器上并执行 readlink /proc/self/ns/user:
kubectl attach -it userns bash
执行命令的输出类似于:
readlink /proc/self/ns/user
user:[4026531837]
cat /proc/self/uid_map
0 0 4294967295
然后,在主机中打开一个 Shell 并运行相同的命令。
输出一定是不同的。这意味着主机和 Pod 使用不同的用户名字空间。当未启用用户名字空间时, 宿主机和 Pod 使用相同的用户名字空间。
如果你在用户名字空间中运行 kubelet,则需要将在 Pod 中运行命令的输出与在主机中运行的输出进行比较:
readlink /proc/$pid/ns/user
user:[4026534732]
使用 kubelet 的进程号代替 $pid
静态 Pod 在指定的节点上由 kubelet 守护进程直接管理,不需要 API 服务器监管。 与由控制面管理的 Pod(例如,Deployment) 不同;kubelet 监视每个静态 Pod(在它失败之后重新启动)。
静态 Pod 始终都会绑定到特定节点的 Kubelet 上。
kubelet 会尝试通过 Kubernetes API 服务器为每个静态 Pod 自动创建一个镜像 Pod。 这意味着节点上运行的静态 Pod 对 API 服务来说是可见的,但是不能通过 API 服务器来控制。 Pod 名称将把以连字符开头的节点主机名作为后缀。
如果你在运行一个 Kubernetes 集群,并且在每个节点上都运行一个静态 Pod, 就可能需要考虑使用 DaemonSet 替代这种方式。
静态 Pod 的 spec 不能引用其他 API 对象
(如:ServiceAccount、
ConfigMap、
Secret 等)。
静态 Pod 不支持临时容器。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
本文假定你在使用 Docker 来运行 Pod, 并且你的节点是运行着 Fedora 操作系统。 其它发行版或者 Kubernetes 部署版本上操作方式可能不一样。
可以通过文件系统上的配置文件或者 Web 网络上的配置文件来配置静态 Pod。
声明文件是标准的 Pod 定义文件,以 JSON 或者 YAML 格式存储在指定目录。路径设置在
Kubelet 配置文件的
staticPodPath: <目录> 字段,kubelet 会定期的扫描这个文件夹下的 YAML/JSON
文件来创建/删除静态 Pod。
注意 kubelet 扫描目录的时候会忽略以点开头的文件。
例如:下面是如何以静态 Pod 的方式启动一个简单 web 服务:
选择一个要运行静态 Pod 的节点。在这个例子中选择 my-node1。
ssh my-node1
选择一个目录,比如在 /etc/kubernetes/manifests 目录来保存 Web 服务 Pod 的定义文件,例如
/etc/kubernetes/manifests/static-web.yaml:
# 在 kubelet 运行的节点上执行以下命令
mkdir -p /etc/kubernetes/manifests/
cat <<EOF >/etc/kubernetes/manifests/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
EOF
在该节点上配置 kubelet,在 kubelet 配置文件中设定 staticPodPath 值。
欲了解更多信息,请参考通过配置文件设定 kubelet 参数。
另一个已弃用的方法是,在该节点上通过命令行参数配置 kubelet,以便从本地查找静态 Pod 清单。
若使用这种弃用的方法,请启动 kubelet 时加上 --pod-manifest-path=/etc/kubernetes/manifests/ 参数。
重启 kubelet。在 Fedora 上,你将使用下面的命令:
# 在 kubelet 运行的节点上执行以下命令
systemctl restart kubelet
Kubelet 根据 --manifest-url=<URL> 参数的配置定期的下载指定文件,并且转换成
JSON/YAML 格式的 Pod 定义文件。
与文件系统上的清单文件使用方式类似,kubelet 调度获取清单文件。
如果静态 Pod 的清单文件有改变,kubelet 会应用这些改变。
按照下面的方式来:
创建一个 YAML 文件,并保存在 Web 服务器上,这样你就可以将该文件的 URL 传递给 kubelet。
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
通过在选择的节点上使用 --manifest-url=<manifest-url> 配置运行 kubelet。
在 Fedora 添加下面这行到 /etc/kubernetes/kubelet:
KUBELET_ARGS="--cluster-dns=10.254.0.10 --cluster-domain=kube.local --manifest-url=<manifest-url>"
重启 kubelet。在 Fedora 上,你将运行如下命令:
# 在 kubelet 运行的节点上执行以下命令
systemctl restart kubelet
当 kubelet 启动时,会自动启动所有定义的静态 Pod。 当定义了一个静态 Pod 并重新启动 kubelet 时,新的静态 Pod 就应该已经在运行了。
可以在节点上运行下面的命令来查看正在运行的容器(包括静态 Pod):
# 在 kubelet 运行的节点上执行以下命令
crictl ps
输出可能会像这样:
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
129fd7d382018 docker.io/library/nginx@sha256:... 11 minutes ago Running web 0 34533c6729106
crictl 会输出镜像 URI 和 SHA-256 校验和。NAME 看起来像:
docker.io/library/nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31。
可以在 API 服务上看到镜像 Pod:
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 2m
要确保 kubelet 在 API 服务上有创建镜像 Pod 的权限。如果没有,创建请求会被 API 服务拒绝。
静态 Pod 上的标签被传播到镜像 Pod。 你可以通过选择算符使用这些标签。
如果你用 kubectl 从 API 服务上删除镜像 Pod,kubelet 不会移除静态 Pod:
kubectl delete pod static-web-my-node1
pod "static-web-my-node1" deleted
可以看到 Pod 还在运行:
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 4s
回到 kubelet 运行所在的节点上,你可以手动停止容器。 可以看到过了一段时间后 kubelet 会发现容器停止了并且会自动重启 Pod:
# 在 kubelet 运行的节点上执行以下命令
# 把 ID 换为你的容器的 ID
crictl stop 129fd7d382018
sleep 20
crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
89db4553e1eeb docker.io/library/nginx@sha256:... 19 seconds ago Running web 1 34533c6729106
一旦你找到合适的容器,你就可以使用 crictl 获取该容器的日志。
# 在容器运行所在的节点上执行以下命令
crictl logs <container_id>
10.240.0.48 - - [16/Nov/2022:12:45:49 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.48 - - [16/Nov/2022:12:45:50 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.48 - - [16/Nove/2022:12:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
若要找到如何使用 crictl 进行调试的更多信息,
请访问使用 crictl 对 Kubernetes 节点进行调试。
运行中的 kubelet 会定期扫描配置的目录(比如例子中的 /etc/kubernetes/manifests 目录)中的变化,
并且根据文件中出现/消失的 Pod 来添加/删除 Pod。
# 这里假定你在用主机文件系统上的静态 Pod 配置文件
# 在容器运行所在的节点上执行以下命令
mv /etc/kubernetes/manifests/static-web.yaml /tmp
sleep 20
crictl ps
# 可以看到没有 nginx 容器在运行
mv /tmp/static-web.yaml /etc/kubernetes/manifests/
sleep 20
crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
f427638871c35 docker.io/library/nginx@sha256:... 19 seconds ago Running web 1 34533c6729106
Kompose 是什么?它是一个转换工具,可将 compose (即 Docker Compose)所组装的所有内容转换成容器编排器(Kubernetes 或 OpenShift)可识别的形式。
更多信息请参考 Kompose 官网 http://kompose.io。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
我们有很多种方式安装 Kompose。首选方式是从最新的 GitHub 发布页面下载二进制文件。
Kompose 通过 GitHub 发布,发布周期为三星期。 你可以在 GitHub 发布页面上看到所有当前版本。
# Linux
curl -L https://github.com/kubernetes/kompose/releases/download/v1.26.0/kompose-linux-amd64 -o kompose
# macOS
curl -L https://github.com/kubernetes/kompose/releases/download/v1.26.0/kompose-darwin-amd64 -o kompose
# Windows
curl -L https://github.com/kubernetes/kompose/releases/download/v1.26.0/kompose-windows-amd64.exe -o kompose.exe
chmod +x kompose
sudo mv ./kompose /usr/local/bin/kompose
或者,你可以下载 tar 包。
用 go get 命令从主分支拉取最新的开发变更的方法安装 Kompose。
go get -u github.com/kubernetes/kompose
Kompose 位于 EPEL CentOS 代码仓库。
如果你还没有安装并启用 EPEL 代码仓库,
请运行命令 sudo yum install epel-release。
如果你的系统中已经启用了 EPEL, 你就可以像安装其他软件包一样安装 Kompose。
sudo yum -y install kompose
Kompose 位于 Fedora 24、25 和 26 的代码仓库。你可以像安装其他软件包一样安装 Kompose。
sudo dnf -y install kompose
只需几步,我们就把你从 Docker Compose 带到 Kubernetes。
你只需要一个现有的 docker-compose.yml 文件。
进入 docker-compose.yml 文件所在的目录。如果没有,请使用下面这个进行测试。
version: "2"
services:
redis-master:
image: registry.k8s.io/redis:e2e
ports:
- "6379"
redis-slave:
image: gcr.io/google_samples/gb-redisslave:v3
ports:
- "6379"
environment:
- GET_HOSTS_FROM=dns
frontend:
image: gcr.io/google-samples/gb-frontend:v4
ports:
- "80:80"
environment:
- GET_HOSTS_FROM=dns
labels:
kompose.service.type: LoadBalancer
要将 docker-compose.yml 转换为 kubectl 可用的文件,请运行 kompose convert
命令进行转换,然后运行 kubectl apply -f <output file> 进行创建。
kompose convert
输出类似于:
INFO Kubernetes file "frontend-tcp-service.yaml" created
INFO Kubernetes file "redis-master-service.yaml" created
INFO Kubernetes file "redis-slave-service.yaml" created
INFO Kubernetes file "frontend-deployment.yaml" created
INFO Kubernetes file "redis-master-deployment.yaml" created
INFO Kubernetes file "redis-slave-deployment.yaml" created
kubectl apply -f frontend-tcp-service.yaml,redis-master-service.yaml,redis-slave-service.yaml,frontend-deployment.yaml,redis-master-deployment.yaml,redis-slave-deployment.yaml
输出类似于:
service/frontend-tcp created
service/redis-master created
service/redis-slave created
deployment.apps/frontend created
deployment.apps/redis-master created
deployment.apps/redis-slave created
你部署的应用在 Kubernetes 中运行起来了。
访问你的应用。
如果你在开发过程中使用 minikube,请执行:
minikube service frontend
否则,我们要查看一下你的服务使用了什么 IP!
kubectl describe svc frontend
Name: frontend-tcp
Namespace: default
Labels: io.kompose.service=frontend-tcp
Annotations: kompose.cmd: kompose convert
kompose.service.type: LoadBalancer
kompose.version: 1.26.0 (40646f47)
Selector: io.kompose.service=frontend
Type: LoadBalancer
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.43.67.174
IPs: 10.43.67.174
Port: 80 80/TCP
TargetPort: 80/TCP
NodePort: 80 31254/TCP
Endpoints: 10.42.0.25:80
Session Affinity: None
External Traffic Policy: Cluster
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal EnsuringLoadBalancer 62s service-controller Ensuring load balancer
Normal AppliedDaemonSet 62s service-controller Applied LoadBalancer DaemonSet kube-system/svclb-frontend-tcp-9362d276
如果你使用的是云驱动,你的 IP 将在 LoadBalancer Ingress 字段给出。
curl http://192.0.2.89
清理。
你完成示例应用 Deployment 的测试之后,只需在 Shell 中运行以下命令,就能删除用过的资源。
kubectl delete -f frontend-tcp-service.yaml,redis-master-service.yaml,redis-slave-service.yaml,frontend-deployment.yaml,redis-master-deployment.yaml,redis-slave-deployment.yaml
CLI
文档
Kompose 支持两种驱动:OpenShift 和 Kubernetes。
你可以通过全局选项 --provider 选择驱动。如果没有指定,
会将 Kubernetes 作为默认驱动。
kompose convertKompose 支持将 V1、V2 和 V3 版本的 Docker Compose 文件转换为 Kubernetes 和 OpenShift 资源对象。
kompose convert 示例 kompose --file docker-voting.yml convert
WARN Unsupported key networks - ignoring
WARN Unsupported key build - ignoring
INFO Kubernetes file "worker-svc.yaml" created
INFO Kubernetes file "db-svc.yaml" created
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "result-svc.yaml" created
INFO Kubernetes file "vote-svc.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
INFO Kubernetes file "result-deployment.yaml" created
INFO Kubernetes file "vote-deployment.yaml" created
INFO Kubernetes file "worker-deployment.yaml" created
INFO Kubernetes file "db-deployment.yaml" created
ls
db-deployment.yaml docker-compose.yml docker-gitlab.yml redis-deployment.yaml result-deployment.yaml vote-deployment.yaml worker-deployment.yaml
db-svc.yaml docker-voting.yml redis-svc.yaml result-svc.yaml vote-svc.yaml worker-svc.yaml
你也可以同时提供多个 docker-compose 文件进行转换:
kompose -f docker-compose.yml -f docker-guestbook.yml convert
INFO Kubernetes file "frontend-service.yaml" created
INFO Kubernetes file "mlbparks-service.yaml" created
INFO Kubernetes file "mongodb-service.yaml" created
INFO Kubernetes file "redis-master-service.yaml" created
INFO Kubernetes file "redis-slave-service.yaml" created
INFO Kubernetes file "frontend-deployment.yaml" created
INFO Kubernetes file "mlbparks-deployment.yaml" created
INFO Kubernetes file "mongodb-deployment.yaml" created
INFO Kubernetes file "mongodb-claim0-persistentvolumeclaim.yaml" created
INFO Kubernetes file "redis-master-deployment.yaml" created
INFO Kubernetes file "redis-slave-deployment.yaml" created
ls
mlbparks-deployment.yaml mongodb-service.yaml redis-slave-service.jsonmlbparks-service.yaml
frontend-deployment.yaml mongodb-claim0-persistentvolumeclaim.yaml redis-master-service.yaml
frontend-service.yaml mongodb-deployment.yaml redis-slave-deployment.yaml
redis-master-deployment.yaml
当提供多个 docker-compose 文件时,配置将会合并。任何通用的配置都将被后续文件覆盖。
kompose convert 示例 kompose --provider openshift --file docker-voting.yml convert
WARN [worker] Service cannot be created because of missing port.
INFO OpenShift file "vote-service.yaml" created
INFO OpenShift file "db-service.yaml" created
INFO OpenShift file "redis-service.yaml" created
INFO OpenShift file "result-service.yaml" created
INFO OpenShift file "vote-deploymentconfig.yaml" created
INFO OpenShift file "vote-imagestream.yaml" created
INFO OpenShift file "worker-deploymentconfig.yaml" created
INFO OpenShift file "worker-imagestream.yaml" created
INFO OpenShift file "db-deploymentconfig.yaml" created
INFO OpenShift file "db-imagestream.yaml" created
INFO OpenShift file "redis-deploymentconfig.yaml" created
INFO OpenShift file "redis-imagestream.yaml" created
INFO OpenShift file "result-deploymentconfig.yaml" created
INFO OpenShift file "result-imagestream.yaml" created
kompose 还支持为服务中的构建指令创建 buildconfig。
默认情况下,它使用当前 git 分支的 remote 仓库作为源仓库,使用当前分支作为构建的源分支。
你可以分别使用 --build-repo 和 --build-branch 选项指定不同的源仓库和分支。
kompose --provider openshift --file buildconfig/docker-compose.yml convert
WARN [foo] Service cannot be created because of missing port.
INFO OpenShift Buildconfig using git@github.com:rtnpro/kompose.git::master as source.
INFO OpenShift file "foo-deploymentconfig.yaml" created
INFO OpenShift file "foo-imagestream.yaml" created
INFO OpenShift file "foo-buildconfig.yaml" created
如果使用 oc create -f 手动推送 OpenShift 工件,则需要确保在构建配置工件之前推送
imagestream 工件,以解决 OpenShift 的这个问题: https://github.com/openshift/origin/issues/4518。
默认的 kompose 转换会生成 yaml 格式的 Kubernetes
Deployment 和
Service 对象。
你可以选择通过 -j 参数生成 json 格式的对象。
你也可以替换生成 Replication Controllers 对象、
DaemonSet 或
Helm Chart。
kompose convert -j
INFO Kubernetes file "redis-svc.json" created
INFO Kubernetes file "web-svc.json" created
INFO Kubernetes file "redis-deployment.json" created
INFO Kubernetes file "web-deployment.json" created
*-deployment.json 文件中包含 Deployment 对象。
kompose convert --replication-controller
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "web-svc.yaml" created
INFO Kubernetes file "redis-replicationcontroller.yaml" created
INFO Kubernetes file "web-replicationcontroller.yaml" created
*-replicationcontroller.yaml 文件包含 Replication Controller 对象。
如果你想指定副本数(默认为 1),可以使用 --replicas 参数:
kompose convert --replication-controller --replicas 3
kompose convert --daemon-set
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "web-svc.yaml" created
INFO Kubernetes file "redis-daemonset.yaml" created
INFO Kubernetes file "web-daemonset.yaml" created
*-daemonset.yaml 文件包含 DaemonSet 对象。
如果你想生成 Helm 可用的 Chart, 只需简单的执行下面的命令:
kompose convert -c
INFO Kubernetes file "web-svc.yaml" created
INFO Kubernetes file "redis-svc.yaml" created
INFO Kubernetes file "web-deployment.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
chart created in "./docker-compose/"
tree docker-compose/
docker-compose
├── Chart.yaml
├── README.md
└── templates
├── redis-deployment.yaml
├── redis-svc.yaml
├── web-deployment.yaml
└── web-svc.yaml
这个 Chart 结构旨在为构建 Helm Chart 提供框架。
kompose 支持 docker-compose.yml 文件中用于 Kompose 的标签,
以便在转换时明确定义 Service 的行为。
kompose.service.type 定义要创建的 Service 类型。例如:
version: "2"
services:
nginx:
image: nginx
dockerfile: foobar
build: ./foobar
cap_add:
- ALL
container_name: foobar
labels:
kompose.service.type: nodeport
kompose.service.expose 定义是否允许从集群外部访问 Service。
如果该值被设置为 "true",提供程序将自动设置端点,
对于任何其他值,该值将被设置为主机名。
如果在 Service 中定义了多个端口,则选择第一个端口作为公开端口。
例如:
version: "2"
services:
web:
image: tuna/docker-counter23
ports:
- "5000:5000"
links:
- redis
labels:
kompose.service.expose: "counter.example.com"
redis:
image: redis:3.0
ports:
- "6379"
当前支持的选项有:
| 键 | 值 |
|---|---|
| kompose.service.type | nodeport / clusterip / loadbalancer |
| kompose.service.expose | true / hostname |
kompose.service.type 标签应该只用 ports 来定义,否则 kompose 会失败。
如果你想创建没有控制器的普通 Pod,可以使用 docker-compose 的 restart
结构来指定这一行为。请参考下表了解 restart 的不同参数。
docker-compose restart |
创建的对象 | Pod restartPolicy |
|---|---|---|
"" |
控制器对象 | Always |
always |
控制器对象 | Always |
on-failure |
Pod | OnFailure |
no |
Pod | Never |
控制器对象可以是 deployment 或 replicationcontroller。
例如,pival Service 将在这里变成 Pod。这个容器计算 pi 的取值。
version: '2'
services:
pival:
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restart: "on-failure"
如果 Docker Compose 文件中为服务声明了卷,Deployment(Kubernetes)或 DeploymentConfig(OpenShift)策略会从 “RollingUpdate”(默认)变为 “Recreate”。 这样做的目的是为了避免服务的多个实例同时访问卷。
如果 Docker Compose 文件中的服务名包含 _(例如 web_service),
那么将会被替换为 -,服务也相应的会重命名(例如 web-service)。
Kompose 这样做的原因是 “Kubernetes” 不允许对象名称中包含 _。
请注意,更改服务名称可能会破坏一些 docker-compose 文件。
Kompose 支持的 Docker Compose 版本包括:1、2 和 3。 对 2.1 和 3.2 版本的支持还有限,因为它们还在实验阶段。
所有三个版本的兼容性列表, 请查看我们的转换文档, 文档中列出了所有不兼容的 Docker Compose 关键字。
Kubernetes 提供一种内置的准入控制器 用来强制实施 Pod 安全性标准。 你可以配置此准入控制器来设置集群范围的默认值和豁免选项。
Pod 安全性准入(Pod Security Admission)在 Kubernetes v1.22 作为 Alpha 特性发布, 在 Kubernetes v1.23 中作为 Beta 特性默认可用。从 1.25 版本起, 此特性进阶至正式发布(Generally Available)。
要获知版本信息,请输入 kubectl version.
如果未运行 Kubernetes 1.29, 你可以切换到与当前运行的 Kubernetes 版本所对应的文档。
pod-security.admission.config.k8s.io/v1 配置需要 v1.25+。
对于 v1.23 和 v1.24,使用
v1beta1。
对于 v1.22,使用
v1alpha1。
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: PodSecurity
configuration:
apiVersion: pod-security.admission.config.k8s.io/v1
kind: PodSecurityConfiguration
# 当未设置 mode 标签时会应用的默认设置
#
# level 标签必须是以下取值之一:
# - "privileged" (默认)
# - "baseline"
# - "restricted"
#
# version 标签必须是如下取值之一:
# - "latest" (默认)
# - 诸如 "v1.29" 这类版本号
defaults:
enforce: "privileged"
enforce-version: "latest"
audit: "privileged"
audit-version: "latest"
warn: "privileged"
warn-version: "latest"
exemptions:
# 要豁免的已认证用户名列表
usernames: []
# 要豁免的运行时类名称列表
runtimeClasses: []
# 要豁免的名字空间列表
namespaces: []
上面的清单需要通过 ——admission-control-config-file 指定到 kube-apiserver。
上面的清单需要通过 --admission-control-config-file 指定给 kube-apiserver。
名字空间可以打上标签以强制执行 Pod 安全性标准。 特权(privileged)、 基线(baseline)和 受限(restricted) 这三种策略涵盖了广泛安全范围,并由 Pod 安全准入控制器实现。
Pod 安全性准入(Pod Security Admission)在 Kubernetes v1.23 中作为 Beta 特性默认可用。 从 1.25 版本起,此特性进阶至正式发布(Generally Available)。
要获知版本信息,请输入 kubectl version.
baseline Pod 容器标准下面的清单定义了一个 my-baseline-namespace 名字空间,其中
baseline 策略要求的 Pod;restricted 策略要求的、已创建的 Pod 为用户生成警告信息,
并添加审计注解;baseline 和 restricted 策略的版本锁定到 v1.29。apiVersion: v1
kind: Namespace
metadata:
name: my-baseline-namespace
labels:
pod-security.kubernetes.io/enforce: baseline
pod-security.kubernetes.io/enforce-version: v1.29
# 我们将这些标签设置为我们所 _期望_ 的 `enforce` 级别
pod-security.kubernetes.io/audit: restricted
pod-security.kubernetes.io/audit-version: v1.29
pod-security.kubernetes.io/warn: restricted
pod-security.kubernetes.io/warn-version: v1.29
kubectl label 为现有名字空间添加标签在添加或变更 enforce 策略(或版本)标签时,准入插件会测试名字空间中的每个
Pod 以检查其是否满足新的策略。不符合策略的情况会被以警告的形式返回给用户。
在刚开始为名字空间评估安全性策略变更时,使用 --dry-run 标志是很有用的。
Pod 安全性标准会在 dry run(试运行)
模式下运行,在这种模式下会生成新策略如何处理现有 Pod 的信息,
但不会真正更新策略。
kubectl label --dry-run=server --overwrite ns --all \
pod-security.kubernetes.io/enforce=baseline
如果你是刚刚开始使用 Pod 安全性标准,一种比较合适的初始步骤是针对所有名字空间为类似
baseline 这种比较严格的安全级别配置审计注解。
kubectl label --overwrite ns --all \
pod-security.kubernetes.io/audit=baseline \
pod-security.kubernetes.io/warn=baseline
注意,这里没有设置 enforce 级别,因而没有被显式评估的名字空间可以被识别出来。 你可以使用下面的命令列举那些没有显式设置 enforce 级别的名字空间:
kubectl get namespaces --selector='!pod-security.kubernetes.io/enforce'
你也可以更新特定的名字空间。下面的命令将 enforce=restricted 策略应用到
my-existing-namespace 名字空间,将 restricted 策略的版本锁定到 v1.29。
kubectl label --overwrite ns my-existing-namespace \
pod-security.kubernetes.io/enforce=restricted \
pod-security.kubernetes.io/enforce-version=v1.29
本页面描述从 PodSecurityPolicy 迁移到内置的 PodSecurity 准入控制器的过程。
这一迁移过程可以通过综合使用试运行、audit 和 warn 模式等来实现,
尽管在使用了变更式 PSP 时会变得有些困难。
你的 Kubernetes 服务器版本必须不低于版本 v1.22.
要获知版本信息,请输入 kubectl version.
如果你目前运行的 Kubernetes 版本不是 1.29, 你可能要切换本页面以查阅你实际所运行的 Kubernetes 版本文档。
本页面假定你已经熟悉 Pod 安全性准入的基本概念。
你可以采取多种策略来完成从 PodSecurityPolicy 到 Pod 安全性准入 (Pod Security Admission)的迁移。 下面是一种可能的迁移路径,其目标是尽可能降低生产环境不可用的风险, 以及安全性仍然不足的风险。
Pod 安全性准入被设计用来直接满足最常见的安全性需求,并提供一组可用于多个集群的安全性级别。 不过,这一机制比 PodSecurityPolicy 的灵活度要低。 值得注意的是,PodSecurityPolicy 所支持的以下特性是 Pod 安全性准入所不支持的:
即便 Pod 安全性准入无法满足你的所有需求,该机制也是设计用作其他策略实施机制的 补充,因此可以和其他准入 Webhook 一起运行,进而提供一种有用的兜底机制。
Pod 安全性准入是通过名字空间上的标签 来控制的。这也就是说,任何能够更新(或通过 patch 部分更新或创建) 名字空间的人都可以更改该名字空间的 Pod 安全性级别,而这可能会被利用来绕过约束性更强的策略。 在继续执行迁移操作之前,请确保只有被信任的、有特权的用户具有这类名字空间访问权限。 不建议将这类强大的访问权限授予不应获得权限提升的用户,不过如果你必须这样做, 你需要使用一个准入 Webhook 来针对为 Namespace 对象设置 Pod 安全性级别设置额外的约束。
在本节中,你会削减变更性质的 PodSecurityPolicy,去掉 Pod 安全性标准范畴之外的选项。
针对要修改的、已存在的 PodSecurityPolicy,你应该将这里所建议的更改写入到其离线副本中。
所克隆的 PSP 应该与原来的副本名字不同,并且按字母序要排到原副本之前
(例如,可以向 PSP 名字前加一个 0)。
先不要在 Kubernetes 中创建新的策略 -
这类操作会在后文的推出更新的策略部分讨论。
如果某个 PodSecurityPolicy 能够变更字段,你可能会在关掉 PodSecurityPolicy 时发现有些 Pod 无法满足 Pod 安全性级别。为避免这类状况, 你应该在执行切换操作之前去掉所有 PSP 的变更操作。 不幸的是,PSP 没有对变更性和验证性字段做清晰的区分,所以这一迁移操作也不够简单直接。
你可以先去掉那些纯粹变更性质的字段,留下验证策略中的其他内容。 这些字段(也列举于将 PodSecurityPolicy 映射到 Pod 安全性标准参考中) 包括:
.spec.defaultAllowPrivilegeEscalation.spec.runtimeClass.defaultRuntimeClassName.metadata.annotations['seccomp.security.alpha.kubernetes.io/defaultProfileName'].metadata.annotations['apparmor.security.beta.kubernetes.io/defaultProfileName'].spec.defaultAddCapabilities - 尽管理论上是一个混合了变更性与验证性功能的字段,
这里的设置应该被合并到 .spec.allowedCapabilities 中,后者会执行相同的验证操作,
但不会执行任何变更动作。删除这些字段可能导致负载缺少所需的配置信息,进而导致一些问题。 参见后文退出更新的策略以获得如何安全地将这些变更上线的建议。
PodSecurityPolicy 中有一些字段未被 Pod 安全性准入机制覆盖。如果你必须使用这些选项, 你需要在 Pod 安全性准入之外部署准入 Webhook 以补充这一能力,而这类操作不在本指南范围。
首先,你可以去掉 Pod 安全性标准所未覆盖的那些验证性字段。这些字段 (也列举于将 PodSecurityPolicy 映射到 Pod 安全性标准参考中, 标记为“无意见”)有:
.spec.allowedHostPaths.spec.allowedFlexVolumes.spec.allowedCSIDrivers.spec.forbiddenSysctls.spec.runtimeClass你也可以去掉以下字段,这些字段与 POSIX/UNIX 用户组控制有关。
如果这些字段中存在使用 MustRunAs 策略的情况,则意味着对应字段是变更性质的。
去掉相应的字段可能导致负载无法设置所需的用户组,进而带来一些问题。
关于如何安全地将这类变更上线的相关建议,请参阅后文的推出更新的策略部分。
.spec.runAsGroup.spec.supplementalGroups.spec.fsGroup剩下的变更性字段是为了适当支持 Pod 安全性标准所需要的,因而需要逐个处理:
.spec.requiredDropCapabilities - 需要此字段来为 Restricted 配置去掉 ALL 设置。.spec.seLinux - (仅针对带有 MustRunAs 规则的变更性设置)需要此字段来满足
Baseline 和 Restricted 配置所需要的 SELinux 需求。.spec.runAsUser - (仅针对带有 RunAsAny 规则的非变更性设置)需要此字段来为
Restricted 配置保证 RunAsNonRoot。.spec.allowPrivilegeEscalation - (如果设置为 false 则为变更性设置)
需要此字段来支持 Restricted 配置。接下来,你可以将更新后的策略推出到你的集群上。在继续操作时,你要非常小心, 因为去掉变更性质的选项可能导致有些工作负载缺少必需的配置。
针对更新后的每个 PodSecurityPolicy:
识别运行于原 PSP 之下的 Pod。可以通过 kubernetes.io/psp 注解来完成。
例如,使用 kubectl:
PSP_NAME="original" # 设置你要检查的 PSP 的名称
kubectl get pods --all-namespaces -o jsonpath="{range .items[?(@.metadata.annotations.kubernetes\.io\/psp=='$PSP_NAME')]}{.metadata.namespace} {.metadata.name}{'\n'}{end}"
比较运行中的 Pod 与原来的 Pod 规约,确定 PodSecurityPolicy 是否更改过这些 Pod。 对于通过工作负载资源所创建的 Pod, 你可以比较 Pod 和控制器资源中的 PodTemplate。如果发现任何变更,则原来的 Pod 或者 PodTemplate 需要被更新以加上所希望的配置。要审查的字段包括:
.metadata.annotations['container.apparmor.security.beta.kubernetes.io/*']
(将 * 替换为每个容器的名称).spec.runtimeClassName.spec.securityContext.fsGroup.spec.securityContext.seccompProfile.spec.securityContext.seLinuxOptions.spec.securityContext.supplementalGroups.spec.containers[*] 和 .spec.initContainers[*] 之下,检查下面字段:.securityContext.allowPrivilegeEscalation.securityContext.capabilities.add.securityContext.capabilities.drop.securityContext.readOnlyRootFilesystem.securityContext.runAsGroup.securityContext.runAsNonRoot.securityContext.runAsUser.securityContext.seccompProfile.securityContext.seLinuxOptionsuse 动词的权限,则所使用的的会是新创建的 PSP 而不是其变更性的副本。use 访问权限的 Role 或 ClusterRole 对象,使之也对更新后的 PSP 授权。下面的步骤需要在集群中的所有名字空间上执行。所列步骤中的命令使用变量
$NAMESPACE 来引用所更新的名字空间。
首先请回顾 Pod 安全性标准内容, 并了解三个安全级别。
为你的名字空间选择 Pod 安全性级别有几种方法:
根据现有的 PodSecurityPolicy 来确定 - 基于将 PodSecurityPolicy 映射到 Pod 安全性标准 参考资料,你可以将各个 PSP 映射到某个 Pod 安全性标准级别。如果你的 PSP 不是基于 Pod 安全性标准的,你可能或者需要选择一个至少与该 PSP 一样宽松的级别, 或者选择一个至少与其一样严格的级别。使用下面的命令你可以查看被 Pod 使用的 PSP 有哪些:
kubectl get pods -n $NAMESPACE -o jsonpath="{.items[*].metadata.annotations.kubernetes\.io\/psp}" | tr " " "\n" | sort -u
上面的第二和第三种方案是基于 现有 Pod 的,因此可能错失那些当前未处于运行状态的 Pod,例如 CronJobs、缩容到零的负载,或者其他尚未全面铺开的负载。
一旦你已经为名字空间选择了 Pod 安全性级别(或者你正在尝试多个不同级别), 先进行测试是个不错的主意(如果使用 Privileged 级别,则可略过此步骤)。 Pod 安全性包含若干工具可用来测试和安全地推出安全性配置。
首先,你可以试运行新策略,这个过程可以针对所应用的策略评估当前在名字空间中运行的 Pod,但不会令新策略马上生效:
# $LEVEL 是要试运行的级别,可以是 "baseline" 或 "restricted"
kubectl label --dry-run=server --overwrite ns $NAMESPACE pod-security.kubernetes.io/enforce=$LEVEL
此命令会针对在所提议的级别下不再合法的所有 现存 Pod 返回警告信息。
第二种办法在抓取当前未运行的负载方面表现的更好:audit 模式。 运行于 audit 模式(而非 enforcing 模式)下时,违反策略级别的 Pod 会被记录到审计日志中, 经过一段时间后可以在日志中查看到,但这些 Pod 不会被拒绝。 warning 模式的工作方式与此类似,不过会立即向用户返回告警信息。 你可以使用下面的命令为名字空间设置 audit 模式的级别:
kubectl label --overwrite ns $NAMESPACE pod-security.kubernetes.io/audit=$LEVEL
当以上两种方法输出意料之外的违例状况时,你就需要或者更新发生违例的负载以满足策略需求, 或者放宽名字空间上的 Pod 安全性级别。
当你对可以安全地在名字空间上实施的级别比较满意时,你可以更新名字空间来实施所期望的级别:
kubectl label --overwrite ns $NAMESPACE pod-security.kubernetes.io/enforce=$LEVEL
最后,你可以通过将 完全特权的 PSP 绑定到某名字空间中所有服务账户上,在名字空间层面绕过所有 PodSecurityPolicy。
# 下面集群范围的命令只需要执行一次
kubectl apply -f privileged-psp.yaml
kubectl create clusterrole privileged-psp --verb use --resource podsecuritypolicies.policy --resource-name privileged
# 逐个名字空间地禁用
kubectl create -n $NAMESPACE rolebinding disable-psp --clusterrole privileged-psp --group system:serviceaccounts:$NAMESPACE
由于特权 PSP 是非变更性的,PSP 准入控制器总是优选非变更性的 PSP, 上面的操作会确保对应名字空间中的所有 Pod 不再会被 PodSecurityPolicy 所更改或限制。
按上述操作逐个名字空间地禁用 PodSecurityPolicy 这种做法的好处是, 如果出现问题,你可以很方便地通过删除 RoleBinding 来回滚所作的更改。 你所要做的只是确保之前存在的 PodSecurityPolicy 还在。
# 撤销 PodSecurityPolicy 的禁用
kubectl delete -n $NAMESPACE rolebinding disable-psp
现在,现有的名字空间都已被更新,强制实施 Pod 安全性准入, 你应该确保你用来管控新名字空间创建的流程与/或策略也被更新,这样合适的 Pod 安全性配置会被应用到新的名字空间上。
你也可以静态配置 Pod 安全性准入控制器,为尚未打标签的名字空间设置默认的 enforce、audit 与/或 warn 级别。 详细信息可参阅配置准入控制器页面。
最后,你已为禁用 PodSecurityPolicy 做好准备。要禁用 PodSecurityPolicy, 你需要更改 API 服务器上的准入配置: 我如何关闭某个准入控制器?
如果需要验证 PodSecurityPolicy 准入控制器不再被启用,你可以通过扮演某个无法访问任何 PodSecurityPolicy 的用户来执行测试(参见 PodSecurityPolicy 示例), 或者通过检查 API 服务器的日志来进行验证。在启动期间,API 服务器会输出日志行,列举所挂载的准入控制器插件。
I0218 00:59:44.903329 13 plugins.go:158] Loaded 16 mutating admission controller(s) successfully in the following order: NamespaceLifecycle,LimitRanger,ServiceAccount,NodeRestriction,TaintNodesByCondition,Priority,DefaultTolerationSeconds,ExtendedResourceToleration,PersistentVolumeLabel,DefaultStorageClass,StorageObjectInUseProtection,RuntimeClass,DefaultIngressClass,MutatingAdmissionWebhook.
I0218 00:59:44.903350 13 plugins.go:161] Loaded 14 validating admission controller(s) successfully in the following order: LimitRanger,ServiceAccount,PodSecurity,Priority,PersistentVolumeClaimResize,RuntimeClass,CertificateApproval,CertificateSigning,CertificateSubjectRestriction,DenyServiceExternalIPs,ValidatingAdmissionWebhook,ResourceQuota.
你应该会看到 PodSecurity(在 validating admission controllers 列表中),
并且两个列表中都不应该包含 PodSecurityPolicy。
一旦你确定 PSP 准入控制器已被禁用(并且这种状况已经持续了一段时间, 这样你才会比较确定不需要回滚),你就可以放心地删除你的 PodSecurityPolicy 以及所关联的所有 Role、ClusterRole、RoleBinding、ClusterRoleBinding 等对象 (仅需要确保他们不再授予其他不相关的访问权限)。
有时候事情会出错。本指南旨在解决这些问题。它包含两个部分:
你也应该查看所用发行版本的已知问题。
如果你的问题在上述指南中没有得到答案,你还有另外几种方式从 Kubernetes 团队获得帮助。
本网站上的文档针对回答各类问题进行了结构化组织和分类。
概念部分解释 Kubernetes 体系结构以及每个组件的工作方式,
安装部分提供了安装的实用说明。
任务部分展示了如何完成常用任务,
教程部分则提供对现实世界、特定行业或端到端开发场景的更全面的演练。
参考部分提供了详细的
Kubernetes API 文档
和命令行 (CLI) 接口的文档,例如kubectl。
若你对容器化应用有软件开发相关的疑问,你可以在 Stack Overflow 上询问。
若你有集群管理或配置相关的疑问,你可以在 Server Fault 上询问。
还有几个更专业的 Stack Exchange 网站,很适合在这些地方询问有关 DevOps、 软件工程或信息安全 (InfoSec) 领域中 Kubernetes 的问题。
社区中的其他人可能已经问过和你类似的问题,也可能能够帮助解决你的问题。
Kubernetes 团队还会监视带有 Kubernetes 标签的帖子。 如果现有的问题对你没有帮助,请在问一个新问题之前,确保你的问题切合 Stack Overflow、 Server Fault 或 Stack Exchange 的主题, 并通读如何提出新问题的指导说明!
Kubernetes 社区中有很多人在 #kubernetes-users 这一 Slack 频道聚集。
Slack 需要注册;你可以请求一份邀请,
并且注册是对所有人开放的。欢迎你随时来问任何问题。
一旦注册了,就可以访问通过 Web 浏览器或者 Slack 专用的应用访问
Slack 上的 Kubernetes 组织。
一旦你完成了注册,就可以浏览各种感兴趣主题的频道列表(一直在增长)。
例如,Kubernetes 新人可能还想加入
#kubernetes-novice
频道。又比如,开发人员应该加入
#kubernetes-contributors
频道。
还有许多国家/地区语言频道。请随时加入这些频道以获得本地化支持和信息:
| 国家 | 频道 |
|---|---|
| 中国 | #cn-users, #cn-events |
| 芬兰 | #fi-users |
| 法国 | #fr-users, #fr-events |
| 德国 | #de-users, #de-events |
| 印度 | #in-users, #in-events |
| 意大利 | #it-users, #it-events |
| 日本 | #jp-users, #jp-events |
| 韩国 | #kr-users |
| 荷兰 | #nl-users |
| 挪威 | #norw-users |
| 波兰 | #pl-users |
| 俄罗斯 | #ru-users |
| 西班牙 | #es-users |
| 瑞典 | #se-users |
| 土耳其 | #tr-users, #tr-events |
欢迎你加入 Kubernetes 官方论坛 discuss.kubernetes.io。
如果你发现一个看起来像 Bug 的问题,或者你想提出一个功能请求,请使用 GitHub 问题跟踪系统。
在提交问题之前,请搜索现有问题列表以查看是否其中已涵盖你的问题。
如果提交 Bug,请提供如何重现问题的详细信息,例如:
kubectl version本篇文档是介绍集群故障排查的;我们假设对于你碰到的问题,你已经排除了是由应用程序造成的。 对于应用的调试,请参阅应用故障排查指南。 你也可以访问故障排查来获取更多的信息。
有关 kubectl 的故障排查, 请参阅 kubectl 故障排查。
调试的第一步是查看所有的节点是否都已正确注册。
运行以下命令:
kubectl get nodes
验证你所希望看见的所有节点都能够显示出来,并且都处于 Ready 状态。
为了了解你的集群的总体健康状况详情,你可以运行:
kubectl cluster-info dump
有时在调试时查看节点的状态很有用 —— 例如,因为你注意到在节点上运行的 Pod 的奇怪行为,
或者找出为什么 Pod 不会调度到节点上。与 Pod 一样,你可以使用 kubectl describe node
和 kubectl get node -o yaml 来检索有关节点的详细信息。
例如,如果节点关闭(与网络断开连接,或者 kubelet 进程挂起并且不会重新启动等),
你将看到以下内容。请注意显示节点为 NotReady 的事件,并注意 Pod 不再运行(它们在 NotReady 状态五分钟后被驱逐)。
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-worker-1 NotReady <none> 1h v1.23.3
kubernetes-node-bols Ready <none> 1h v1.23.3
kubernetes-node-st6x Ready <none> 1h v1.23.3
kubernetes-node-unaj Ready <none> 1h v1.23.3
kubectl describe node kube-worker-1
Name: kube-worker-1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=kube-worker-1
kubernetes.io/os=linux
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 17 Feb 2022 16:46:30 -0500
Taints: node.kubernetes.io/unreachable:NoExecute
node.kubernetes.io/unreachable:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: kube-worker-1
AcquireTime: <unset>
RenewTime: Thu, 17 Feb 2022 17:13:09 -0500
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 17 Feb 2022 17:09:13 -0500 Thu, 17 Feb 2022 17:09:13 -0500 WeaveIsUp Weave pod has set this
MemoryPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
DiskPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
PIDPressure Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Ready Unknown Thu, 17 Feb 2022 17:12:40 -0500 Thu, 17 Feb 2022 17:13:52 -0500 NodeStatusUnknown Kubelet stopped posting node status.
Addresses:
InternalIP: 192.168.0.113
Hostname: kube-worker-1
Capacity:
cpu: 2
ephemeral-storage: 15372232Ki
hugepages-2Mi: 0
memory: 2025188Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 14167048988
hugepages-2Mi: 0
memory: 1922788Ki
pods: 110
System Info:
Machine ID: 9384e2927f544209b5d7b67474bbf92b
System UUID: aa829ca9-73d7-064d-9019-df07404ad448
Boot ID: 5a295a03-aaca-4340-af20-1327fa5dab5c
Kernel Version: 5.13.0-28-generic
OS Image: Ubuntu 21.10
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.5.9
Kubelet Version: v1.23.3
Kube-Proxy Version: v1.23.3
Non-terminated Pods: (4 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
default nginx-deployment-67d4bdd6f5-cx2nz 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
default nginx-deployment-67d4bdd6f5-w6kd7 500m (25%) 500m (25%) 128Mi (6%) 128Mi (6%) 23m
kube-system kube-proxy-dnxbz 0 (0%) 0 (0%) 0 (0%) 0 (0%) 28m
kube-system weave-net-gjxxp 100m (5%) 0 (0%) 200Mi (10%) 0 (0%) 28m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1100m (55%) 1 (50%)
memory 456Mi (24%) 256Mi (13%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
...
kubectl get node kube-worker-1 -o yaml
apiVersion: v1
kind: Node
metadata:
annotations:
kubeadm.alpha.kubernetes.io/cri-socket: /run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: "0"
volumes.kubernetes.io/controller-managed-attach-detach: "true"
creationTimestamp: "2022-02-17T21:46:30Z"
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: kube-worker-1
kubernetes.io/os: linux
name: kube-worker-1
resourceVersion: "4026"
uid: 98efe7cb-2978-4a0b-842a-1a7bf12c05f8
spec: {}
status:
addresses:
- address: 192.168.0.113
type: InternalIP
- address: kube-worker-1
type: Hostname
allocatable:
cpu: "2"
ephemeral-storage: "14167048988"
hugepages-2Mi: "0"
memory: 1922788Ki
pods: "110"
capacity:
cpu: "2"
ephemeral-storage: 15372232Ki
hugepages-2Mi: "0"
memory: 2025188Ki
pods: "110"
conditions:
- lastHeartbeatTime: "2022-02-17T22:20:32Z"
lastTransitionTime: "2022-02-17T22:20:32Z"
message: Weave pod has set this
reason: WeaveIsUp
status: "False"
type: NetworkUnavailable
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:13:25Z"
message: kubelet has sufficient memory available
reason: KubeletHasSufficientMemory
status: "False"
type: MemoryPressure
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:13:25Z"
message: kubelet has no disk pressure
reason: KubeletHasNoDiskPressure
status: "False"
type: DiskPressure
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:13:25Z"
message: kubelet has sufficient PID available
reason: KubeletHasSufficientPID
status: "False"
type: PIDPressure
- lastHeartbeatTime: "2022-02-17T22:20:15Z"
lastTransitionTime: "2022-02-17T22:15:15Z"
message: kubelet is posting ready status. AppArmor enabled
reason: KubeletReady
status: "True"
type: Ready
daemonEndpoints:
kubeletEndpoint:
Port: 10250
nodeInfo:
architecture: amd64
bootID: 22333234-7a6b-44d4-9ce1-67e31dc7e369
containerRuntimeVersion: containerd://1.5.9
kernelVersion: 5.13.0-28-generic
kubeProxyVersion: v1.23.3
kubeletVersion: v1.23.3
machineID: 9384e2927f544209b5d7b67474bbf92b
operatingSystem: linux
osImage: Ubuntu 21.10
systemUUID: aa829ca9-73d7-064d-9019-df07404ad448
目前,深入挖掘集群需要登录相关机器。以下是相关日志文件的位置。
在基于 systemd 的系统上,你可能需要使用 journalctl 而不是检查日志文件。
/var/log/kube-apiserver.log —— API 服务器,负责提供 API 服务/var/log/kube-scheduler.log —— 调度器,负责制定调度决策/var/log/kube-controller-manager.log —— 运行大多数 Kubernetes
内置控制器的组件,除了调度(kube-scheduler 处理调度)。/var/log/kubelet.log —— 负责在节点运行容器的 kubelet 所产生的日志/var/log/kube-proxy.log —— 负责将流量转发到服务端点的 kube-proxy 所产生的日志这是可能出错的事情的不完整列表,以及如何调整集群设置以缓解问题。
措施:对于 IaaS 上的 VM,使用 IaaS 的自动 VM 重启功能
措施: 对于运行 API 服务器和 etcd 的 VM,使用 IaaS 提供的可靠的存储(例如 GCE PD 或者 AWS EBS 卷)
措施:使用高可用性的配置
措施:定期对 API 服务器的 PD 或 EBS 卷执行快照操作
措施:在 Pod 的前面使用副本控制器或服务
措施:应用(容器)设计成容许异常重启
kubectl debug node 调试 Kubernetes 节点crictl 来调试 Kubernetes 节点telepresence 本地开发和调试服务本文讲述研判和诊断 kubectl 相关的问题。
如果你在访问 kubectl 或连接到集群时遇到问题,本文概述了各种常见的情况和可能的解决方案,
以帮助确定和解决可能的原因。
kubectl,参见安装工具。确保你已在本机上正确安装和配置了 kubectl。
检查 kubectl 版本以确保其是最新的,并与你的集群兼容。
检查 kubectl 版本:
kubectl version
你将看到类似的输出:
Client Version: version.Info{Major:"1", Minor:"27", GitVersion:"v1.27.4",GitCommit:"fa3d7990104d7c1f16943a67f11b154b71f6a132", GitTreeState:"clean",BuildDate:"2023-07-19T12:20:54Z", GoVersion:"go1.20.6", Compiler:"gc", Platform:"linux/amd64"}
Kustomize Version: v5.0.1
Server Version: version.Info{Major:"1", Minor:"27", GitVersion:"v1.27.3",GitCommit:"25b4e43193bcda6c7328a6d147b1fb73a33f1598", GitTreeState:"clean",BuildDate:"2023-06-14T09:47:40Z", GoVersion:"go1.20.5", Compiler:"gc", Platform:"linux/amd64"}
如果你看到 Unable to connect to the server: dial tcp <server-ip>:8443: i/o timeout,
而不是 Server Version,则需要解决 kubectl 与你集群的连接问题。
确保按照 kubectl 官方安装文档安装了 kubectl,
并正确配置了 $PATH 环境变量。
kubectl 需要一个 kubeconfig 文件来连接到 Kubernetes 集群。
kubeconfig 文件通常位于 ~/.kube/config 目录下。确保你有一个有效的 kubeconfig 文件。
如果你没有 kubeconfig 文件,可以从 Kubernetes 管理员那里获取,或者可以从 Kubernetes 控制平面的
/etc/kubernetes/admin.conf 目录复制这个文件。如果你在云平台上部署了 Kubernetes 集群并且丢失了你的
kubeconfig 文件,则可以使用云厂商的工具重新生成它。参考云厂商的文档以重新生成 kubeconfig 文件。
检查 $KUBECONFIG 环境变量是否配置正确。你可以设置 $KUBECONFIG 环境变量,或者在
kubectl 中使用 --kubeconfig 参数来指定 kubeconfig 文件的目录。
如果你正在使用虚拟专用网络(VPN)访问 Kubernetes 集群,请确保你的 VPN 连接是可用且稳定的。 有时,VPN 断开连接可能会导致与集群的连接问题。重新连接到 VPN,并尝试再次访问集群。
如果你正在使用基于令牌的身份认证,并且 kubectl 返回有关身份认证令牌或身份认证服务器地址的错误, 校验 Kubernetes 身份认证令牌和身份认证服务器地址是否被配置正确。
如果 kubectl 返回有关鉴权的错误,确保你正在使用有效的用户凭据,并且你具有访问所请求资源的权限。
Kubernetes 支持多个集群和上下文。 确保你正在使用正确的上下文与集群进行交互。
列出可用的上下文:
kubectl config get-contexts
切换到合适的上下文:
kubectl config use-context <context-name>
kube-apiserver 服务器是 Kubernetes 集群的核心组件。如果 API 服务器或运行在 API 服务器前面的负载均衡器不可达或没有响应,你将无法与集群进行交互。
通过使用 ping 命令检查 API 服务器的主机是否可达。检查集群的网络连接和防火墙。
如果你使用云厂商部署集群,请检查云厂商对集群的 API 服务器的健康检查状态。
验证负载均衡器(如果使用)的状态,确保其健康且转发流量到 API 服务器。
Kubernetes API 服务器默认只为 HTTPS 请求提供服务。在这种情况下, TLS 问题可能会因各种原因而出现,例如证书过期或信任链有效性。
你可以在 kubeconfig 文件中找到 TLS 证书,此文件位于 ~/.kube/config 目录下。
certificate-authority 属性包含 CA 证书,而 client-certificate 属性则包含客户端证书。
验证这些证书的到期时间:
openssl x509 -noout -dates -in $(kubectl config view --minify --output 'jsonpath={.clusters[0].cluster.certificate-authority}')
输出为:
notBefore=Sep 2 08:34:12 2023 GMT
notAfter=Aug 31 08:34:12 2033 GMT
openssl x509 -noout -dates -in $(kubectl config view --minify --output 'jsonpath={.users[0].user.client-certificate}')
输出为:
notBefore=Sep 2 08:34:12 2023 GMT
notAfter=Sep 2 08:34:12 2026 GMT
某些 kubectl 身份认证助手提供了便捷访问 Kubernetes 集群的方式。 如果你使用了这些助手并且遇到连接问题,确保必要的配置仍然存在。
查看 kubectl 配置以了解身份认证细节:
kubectl config view
如果你之前使用了辅助工具(例如 kubectl-oidc-login),确保它仍然安装和配置正确。
要扩展应用程序并提供可靠的服务,你需要了解应用程序在部署时的行为。 你可以通过检测容器、Pod、 Service 和整个集群的特征来检查 Kubernetes 集群中应用程序的性能。 Kubernetes 在每个级别上提供有关应用程序资源使用情况的详细信息。 此信息使你可以评估应用程序的性能,以及在何处可以消除瓶颈以提高整体性能。
在 Kubernetes 中,应用程序监控不依赖单个监控解决方案。在新集群上, 你可以使用资源度量或完整度量管道来收集监视统计信息。
资源指标管道提供了一组与集群组件,例如
Horizontal Pod Autoscaler
控制器以及 kubectl top 实用程序相关的有限度量。
这些指标是由轻量级的、短期、内存存储的
metrics-server 收集,
并通过 metrics.k8s.io 公开。
metrics-server 发现集群中的所有节点,并且查询每个节点的
kubelet
以获取 CPU 和内存使用情况。
kubelet 充当 Kubernetes 主节点与节点之间的桥梁,管理机器上运行的 Pod 和容器。
kubelet 将每个 Pod 转换为其组成的容器,并通过容器运行时接口从容器运行时获取各个容器使用情况统计信息。
如果某个容器运行时使用 Linux cgroups 和名字空间来实现容器。
并且这一容器运行时不发布资源用量统计信息,
那么 kubelet 可以直接查找这些统计信息(使用来自 cAdvisor 的代码)。
无论这些统计信息如何到达,kubelet 都会通过 metrics-server Resource Metrics API 公开聚合的
Pod 资源用量统计信息。
该 API 在 kubelet 的经过身份验证和只读的端口上的 /metrics/resource/v1beta1 中提供。
一个完整度量管道可以让你访问更丰富的度量。
Kubernetes 还可以根据集群的当前状态,使用 Pod 水平自动扩缩器等机制,
通过自动调用扩展或调整集群来响应这些度量。
监控管道从 kubelet 获取度量值,然后通过适配器将它们公开给 Kubernetes,
方法是实现 custom.metrics.k8s.io 或 external.metrics.k8s.io API。
Kubernetes 在设计上保证能够与 OpenMetrics 一同使用, OpenMetrics 是 CNCF 可观测性和分析 - 监控项目之一, 它构建于 Prometheus 暴露格式之上, 并对其进行了扩展,这些扩展几乎 100% 向后兼容。
如果你浏览 CNCF Landscape, 你可以看到许多监控项目,它们可以用在 Kubernetes 上,抓取指标数据并利用这些数据来观测你的集群, 选择哪种工具或哪些工具可以满足你的需求,这完全取决于你自己。 CNCF 的可观测性和分析景观包括了各种开源软件、付费的软件即服务(SaaS)以及其他混合商业产品。
当你设计和实现一个完整的指标监控数据管道时,你可以将监控数据反馈给 Kubernetes。 例如,HorizontalPodAutoscaler 可以使用处理过的指标数据来计算出你的工作负载组件运行了多少个 Pod。
将完整的指标管道集成到 Kubernetes 实现中超出了 Kubernetes 文档的范围,因为可能的解决方案具有非常广泛的范围。
监控平台的选择在很大程度上取决于你的需求、预算和技术资源。 Kubernetes 不推荐任何特定的指标管道; 可使用许多选项。 你的监控系统应能够处理 OpenMetrics 指标传输标准, 并且需要选择最适合基础设施平台的整体设计和部署。
了解其他调试工具,包括:
对于 Kubernetes,Metrics API 提供了一组基本的指标,以支持自动伸缩和类似的用例。 该 API 提供有关节点和 Pod 的资源使用情况的信息, 包括 CPU 和内存的指标。如果将 Metrics API 部署到集群中, 那么 Kubernetes API 的客户端就可以查询这些信息,并且可以使用 Kubernetes 的访问控制机制来管理权限。
HorizontalPodAutoscaler (HPA) 和 VerticalPodAutoscaler (VPA) 使用 metrics API 中的数据调整工作负载副本和资源,以满足客户需求。
你也可以通过 kubectl top 命令来查看资源指标。
Metrics API 及其启用的指标管道仅提供最少的 CPU 和内存指标,以启用使用 HPA 和/或 VPA 的自动扩展。 如果你想提供更完整的指标集,你可以通过部署使用 Custom Metrics API 的第二个指标管道来作为简单的 Metrics API 的补充。
图 1 说明了资源指标管道的架构。
图 1. 资源指标管道
图中从右到左的架构组件包括以下内容:
cAdvisor: 用于收集、聚合和公开 Kubelet 中包含的容器指标的守护程序。
kubelet: 用于管理容器资源的节点代理。
可以使用 /metrics/resource 和 /stats kubelet API 端点访问资源指标。
节点层面资源指标: kubelet 提供的 API,用于发现和检索可通过 /metrics/resource 端点获得的每个节点的汇总统计信息。
metrics-server: 集群插件组件,用于收集和聚合从每个 kubelet 中提取的资源指标。
API 服务器提供 Metrics API 以供 HPA、VPA 和 kubectl top 命令使用。Metrics Server 是 Metrics API 的参考实现。
Metrics API: Kubernetes API 支持访问用于工作负载自动缩放的 CPU 和内存。 要在你的集群中进行这项工作,你需要一个提供 Metrics API 的 API 扩展服务器。
Kubernetes 1.8 [beta]
metrics-server 实现了 Metrics API。此 API 允许你访问集群中节点和 Pod 的 CPU 和内存使用情况。 它的主要作用是将资源使用指标提供给 K8s 自动缩放器组件。
下面是一个 minikube 节点的 Metrics API 请求示例,通过 jq 管道处理以便于阅读:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes/minikube" | jq '.'
这是使用 curl 来执行的相同 API 调用:
curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/nodes/minikube
响应示例:
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "minikube",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/minikube",
"creationTimestamp": "2022-01-27T18:48:43Z"
},
"timestamp": "2022-01-27T18:48:33Z",
"window": "30s",
"usage": {
"cpu": "487558164n",
"memory": "732212Ki"
}
}
下面是一个 kube-system 命名空间中的 kube-scheduler-minikube Pod 的 Metrics API 请求示例,
通过 jq 管道处理以便于阅读:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube" | jq '.'
这是使用 curl 来完成的相同 API 调用:
curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube
响应示例:
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "kube-scheduler-minikube",
"namespace": "kube-system",
"selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube",
"creationTimestamp": "2022-01-27T19:25:00Z"
},
"timestamp": "2022-01-27T19:24:31Z",
"window": "30s",
"containers": [
{
"name": "kube-scheduler",
"usage": {
"cpu": "9559630n",
"memory": "22244Ki"
}
}
]
}
Metrics API 在 k8s.io/metrics 代码库中定义。
你必须启用 API 聚合层并为
metrics.k8s.io API 注册一个 APIService。
要了解有关 Metrics API 的更多信息, 请参阅资源 Resource Metrics API Design、 metrics-server 代码库 和 Resource Metrics API。
你必须部署提供 Metrics API 服务的 metrics-server 或其他适配器才能访问它。
CPU 报告为以 cpu 为单位测量的平均核心使用率。在 Kubernetes 中, 一个 cpu 相当于云提供商的 1 个 vCPU/Core,以及裸机 Intel 处理器上的 1 个超线程。
该值是通过对内核提供的累积 CPU 计数器(在 Linux 和 Windows 内核中)取一个速率得出的。 用于计算 CPU 的时间窗口显示在 Metrics API 的窗口字段下。
要了解更多关于 Kubernetes 如何分配和测量 CPU 资源的信息,请参阅 CPU 的含义。
内存报告为在收集度量标准的那一刻的工作集大小,以字节为单位。
在理想情况下,“工作集”是在内存压力下无法释放的正在使用的内存量。 然而,工作集的计算因主机操作系统而异,并且通常大量使用启发式算法来产生估计。
Kubernetes 模型中,容器工作集是由容器运行时计算的与相关容器关联的匿名内存。 工作集指标通常还包括一些缓存(文件支持)内存,因为主机操作系统不能总是回收页面。
要了解有关 Kubernetes 如何分配和测量内存资源的更多信息, 请参阅内存的含义。
metrics-server 从 kubelet 中获取资源指标,并通过 Metrics API 在 Kubernetes API 服务器中公开它们,以供 HPA 和 VPA 使用。
你还可以使用 kubectl top 命令查看这些指标。
metrics-server 使用 Kubernetes API 来跟踪集群中的节点和 Pod。metrics-server 服务器通过 HTTP 查询每个节点以获取指标。 metrics-server 还构建了 Pod 元数据的内部视图,并维护 Pod 健康状况的缓存。 缓存的 Pod 健康信息可通过 metrics-server 提供的扩展 API 获得。
例如,对于 HPA 查询,metrics-server 需要确定哪些 Pod 满足 Deployment 中的标签选择器。
metrics-server 调用 kubelet API 从每个节点收集指标。根据它使用的 metrics-server 版本:
/metrics/resource/stats/summary了解更多 metrics-server,参阅 metrics-server 代码库。
你还可以查看以下内容:
若要了解 kubelet 如何提供节点指标以及你可以如何通过 Kubernetes API 访问这些指标, 请阅读节点指标数据。
节点问题检测器(Node Problem Detector) 是一个守护程序,用于监视和报告节点的健康状况。
你可以将节点问题探测器以 DaemonSet 或独立守护程序运行。
节点问题检测器从各种守护进程收集节点问题,并以节点
Condition 和
Event
的形式报告给 API 服务器。
要了解如何安装和使用节点问题检测器,请参阅 节点问题探测器项目文档。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
一些云供应商将节点问题检测器以插件形式启用。
你还可以使用 kubectl 或创建插件 DaemonSet 来启用节点问题探测器。
kubectl 提供了节点问题探测器最灵活的管理。
你可以覆盖默认配置使其适合你的环境或检测自定义节点问题。例如:
创建类似于 node-strought-detector.yaml 的节点问题检测器配置:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-problem-detector-v0.1
namespace: kube-system
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
hostNetwork: true
containers:
- name: node-problem-detector
image: registry.k8s.io/node-problem-detector:v0.1
securityContext:
privileged: true
resources:
limits:
cpu: "200m"
memory: "100Mi"
requests:
cpu: "20m"
memory: "20Mi"
volumeMounts:
- name: log
mountPath: /log
readOnly: true
volumes:
- name: log
hostPath:
path: /var/log/使用 kubectl 启动节点问题检测器:
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector.yaml
如果你使用的是自定义集群引导解决方案,不需要覆盖默认配置, 可以利用插件 Pod 进一步自动化部署。
创建 node-strick-detector.yaml,并在控制平面节点上保存配置到插件 Pod 的目录
/etc/kubernetes/addons/node-problem-detector。
构建节点问题检测器的 docker 镜像时,会嵌入 默认配置。
不过,你可以像下面这样使用 ConfigMap
将其覆盖:
更改 config/ 中的配置文件
创建 ConfigMap node-strick-detector-config:
kubectl create configmap node-problem-detector-config --from-file=config/
更改 node-problem-detector.yaml 以使用 ConfigMap:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-problem-detector-v0.1
namespace: kube-system
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
k8s-app: node-problem-detector
version: v0.1
kubernetes.io/cluster-service: "true"
spec:
hostNetwork: true
containers:
- name: node-problem-detector
image: registry.k8s.io/node-problem-detector:v0.1
securityContext:
privileged: true
resources:
limits:
cpu: "200m"
memory: "100Mi"
requests:
cpu: "20m"
memory: "20Mi"
volumeMounts:
- name: log
mountPath: /log
readOnly: true
- name: config # 使用 ConfigMap 卷中的数据覆盖 config/ 目录内容
mountPath: /config
readOnly: true
volumes:
- name: log
hostPath:
path: /var/log/
- name: config # 定义 ConfigMap 卷
configMap:
name: node-problem-detector-config使用新的配置文件重新创建节点问题检测器:
# 如果你正在运行节点问题检测器,请先删除,然后再重新创建
kubectl delete -f https://k8s.io/examples/debug/node-problem-detector.yaml
kubectl apply -f https://k8s.io/examples/debug/node-problem-detector-configmap.yaml
kubectl 启动的节点问题检测器。
如果节点问题检测器作为集群插件运行,则不支持覆盖配置。
插件管理器不支持 ConfigMap。
问题守护程序是节点问题检测器的子守护程序。 它监视特定类型的节点问题并报告给节点问题检测器。 支持下面几种类型的问题守护程序。
SystemLogMonitor 类型的守护程序根据预定义的规则监视系统日志并报告问题和指标。
你可以针对不同的日志源自定义配置如
filelog、
kmsg、
kernel、
abrt
和 systemd。SystemStatsMonitor 类型的守护程序收集各种与健康相关的系统统计数据作为指标。
你可以通过更新其配置文件来自定义其行为。CustomPluginMonitor 类型的守护程序通过运行用户定义的脚本来调用和检查各种节点问题。
你可以使用不同的自定义插件监视器来监视不同的问题,并通过更新
配置文件
来定制守护程序行为。HealthChecker 类型的守护程序检查节点上的 kubelet 和容器运行时的健康状况。系统日志监视器目前支持基于文件的日志、journald 和 kmsg。 可以通过实现一个新的 log watcher 来添加额外的日志源。
你可以通过开发自定义插件来扩展节点问题检测器,以执行以任何语言编写的任何监控脚本。 监控脚本必须符合退出码和标准输出的插件协议。 有关更多信息,请参阅 插件接口提案.
导出器(Exporter)向特定后端报告节点问题和/或指标。 支持下列导出器:
Kubernetes exporter:此导出器向 Kubernetes API 服务器报告节点问题。 临时问题报告为事件,永久性问题报告为节点状况。
Prometheus exporter:此导出器在本地将节点问题和指标报告为 Prometheus(或 OpenMetrics)指标。 你可以使用命令行参数指定导出器的 IP 地址和端口。
Stackdriver exporter:此导出器向 Stackdriver Monitoring API 报告节点问题和指标。 可以使用配置文件自定义导出行为。
建议在集群中运行节点问题检测器以监控节点运行状况。 运行节点问题检测器时,你可以预期每个节点上的额外资源开销。 通常这是可接受的,因为:
Kubernetes v1.11 [stable]
crictl 是 CRI 兼容的容器运行时命令行接口。
你可以使用它来检查和调试 Kubernetes 节点上的容器运行时和应用程序。
crictl 和它的源代码在
cri-tools 代码库。
crictl 需要带有 CRI 运行时的 Linux 操作系统。
你可以从 cri-tools 发布页面
下载一个压缩的 crictl 归档文件,用于几种不同的架构。
下载与你的 kubernetes 版本相对应的版本。
提取它并将其移动到系统路径上的某个位置,例如 /usr/local/bin/。
crictl 命令有几个子命令和运行时参数。
有关详细信息,请使用 crictl help 或 crictl <subcommand> help 获取帮助信息。
你可以用以下方法之一来为 crictl 设置端点:
--runtime-endpoint 和 --image-endpoint。CONTAINER_RUNTIME_ENDPOINT 和 IMAGE_SERVICE_ENDPOINT。--config=/etc/crictl.yaml 中设置端点。
要设置不同的文件,可以在运行 crictl 时使用 --config=PATH_TO_FILE 标志。如果你不设置端点,crictl 将尝试连接到已知端点的列表,这可能会影响性能。
你还可以在连接到服务器并启用或禁用调试时指定超时值,方法是在配置文件中指定
timeout 或 debug 值,或者使用 --timeout 和 --debug 命令行参数。
要查看或编辑当前配置,请查看或编辑 /etc/crictl.yaml 的内容。
例如,使用 containerd 容器运行时的配置会类似于这样:
runtime-endpoint: unix:///var/run/containerd/containerd.sock
image-endpoint: unix:///var/run/containerd/containerd.sock
timeout: 10
debug: true
要进一步了解 crictl,参阅
crictl 文档。
如果使用 crictl 在正在运行的 Kubernetes 集群上创建 Pod 沙盒或容器,
kubelet 最终将删除它们。
crictl 不是一个通用的工作流工具,而是一个对调试有用的工具。
打印所有 Pod 的清单:
crictl pods
输出类似于:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
926f1b5a1d33a About a minute ago Ready sh-84d7dcf559-4r2gq default 0
4dccb216c4adb About a minute ago Ready nginx-65899c769f-wv2gp default 0
a86316e96fa89 17 hours ago Ready kube-proxy-gblk4 kube-system 0
919630b8f81f1 17 hours ago Ready nvidia-device-plugin-zgbbv kube-system 0
根据名称打印 Pod 清单:
crictl pods --name nginx-65899c769f-wv2gp
输出类似于这样:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
根据标签打印 Pod 清单:
crictl pods --label run=nginx
输出类似于这样:
POD ID CREATED STATE NAME NAMESPACE ATTEMPT
4dccb216c4adb 2 minutes ago Ready nginx-65899c769f-wv2gp default 0
打印所有镜像清单:
crictl images
输出类似于这样:
IMAGE TAG IMAGE ID SIZE
busybox latest 8c811b4aec35f 1.15MB
k8s-gcrio.azureedge.net/hyperkube-amd64 v1.10.3 e179bbfe5d238 665MB
k8s-gcrio.azureedge.net/pause-amd64 3.1 da86e6ba6ca19 742kB
nginx latest cd5239a0906a6 109MB
根据仓库打印镜像清单:
crictl images nginx
输出类似于这样:
IMAGE TAG IMAGE ID SIZE
nginx latest cd5239a0906a6 109MB
只打印镜像 ID:
crictl images -q
输出类似于这样:
sha256:8c811b4aec35f259572d0f79207bc0678df4c736eeec50bc9fec37ed936a472a
sha256:e179bbfe5d238de6069f3b03fccbecc3fb4f2019af741bfff1233c4d7b2970c5
sha256:da86e6ba6ca197bf6bc5e9d900febd906b133eaa4750e6bed647b0fbe50ed43e
sha256:cd5239a0906a6ccf0562354852fae04bc5b52d72a2aff9a871ddb6bd57553569
打印所有容器清单:
crictl ps -a
输出类似于这样:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 7 minutes ago Running sh 1
9c5951df22c78 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 8 minutes ago Exited sh 0
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 8 minutes ago Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 18 hours ago Running kube-proxy 0
打印正在运行的容器清单:
crictl ps
输出类似于这样:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
1f73f2d81bf98 busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47 6 minutes ago Running sh 1
87d3992f84f74 nginx@sha256:d0a8828cccb73397acb0073bf34f4d7d8aa315263f1e7806bf8c55d8ac139d5f 7 minutes ago Running nginx 0
1941fb4da154f k8s-gcrio.azureedge.net/hyperkube-amd64@sha256:00d814b1f7763f4ab5be80c58e98140dfc69df107f253d7fdd714b30a714260a 17 hours ago Running kube-proxy 0
crictl exec -i -t 1f73f2d81bf98 ls
输出类似于这样:
bin dev etc home proc root sys tmp usr var
获取容器的所有日志:
crictl logs 87d3992f84f74
输出类似于这样:
10.240.0.96 - - [06/Jun/2018:02:45:49 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.96 - - [06/Jun/2018:02:45:50 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
10.240.0.96 - - [06/Jun/2018:02:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
获取最近的 N 行日志:
crictl logs --tail=1 87d3992f84f74
输出类似于这样:
10.240.0.96 - - [06/Jun/2018:02:45:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.47.0" "-"
用 crictl 运行 Pod 沙盒对容器运行时排错很有帮助。
在运行的 Kubernetes 集群中,沙盒会随机地被 kubelet 停止和删除。
编写下面的 JSON 文件:
{
"metadata": {
"name": "nginx-sandbox",
"namespace": "default",
"attempt": 1,
"uid": "hdishd83djaidwnduwk28bcsb"
},
"log_directory": "/tmp",
"linux": {
}
}
使用 crictl runp 命令应用 JSON 文件并运行沙盒。
crictl runp pod-config.json
返回了沙盒的 ID。
用 crictl 创建容器对容器运行时排错很有帮助。
在运行的 Kubernetes 集群中,容器最终将被 kubelet 停止和删除。
拉取 busybox 镜像
crictl pull busybox
Image is up to date for busybox@sha256:141c253bc4c3fd0a201d32dc1f493bcf3fff003b6df416dea4f41046e0f37d47
创建 Pod 和容器的配置:
Pod 配置:
{
"metadata": {
"name": "busybox-sandbox",
"namespace": "default",
"attempt": 1,
"uid": "aewi4aeThua7ooShohbo1phoj"
},
"log_directory": "/tmp",
"linux": {
}
}
容器配置:
{
"metadata": {
"name": "busybox"
},
"image":{
"image": "busybox"
},
"command": [
"top"
],
"log_path":"busybox.log",
"linux": {
}
}
创建容器,传递先前创建的 Pod 的 ID、容器配置文件和 Pod 配置文件。返回容器的 ID。
crictl create f84dd361f8dc51518ed291fbadd6db537b0496536c1d2d6c05ff943ce8c9a54f container-config.json pod-config.json
查询所有容器并确认新创建的容器状态为 Created。
crictl ps -a
输出类似于这样:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
3e025dd50a72d busybox 32 seconds ago Created busybox 0
要启动容器,要将容器 ID 传给 crictl start:
crictl start 3e025dd50a72d956c4f14881fbb5b1080c9275674e95fb67f965f6478a957d60
输出类似于这样:
3e025dd50a72d956c4f14881fbb5b1080c9275674e95fb67f965f6478a957d60
确认容器的状态为 Running。
crictl ps
输出类似于这样:
CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT
3e025dd50a72d busybox About a minute ago Running busybox 0
我的 Pod 都卡在 “Container Creating” 或者不断重启
确保你的 pause 镜像跟你的 Windows 版本兼容。 查看 Pause 容器 以了解最新的或建议的 pause 镜像,或者了解更多信息。
如果你在使用 containerd 作为你的容器运行时,那么 pause 镜像在 config.toml 配置文件的
plugins.plugins.cri.sandbox_image 中指定。
我的 Pod 状态显示 'ErrImgPull' 或者 'ImagePullBackOff'
保证你的 Pod 被调度到兼容的 Windows 节点上。
关于如何为你的 Pod 指定一个兼容节点, 可以查看这个指可以查看这个指南 以了解更多的信息。
我的 Windows Pod 没有网络连接
如果你使用的是虚拟机,请确保所有 VM 网卡上都已启用 MAC spoofing。
我的 Windows Pod 不能 ping 通外界资源
Windows Pod 没有为 ICMP 协议编写出站规则,但 TCP/UDP 是支持的。当试图演示与集群外部资源的连接时,
可以把 ping <IP> 替换为 curl <IP> 命令。
如果你仍然遇到问题,很可能你需要额外关注 cni.conf 的配置。你可以随时编辑这个静态文件。更新配置将应用于新的 Kubernetes 资源。
Kubernetes 的网络需求之一(查看 Kubernetes 模型)
是集群通信不需要内部的 NAT。
为了遵守这一要求,对于你不希望发生的出站 NAT 通信,这里有一个
ExceptionList。
然而,这也意味着你需要从 ExceptionList 中去掉你试图查询的外部 IP。
只有这样,来自你的 Windows Pod 的流量才会被正确地 SNAT 转换,以接收来自外部环境的响应。
就此而言,你的 cni.conf 中的 ExceptionList 应该如下所示:
"ExceptionList": [
"10.244.0.0/16", # 集群子网
"10.96.0.0/12", # 服务子网
"10.127.130.0/24" # 管理(主机)子网
]
我的 Windows 节点无法访问 NodePort 类型 Service
从节点本身访问本地 NodePort 失败,是一个已知的限制。 你可以从其他节点或外部客户端正常访问 NodePort。
容器的 vNIC 和 HNS 端点正在被删除
当 hostname-override 参数没有传递给
kube-proxy
时可能引发这一问题。想要解决这个问题,用户需要将主机名传递给 kube-proxy,如下所示:
C:\k\kube-proxy.exe --hostname-override=$(hostname)
我的 Windows 节点无法通过服务 IP 访问我的服务
这是 Windows 上网络栈的一个已知限制。但是 Windows Pod 可以访问 Service IP。
启动 kubelet 时找不到网络适配器
Windows 网络栈需要一个虚拟适配器才能使 Kubernetes 网络工作。 如果以下命令没有返回结果(在管理员模式的 shell 中), 则意味着创建虚拟网络失败,而虚拟网络的存在是 kubelet 正常工作的前提:
Get-HnsNetwork | ? Name -ieq "cbr0"
Get-NetAdapter | ? Name -Like "vEthernet (Ethernet*"
如果主机的网络适配器不是 "Ethernet",通常有必要修改 start.ps1 脚本的
InterfaceName
参数。否则,如果虚拟网络创建过程出错,请检查 start-kubelet.ps1 脚本的输出。
DNS 解析工作异常
查阅这一节了解 Windows 系统上的 DNS 限制。
kubectl port-forward 失败,错误为 "unable to do port forwarding: wincat not found"
在 Kubernetes 1.15 中,pause 基础架构容器 mcr.microsoft.com/oss/kubernetes/pause:3.6
中包含 wincat.exe 来实现端口转发。
请确保使用 Kubernetes 的受支持版本。如果你想构建自己的 pause 基础架构容器,
请确保其中包含 wincat。
我的 Kubernetes 安装失败,因为我的 Windows 服务器节点使用了代理服务器
如果使用了代理服务器,必须定义下面的 PowerShell 环境变量:
[Environment]::SetEnvironmentVariable("HTTP_PROXY", "http://proxy.example.com:80/", [EnvironmentVariableTarget]::Machine)
[Environment]::SetEnvironmentVariable("HTTPS_PROXY", "http://proxy.example.com:443/", [EnvironmentVariableTarget]::Machine)
使用 Flannel 时,我的节点在重新加入集群后出现问题
当先前删除的节点重新加入集群时, flannelD 尝试为节点分配一个新的 Pod 子网。 用户应该在以下路径中删除旧的 Pod 子网配置文件:
Remove-Item C:\k\SourceVip.json
Remove-Item C:\k\SourceVipRequest.json
Flanneld 卡在 "Waiting for the Network to be created"
关于这个问题有很多报告;
很可能是 Flannel 网络管理 IP 的设置时机问题。
一个变通方法是重新启动 start.ps1 或按如下方式手动重启:
[Environment]::SetEnvironmentVariable("NODE_NAME", "<Windows 工作节点主机名>")
C:\flannel\flanneld.exe --kubeconfig-file=c:\k\config --iface=<Windows 工作节点 IP> --ip-masq=1 --kube-subnet-mgr=1
我的 Windows Pod 无法启动,因为缺少 /run/flannel/subnet.env
这表明 Flannel 没有正确启动。你可以尝试重启 flanneld.exe 或者你可以将 Kubernetes 控制节点的
/run/flannel/subnet.env 文件手动拷贝到 Windows 工作节点上,放在 C:\run\flannel\subnet.env;
并且将 FLANNEL_SUBNET 行修改为不同取值。例如,如果期望节点子网为 10.244.4.1/24:
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.4.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=true
如果这些步骤都不能解决你的问题,你可以通过以下方式获得关于在 Kubernetes 中运行 Windows 容器的帮助:
Kubernetes 审计(Auditing) 功能提供了与安全相关的、按时间顺序排列的记录集, 记录每个用户、使用 Kubernetes API 的应用以及控制面自身引发的活动。
审计功能使得集群管理员能够回答以下问题:
审计记录最初产生于 kube-apiserver 内部。每个请求在不同执行阶段都会生成审计事件;这些审计事件会根据特定策略被预处理并写入后端。 策略确定要记录的内容和用来存储记录的后端,当前的后端支持日志文件和 webhook。
每个请求都可被记录其相关的阶段(stage)。已定义的阶段有:
RequestReceived - 此阶段对应审计处理器接收到请求后,
并且在委托给其余处理器之前生成的事件。ResponseStarted - 在响应消息的头部发送后,响应消息体发送前生成的事件。
只有长时间运行的请求(例如 watch)才会生成这个阶段。ResponseComplete - 当响应消息体完成并且没有更多数据需要传输的时候。Panic - 当 panic 发生时生成。审计日志记录功能会增加 API server 的内存消耗,因为需要为每个请求存储审计所需的某些上下文。 内存消耗取决于审计日志记录的配置。
审计策略定义了关于应记录哪些事件以及应包含哪些数据的规则。
审计策略对象结构定义在
audit.k8s.io API 组。
处理事件时,将按顺序与规则列表进行比较。第一个匹配规则设置事件的审计级别(Audit Level)。
已定义的审计级别有:
None - 符合这条规则的日志将不会记录。Metadata - 记录请求的元数据(请求的用户、时间戳、资源、动词等等),
但是不记录请求或者响应的消息体。Request - 记录事件的元数据和请求的消息体,但是不记录响应的消息体。
这不适用于非资源类型的请求。RequestResponse - 记录事件的元数据,请求和响应的消息体。这不适用于非资源类型的请求。你可以使用 --audit-policy-file 标志将包含策略的文件传递给 kube-apiserver。
如果不设置该标志,则不记录事件。
注意 rules 字段必须在审计策略文件中提供。没有(0)规则的策略将被视为非法配置。
以下是一个审计策略文件的示例:
apiVersion: audit.k8s.io/v1 # 这是必填项。
kind: Policy
# 不要在 RequestReceived 阶段为任何请求生成审计事件。
omitStages:
- "RequestReceived"
rules:
# 在日志中用 RequestResponse 级别记录 Pod 变化。
- level: RequestResponse
resources:
- group: ""
# 资源 "pods" 不匹配对任何 Pod 子资源的请求,
# 这与 RBAC 策略一致。
resources: ["pods"]
# 在日志中按 Metadata 级别记录 "pods/log"、"pods/status" 请求
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# 不要在日志中记录对名为 "controller-leader" 的 configmap 的请求。
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# 不要在日志中记录由 "system:kube-proxy" 发出的对端点或服务的监测请求。
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API 组
resources: ["endpoints", "services"]
# 不要在日志中记录对某些非资源 URL 路径的已认证请求。
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # 通配符匹配。
- "/version"
# 在日志中记录 kube-system 中 configmap 变更的请求消息体。
- level: Request
resources:
- group: "" # core API 组
resources: ["configmaps"]
# 这个规则仅适用于 "kube-system" 名字空间中的资源。
# 空字符串 "" 可用于选择非名字空间作用域的资源。
namespaces: ["kube-system"]
# 在日志中用 Metadata 级别记录所有其他名字空间中的 configmap 和 secret 变更。
- level: Metadata
resources:
- group: "" # core API 组
resources: ["secrets", "configmaps"]
# 在日志中以 Request 级别记录所有其他 core 和 extensions 组中的资源操作。
- level: Request
resources:
- group: "" # core API 组
- group: "extensions" # 不应包括在内的组版本。
# 一个抓取所有的规则,将在日志中以 Metadata 级别记录所有其他请求。
- level: Metadata
# 符合此规则的 watch 等长时间运行的请求将不会
# 在 RequestReceived 阶段生成审计事件。
omitStages:
- "RequestReceived"
你可以使用最低限度的审计策略文件在 Metadata 级别记录所有请求:
# 在 Metadata 级别为所有请求生成日志
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
- level: Metadata
如果你在打磨自己的审计配置文件,你可以使用为 Google Container-Optimized OS 设计的审计配置作为出发点。你可以参考 configure-helper.sh 脚本,该脚本能够生成审计策略文件。你可以直接在脚本中看到审计策略的绝大部份内容。
你也可以参考 Policy 配置参考
以获取有关已定义字段的详细信息。
审计后端实现将审计事件导出到外部存储。kube-apiserver 默认提供两个后端:
在这所有情况下,审计事件均遵循 Kubernetes API 在
audit.k8s.io API 组
中定义的结构。
对于 patch 请求,请求的消息体需要是设定 patch 操作的 JSON 所构成的一个串,
而不是一个完整的 Kubernetes API 对象的 JSON 串。
例如,以下的示例是一个合法的 patch 请求消息体,该请求对应
/apis/batch/v1/namespaces/some-namespace/jobs/some-job-name:
[
{
"op": "replace",
"path": "/spec/parallelism",
"value": 0
},
{
"op": "remove",
"path": "/spec/template/spec/containers/0/terminationMessagePolicy"
}
]
Log 后端将审计事件写入 JSONlines 格式的文件。
你可以使用以下 kube-apiserver 标志配置 Log 审计后端:
--audit-log-path 指定用来写入审计事件的日志文件路径。不指定此标志会禁用日志后端。- 意味着标准化--audit-log-maxage 定义保留旧审计日志文件的最大天数--audit-log-maxbackup 定义要保留的审计日志文件的最大数量--audit-log-maxsize 定义审计日志文件轮转之前的最大大小(兆字节)如果你的集群控制面以 Pod 的形式运行 kube-apiserver,记得要通过 hostPath
卷来访问策略文件和日志文件所在的目录,这样审计记录才会持久保存下来。例如:
- --audit-policy-file=/etc/kubernetes/audit-policy.yaml
- --audit-log-path=/var/log/kubernetes/audit/audit.log
接下来挂载数据卷:
...
volumeMounts:
- mountPath: /etc/kubernetes/audit-policy.yaml
name: audit
readOnly: true
- mountPath: /var/log/kubernetes/audit/
name: audit-log
readOnly: false
最后配置 hostPath:
...
volumes:
- name: audit
hostPath:
path: /etc/kubernetes/audit-policy.yaml
type: File
- name: audit-log
hostPath:
path: /var/log/kubernetes/audit/
type: DirectoryOrCreate
Webhook 后端将审计事件发送到远程 Web API,该远程 API 应该暴露与 kube-apiserver
形式相同的 API,包括其身份认证机制。你可以使用如下 kube-apiserver 标志来配置
Webhook 审计后端:
--audit-webhook-config-file 设置 Webhook 配置文件的路径。Webhook 配置文件实际上是一个
kubeconfig 文件。--audit-webhook-initial-backoff 指定在第一次失败后重发请求等待的时间。随后的请求将以指数退避重试。Webhook 配置文件使用 kubeconfig 格式指定服务的远程地址和用于连接它的凭据。
日志和 Webhook 后端都支持批处理。以 Webhook 为例,以下是可用参数列表。要获取日志
后端的同样参数,请在参数名称中将 webhook 替换为 log。
默认情况下,在 webhook 中批处理是被启用的,在 log 中批处理是被禁用的。
同样,默认情况下,在 webhook 中启用带宽限制,在 log 中禁用带宽限制。
--audit-webhook-mode 定义缓存策略,可选值如下:
batch - 以批处理缓存事件和异步的过程。这是默认值。blocking - 在 API 服务器处理每个单独事件时,阻塞其响应。blocking-strict - 与 blocking 相同,不过当审计日志在 RequestReceived
阶段失败时,整个 API 服务请求会失效。以下参数仅用于 batch 模式:
--audit-webhook-batch-buffer-size 定义 batch 之前要缓存的事件数。
如果传入事件的速率溢出缓存区,则会丢弃事件。--audit-webhook-batch-max-size 定义一个 batch 中的最大事件数。--audit-webhook-batch-max-wait 无条件 batch 队列中的事件前等待的最大事件。--audit-webhook-batch-throttle-qps 每秒生成的最大批次数。--audit-webhook-batch-throttle-burst 在达到允许的 QPS 前,同一时刻允许存在的最大 batch 生成数。需要设置参数以适应 API 服务器上的负载。
例如,如果 kube-apiserver 每秒收到 100 个请求,并且每个请求仅在 ResponseStarted
和 ResponseComplete 阶段进行审计,则应该考虑每秒生成约 200 个审计事件。
假设批处理中最多有 100 个事件,则应将限制级别设置为每秒至少 2 个查询。
假设后端最多需要 5 秒钟来写入事件,你应该设置缓冲区大小以容纳最多 5 秒的事件,
即 10 个 batch,即 1000 个事件。
但是,在大多数情况下,默认参数应该足够了,你不必手动设置它们。 你可以查看 kube-apiserver 公开的以下 Prometheus 指标,并在日志中监控审计子系统的状态。
apiserver_audit_event_total 包含所有暴露的审计事件数量的指标。apiserver_audit_error_total 在暴露时由于发生错误而被丢弃的事件的数量。日志后端和 Webhook 后端都支持限制所输出的事件大小。 例如,下面是可以为日志后端配置的标志列表:
audit-log-truncate-enabled:是否弃用事件和批次的截断处理。audit-log-truncate-max-batch-size:向下层后端发送的各批次的最大字节数。audit-log-truncate-max-event-size:向下层后端发送的审计事件的最大字节数。默认情况下,截断操作在 webhook 和 log 后端都是被禁用的,集群管理员需要设置
audit-log-truncate-enabled 或 audit-webhook-truncate-enabled 标志来启用此操作。
Event
和 Policy 资源的信息。Kubernetes 应用程序通常由多个独立的服务组成,每个服务都在自己的容器中运行。 在远端的 Kubernetes 集群上开发和调试这些服务可能很麻烦, 需要在运行的容器上打开 Shell, 以运行调试工具。
telepresence 是一个工具,用于简化本地开发和调试服务的过程,同时可以将服务代理到远程 Kubernetes 集群。
telepresence 允许你使用自定义工具(例如调试器和 IDE)调试本地服务,
并能够让此服务完全访问 ConfigMap、Secret 和远程集群上运行的服务。
本文档描述如何在本地使用 telepresence 开发和调试远程集群上运行的服务。
kubectl 与集群交互安装 telepresence 后,运行 telepresence connect 来启动它的守护进程并将本地工作站连接到远程
Kubernetes 集群。
$ telepresence connect
Launching Telepresence Daemon
...
Connected to context default (https://<cluster public IP>)
你可以通过 curl 使用 Kubernetes 语法访问服务,例如:curl -ik https://kubernetes.default
在 Kubernetes 上开发应用程序时,通常对单个服务进行编程或调试。 服务可能需要访问其他服务以进行测试和调试。 一种选择是使用连续部署流水线,但即使最快的部署流水线也会在程序或调试周期中引入延迟。
使用 telepresence intercept $SERVICE_NAME --port $LOCAL_PORT:$REMOTE_PORT
命令创建一个 "拦截器" 用于重新路由远程服务流量。
环境变量:
$SERVICE_NAME 是本地服务名称$LOCAL_PORT 是服务在本地工作站上运行的端口$REMOTE_PORT 是服务在集群中侦听的端口运行此命令会告诉 Telepresence 将远程流量发送到本地服务,而不是远程 Kubernetes 集群中的服务中。 在本地编辑保存服务源代码,并在访问远程应用时查看相应变更会立即生效。 还可以使用调试器或任何其他本地开发工具运行本地服务。
Telepresence 会在远程集群中运行的现有应用程序容器旁边安装流量代理 Sidecar。 当它捕获进入 Pod 的所有流量请求时,不是将其转发到远程集群中的应用程序, 而是路由所有流量(当创建全局拦截器时) 或流量的一个子集(当创建自定义拦截器时) 到本地开发环境。
如果你对实践教程感兴趣, 请查看本教程, 其中介绍了如何在 Google Kubernetes Engine 上本地开发 Guestbook 应用程序。
如需进一步了解,请访问 Telepresence 官方网站。
本页演示如何使用 kubectl debug 命令调试在 Kubernetes
集群上运行的节点。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.2. 要获知版本信息,请输入kubectl version.
你需要有权限创建 Pod 并将这些新 Pod 分配到任意节点。 你还需要被授权创建能够访问主机上文件系统的 Pod。
kubectl debug node 调试节点 使用 kubectl debug node 命令将 Pod 部署到要排查故障的节点上。
此命令在你无法使用 SSH 连接节点时比较有用。
当 Pod 被创建时,Pod 会在节点上打开一个交互的 Shell。
要在名为 “mynode” 的节点上创建一个交互式 Shell,运行:
kubectl debug node/mynode -it --image=ubuntu
Creating debugging pod node-debugger-mynode-pdx84 with container debugger on node mynode.
If you don't see a command prompt, try pressing enter.
root@mynode:/#
调试命令有助于收集信息和排查问题。
你可能使用的命令包括 ip、ifconfig、nc、ping 和 ps 等等。
你还可以从各种包管理器安装 mtr、tcpdump 和 curl 等其他工具。
这些调试命令会因调试 Pod 所使用的镜像不同而有些差别,并且这些命令可能需要被安装。
用于调试的 Pod 可以访问节点的根文件系统,该文件系统挂载在 Pod 中的 /host 路径。
如果你在 filesystem 名字空间中运行 kubelet,
则正调试的 Pod 将看到此名字空间的根,而不是整个节点的根。
对于典型的 Linux 节点,你可以查看以下路径找到一些重要的日志:
/host/var/log/kubelet.logkubelet 所产生的日志。/host/var/log/kube-proxy.logkube-proxy 所产生的日志。/host/var/log/containerd.logcontainerd 进程所产生的日志。/host/var/log/syslog/host/var/log/kern.log当在节点上创建一个调试会话时,需谨记:
kubectl debug 根据节点的名称自动生成新 Pod 的名称。/host。chroot /host 将失败。如果你需要一个有特权的 Pod,请手动创建。当你使用正调试的 Pod 完成时,将其删除:
kubectl get pods
NAME READY STATUS RESTARTS AGE
node-debugger-mynode-pdx84 0/1 Completed 0 8m1s
# 相应更改 Pod 名称
kubectl delete pod node-debugger-mynode-pdx84 --now
pod "node-debugger-mynode-pdx84" deleted
如果节点停机(网络断开或 kubelet 宕机且无法启动等),则 kubectl debug node 命令将不起作用。
这种情况下请检查调试关闭/无法访问的节点。
该文档包含一组用于解决容器化应用程序问题的资源。 它涵盖了诸如 Kubernetes 资源(如 Pod、Service 或 StatefulSets)的常见问题、 关于理解容器终止消息的建议以及调试正在运行的容器的方法。
本指南帮助用户调试那些部署到 Kubernetes 上后没有正常运行的应用。 本指南 并非 指导用户如何调试集群。 如果想调试集群的话,请参阅这里。
故障排查的第一步是先给问题分类。问题是什么?是关于 Pod、Replication Controller 还是 Service?
调试 Pod 的第一步是查看 Pod 信息。用如下命令查看 Pod 的当前状态和最近的事件:
kubectl describe pods ${POD_NAME}
查看一下 Pod 中的容器所处的状态。这些容器的状态都是 Running 吗?最近有没有重启过?
后面的调试都是要依靠 Pod 的状态的。
如果一个 Pod 停滞在 Pending 状态,表示 Pod 没有被调度到节点上。
通常这是因为某种类型的资源不足导致无法调度。
查看上面的 kubectl describe ... 命令的输出,其中应该显示了为什么没被调度的原因。
常见原因如下:
资源不足: 你可能耗尽了集群上所有的 CPU 或内存。此时,你需要删除 Pod、调整资源请求或者为集群添加节点。 更多信息请参阅计算资源文档
使用了 hostPort:
如果绑定 Pod 到 hostPort,那么能够运行该 Pod 的节点就有限了。
多数情况下,hostPort 是非必要的,而应该采用 Service 对象来暴露 Pod。
如果确实需要使用 hostPort,那么集群中节点的个数就是所能创建的 Pod
的数量上限。
如果 Pod 停滞在 Waiting 状态,则表示 Pod 已经被调度到某工作节点,但是无法在该节点上运行。
同样,kubectl describe ... 命令的输出可能很有用。
Waiting 状态的最常见原因是拉取镜像失败。要检查的有三个方面:
docker pull <镜像>。如果 Pod 停滞在 Terminating 状态,表示已发出删除 Pod 的请求,
但控制平面无法删除该 Pod 对象。
如果 Pod 拥有 Finalizer 并且集群中安装了准入 Webhook, 可能会导致控制平面无法移除 Finalizer,从而导致 Pod 出现此问题。
要确认这种情况,请检查你的集群中是否有 ValidatingWebhookConfiguration 或
MutatingWebhookConfiguration 处理 pods 资源的 UPDATE 操作。
如果 Webhook 是由第三方提供的:
UPDATE 操作的 Webhook。如果你是 Webhook 的作者:
UPDATE 操作时不要更改不可变字段。
例如,一般不允许更改 containers。一旦 Pod 被调度, 就可以采用调试运行中的 Pod 中的方法来进一步调试。
如果 Pod 行为不符合预期,很可能 Pod 描述(例如你本地机器上的 mypod.yaml)中有问题,
并且该错误在创建 Pod 时被忽略掉,没有报错。
通常,Pod 的定义中节区嵌套关系错误、字段名字拼错的情况都会引起对应内容被忽略掉。
例如,如果你误将 command 写成 commnd,Pod 虽然可以创建,
但它不会执行你期望它执行的命令行。
可以做的第一件事是删除你的 Pod,并尝试带有 --validate 选项重新创建。
例如,运行 kubectl apply --validate -f mypod.yaml。
如果 command 被误拼成 commnd,你将会看到下面的错误信息:
I0805 10:43:25.129850 46757 schema.go:126] unknown field: commnd
I0805 10:43:25.129973 46757 schema.go:129] this may be a false alarm, see https://github.com/kubernetes/kubernetes/issues/6842
pods/mypod
接下来就要检查的是 API 服务器上的 Pod 与你所期望创建的是否匹配
(例如,你原本使用本机上的一个 YAML 文件来创建 Pod)。
例如,运行 kubectl get pods/mypod -o yaml > mypod-on-apiserver.yaml,
之后手动比较 mypod.yaml 与从 API 服务器取回的 Pod 描述。
从 API 服务器处获得的 YAML 通常包含一些创建 Pod 所用的 YAML 中不存在的行,这是正常的。
不过,如果如果源文件中有些行在 API 服务器版本中不存在,则意味着
Pod 规约是有问题的。
副本控制器相对比较简单直接。它们要么能创建 Pod,要么不能。 如果不能创建 Pod,请参阅上述说明调试 Pod。
你也可以使用 kubectl describe rc ${CONTROLLER_NAME} 命令来检视副本控制器相关的事件。
服务支持在多个 Pod 间负载均衡。 有一些常见的问题可以造成服务无法正常工作。 以下说明将有助于调试服务的问题。
首先,验证服务是否有端点。对于每一个 Service 对象,API 服务器为其提供对应的
endpoints 资源。
通过如下命令可以查看 endpoints 资源:
kubectl get endpoints ${SERVICE_NAME}
确保 Endpoints 与服务成员 Pod 个数一致。 例如,如果你的 Service 用来运行 3 个副本的 nginx 容器,你应该会在 Service 的 Endpoints 中看到 3 个不同的 IP 地址。
如果没有 Endpoints,请尝试使用 Service 所使用的标签列出 Pod。 假定你的服务包含如下标签选择算符:
...
spec:
- selector:
name: nginx
type: frontend
你可以使用如下命令列出与选择算符相匹配的 Pod,并验证这些 Pod 是否归属于创建的服务:
kubectl get pods --selector=name=nginx,type=frontend
验证 Pod 的 containerPort 与服务的 targetPort 是否匹配。
请参阅调试 Service 了解更多信息。
如果上述方法都不能解决你的问题,
请按照调试 Service 文档中的介绍,
确保你的 Service 处于 Running 状态,有 Endpoints 被创建,Pod 真的在提供服务;
DNS 服务已配置并正常工作,iptables 规则也已安装并且 kube-proxy 也没有异常行为。
你也可以访问故障排查文档来获取更多信息。
对于新安装的 Kubernetes,经常出现的问题是 Service 无法正常运行。你已经通过 Deployment(或其他工作负载控制器)运行了 Pod,并创建 Service , 但是当你尝试访问它时,没有任何响应。此文档有望对你有所帮助并找出问题所在。
对于这里的许多步骤,你可能希望知道运行在集群中的 Pod 看起来是什么样的。 最简单的方法是运行一个交互式的 busybox Pod:
kubectl run -it --rm --restart=Never busybox --image=gcr.io/google-containers/busybox sh
如果你已经有了你想使用的正在运行的 Pod,则可以运行以下命令去进入:
kubectl exec <POD-NAME> -c <CONTAINER-NAME> -- <COMMAND>
为了完成本次实践的任务,我们先运行几个 Pod。 由于你可能正在调试自己的 Service,所以,你可以使用自己的信息进行替换, 或者你也可以跟着教程并开始下面的步骤来获得第二个数据点。
kubectl create deployment hostnames --image=registry.k8s.io/serve_hostname
deployment.apps/hostnames created
kubectl 命令将打印创建或变更的资源的类型和名称,它们可以在后续命令中使用。
让我们将这个 deployment 的副本数扩至 3。
kubectl scale deployment hostnames --replicas=3
deployment.apps/hostnames scaled
请注意这与你使用以下 YAML 方式启动 Deployment 类似:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: hostnames
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: registry.k8s.io/serve_hostname
"app" 标签是 kubectl create deployment 根据 Deployment 名称自动设置的。
确认你的 Pod 是运行状态:
kubectl get pods -l app=hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 2m
hostnames-632524106-ly40y 1/1 Running 0 2m
hostnames-632524106-tlaok 1/1 Running 0 2m
你还可以确认你的 Pod 是否正在提供服务。你可以获取 Pod IP 地址列表并直接对其进行测试。
kubectl get pods -l app=hostnames \
-o go-template='{{range .items}}{{.status.podIP}}{{"\n"}}{{end}}'
10.244.0.5
10.244.0.6
10.244.0.7
用于本教程的示例容器通过 HTTP 在端口 9376 上提供其自己的主机名, 但是如果要调试自己的应用程序,则需要使用你的 Pod 正在侦听的端口号。
在 Pod 内运行:
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do
wget -qO- $ep
done
输出类似这样:
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
如果此时你没有收到期望的响应,则你的 Pod 状态可能不健康,或者可能没有在你认为正确的端口上进行监听。
你可能会发现 kubectl logs 命令对于查看正在发生的事情很有用,
或者你可能需要通过kubectl exec 直接进入 Pod 中并从那里进行调试。
假设到目前为止一切都已按计划进行,那么你可以开始调查为何你的 Service 无法正常工作。
细心的读者会注意到我们实际上尚未创建 Service —— 这是有意而为之。 这一步有时会被遗忘,这是首先要检查的步骤。
那么,如果我尝试访问不存在的 Service 会怎样? 假设你有另一个 Pod 通过名称匹配到 Service,你将得到类似结果:
wget -O- hostnames
Resolving hostnames (hostnames)... failed: Name or service not known.
wget: unable to resolve host address 'hostnames'
首先要检查的是该 Service 是否真实存在:
kubectl get svc hostnames
No resources found.
Error from server (NotFound): services "hostnames" not found
让我们创建 Service。 和以前一样,在这次实践中 —— 你可以在此处使用自己的 Service 的内容。
kubectl expose deployment hostnames --port=80 --target-port=9376
service/hostnames exposed
重新运行查询命令:
kubectl get svc hostnames
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hostnames ClusterIP 10.0.1.175 <none> 80/TCP 5s
现在你知道了 Service 确实存在。
同前,此步骤效果与通过 YAML 方式启动 Service 一样:
apiVersion: v1
kind: Service
metadata:
labels:
app: hostnames
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80
targetPort: 9376
为了突出配置范围的完整性,你在此处创建的 Service 使用的端口号与 Pods 不同。 对于许多真实的 Service,这些值可以是相同的。
如果你部署了任何可能影响到 hostnames-* Pod 的传入流量的网络策略入站规则,
则需要对其进行检查。
详细信息,请参阅网络策略。
通常客户端通过 DNS 名称来匹配到 Service。
从相同命名空间下的 Pod 中运行以下命令:
nslookup hostnames
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
如果失败,那么你的 Pod 和 Service 可能位于不同的命名空间中, 请尝试使用限定命名空间的名称(同样在 Pod 内运行):
nslookup hostnames.default
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames.default
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
如果成功,那么需要调整你的应用,使用跨命名空间的名称去访问它, 或者在相同的命名空间中运行应用和 Service。如果仍然失败,请尝试一个完全限定的名称:
nslookup hostnames.default.svc.cluster.local
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: hostnames.default.svc.cluster.local
Address 1: 10.0.1.175 hostnames.default.svc.cluster.local
注意这里的后缀:"default.svc.cluster.local"。"default" 是我们正在操作的命名空间。 "svc" 表示这是一个 Service。"cluster.local" 是你的集群域,在你自己的集群中可能会有所不同。
你也可以在集群中的节点上尝试此操作:
10.0.0.10 是集群的 DNS 服务 IP,你的可能有所不同。
nslookup hostnames.default.svc.cluster.local 10.0.0.10
Server: 10.0.0.10
Address: 10.0.0.10#53
Name: hostnames.default.svc.cluster.local
Address: 10.0.1.175
如果你能够使用完全限定的名称查找,但不能使用相对名称,则需要检查你 Pod 中的
/etc/resolv.conf 文件是否正确。在 Pod 中运行以下命令:
cat /etc/resolv.conf
你应该可以看到类似这样的输出:
nameserver 10.0.0.10
search default.svc.cluster.local svc.cluster.local cluster.local example.com
options ndots:5
nameserver 行必须指示你的集群的 DNS Service,
它是通过 --cluster-dns 标志传递到 kubelet 的。
search 行必须包含一个适当的后缀,以便查找 Service 名称。
在本例中,它查找本地命名空间(default.svc.cluster.local)中的服务和所有命名空间
(svc.cluster.local)中的服务,最后在集群(cluster.local)中查找服务的名称。
根据你自己的安装情况,可能会有额外的记录(最多 6 条)。
集群后缀是通过 --cluster-domain 标志传递给 kubelet 的。
本文中,我们假定后缀是 “cluster.local”。
你的集群配置可能不同,这种情况下,你应该在上面的所有命令中更改它。
options 行必须设置足够高的 ndots,以便 DNS 客户端库考虑搜索路径。
在默认情况下,Kubernetes 将这个值设置为 5,这个值足够高,足以覆盖它生成的所有 DNS 名称。
如果上面的方式仍然失败,DNS 查找不到你需要的 Service ,你可以后退一步, 看看还有什么其它东西没有正常工作。 Kubernetes 主 Service 应该一直是工作的。在 Pod 中运行如下命令:
nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
如果失败,你可能需要转到本文的 kube-proxy 节, 或者甚至回到文档的顶部重新开始,但不是调试你自己的 Service ,而是调试 DNS Service。
假设你已经确认 DNS 工作正常,那么接下来要测试的是你的 Service 能否通过它的 IP 正常访问。
从集群中的一个 Pod,尝试访问 Service 的 IP(从上面的 kubectl get 命令获取)。
for i in $(seq 1 3); do
wget -qO- 10.0.1.175:80
done
输出应该类似这样:
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
如果 Service 状态是正常的,你应该得到正确的响应。 如果没有,有很多可能出错的地方,请继续阅读。
这听起来可能很愚蠢,但你应该两次甚至三次检查你的 Service 配置是否正确,并且与你的 Pod 匹配。 查看你的 Service 配置并验证它:
kubectl get service hostnames -o json
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "hostnames",
"namespace": "default",
"uid": "428c8b6c-24bc-11e5-936d-42010af0a9bc",
"resourceVersion": "347189",
"creationTimestamp": "2015-07-07T15:24:29Z",
"labels": {
"app": "hostnames"
}
},
"spec": {
"ports": [
{
"name": "default",
"protocol": "TCP",
"port": 80,
"targetPort": 9376,
"nodePort": 0
}
],
"selector": {
"app": "hostnames"
},
"clusterIP": "10.0.1.175",
"type": "ClusterIP",
"sessionAffinity": "None"
},
"status": {
"loadBalancer": {}
}
}
spec.ports[] 中列出?targetPort 对你的 Pod 来说正确吗(许多 Pod 使用与 Service 不同的端口)?protocol 和 Pod 的是否对应?如果你已经走到了这一步,你已经确认你的 Service 被正确定义,并能通过 DNS 解析。 现在,让我们检查一下,你运行的 Pod 确实是被 Service 选中的。
早些时候,我们已经看到 Pod 是运行状态。我们可以再检查一下:
kubectl get pods -l app=hostnames
NAME READY STATUS RESTARTS AGE
hostnames-632524106-bbpiw 1/1 Running 0 1h
hostnames-632524106-ly40y 1/1 Running 0 1h
hostnames-632524106-tlaok 1/1 Running 0 1h
-l app=hostnames 参数是在 Service 上配置的标签选择器。
“AGE” 列表明这些 Pod 已经启动一个小时了,这意味着它们运行良好,而未崩溃。
"RESTARTS" 列表明 Pod 没有经常崩溃或重启。经常性崩溃可能导致间歇性连接问题。 如果重启次数过大,通过调试 Pod 了解相关技术。
在 Kubernetes 系统中有一个控制回路,它评估每个 Service 的选择算符,并将结果保存到 Endpoints 对象中。
kubectl get endpoints hostnames
NAME ENDPOINTS
hostnames 10.244.0.5:9376,10.244.0.6:9376,10.244.0.7:9376
这证实 Endpoints 控制器已经为你的 Service 找到了正确的 Pods。
如果 ENDPOINTS 列的值为 <none>,则应检查 Service 的 spec.selector 字段,
以及你实际想选择的 Pod 的 metadata.labels 的值。
常见的错误是输入错误或其他错误,例如 Service 想选择 app=hostnames,但是
Deployment 指定的是 run=hostnames。在 1.18之前的版本中 kubectl run
也可以被用来创建 Deployment。
至此,你知道你的 Service 已存在,并且已匹配到你的Pod。在本实验的开始,你已经检查了 Pod 本身。 让我们再次检查 Pod 是否确实在工作 - 你可以绕过 Service 机制并直接转到 Pod, 如上面的 Endpoints 所示。
这些命令使用的是 Pod 端口(9376),而不是 Service 端口(80)。
在 Pod 中运行:
for ep in 10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376; do
wget -qO- $ep
done
输出应该类似这样:
hostnames-632524106-bbpiw
hostnames-632524106-ly40y
hostnames-632524106-tlaok
你希望 Endpoint 列表中的每个 Pod 都返回自己的主机名。 如果情况并非如此(或你自己的 Pod 的正确行为是什么),你应调查发生了什么事情。
如果你到达这里,则说明你的 Service 正在运行,拥有 Endpoints,Pod 真正在提供服务。 此时,整个 Service 代理机制是可疑的。让我们一步一步地确认它没问题。
Service 的默认实现(在大多数集群上应用的)是 kube-proxy。 这是一个在每个节点上运行的程序,负责配置用于提供 Service 抽象的机制之一。 如果你的集群不使用 kube-proxy,则以下各节将不适用,你将必须检查你正在使用的 Service 的实现方式。
确认 kube-proxy 正在节点上运行。在节点上直接运行,你将会得到类似以下的输出:
ps auxw | grep kube-proxy
root 4194 0.4 0.1 101864 17696 ? Sl Jul04 25:43 /usr/local/bin/kube-proxy --master=https://kubernetes-master --kubeconfig=/var/lib/kube-proxy/kubeconfig --v=2
下一步,确认它并没有出现明显的失败,比如连接主节点失败。要做到这一点,你必须查看日志。
访问日志的方式取决于你节点的操作系统。
在某些操作系统上日志是一个文件,如 /var/log/messages kube-proxy.log,
而其他操作系统使用 journalctl 访问日志。你应该看到输出类似于:
I1027 22:14:53.995134 5063 server.go:200] Running in resource-only container "/kube-proxy"
I1027 22:14:53.998163 5063 server.go:247] Using iptables Proxier.
I1027 22:14:54.038140 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns-tcp" to [10.244.1.3:53]
I1027 22:14:54.038164 5063 proxier.go:352] Setting endpoints for "kube-system/kube-dns:dns" to [10.244.1.3:53]
I1027 22:14:54.038209 5063 proxier.go:352] Setting endpoints for "default/kubernetes:https" to [10.240.0.2:443]
I1027 22:14:54.038238 5063 proxier.go:429] Not syncing iptables until Services and Endpoints have been received from master
I1027 22:14:54.040048 5063 proxier.go:294] Adding new service "default/kubernetes:https" at 10.0.0.1:443/TCP
I1027 22:14:54.040154 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns" at 10.0.0.10:53/UDP
I1027 22:14:54.040223 5063 proxier.go:294] Adding new service "kube-system/kube-dns:dns-tcp" at 10.0.0.10:53/TCP
如果你看到有关无法连接主节点的错误消息,则应再次检查节点配置和安装步骤。
kube-proxy 无法正确运行的可能原因之一是找不到所需的 conntrack 二进制文件。
在一些 Linux 系统上,这也是可能发生的,这取决于你如何安装集群,
例如,你是手动开始一步步安装 Kubernetes。如果是这样的话,你需要手动安装
conntrack 包(例如,在 Ubuntu 上使用 sudo apt install conntrack),然后重试。
Kube-proxy 可以以若干模式之一运行。在上述日志中,Using iptables Proxier
行表示 kube-proxy 在 "iptables" 模式下运行。
最常见的另一种模式是 "ipvs"。
在 "iptables" 模式中, 你应该可以在节点上看到如下输出:
iptables-save | grep hostnames
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
对于每个 Service 的每个端口,应有 1 条 KUBE-SERVICES 规则、一个 KUBE-SVC-<hash> 链。
对于每个 Pod 末端,在那个 KUBE-SVC-<hash> 链中应该有一些规则与之对应,还应该
有一个 KUBE-SEP-<hash> 链与之对应,其中包含为数不多的几条规则。
实际的规则数量可能会根据你实际的配置(包括 NodePort 和 LoadBalancer 服务)有所不同。
在 "ipvs" 模式中, 你应该在节点下看到如下输出:
ipvsadm -ln
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
...
TCP 10.0.1.175:80 rr
-> 10.244.0.5:9376 Masq 1 0 0
-> 10.244.0.6:9376 Masq 1 0 0
-> 10.244.0.7:9376 Masq 1 0 0
...
对于每个 Service 的每个端口,还有 NodePort,External IP 和 LoadBalancer 类型服务
的 IP,kube-proxy 将创建一个虚拟服务器。
对于每个 Pod 末端,它将创建相应的真实服务器。
在此示例中,服务主机名(10.0.1.175:80)拥有 3 个末端(10.244.0.5:9376、
10.244.0.6:9376 和 10.244.0.7:9376)。
假设你确实遇到上述情况之一,请重试从节点上通过 IP 访问你的 Service :
curl 10.0.1.175:80
hostnames-632524106-bbpiw
如果这步操作仍然失败,请查看 kube-proxy 日志中的特定行,如:
Setting endpoints for default/hostnames:default to [10.244.0.5:9376 10.244.0.6:9376 10.244.0.7:9376]
如果你没有看到这些,请尝试将 -v 标志设置为 4 并重新启动 kube-proxy,然后再查看日志。
这听起来似乎不太可能,但是确实可能发生,并且应该可以工作。
如果网络没有为“发夹模式(Hairpin)”流量生成正确配置,
通常当 kube-proxy 以 iptables 模式运行,并且 Pod 与桥接网络连接时,就会发生这种情况。
kubelet 提供了 hairpin-mode
标志。
如果 Service 的末端尝试访问自己的 Service VIP,则该端点可以把流量负载均衡回来到它们自身。
hairpin-mode 标志必须被设置为 hairpin-veth 或者 promiscuous-bridge。
诊断此类问题的常见步骤如下:
确认 hairpin-mode 被设置为 hairpin-veth 或 promiscuous-bridge。
你应该可以看到下面这样。本例中 hairpin-mode 被设置为 promiscuous-bridge。
ps auxw | grep kubelet
root 3392 1.1 0.8 186804 65208 ? Sl 00:51 11:11 /usr/local/bin/kubelet --enable-debugging-handlers=true --config=/etc/kubernetes/manifests --allow-privileged=True --v=4 --cluster-dns=10.0.0.10 --cluster-domain=cluster.local --configure-cbr0=true --cgroup-root=/ --system-cgroups=/system --hairpin-mode=promiscuous-bridge --runtime-cgroups=/docker-daemon --kubelet-cgroups=/kubelet --babysit-daemons=true --max-pods=110 --serialize-image-pulls=false --outofdisk-transition-frequency=0
确认有效的 hairpin-mode。要做到这一点,你必须查看 kubelet 日志。
访问日志取决于节点的操作系统。在一些操作系统上,它是一个文件,如 /var/log/kubelet.log,
而其他操作系统则使用 journalctl 访问日志。请注意,由于兼容性,
有效的 hairpin-mode 可能不匹配 --hairpin-mode 标志。在 kubelet.log
中检查是否有带有关键字 hairpin 的日志行。应该有日志行指示有效的
hairpin-mode,就像下面这样。
I0629 00:51:43.648698 3252 kubelet.go:380] Hairpin mode set to "promiscuous-bridge"
如果有效的发夹模式是 hairpin-veth, 要保证 Kubelet 有操作节点上 /sys 的权限。
如果一切正常,你将会看到如下输出:
for intf in /sys/devices/virtual/net/cbr0/brif/*; do cat $intf/hairpin_mode; done
1
1
1
1
如果有效的发卡模式是 promiscuous-bridge, 要保证 Kubelet 有操作节点上
Linux 网桥的权限。如果 cbr0 桥正在被使用且被正确设置,你将会看到如下输出:
ifconfig cbr0 |grep PROMISC
UP BROADCAST RUNNING PROMISC MULTICAST MTU:1460 Metric:1
如果你走到这一步,那么就真的是奇怪的事情发生了。你的 Service 正在运行,有 Endpoints 存在,
你的 Pods 也确实在提供服务。你的 DNS 正常,iptables 规则已经安装,kube-proxy 看起来也正常。
然而 Service 还是没有正常工作。这种情况下,请告诉我们,以便我们可以帮助调查!
通过 Slack 或者 Forum 或者 GitHub 联系我们。
访问故障排查概述文档获取更多信息。
此任务展示如何调试 StatefulSet。
StatefulSet 在创建 Pod 时为其设置了 app.kubernetes.io/name=MyApp 标签,列出仅属于某 StatefulSet
的所有 Pod 时,可以使用以下命令:
kubectl get pods -l app.kubernetes.io/name=MyApp
如果你发现列出的任何 Pod 长时间处于 Unknown 或 Terminating 状态,请参阅
删除 StatefulSet Pod
了解如何处理它们的说明。
你可以参考调试 Pod
来调试 StatefulSet 中的各个 Pod。
进一步了解如何调试 Init 容器。
本文介绍如何编写和读取容器的终止消息。
终止消息为容器提供了一种方法,可以将有关致命事件的信息写入某个位置, 在该位置可以通过仪表板和监控软件等工具轻松检索和显示致命事件。 在大多数情况下,你放入终止消息中的信息也应该写入 常规 Kubernetes 日志。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在本练习中,你将创建运行一个容器的 Pod。 配置文件指定在容器启动时要运行的命令。
apiVersion: v1
kind: Pod
metadata:
name: termination-demo
spec:
containers:
- name: termination-demo-container
image: debian
command: ["/bin/sh"]
args: ["-c", "sleep 10 && echo Sleep expired > /dev/termination-log"]
基于 YAML 配置文件创建 Pod:
kubectl apply -f https://k8s.io/examples/debug/termination.yaml
YAML 文件中,在 command 和 args 字段,你可以看到容器休眠 10 秒然后将 "Sleep expired"
写入 /dev/termination-log 文件。
容器写完 "Sleep expired" 消息后就终止了。
显示 Pod 的信息:
kubectl get pod termination-demo
重复前面的命令直到 Pod 不再运行。
显示 Pod 的详细信息:
kubectl get pod termination-demo --output=yaml
输出结果包含 "Sleep expired" 消息:
apiVersion: v1
kind: Pod
...
lastState:
terminated:
containerID: ...
exitCode: 0
finishedAt: ...
message: |
Sleep expired
...
使用 Go 模板过滤输出结果,使其只含有终止消息:
kubectl get pod termination-demo -o go-template="{{range .status.containerStatuses}}{{.lastState.terminated.message}}{{end}}"
如果你正在运行多容器 Pod,则可以使用 Go 模板来包含容器的名称。这样,你可以发现哪些容器出现故障:
kubectl get pod multi-container-pod -o go-template='{{range .status.containerStatuses}}{{printf "%s:\n%s\n\n" .name .lastState.terminated.message}}{{end}}'
Kubernetes 从容器的 terminationMessagePath 字段中指定的终止消息文件中检索终止消息,
默认值为 /dev/termination-log。
通过定制这个字段,你可以告诉 Kubernetes 使用不同的文件。
Kubernetes 使用指定文件中的内容在成功和失败时填充容器的状态消息。
终止消息旨在简要说明最终状态,例如断言失败消息。 kubelet 会截断长度超过 4096 字节的消息。
所有容器的总消息长度限制为 12KiB,将会在每个容器之间平均分配。
例如,如果有 12 个容器(initContainers 或 containers),
每个容器都有 1024 字节的可用终止消息空间。
默认的终止消息路径是 /dev/termination-log。
Pod 启动后不能设置终止消息路径。
在下例中,容器将终止消息写入 /tmp/my-log 给 Kubernetes 来检索:
apiVersion: v1
kind: Pod
metadata:
name: msg-path-demo
spec:
containers:
- name: msg-path-demo-container
image: debian
terminationMessagePath: "/tmp/my-log"
此外,用户可以设置容器的 terminationMessagePolicy 字段,以便进一步自定义。
此字段默认为 "File",这意味着仅从终止消息文件中检索终止消息。
通过将 terminationMessagePolicy 设置为 "FallbackToLogsOnError",你就可以告诉 Kubernetes,在容器因错误退出时,如果终止消息文件为空,则使用容器日志输出的最后一块作为终止消息。
日志输出限制为 2048 字节或 80 行,以较小者为准。
此页显示如何核查与 Init 容器执行相关的问题。
下面的示例命令行将 Pod 称为 <pod-name>,而 Init 容器称为 <init-container-1> 和
<init-container-2>。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
显示你的 Pod 的状态:
kubectl get pod <pod-name>
例如,状态 Init:1/2 表明两个 Init 容器中的一个已经成功完成:
NAME READY STATUS RESTARTS AGE
<pod-name> 0/1 Init:1/2 0 7s
更多状态值及其含义请参考理解 Pod 的状态。
查看 Init 容器运行的更多详情:
kubectl describe pod <pod-name>
例如,对于包含两个 Init 容器的 Pod 可能显示如下信息:
Init Containers:
<init-container-1>:
Container ID: ...
...
State: Terminated
Reason: Completed
Exit Code: 0
Started: ...
Finished: ...
Ready: True
Restart Count: 0
...
<init-container-2>:
Container ID: ...
...
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: ...
Finished: ...
Ready: False
Restart Count: 3
...
你还可以通过编程方式读取 Pod Spec 上的 status.initContainerStatuses 字段,了解 Init 容器的状态:
kubectl get pod nginx --template '{{.status.initContainerStatuses}}'
此命令将返回与原始 JSON 中相同的信息.
与 Pod 名称一起传递 Init 容器名称,以访问容器的日志。
kubectl logs <pod-name> -c <init-container-2>
运行 Shell 脚本的 Init 容器在执行 Shell 脚本时输出命令本身。
例如,你可以在 Bash 中通过在脚本的开头运行 set -x 来实现。
以 Init: 开头的 Pod 状态汇总了 Init 容器执行的状态。
下表介绍调试 Init 容器时可能看到的一些状态值示例。
| 状态 | 含义 |
|---|---|
Init:N/M |
Pod 包含 M 个 Init 容器,其中 N 个已经运行完成。 |
Init:Error |
Init 容器已执行失败。 |
Init:CrashLoopBackOff |
Init 容器执行总是失败。 |
Pending |
Pod 还没有开始执行 Init 容器。 |
PodInitializing or Running |
Pod 已经完成执行 Init 容器。 |
本页解释如何在节点上调试运行中(或崩溃)的 Pod。
对于一些高级调试步骤,你应该知道 Pod 具体运行在哪个节点上,并具有在该节点上运行命令的 shell 访问权限。
你不需要任何访问权限就可以使用 kubectl 去运行一些标准调试步骤。
kubectl describe pod 命令获取 Pod 详情与之前的例子类似,我们使用一个 Deployment 来创建两个 Pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
使用如下命令创建 Deployment:
kubectl apply -f https://k8s.io/examples/application/nginx-with-request.yaml
deployment.apps/nginx-deployment created
使用如下命令查看 Pod 状态:
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-67d4bdd6f5-cx2nz 1/1 Running 0 13s
nginx-deployment-67d4bdd6f5-w6kd7 1/1 Running 0 13s
我们可以使用 kubectl describe pod 命令来查询每个 Pod 的更多信息,比如:
kubectl describe pod nginx-deployment-67d4bdd6f5-w6kd7
Name: nginx-deployment-67d4bdd6f5-w6kd7
Namespace: default
Priority: 0
Node: kube-worker-1/192.168.0.113
Start Time: Thu, 17 Feb 2022 16:51:01 -0500
Labels: app=nginx
pod-template-hash=67d4bdd6f5
Annotations: <none>
Status: Running
IP: 10.88.0.3
IPs:
IP: 10.88.0.3
IP: 2001:db8::1
Controlled By: ReplicaSet/nginx-deployment-67d4bdd6f5
Containers:
nginx:
Container ID: containerd://5403af59a2b46ee5a23fb0ae4b1e077f7ca5c5fb7af16e1ab21c00e0e616462a
Image: nginx
Image ID: docker.io/library/nginx@sha256:2834dc507516af02784808c5f48b7cbe38b8ed5d0f4837f16e78d00deb7e7767
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 17 Feb 2022 16:51:05 -0500
Ready: True
Restart Count: 0
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 500m
memory: 128Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-bgsgp (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-bgsgp:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 34s default-scheduler Successfully assigned default/nginx-deployment-67d4bdd6f5-w6kd7 to kube-worker-1
Normal Pulling 31s kubelet Pulling image "nginx"
Normal Pulled 30s kubelet Successfully pulled image "nginx" in 1.146417389s
Normal Created 30s kubelet Created container nginx
Normal Started 30s kubelet Started container nginx
在这里,你可以看到有关容器和 Pod 的配置信息(标签、资源需求等), 以及有关容器和 Pod 的状态信息(状态、就绪、重启计数、事件等)。
容器状态是 Waiting、Running 和 Terminated 之一。 根据状态的不同,还有对应的额外的信息 —— 在这里你可以看到, 对于处于运行状态的容器,系统会告诉你容器的启动时间。
Ready 指示是否通过了最后一个就绪态探测。 (在本例中,容器没有配置就绪态探测;如果没有配置就绪态探测,则假定容器已经就绪。)
Restart Count 告诉你容器已重启的次数; 这些信息对于定位配置了 “Always” 重启策略的容器持续崩溃问题非常有用。
目前,唯一与 Pod 有关的状态是 Ready 状况,该状况表明 Pod 能够为请求提供服务, 并且应该添加到相应服务的负载均衡池中。
最后,你还可以看到与 Pod 相关的近期事件。 “From” 标明记录事件的组件, “Reason” 和 “Message” 告诉你发生了什么。
可以使用事件来调试的一个常见的场景是,你创建 Pod 无法被调度到任何节点。 比如,Pod 请求的资源比较多,没有任何一个节点能够满足,或者它指定了一个标签,没有节点可匹配。 假定我们创建之前的 Deployment 时指定副本数是 5(不再是 2),并且请求 600 毫核(不再是 500), 对于一个 4 个节点的集群,若每个节点只有 1 个 CPU,这时至少有一个 Pod 不能被调度。 (需要注意的是,其他集群插件 Pod,比如 fluentd、skydns 等等会在每个节点上运行, 如果我们需求 1000 毫核,将不会有 Pod 会被调度。)
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 7m
nginx-deployment-1006230814-fmgu3 1/1 Running 0 7m
nginx-deployment-1370807587-6ekbw 1/1 Running 0 1m
nginx-deployment-1370807587-fg172 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sd 0/1 Pending 0 1m
为了查找 Pod nginx-deployment-1370807587-fz9sd 没有运行的原因,我们可以使用
kubectl describe pod 命令描述 Pod,查看其事件:
kubectl describe pod nginx-deployment-1370807587-fz9sd
Name: nginx-deployment-1370807587-fz9sd
Namespace: default
Node: /
Labels: app=nginx,pod-template-hash=1370807587
Status: Pending
IP:
Controllers: ReplicaSet/nginx-deployment-1370807587
Containers:
nginx:
Image: nginx
Port: 80/TCP
QoS Tier:
memory: Guaranteed
cpu: Guaranteed
Limits:
cpu: 1
memory: 128Mi
Requests:
cpu: 1
memory: 128Mi
Environment Variables:
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 48s 7 {default-scheduler } Warning FailedScheduling pod (nginx-deployment-1370807587-fz9sd) failed to fit in any node
fit failure on node (kubernetes-node-6ta5): Node didn't have enough resource: CPU, requested: 1000, used: 1420, capacity: 2000
fit failure on node (kubernetes-node-wul5): Node didn't have enough resource: CPU, requested: 1000, used: 1100, capacity: 2000
这里你可以看到由调度器记录的事件,它表明了 Pod 不能被调度的原因是 FailedScheduling(也可能是其他值)。
其 message 部分表明没有任何节点拥有足够多的资源。
要纠正这种情况,可以使用 kubectl scale 更新 Deployment,以指定 4 个或更少的副本。
(或者你可以让 Pod 继续保持这个状态,这是无害的。)
你在 kubectl describe pod 结尾处看到的事件都保存在 etcd 中,
并提供关于集群中正在发生的事情的高级信息。
如果需要列出所有事件,可使用命令:
kubectl get events
但是,需要注意的是,事件是区分名字空间的。
如果你对某些名字空间域的对象(比如 my-namespace 名字下的 Pod)的事件感兴趣,
你需要显式地在命令行中指定名字空间:
kubectl get events --namespace=my-namespace
查看所有 namespace 的事件,可使用 --all-namespaces 参数。
除了 kubectl describe pod 以外,另一种获取 Pod 额外信息(除了 kubectl get pod)的方法
是给 kubectl get pod 增加 -o yaml 输出格式参数。
该命令将以 YAML 格式为你提供比 kubectl describe pod 更多的信息 —— 实际上是系统拥有的关于 Pod 的所有信息。
在这里,你将看到注解(没有标签限制的键值元数据,由 Kubernetes 系统组件在内部使用)、
重启策略、端口和卷等。
kubectl get pod nginx-deployment-1006230814-6winp -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-02-17T21:51:01Z"
generateName: nginx-deployment-67d4bdd6f5-
labels:
app: nginx
pod-template-hash: 67d4bdd6f5
name: nginx-deployment-67d4bdd6f5-w6kd7
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-67d4bdd6f5
uid: 7d41dfd4-84c0-4be4-88ab-cedbe626ad82
resourceVersion: "1364"
uid: a6501da1-0447-4262-98eb-c03d4002222e
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources:
limits:
cpu: 500m
memory: 128Mi
requests:
cpu: 500m
memory: 128Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-bgsgp
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: kube-worker-1
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: kube-api-access-bgsgp
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2022-02-17T21:51:01Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2022-02-17T21:51:06Z"
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2022-02-17T21:51:06Z"
status: "True"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2022-02-17T21:51:01Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: containerd://5403af59a2b46ee5a23fb0ae4b1e077f7ca5c5fb7af16e1ab21c00e0e616462a
image: docker.io/library/nginx:latest
imageID: docker.io/library/nginx@sha256:2834dc507516af02784808c5f48b7cbe38b8ed5d0f4837f16e78d00deb7e7767
lastState: {}
name: nginx
ready: true
restartCount: 0
started: true
state:
running:
startedAt: "2022-02-17T21:51:05Z"
hostIP: 192.168.0.113
phase: Running
podIP: 10.88.0.3
podIPs:
- ip: 10.88.0.3
- ip: 2001:db8::1
qosClass: Guaranteed
startTime: "2022-02-17T21:51:01Z"
首先,查看受到影响的容器的日志:
kubectl logs ${POD_NAME} ${CONTAINER_NAME}
如果你的容器之前崩溃过,你可以通过下面命令访问之前容器的崩溃日志:
kubectl logs --previous ${POD_NAME} ${CONTAINER_NAME}
如果 容器镜像 包含调试程序,
比如从 Linux 和 Windows 操作系统基础镜像构建的镜像,你可以使用 kubectl exec 命令
在特定的容器中运行一些命令:
kubectl exec ${POD_NAME} -c ${CONTAINER_NAME} -- ${CMD} ${ARG1} ${ARG2} ... ${ARGN}
-c ${CONTAINER_NAME} 是可选择的。如果 Pod 中仅包含一个容器,就可以忽略它。
例如,要查看正在运行的 Cassandra Pod 中的日志,可以运行:
kubectl exec cassandra -- cat /var/log/cassandra/system.log
你可以在 kubectl exec 命令后面加上 -i 和 -t 来运行一个连接到你的终端的 Shell,比如:
kubectl exec -it cassandra -- sh
若要了解更多内容,可查看获取正在运行容器的 Shell。
Kubernetes v1.25 [stable]
当由于容器崩溃或容器镜像不包含调试程序(例如无发行版镜像等)
而导致 kubectl exec 无法运行时,临时容器对于排除交互式故障很有用。
你可以使用 kubectl debug 命令来给正在运行中的 Pod 增加一个临时容器。
首先,像示例一样创建一个 pod:
kubectl run ephemeral-demo --image=registry.k8s.io/pause:3.1 --restart=Never
本节示例中使用 pause 容器镜像,因为它不包含调试程序,但是这个方法适用于所有容器镜像。
如果你尝试使用 kubectl exec 来创建一个 shell,你将会看到一个错误,因为这个容器镜像中没有 shell。
kubectl exec -it ephemeral-demo -- sh
OCI runtime exec failed: exec failed: container_linux.go:346: starting container process caused "exec: \"sh\": executable file not found in $PATH": unknown
你可以改为使用 kubectl debug 添加调试容器。
如果你指定 -i 或者 --interactive 参数,kubectl 将自动挂接到临时容器的控制台。
kubectl debug -it ephemeral-demo --image=busybox:1.28 --target=ephemeral-demo
Defaulting debug container name to debugger-8xzrl.
If you don't see a command prompt, try pressing enter.
/ #
此命令添加一个新的 busybox 容器并将其挂接到该容器。--target 参数指定另一个容器的进程命名空间。
这个指定进程命名空间的操作是必需的,因为 kubectl run 不能在它创建的 Pod
中启用共享进程命名空间。
你可以使用 kubectl describe 查看新创建的临时容器的状态:
kubectl describe pod ephemeral-demo
...
Ephemeral Containers:
debugger-8xzrl:
Container ID: docker://b888f9adfd15bd5739fefaa39e1df4dd3c617b9902082b1cfdc29c4028ffb2eb
Image: busybox
Image ID: docker-pullable://busybox@sha256:1828edd60c5efd34b2bf5dd3282ec0cc04d47b2ff9caa0b6d4f07a21d1c08084
Port: <none>
Host Port: <none>
State: Running
Started: Wed, 12 Feb 2020 14:25:42 +0100
Ready: False
Restart Count: 0
Environment: <none>
Mounts: <none>
...
使用 kubectl delete 来移除已经结束掉的 Pod:
kubectl delete pod ephemeral-demo
有些时候 Pod 的配置参数使得在某些情况下很难执行故障排查。
例如,在容器镜像中不包含 shell 或者你的应用程序在启动时崩溃的情况下,
就不能通过运行 kubectl exec 来排查容器故障。
在这些情况下,你可以使用 kubectl debug 来创建 Pod 的副本,通过更改配置帮助调试。
当应用程序正在运行但其表现不符合预期时,你会希望在 Pod 中添加额外的调试工具, 这时添加新容器是很有用的。
例如,应用的容器镜像是建立在 busybox 的基础上,
但是你需要 busybox 中并不包含的调试工具。
你可以使用 kubectl run 模拟这个场景:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
通过运行以下命令,建立 myapp 的一个名为 myapp-debug 的副本,
新增了一个用于调试的 Ubuntu 容器,
kubectl debug myapp -it --image=ubuntu --share-processes --copy-to=myapp-debug
Defaulting debug container name to debugger-w7xmf.
If you don't see a command prompt, try pressing enter.
root@myapp-debug:/#
--container 指定新的容器名,kubectl debug 会自动生成的。-i 标志使 kubectl debug 附加到新容器上。
你可以通过指定 --attach=false 来防止这种情况。
如果你的会话断开连接,你可以使用 kubectl attach 重新连接。--share-processes 允许在此 Pod 中的其他容器中查看该容器的进程。
参阅在 Pod 中的容器之间共享进程命名空间
获取更多信息。不要忘了清理调试 Pod:
kubectl delete pod myapp myapp-debug
有时更改容器的命令很有用,例如添加调试标志或因为应用崩溃。
为了模拟应用崩溃的场景,使用 kubectl run 命令创建一个立即退出的容器:
kubectl run --image=busybox:1.28 myapp -- false
使用 kubectl describe pod myapp 命令,你可以看到容器崩溃了:
Containers:
myapp:
Image: busybox
...
Args:
false
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
你可以使用 kubectl debug 命令创建该 Pod 的一个副本,
在该副本中命令改变为交互式 shell:
kubectl debug myapp -it --copy-to=myapp-debug --container=myapp -- sh
If you don't see a command prompt, try pressing enter.
/ #
现在你有了一个可以执行类似检查文件系统路径或者手动运行容器命令的交互式 shell。
--container 命令指定容器的名字,
否则 kubectl debug 将建立一个新的容器运行你指定的命令。-i 使 kubectl debug 附加到容器。
你可通过指定 --attach=false 来防止这种情况。
如果你的断开连接,可以使用 kubectl attach 重新连接。不要忘了清理调试 Pod:
kubectl delete pod myapp myapp-debug
在某些情况下,你可能想要改动一个行为异常的 Pod,即从其正常的生产容器镜像更改为包含调试构建程序或其他实用程序的镜像。
下面的例子,用 kubectl run 创建一个 Pod:
kubectl run myapp --image=busybox:1.28 --restart=Never -- sleep 1d
现在可以使用 kubectl debug 创建一个拷贝并将其容器镜像更改为 ubuntu:
kubectl debug myapp --copy-to=myapp-debug --set-image=*=ubuntu
--set-image 与 container_name=image 使用相同的 kubectl set image 语法。
*=ubuntu 表示把所有容器的镜像改为 ubuntu。
kubectl delete pod myapp myapp-debug
如果这些方法都不起作用,你可以找到运行 Pod 的节点,然后创建一个 Pod 运行在该节点上。
你可以通过 kubectl debug 在节点上创建一个交互式 Shell:
kubectl debug node/mynode -it --image=ubuntu
Creating debugging pod node-debugger-mynode-pdx84 with container debugger on node mynode.
If you don't see a command prompt, try pressing enter.
root@ek8s:/#
当在节点上创建调试会话,注意以下要点:
kubectl debug 基于节点的名字自动生成新的 Pod 的名字。/host。chroot /host 也可能会失败。当你完成节点调试时,不要忘记清理调试 Pod:
kubectl delete pod node-debugger-mynode-pdx84
本文介绍怎样使用 kubectl exec 命令获取正在运行容器的 Shell。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在本练习中,你将创建包含一个容器的 Pod。容器运行 nginx 镜像。下面是 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: shell-demo
spec:
volumes:
- name: shared-data
emptyDir: {}
containers:
- name: nginx
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
hostNetwork: true
dnsPolicy: Default
创建 Pod:
kubectl apply -f https://k8s.io/examples/application/shell-demo.yaml
检查容器是否运行正常:
kubectl get pod shell-demo
获取正在运行容器的 Shell:
kubectl exec --stdin --tty shell-demo -- /bin/bash
双破折号 "--" 用于将要传递给命令的参数与 kubectl 的参数分开。
在 shell 中,打印根目录:
# 在容器内运行如下命令
ls /
在 shell 中,实验其他命令。下面是一些示例:
# 你可以在容器中运行这些示例命令
ls /
cat /proc/mounts
cat /proc/1/maps
apt-get update
apt-get install -y tcpdump
tcpdump
apt-get install -y lsof
lsof
apt-get install -y procps
ps aux
ps aux | grep nginx
再看一下 Pod 的配置文件。该 Pod 有个 emptyDir 卷,容器将该卷挂载到了 /usr/share/nginx/html。
在 shell 中,在 /usr/share/nginx/html 目录创建一个 index.html 文件:
# 在容器内运行如下命令
echo 'Hello shell demo' > /usr/share/nginx/html/index.html
在 shell 中,向 nginx 服务器发送 GET 请求:
# 在容器内运行如下命令
apt-get update
apt-get install curl
curl http://localhost/
输出结果显示了你在 index.html 中写入的文本。
Hello shell demo
当用完 shell 后,输入 exit 退出。
exit # 快速退出容器内的 Shell
在普通的命令窗口(而不是 shell)中,打印环境运行容器中的变量:
kubectl exec shell-demo -- env
实验运行其他命令。下面是一些示例:
kubectl exec shell-demo -- ps aux
kubectl exec shell-demo -- ls /
kubectl exec shell-demo -- cat /proc/1/mounts
如果 Pod 有多个容器,--container 或者 -c 可以在 kubectl exec 命令中指定容器。
例如,你有个名为 my-pod 的 Pod,该 Pod 有两个容器分别为 main-app 和 healper-app。
下面的命令将会打开一个 shell 访问 main-app 容器。
kubectl exec -i -t my-pod --container main-app -- /bin/bash
短的命令参数 -i 和 -t 与长的命令参数 --stdin 和 --tty 作用相同。
你可以通过在一个目录中存储多个对象配置文件、并使用 kubectl apply
来递归地创建和更新对象来创建、更新和删除 Kubernetes 对象。
这种方法会保留对现有对象已作出的修改,而不会将这些更改写回到对象配置文件中。
kubectl diff 也会给你呈现 apply 将作出的变更的预览。
安装 kubectl。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
kubectl 工具能够支持三种对象管理方式:
关于每种对象管理的优缺点的讨论,可参见 Kubernetes 对象管理。
声明式对象管理需要用户对 Kubernetes 对象定义和配置有比较深刻的理解。 如果你还没有这方面的知识储备,请先阅读下面的文档:
以下是本文档中使用的术语的定义:
kubectl apply。
配置文件通常存储于类似 Git 这种源码控制系统中。kubectl apply 命令以写入变更。使用 kubectl apply 来创建指定目录中配置文件所定义的所有对象,除非对应对象已经存在:
kubectl apply -f <目录>
此操作会在每个对象上设置 kubectl.kubernetes.io/last-applied-configuration: '{...}'
注解。注解值中包含了用来创建对象的配置文件的内容。
添加 -R 标志可以递归地处理目录。
下面是一个对象配置文件示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
执行 kubectl diff 可以打印出将被创建的对象:
kubectl diff -f https://k8s.io/examples/application/simple_deployment.yaml
diff 使用服务器端试运行(Server-side Dry-run)
功能特性;而该功能特性需要在 kube-apiserver 上启用。
由于 diff 操作会使用试运行模式执行服务器端 apply 请求,因此需要为用户配置
PATCH、CREATE 和 UPDATE 操作权限。
参阅试运行授权了解详情。
使用 kubectl apply 来创建对象:
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
使用 kubectl get 打印其现时配置:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示注解 kubectl.kubernetes.io/last-applied-configuration
被写入到现时配置中,并且其内容与配置文件相同:
kind: Deployment
metadata:
annotations:
# ...
# 此为 simple_deployment.yaml 的 JSON 表示
# 在对象创建时由 kubectl apply 命令写入
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
# ...
minReadySeconds: 5
selector:
matchLabels:
# ...
app: nginx
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.14.2
# ...
name: nginx
ports:
- containerPort: 80
# ...
# ...
# ...
# ...
你也可以使用 kubectl apply 来更新某个目录中定义的所有对象,即使那些对象已经存在。
这一操作会隐含以下行为:
kubectl diff -f <目录>
kubectl apply -f <目录>
使用 -R 标志递归处理目录。
下面是一个配置文件示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
使用 kubectl apply 来创建对象:
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
出于演示的目的,上面的命令引用的是单个文件而不是整个目录。
使用 kubectl get 打印现时配置:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示,注解 kubectl.kubernetes.io/last-applied-configuration
被写入到现时配置中,并且其取值与配置文件内容相同。
kind: Deployment
metadata:
annotations:
# ...
# 此为 simple_deployment.yaml 的 JSON 表示
# 在对象创建时由 kubectl apply 命令写入
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
# ...
minReadySeconds: 5
selector:
matchLabels:
# ...
app: nginx
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.14.2
# ...
name: nginx
ports:
- containerPort: 80
# ...
# ...
# ...
# ...
通过 kubectl scale 命令直接更新现时配置中的 replicas 字段。
这一命令没有使用 kubectl apply:
kubectl scale deployment/nginx-deployment --replicas=2
使用 kubectl get 来打印现时配置:
kubectl get deployment nginx-deployment -o yaml
输出显示,replicas 字段已经被设置为 2,而 last-applied-configuration
注解中并不包含 replicas 字段。
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
# ...
# 注意注解中并不包含 replicas
# 这是因为更新并不是通过 kubectl apply 来执行的
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
replicas: 2 # 由 scale 命令填写
# ...
minReadySeconds: 5
selector:
matchLabels:
# ...
app: nginx
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.14.2
# ...
name: nginx
ports:
- containerPort: 80
# ...
现在更新 simple_deployment.yaml 配置文件,将镜像文件从
nginx:1.14.2 更改为 nginx:1.16.1,同时删除minReadySeconds 字段:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1 # 更新该镜像
ports:
- containerPort: 80
应用对配置文件所作更改:
kubectl diff -f https://k8s.io/examples/application/update_deployment.yaml
kubectl apply -f https://k8s.io/examples/application/update_deployment.yaml
使用 kubectl get 打印现时配置:
kubectl get -f https://k8s.io/examples/application/update_deployment.yaml -o yaml
输出显示现时配置中发生了以下更改:
replicas 保留了 kubectl scale 命令所设置的值:2;
之所以该字段被保留是因为配置文件中并没有设置 replicas。image 的内容已经从 nginx:1.14.2 更改为 nginx:1.16.1。last-applied-configuration 内容被更改为新的镜像名称。minReadySeconds 被移除。last-applied-configuration 中不再包含 minReadySeconds 字段。apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
# ...
# 注解中包含更新后的镜像 nginx 1.16.1
# 但是其中并不包含更改后的 replicas 值 2
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.16.1","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
replicas: 2 # 由 `kubectl scale` 设置,被 `kubectl apply` 命令忽略
# minReadySeconds 被 `kubectl apply` 清除
# ...
selector:
matchLabels:
# ...
app: nginx
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.16.1 # 由 `kubectl apply` 设置
# ...
name: nginx
ports:
- containerPort: 80
# ...
# ...
# ...
# ...
将 kubectl apply 与指令式对象配置命令 kubectl create 或 kubectl replace
混合使用是不受支持的。这是因为 create 和 replace 命令都不会保留
kubectl apply 用来计算更新内容所使用的
kubectl.kubernetes.io/last-applied-configuration 注解值。
有两种方法来删除 kubectl apply 管理的对象。
kubectl delete -f <文件名>使用指令式命令来手动删除对象是建议的方法,因为这种方法更为明确地给出了要删除的内容是什么, 且不容易造成用户不小心删除了其他对象的情况。
kubectl delete -f <文件名>
kubectl apply -f <目录> --prune作为 kubectl delete 操作的替代方式,你可以在本地文件系统的目录中的清单文件被删除之后,
使用 kubectl apply 来辩识要删除的对象。
在 Kubernetes 1.29 中,kubectl apply 可使用两种剪裁模式:
Kubernetes v1.5 [alpha]
在 Allowlist 模式下使用 kubectl apply 命令时要小心使用 --prune 标志。
哪些对象被剪裁取决于 --prune-allowlist、--selector 和 --namespace 标志的值,
并且依赖于作用域中对象的动态发现。特别是在调用之间更改标志值时,这可能会导致对象被意外删除或保留。
要使用基于 Allowlist 的剪裁,可以添加以下标志到你的 kubectl apply 调用:
--prune:删除之前应用的、不在当前调用所传递的集合中的对象。--prune-allowlist:一个需要考虑进行剪裁的组-版本-类别(group-version-kind, GVK)列表。
这个标志是可选的,但强烈建议使用,因为它的默认值是同时作用于命名空间和集群的部分类型列表,
这可能会产生令人意外的结果。--selector/-l:使用标签选择算符以约束要剪裁的对象的集合。此标志是可选的,但强烈建议使用。--all:用于替代 --selector/-l 以显式选择之前应用的类型为 Allowlist 的所有对象。基于 Allowlist 的剪裁会查询 API 服务器以获取与给定标签(如果有)匹配的所有允许列出的 GVK 对象,
并尝试将返回的活动对象配置与对象清单文件进行匹配。如果一个对象与查询匹配,并且它在目录中没有对应的清单,
但它有一个 kubectl.kubernetes.io/last-applied-configuration 注解,则它将被删除。
kubectl apply -f <目录> --prune -l <标签> --prune-allowlist=<gvk 列表>
带剪裁(prune)行为的 apply 操作应在包含对象清单的根目录运行。
如果对象之前被执行了 apply 操作,具有给定的标签(如果有)且未出现在子目录中,
在其子目录中运行可能导致对象被不小心删除。
Kubernetes v1.27 [alpha]
kubectl apply --prune --applyset 目前处于 Alpha 阶段,在后续的版本中可能引入向后不兼容的变更。
要使用基于 ApplySet 的剪裁,请设置 KUBECTL_APPLYSET=true 环境变量,
并添加以下标志到你的 kubectl apply 调用中:
--prune:删除之前应用的、不在当前调用所传递的集合中的对象。--applyset:是 kubectl 可以使用的对象的名称,用于在 apply 操作中准确高效地跟踪集合成员。KUBECTL_APPLYSET=true kubectl apply -f <目录> --prune --applyset=<名称>
默认情况下,所使用的 ApplySet 父对象的类别是 Secret。
不过也可以按格式 --applyset=configmaps/<name> 使用 ConfigMap。
使用 Secret 或 ConfigMap 时,如果对应对象尚不存在,kubectl 将创建这些对象。
还可以使用自定义资源作为 ApplySet 父对象。
要启用此功能,请为定义目标资源的 CRD 打上标签:applyset.kubernetes.io/is-parent-type: true。
然后,创建你想要用作 ApplySet 父级的对象(kubectl 不会自动为自定义资源执行此操作)。
最后,按以下方式在 applyset 标志中引用该对象: --applyset=<resource>.<group>/<name>
(例如 widgets.custom.example.com/widget-name)。
使用基于 ApplySet 的剪裁时,kubectl 会在将集合中的对象发送到服务器之前将标签
applyset.kubernetes.io/part-of=<parentID> 添加到集合中的每个对象上。
出于性能原因,它还会将该集合包含的资源类型和命名空间列表收集到当前父对象上的注解中。
最后,在 apply 操作结束时,它会在 API 服务器上查找由 applyset.kubernetes.io/part-of=<parentID>
标签定义的、属于此集合所对应命名空间(或适用的集群作用域)中对应类型的对象。
注意事项和限制:
--namespace 标志是必需的。这意味着跨越多个命名空间的
ApplySet 必须使用集群作用域的自定义资源作为父对象。你可以使用 kubectl get 并指定 -o yaml 选项来查看现时对象的配置:
kubectl get -f <文件名 | URL> -o yaml
patch 是一种更新操作,其作用域为对象的一些特定字段而不是整个对象。 这使得你可以更新对象的特定字段集合而不必先要读回对象。
kubectl apply 更新对象的现时配置,它是通过向 API 服务器发送一个 patch
请求来执行更新动作的。所提交的补丁中定义了对现时对象配置中特定字段的更新。
kubectl apply 命令会使用当前的配置文件、现时配置以及现时配置中保存的
last-applied-configuration 注解内容来计算补丁更新内容。
kubectl apply 命令将配置文件的内容写入到
kubectl.kubernetes.io/last-applied-configuration 注解中。
这些内容用来识别配置文件中已经移除的、因而也需要从现时配置中删除的字段。
用来计算要删除或设置哪些字段的步骤如下:
last-applied-configuration
中存在但在配置文件中不再存在的字段。下面是一个例子。假定此文件是某 Deployment 对象的配置文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1 # 更新该镜像
ports:
- containerPort: 80
同时假定同一 Deployment 对象的现时配置如下:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
# ...
# 注意注解中并不包含 replicas
# 这是因为更新并不是通过 kubectl apply 来执行的
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.14.2","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
replicas: 2 # 按规模填写
# ...
minReadySeconds: 5
selector:
matchLabels:
# ...
app: nginx
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.14.2
# ...
name: nginx
ports:
- containerPort: 80
# ...
下面是 kubectl apply 将执行的合并计算:
last-applied-configuration 并将其与配置文件中的值相比较,
计算要删除的字段。
对于本地对象配置文件中显式设置为空的字段,清除其在现时配置中的设置,
无论这些字段是否出现在 last-applied-configuration 中。
在此例中,minReadySeconds 出现在 last-applied-configuration 注解中,
但并不存在于配置文件中。
动作: 从现时配置中删除 minReadySeconds 字段。image 值与现时配置中的 image 不匹配。
动作:设置现时配置中的 image 值。last-applied-configuration 注解的内容,使之与配置文件匹配。下面是此合并操作之后形成的现时配置:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
# ...
# 注解中包含更新后的镜像 nginx 1.16.1,
# 但是其中并不包含更改后的 replicas 值 2
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.16.1","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
selector:
matchLabels:
# ...
app: nginx
replicas: 2 # 由 `kubectl scale` 设置,被 `kubectl apply` 命令忽略
# minReadySeconds 此字段被 `kubectl apply` 清除
# ...
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.16.1 # 由 `kubectl apply` 设置
# ...
name: nginx
ports:
- containerPort: 80
# ...
# ...
# ...
# ...
配置文件中的特定字段与现时配置合并时,合并方式取决于字段类型。 字段类型有几种:
基本类型:字段类型为 string、integer 或 boolean 之一。
例如:image 和 replicas 字段都是基本类型字段。
动作: 替换。
map:也称作 object。类型为 map 或包含子域的复杂结构。例如,labels、
annotations、spec 和 metadata 都是 map。
动作: 合并元素或子字段。
list:包含元素列表的字段,其中每个元素可以是基本类型或 map。
例如,containers、ports 和 args 都是 list。
动作: 不一定。
当 kubectl apply 更新某个 map 或 list 字段时,它通常不会替换整个字段,
而是会更新其中的各个子元素。例如,当合并 Deployment 的 spec 时,kubectl
并不会将其整个替换掉。相反,实际操作会是对 replicas 这类 spec
的子字段来执行比较和更新。
基本类型字段会被替换或清除。
- 表示的是“不适用”,因为指定数值未被使用。
| 字段在对象配置文件中 | 字段在现时对象配置中 | 字段在 last-applied-configuration 中 |
动作 |
|---|---|---|---|
| 是 | 是 | - | 将配置文件中值设置到现时配置上。 |
| 是 | 否 | - | 将配置文件中值设置到现时配置上。 |
| 否 | - | 是 | 从现时配置中移除。 |
| 否 | - | 否 | 什么也不做。保持现时值。 |
用来表示映射的字段在合并时会逐个子字段或元素地比较:
- 表示的是“不适用”,因为指定数值未被使用。
| 键存在于对象配置文件中 | 键存在于现时对象配置中 | 键存在于 last-applied-configuration 中 |
动作 |
|---|---|---|---|
| 是 | 是 | - | 比较子域取值。 |
| 是 | 否 | - | 将现时配置设置为本地配置值。 |
| 否 | - | 是 | 从现时配置中删除键。 |
| 否 | - | 否 | 什么也不做,保留现时值。 |
对 list 类型字段的变更合并会使用以下三种策略之一:
策略的选择是基于各个字段做出的。
将整个 list 视为一个基本类型字段。或者整个替换或者整个删除。 此操作会保持 list 中元素顺序不变
示例: 使用 kubectl apply 来更新 Pod 中 Container 的 args 字段。
此操作会将现时配置中的 args 值设为配置文件中的值。
所有之前添加到现时配置中的 args 元素都会丢失。
配置文件中的 args 元素的顺序在被添加到现时配置中时保持不变。
# last-applied-configuration 值
args: ["a", "b"]
# 配置文件值
args: ["a", "c"]
# 现时配置
args: ["a", "b", "d"]
# 合并结果
args: ["a", "c"]
解释: 合并操作将配置文件中的值当做新的 list 值。
此操作将 list 视为 map,并将每个元素中的特定字段当做其主键。 逐个元素地执行添加、删除或更新操作。结果顺序无法得到保证。
此合并策略会使用每个字段上的一个名为 patchMergeKey 的特殊标签。
Kubernetes 源代码中为每个字段定义了 patchMergeKey:
types.go。
当合并由 map 组成的 list 时,给定元素中被设置为 patchMergeKey
的字段会被当做该元素的 map 键值来使用。
例如: 使用 kubectl apply 来更新 Pod 规约中的 containers 字段。
此操作会将 containers 列表视作一个映射来执行合并,每个元素的主键为 name。
# last-applied-configuration 值
containers:
- name: nginx
image: nginx:1.16
- name: nginx-helper-a # 键 nginx-helper-a 会被删除
image: helper:1.3
- name: nginx-helper-b # 键 nginx-helper-b 会被保留
image: helper:1.3
# 配置文件值
containers:
- name: nginx
image: nginx:1.16
- name: nginx-helper-b
image: helper:1.3
- name: nginx-helper-c # 键 nginx-helper-c 会被添加
image: helper:1.3
# 现时配置
containers:
- name: nginx
image: nginx:1.16
- name: nginx-helper-a
image: helper:1.3
- name: nginx-helper-b
image: helper:1.3
args: ["run"] # 字段会被保留
- name: nginx-helper-d # 键 nginx-helper-d 会被保留
image: helper:1.3
# 合并结果
containers:
- name: nginx
image: nginx:1.16
# 元素 nginx-helper-a 被删除
- name: nginx-helper-b
image: helper:1.3
args: ["run"] # 字段被保留
- name: nginx-helper-c # 新增元素
image: helper:1.3
- name: nginx-helper-d # 此元素被忽略(保留)
image: helper:1.3
解释:
args 被保留。
kubectl apply 能够辩识出现时配置中的容器 "nginx-helper-b" 与配置文件
中的容器 "nginx-helper-b" 相同,即使它们的字段值有些不同(配置文件中未给定
args 值)。这是因为 patchMergeKey 字段(name)的值在两个版本中都一样。在 Kubernetes 1.5 中,尚不支持对由基本类型元素构成的 list 进行合并。
选择上述哪种策略是由源码中给定字段的 patchStrategy 标记来控制的:
types.go。
如果 list 类型字段未设置 patchStrategy,则整个 list 会被替换掉。
API 服务器会在对象创建时其中某些字段未设置的情况下在现时配置中为其设置默认值。
下面是一个 Deployment 的配置文件。文件未设置 strategy:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
使用 kubectl apply 创建对象:
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
使用 kubectl get 打印现时配置:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示 API 在现时配置中为某些字段设置了默认值。 这些字段在配置文件中并未设置。
apiVersion: apps/v1
kind: Deployment
# ...
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
replicas: 1 # API 服务器所设默认值
strategy:
rollingUpdate: # API 服务器基于 strategy.type 所设默认值
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate # API 服务器所设默认值
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.14.2
imagePullPolicy: IfNotPresent # API 服务器所设默认值
name: nginx
ports:
- containerPort: 80
protocol: TCP # API 服务器所设默认值
resources: {} # API 服务器所设默认值
terminationMessagePath: /dev/termination-log # API 服务器所设默认值
dnsPolicy: ClusterFirst # API 服务器所设默认值
restartPolicy: Always # API 服务器所设默认值
securityContext: {} # API 服务器所设默认值
terminationGracePeriodSeconds: 30 # API 服务器所设默认值
# ...
在补丁请求中,已经设置了默认值的字段不会被重新设回其默认值, 除非在补丁请求中显式地要求清除。对于默认值取决于其他字段的某些字段而言, 这可能会引发一些意想不到的行为。当所依赖的其他字段后来发生改变时, 基于它们所设置的默认值只能在显式执行清除操作时才会被更新。
为此,建议在配置文件中为服务器设置默认值的字段显式提供定义, 即使所给的定义与服务器端默认值设定相同。 这样可以使得辩识无法被服务器重新基于默认值来设置的冲突字段变得容易。
示例:
# last-applied-configuration
spec:
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# 配置文件
spec:
strategy:
type: Recreate # 更新的值
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# 现时配置
spec:
strategy:
type: RollingUpdate # 默认设置的值
rollingUpdate: # 基于 type 设置的默认值
maxSurge : 1
maxUnavailable: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
# 合并后的结果 - 出错!
spec:
strategy:
type: Recreate # 更新的值:与 rollingUpdate 不兼容
rollingUpdate: # 默认设置的值:与 "type: Recreate" 冲突
maxSurge : 1
maxUnavailable: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
解释:
strategy.type。strategy.type 设置默认值 RollingUpdate,并为 strategy.rollingUpdate
设置默认值。strategy.type 为 Recreate。字段 strategy.rollingUpdate
仍会取其默认设置值,尽管服务器期望该字段被清除。
如果 strategy.rollingUpdate 值最初于配置文件中定义,
则它们需要被清除这一点就更明确一些。apply 操作失败,因为 strategy.rollingUpdate 未被清除。
strategy.rollingupdate 在 strategy.type 为 Recreate 不可被设定。建议:以下字段应该在对象配置文件中显式定义:
PodTemplate 标签没有出现在配置文件中的字段可以通过将其值设置为 null 并应用配置文件来清除。
对于由服务器按默认值设置的字段,清除操作会触发重新为字段设置新的默认值。
更改某个对象字段时,应该采用下面的方法:
kubectl apply.kubectl scale。将字段添加到配置文件。针对该字段,不再直接执行对现时配置的修改。
修改均通过 kubectl apply 来执行。
在 Kubernetes 1.5 中,将字段的属主从配置文件切换到某指令式写者需要手动执行以下步骤:
kubectl.kubernetes.io/last-applied-configuration
注解中删除。Kubernetes 对象在同一时刻应该只用一种方法来管理。 从一种方法切换到另一种方法是可能的,但这一切换是一个手动过程。
在声明式管理方法中使用指令式命令来删除对象是可以的。
从指令式命令管理切换到声明式对象配置管理的切换包含以下几个手动步骤:
将现时对象导出到本地配置文件:
kubectl get <kind>/<name> -o yaml > <kind>_<name>.yaml
手动移除配置文件中的 status 字段。
这一步骤是可选的,因为 kubectl apply 并不会更新 status 字段,
即便配置文件中包含 status 字段。
设置对象上的 kubectl.kubernetes.io/last-applied-configuration 注解:
kubectl replace --save-config -f <kind>_<name>.yaml
更改过程,使用 kubectl apply 专门管理对象。
在对象上设置 kubectl.kubernetes.io/last-applied-configuration 注解:
kubectl replace --save-config -f <kind>_<name>.yaml
自此排他性地使用 kubectl apply 来管理对象。
强烈不建议更改控制器上的选择算符。
建议的方法是定义一个不可变更的 PodTemplate 标签, 仅用于控制器选择算符且不包含其他语义性的含义。
示例:
selector:
matchLabels:
controller-selector: "apps/v1/deployment/nginx"
template:
metadata:
labels:
controller-selector: "apps/v1/deployment/nginx"
Kustomize 是一个独立的工具,用来通过 kustomization 文件 定制 Kubernetes 对象。
从 1.14 版本开始,kubectl 也开始支持使用 kustomization 文件来管理 Kubernetes 对象。
要查看包含 kustomization 文件的目录中的资源,执行下面的命令:
kubectl kustomize <kustomization_directory>
要应用这些资源,使用 --kustomize 或 -k 参数来执行 kubectl apply:
kubectl apply -k <kustomization_directory>
安装 kubectl。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
Kustomize 是一个用来定制 Kubernetes 配置的工具。它提供以下功能特性来管理应用配置文件:
ConfigMap 和 Secret 包含其他 Kubernetes 对象(如 Pod)所需要的配置或敏感数据。
ConfigMap 或 Secret 中数据的来源往往是集群外部,例如某个 .properties 文件或者 SSH 密钥文件。
Kustomize 提供 secretGenerator 和 configMapGenerator,可以基于文件或字面值来生成 Secret 和 ConfigMap。
要基于文件来生成 ConfigMap,可以在 configMapGenerator 的 files
列表中添加表项。
下面是一个根据 .properties 文件中的数据条目来生成 ConfigMap 的示例:
# 生成一个 application.properties 文件
cat <<EOF >application.properties
FOO=Bar
EOF
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: example-configmap-1
files:
- application.properties
EOF
所生成的 ConfigMap 可以使用下面的命令来检查:
kubectl kustomize ./
所生成的 ConfigMap 为:
apiVersion: v1
data:
application.properties: |
FOO=Bar
kind: ConfigMap
metadata:
name: example-configmap-1-8mbdf7882g
要从 env 文件生成 ConfigMap,请在 configMapGenerator 中的 envs 列表中添加一个条目。
下面是一个用来自 .env 文件的数据生成 ConfigMap 的例子:
# 创建一个 .env 文件
cat <<EOF >.env
FOO=Bar
EOF
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: example-configmap-1
envs:
- .env
EOF
可以使用以下命令检查生成的 ConfigMap:
kubectl kustomize ./
生成的 ConfigMap 为:
apiVersion: v1
data:
FOO: Bar
kind: ConfigMap
metadata:
name: example-configmap-1-42cfbf598f
.env 文件中的每个变量在生成的 ConfigMap 中成为一个单独的键。这与之前的示例不同,
前一个示例将一个名为 application.properties 的文件(及其所有条目)嵌入到同一个键的值中。
ConfigMap 也可基于字面的键值偶对来生成。要基于键值偶对来生成 ConfigMap,
在 configMapGenerator 的 literals 列表中添加表项。下面是一个例子,
展示如何使用键值偶对中的数据条目来生成 ConfigMap 对象:
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: example-configmap-2
literals:
- FOO=Bar
EOF
可以用下面的命令检查所生成的 ConfigMap:
kubectl kustomize ./
所生成的 ConfigMap 为:
apiVersion: v1
data:
FOO: Bar
kind: ConfigMap
metadata:
name: example-configmap-2-g2hdhfc6tk
要在 Deployment 中使用生成的 ConfigMap,使用 configMapGenerator 的名称对其进行引用。 Kustomize 将自动使用生成的名称替换该名称。
这是使用生成的 ConfigMap 的 deployment 示例:
# 创建一个 application.properties 文件
cat <<EOF >application.properties
FOO=Bar
EOF
cat <<EOF >deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: app
image: my-app
volumeMounts:
- name: config
mountPath: /config
volumes:
- name: config
configMap:
name: example-configmap-1
EOF
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
configMapGenerator:
- name: example-configmap-1
files:
- application.properties
EOF
生成 ConfigMap 和 Deployment:
kubectl kustomize ./
生成的 Deployment 将通过名称引用生成的 ConfigMap:
apiVersion: v1
data:
application.properties: |
FOO=Bar
kind: ConfigMap
metadata:
name: example-configmap-1-g4hk9g2ff8
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-app
name: my-app
spec:
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- image: my-app
name: app
volumeMounts:
- mountPath: /config
name: config
volumes:
- configMap:
name: example-configmap-1-g4hk9g2ff8
name: config
你可以基于文件或者键值偶对来生成 Secret。要使用文件内容来生成 Secret,
在 secretGenerator 下面的 files 列表中添加表项。
下面是一个根据文件中数据来生成 Secret 对象的示例:
# 创建一个 password.txt 文件
cat <<EOF >./password.txt
username=admin
password=secret
EOF
cat <<EOF >./kustomization.yaml
secretGenerator:
- name: example-secret-1
files:
- password.txt
EOF
所生成的 Secret 如下:
apiVersion: v1
data:
password.txt: dXNlcm5hbWU9YWRtaW4KcGFzc3dvcmQ9c2VjcmV0Cg==
kind: Secret
metadata:
name: example-secret-1-t2kt65hgtb
type: Opaque
要基于键值偶对字面值生成 Secret,先要在 secretGenerator 的 literals
列表中添加表项。下面是基于键值偶对中数据条目来生成 Secret 的示例:
cat <<EOF >./kustomization.yaml
secretGenerator:
- name: example-secret-2
literals:
- username=admin
- password=secret
EOF
所生成的 Secret 如下:
apiVersion: v1
data:
password: c2VjcmV0
username: YWRtaW4=
kind: Secret
metadata:
name: example-secret-2-t52t6g96d8
type: Opaque
与 ConfigMap 一样,生成的 Secret 可以通过引用 secretGenerator 的名称在 Deployment 中使用:
# 创建一个 password.txt 文件
cat <<EOF >./password.txt
username=admin
password=secret
EOF
cat <<EOF >deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: app
image: my-app
volumeMounts:
- name: password
mountPath: /secrets
volumes:
- name: password
secret:
secretName: example-secret-1
EOF
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
secretGenerator:
- name: example-secret-1
files:
- password.txt
EOF
所生成的 ConfigMap 和 Secret 都会包含内容哈希值后缀。
这是为了确保内容发生变化时,所生成的是新的 ConfigMap 或 Secret。
要禁止自动添加后缀的行为,用户可以使用 generatorOptions。
除此以外,为生成的 ConfigMap 和 Secret 指定贯穿性选项也是可以的。
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: example-configmap-3
literals:
- FOO=Bar
generatorOptions:
disableNameSuffixHash: true
labels:
type: generated
annotations:
note: generated
EOF
运行 kubectl kustomize ./ 来查看所生成的 ConfigMap:
apiVersion: v1
data:
FOO: Bar
kind: ConfigMap
metadata:
annotations:
note: generated
labels:
type: generated
name: example-configmap-3
在项目中为所有 Kubernetes 对象设置贯穿性字段是一种常见操作。 贯穿性字段的一些使用场景如下:
下面是一个例子:
# 创建一个 deployment.yaml
cat <<EOF >./deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
EOF
cat <<EOF >./kustomization.yaml
namespace: my-namespace
namePrefix: dev-
nameSuffix: "-001"
commonLabels:
app: bingo
commonAnnotations:
oncallPager: 800-555-1212
resources:
- deployment.yaml
EOF
执行 kubectl kustomize ./ 查看这些字段都被设置到 Deployment 资源上:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
oncallPager: 800-555-1212
labels:
app: bingo
name: dev-nginx-deployment-001
namespace: my-namespace
spec:
selector:
matchLabels:
app: bingo
template:
metadata:
annotations:
oncallPager: 800-555-1212
labels:
app: bingo
spec:
containers:
- image: nginx
name: nginx
一种常见的做法是在项目中构造资源集合并将其放到同一个文件或目录中管理。 Kustomize 提供基于不同文件来组织资源并向其应用补丁或者其他定制的能力。
Kustomize 支持组合不同的资源。kustomization.yaml 文件的 resources 字段定义配置中要包含的资源列表。
你可以将 resources 列表中的路径设置为资源配置文件的路径。
下面是由 Deployment 和 Service 构成的 NGINX 应用的示例:
# 创建 deployment.yaml 文件
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
# 创建 service.yaml 文件
cat <<EOF > service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF
# 创建 kustomization.yaml 来组织以上两个资源
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
- service.yaml
EOF
kubectl kustomize ./ 所得到的资源中既包含 Deployment 也包含 Service 对象。
补丁文件(Patches)可以用来对资源执行不同的定制。
Kustomize 通过 patchesStrategicMerge 和 patchesJson6902 支持不同的打补丁机制。
patchesStrategicMerge 的内容是一个文件路径的列表,其中每个文件都应可解析为
策略性合并补丁(Strategic Merge Patch)。
补丁文件中的名称必须与已经加载的资源的名称匹配。
建议构造规模较小的、仅做一件事情的补丁。
例如,构造一个补丁来增加 Deployment 的副本个数;构造另外一个补丁来设置内存限制。
# 创建 deployment.yaml 文件
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
# 生成一个补丁 increase_replicas.yaml
cat <<EOF > increase_replicas.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
EOF
# 生成另一个补丁 set_memory.yaml
cat <<EOF > set_memory.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
template:
spec:
containers:
- name: my-nginx
resources:
limits:
memory: 512Mi
EOF
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
patchesStrategicMerge:
- increase_replicas.yaml
- set_memory.yaml
EOF
执行 kubectl kustomize ./ 来查看 Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
ports:
- containerPort: 80
resources:
limits:
memory: 512Mi
并非所有资源或者字段都支持策略性合并补丁。为了支持对任何资源的任何字段进行修改,
Kustomize 提供通过 patchesJson6902 来应用 JSON 补丁的能力。
为了给 JSON 补丁找到正确的资源,需要在 kustomization.yaml 文件中指定资源的组(group)、
版本(version)、类别(kind)和名称(name)。
例如,为某 Deployment 对象增加副本个数的操作也可以通过 patchesJson6902 来完成:
# 创建一个 deployment.yaml 文件
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
# 创建一个 JSON 补丁文件
cat <<EOF > patch.yaml
- op: replace
path: /spec/replicas
value: 3
EOF
# 创建一个 kustomization.yaml
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
patchesJson6902:
- target:
group: apps
version: v1
kind: Deployment
name: my-nginx
path: patch.yaml
EOF
执行 kubectl kustomize ./ 以查看 replicas 字段被更新:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 3
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: nginx
name: my-nginx
ports:
- containerPort: 80
除了补丁之外,Kustomize 还提供定制容器镜像或者将其他对象的字段值注入到容器中的能力,并且不需要创建补丁。
例如,你可以通过在 kustomization.yaml 文件的 images 字段设置新的镜像来更改容器中使用的镜像。
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
cat <<EOF >./kustomization.yaml
resources:
- deployment.yaml
images:
- name: nginx
newName: my.image.registry/nginx
newTag: 1.4.0
EOF
执行 kubectl kustomize ./ 以查看所使用的镜像已被更新:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 2
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- image: my.image.registry/nginx:1.4.0
name: my-nginx
ports:
- containerPort: 80
有些时候,Pod 中运行的应用可能需要使用来自其他对象的配置值。
例如,某 Deployment 对象的 Pod 需要从环境变量或命令行参数中读取读取
Service 的名称。
由于在 kustomization.yaml 文件中添加 namePrefix 或 nameSuffix 时
Service 名称可能发生变化,建议不要在命令参数中硬编码 Service 名称。
对于这种使用场景,Kustomize 可以通过 vars 将 Service 名称注入到容器中。
# 创建一个 deployment.yaml 文件(引用此处的文档分隔符)
cat <<'EOF' > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
command: ["start", "--host", "$(MY_SERVICE_NAME)"]
EOF
# 创建一个 service.yaml 文件
cat <<EOF > service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF
cat <<EOF >./kustomization.yaml
namePrefix: dev-
nameSuffix: "-001"
resources:
- deployment.yaml
- service.yaml
vars:
- name: MY_SERVICE_NAME
objref:
kind: Service
name: my-nginx
apiVersion: v1
EOF
执行 kubectl kustomize ./ 以查看注入到容器中的 Service 名称是 dev-my-nginx-001:
apiVersion: apps/v1
kind: Deployment
metadata:
name: dev-my-nginx-001
spec:
replicas: 2
selector:
matchLabels:
run: my-nginx
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- command:
- start
- --host
- dev-my-nginx-001
image: nginx
name: my-nginx
Kustomize 中有 基准(bases) 和 覆盖(overlays) 的概念区分。
基准 是包含 kustomization.yaml 文件的一个目录,其中包含一组资源及其相关的定制。
基准可以是本地目录或者来自远程仓库的目录,只要其中存在 kustomization.yaml 文件即可。
覆盖 也是一个目录,其中包含将其他 kustomization 目录当做 bases 来引用的
kustomization.yaml 文件。
基准不了解覆盖的存在,且可被多个覆盖所使用。
覆盖则可以有多个基准,且可针对所有基准中的资源执行组织操作,还可以在其上执行定制。
# 创建一个包含基准的目录
mkdir base
# 创建 base/deployment.yaml
cat <<EOF > base/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
EOF
# 创建 base/service.yaml 文件
cat <<EOF > base/service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF
# 创建 base/kustomization.yaml
cat <<EOF > base/kustomization.yaml
resources:
- deployment.yaml
- service.yaml
EOF
此基准可在多个覆盖中使用。你可以在不同的覆盖中添加不同的 namePrefix 或其他贯穿性字段。
下面是两个使用同一基准的覆盖:
mkdir dev
cat <<EOF > dev/kustomization.yaml
resources:
- ../base
namePrefix: dev-
EOF
mkdir prod
cat <<EOF > prod/kustomization.yaml
resources:
- ../base
namePrefix: prod-
EOF
在 kubectl 命令中使用 --kustomize 或 -k 参数来识别被 kustomization.yaml 所管理的资源。
注意 -k 要指向一个 kustomization 目录。例如:
kubectl apply -k <kustomization 目录>/
假定使用下面的 kustomization.yaml:
# 创建 deployment.yaml 文件
cat <<EOF > deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 80
EOF
# 创建 kustomization.yaml
cat <<EOF >./kustomization.yaml
namePrefix: dev-
commonLabels:
app: my-nginx
resources:
- deployment.yaml
EOF
执行下面的命令来应用 Deployment 对象 dev-my-nginx:
> kubectl apply -k ./
deployment.apps/dev-my-nginx created
运行下面的命令之一来查看 Deployment 对象 dev-my-nginx:
kubectl get -k ./
kubectl describe -k ./
执行下面的命令来比较 Deployment 对象 dev-my-nginx 与清单被应用之后集群将处于的状态:
kubectl diff -k ./
执行下面的命令删除 Deployment 对象 dev-my-nginx:
> kubectl delete -k ./
deployment.apps "dev-my-nginx" deleted
| 字段 | 类型 | 解释 |
|---|---|---|
| namespace | string | 为所有资源添加名字空间 |
| namePrefix | string | 此字段的值将被添加到所有资源名称前面 |
| nameSuffix | string | 此字段的值将被添加到所有资源名称后面 |
| commonLabels | map[string]string | 要添加到所有资源和选择算符的标签 |
| commonAnnotations | map[string]string | 要添加到所有资源的注解 |
| resources | []string | 列表中的每个条目都必须能够解析为现有的资源配置文件 |
| configMapGenerator | []ConfigMapArgs | 列表中的每个条目都会生成一个 ConfigMap |
| secretGenerator | []SecretArgs | 列表中的每个条目都会生成一个 Secret |
| generatorOptions | GeneratorOptions | 更改所有 ConfigMap 和 Secret 生成器的行为 |
| bases | []string | 列表中每个条目都应能解析为一个包含 kustomization.yaml 文件的目录 |
| patchesStrategicMerge | []string | 列表中每个条目都能解析为某 Kubernetes 对象的策略性合并补丁 |
| patchesJson6902 | []Patch | 列表中每个条目都能解析为一个 Kubernetes 对象和一个 JSON 补丁 |
| vars | []Var | 每个条目用来从某资源的字段来析取文字 |
| images | []Image | 每个条目都用来更改镜像的名称、标记与/或摘要,不必生成补丁 |
| configurations | []string | 列表中每个条目都应能解析为一个包含 Kustomize 转换器配置 的文件 |
| crds | []string | 列表中每个条目都应能够解析为 Kubernetes 类别的 OpenAPI 定义文件 |
使用构建在 kubectl 命令行工具中的指令式命令可以直接快速创建、更新和删除
Kubernetes 对象。本文档解释这些命令的组织方式以及如何使用它们来管理活跃对象。
安装kubectl。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
kubectl 工具能够支持三种对象管理方式:
关于每种对象管理的优缺点的讨论,可参见 Kubernetes 对象管理。
kubectl 工具支持动词驱动的命令,用来创建一些最常见的对象类别。
命令的名称设计使得不熟悉 Kubernetes 对象类型的用户也能做出判断。
run:创建一个新的 Pod 来运行一个容器。expose:创建一个新的 Service 对象为若干 Pod 提供流量负载均衡。autoscale:创建一个新的 Autoscaler 对象来自动对某控制器(例如:Deployment)
执行水平扩缩。kubectl 命令也支持一些对象类型驱动的创建命令。
这些命令可以支持更多的对象类别,并且在其动机上体现得更为明显,
不过要求用户了解它们所要创建的对象的类别。
create <对象类别> [<子类别>] <实例名称>某些对象类别拥有自己的子类别,可以在 create 命令中设置。
例如,Service 对象有 ClusterIP、LoadBalancer 和 NodePort 三种子类别。
下面是一个创建 NodePort 子类别的 Service 的示例:
kubectl create service nodeport <服务名称>
在前述示例中,create service nodeport 命令也称作 create service
命令的子命令。
可以使用 -h 标志找到一个子命令所支持的参数和标志。
kubectl create service nodeport -h
kubectl 命令也支持一些动词驱动的命令,用来执行一些常见的更新操作。
这些命令的设计是为了让一些不了解 Kubernetes 对象的用户也能执行更新操作,
但不需要了解哪些字段必须设置:
scale:对某控制器进行水平扩缩以便通过更新控制器的副本个数来添加或删除 Pod。annotate:为对象添加或删除注解。label:为对象添加或删除标签。kubectl 命令也支持由对象的某一方面来驱动的更新命令。
设置对象的这一方面可能对不同类别的对象意味着不同的字段:
set <字段>:设置对象的某一方面。在 Kubernetes 1.5 版本中,并非所有动词驱动的命令都有对应的方面驱动的命令。
kubectl 工具支持以下额外的方式用来直接更新活跃对象,不过这些操作要求
用户对 Kubernetes 对象的模式定义有很好的了解:
edit:通过在编辑器中打开活跃对象的配置,直接编辑其原始配置。patch:通过使用补丁字符串(Patch String)直接更改某活跃对象的特定字段。
关于补丁字符串的更详细信息,参见
API 约定
的 patch 节。你可以使用 delete 命令从集群中删除一个对象:
delete <类别>/<名称>你可以使用 kubectl delete 来执行指令式命令或者指令式对象配置。不同之处在于传递给命令的参数。
要将 kubectl delete 作为指令式命令使用,将要删除的对象作为参数传递给它。
下面是一个删除名为 nginx 的 Deployment 对象的命令:
kubectl delete deployment/nginx
用来打印对象信息的命令有好几个:
get:打印匹配到的对象的基本信息。使用 get -h 可以查看选项列表。describe:打印匹配到的对象的详细信息的汇集版本。logs:打印 Pod 中运行的容器的 stdout 和 stderr 输出。set 命令在创建对象之前修改对象 有些对象字段在 create 命令中没有对应的标志。
在这些场景中,你可以使用 set 和 create 命令的组合来在对象创建之前设置字段值。
这是通过将 create 命令的输出用管道方式传递给 set 命令来实现的,最后执行 create 命令来创建对象。
下面是一个例子:
kubectl create service clusterip my-svc --clusterip="None" -o yaml --dry-run=client | kubectl set selector --local -f - 'environment=qa' -o yaml | kubectl create -f -
kubectl create service -o yaml --dry-run=client 创建 Service 的配置,
但将其以 YAML 格式在标准输出上打印而不是发送给 API 服务器。kubectl set selector --local -f - -o yaml 从标准输入读入配置,
并将更新后的配置以 YAML 格式输出到标准输出。kubectl create -f - 使用标准输入上获得的配置创建对象。--edit 更改对象你可以用 kubectl create --edit 来在对象被创建之前执行任意的变更。
下面是一个例子:
kubectl create service clusterip my-svc --clusterip="None" -o yaml --dry-run=client > /tmp/srv.yaml
kubectl create --edit -f /tmp/srv.yaml
kubectl create service 创建 Service 的配置并将其保存到 /tmp/srv.yaml 文件。kubectl create --edit 在创建 Service 对象打开其配置文件进行编辑。可以使用 kubectl 命令行工具以及用 YAML 或 JSON 编写的对象配置文件来创建、更新和删除 Kubernetes 对象。
本文档说明了如何使用配置文件定义和管理对象。
安装 kubectl。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
kubectl 工具支持三种对象管理:
参见 Kubernetes 对象管理 中关于每种对象管理的优缺点的讨论。
你可以使用 kubectl create -f 从配置文件创建一个对象。
更多细节参阅 kubernetes API 参考。
kubectl create -f <filename|url>使用 replace 命令更新对象会删除所有未在配置文件中指定的规范的某些部分。
不应将其规范由集群部分管理的对象使用,比如类型为 LoadBalancer 的服务,
其中 externalIPs 字段独立于配置文件进行管理。
必须将独立管理的字段复制到配置文件中,以防止 replace 删除它们。
你可以使用 kubectl replace -f 根据配置文件更新活动对象。
kubectl replace -f <filename|url>你可以使用 kubectl delete -f 删除配置文件中描述的对象。
kubectl delete -f <filename|url>如果配置文件在 metadata 节中设置了 generateName 字段而非 name 字段,
你无法使用 kubectl delete -f <filename|url> 来删除该对象。
你必须使用其他标志才能删除对象。例如:
kubectl delete <type> <name>
kubectl delete <type> -l <label>
你可以使用 kubectl get -f 查看有关配置文件中描述的对象的信息。
kubectl get -f <filename|url> -o yaml-o yaml 标志指定打印完整的对象配置。使用 kubectl get -h 查看选项列表。
当完全定义每个对象的配置并将其记录在其配置文件中时,create、 replace 和delete 命令会很好的工作。
但是,当更新一个活动对象,并且更新没有合并到其配置文件中时,下一次执行 replace 时,更新将丢失。
如果控制器,例如 HorizontalPodAutoscaler ,直接对活动对象进行更新,则会发生这种情况。
这有一个例子:
如果需要支持同一对象的多个编写器,则可以使用 kubectl apply 来管理该对象。
假设你具有对象配置文件的 URL。
你可以在创建对象之前使用 kubectl create --edit 对配置进行更改。
这对于指向可以由读者修改的配置文件的教程和任务特别有用。
kubectl create -f <url> --edit
从命令式命令迁移到命令式对象配置涉及几个手动步骤。
将活动对象导出到本地对象配置文件:
kubectl get <kind>/<name> -o yaml > <kind>_<name>.yaml
对于后续的对象管理,只能使用 replace 。
kubectl replace -f <kind>_<name>.yaml
不建议在控制器上更新选择器。
推荐的方法是定义单个不变的 PodTemplate 标签,该标签仅由控制器选择器使用,而没有其他语义。
标签示例:
selector:
matchLabels:
controller-selector: "apps/v1/deployment/nginx"
template:
metadata:
labels:
controller-selector: "apps/v1/deployment/nginx"
这个任务展示如何使用 kubectl patch 就地更新 API 对象。
这个任务中的练习演示了一个策略性合并 patch 和一个 JSON 合并 patch。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
下面是具有两个副本的 Deployment 的配置文件。每个副本是一个 Pod,有一个容器:
apiVersion: apps/v1
kind: Deployment
metadata:
name: patch-demo
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: patch-demo-ctr
image: nginx
tolerations:
- effect: NoSchedule
key: dedicated
value: test-team
创建 Deployment:
kubectl apply -f https://k8s.io/examples/application/deployment-patch.yaml
查看与 Deployment 相关的 Pod:
kubectl get pods
输出显示 Deployment 有两个 Pod。1/1 表示每个 Pod 有一个容器:
NAME READY STATUS RESTARTS AGE
patch-demo-28633765-670qr 1/1 Running 0 23s
patch-demo-28633765-j5qs3 1/1 Running 0 23s
把运行的 Pod 的名字记下来。稍后,你将看到这些 Pod 被终止并被新的 Pod 替换。
此时,每个 Pod 都有一个运行 nginx 镜像的容器。现在假设你希望每个 Pod 有两个容器:一个运行 nginx,另一个运行 redis。
创建一个名为 patch-file.yaml 的文件。内容如下:
spec:
template:
spec:
containers:
- name: patch-demo-ctr-2
image: redis
修补你的 Deployment:
kubectl patch deployment patch-demo --patch-file patch-file.yaml
查看修补后的 Deployment:
kubectl get deployment patch-demo --output yaml
输出显示 Deployment 中的 PodSpec 有两个容器:
containers:
- image: redis
imagePullPolicy: Always
name: patch-demo-ctr-2
...
- image: nginx
imagePullPolicy: Always
name: patch-demo-ctr
...
查看与 patch Deployment 相关的 Pod:
kubectl get pods
输出显示正在运行的 Pod 与以前运行的 Pod 有不同的名称。Deployment 终止了旧的 Pod,
并创建了两个符合更新后的 Deployment 规约的新 Pod。2/2 表示每个 Pod 有两个容器:
NAME READY STATUS RESTARTS AGE
patch-demo-1081991389-2wrn5 2/2 Running 0 1m
patch-demo-1081991389-jmg7b 2/2 Running 0 1m
仔细查看其中一个 patch-demo Pod:
kubectl get pod <your-pod-name> --output yaml
输出显示 Pod 有两个容器:一个运行 nginx,一个运行 redis:
containers:
- image: redis
...
- image: nginx
...
你在前面的练习中所做的 patch 称为 策略性合并 patch(Strategic Merge Patch)。
请注意,patch 没有替换 containers 列表。相反,它向列表中添加了一个新 Container。换句话说,
patch 中的列表与现有列表合并。当你在列表中使用策略性合并 patch 时,并不总是这样。
在某些情况下,列表是替换的,而不是合并的。
对于策略性合并 patch,列表可以根据其 patch 策略进行替换或合并。
patch 策略由 Kubernetes 源代码中字段标记中的 patchStrategy 键的值指定。
例如,PodSpec 结构体的 Containers 字段的 patchStrategy 为 merge:
type PodSpec struct {
...
Containers []Container `json:"containers" patchStrategy:"merge" patchMergeKey:"name" ...`
...
}
你还可以在 OpenApi 规范中看到 patch 策略:
"io.k8s.api.core.v1.PodSpec": {
...,
"containers": {
"description": "List of containers belonging to the pod. ...."
},
"x-kubernetes-patch-merge-key": "name",
"x-kubernetes-patch-strategy": "merge"
}
你可以在 Kubernetes API 文档 中看到 patch 策略。
创建一个名为 patch-file-tolerations.yaml 的文件。内容如下:
spec:
template:
spec:
tolerations:
- effect: NoSchedule
key: disktype
value: ssd
对 Deployment 执行 patch 操作:
kubectl patch deployment patch-demo --patch-file patch-file-tolerations.yaml
查看修补后的 Deployment:
kubectl get deployment patch-demo --output yaml
输出结果显示 Deployment 中的 PodSpec 只有一个容忍度设置:
tolerations:
- effect: NoSchedule
key: disktype
value: ssd
请注意,PodSpec 中的 tolerations 列表被替换,而不是合并。这是因为 PodSpec 的 tolerations
的字段标签中没有 patchStrategy 键。所以策略合并 patch 操作使用默认的 patch 策略,也就是 replace。
type PodSpec struct {
...
Tolerations []Toleration `json:"tolerations,omitempty" protobuf:"bytes,22,opt,name=tolerations"`
...
}
策略性合并 patch 不同于 JSON 合并 patch。 使用 JSON 合并 patch,如果你想更新列表,你必须指定整个新列表。新的列表完全取代现有的列表。
kubectl patch 命令有一个 type 参数,你可以将其设置为以下值之一:
| 参数值 | 合并类型 |
|---|---|
| json | JSON Patch, RFC 6902 |
| merge | JSON Merge Patch, RFC 7386 |
| strategic | 策略合并 patch |
有关 JSON patch 和 JSON 合并 patch 的比较,查看 JSON patch 和 JSON 合并 patch。
type 参数的默认值是 strategic。在前面的练习中,我们做了一个策略性的合并 patch。
下一步,在相同的 Deployment 上执行 JSON 合并 patch。创建一个名为 patch-file-2 的文件。内容如下:
spec:
template:
spec:
containers:
- name: patch-demo-ctr-3
image: gcr.io/google-samples/node-hello:1.0
在 patch 命令中,将 type 设置为 merge:
kubectl patch deployment patch-demo --type merge --patch-file patch-file-2.yaml
查看修补后的 Deployment:
kubectl get deployment patch-demo --output yaml
patch 中指定的 containers 列表只有一个 Container。
输出显示你所给出的 Container 列表替换了现有的 containers 列表。
spec:
containers:
- image: gcr.io/google-samples/node-hello:1.0
...
name: patch-demo-ctr-3
列出正运行的 Pod:
kubectl get pods
在输出中,你可以看到已经终止了现有的 Pod,并创建了新的 Pod。1/1 表示每个新 Pod 只运行一个容器。
NAME READY STATUS RESTARTS AGE
patch-demo-1307768864-69308 1/1 Running 0 1m
patch-demo-1307768864-c86dc 1/1 Running 0 1m
apiVersion: apps/v1
kind: Deployment
metadata:
name: retainkeys-demo
spec:
selector:
matchLabels:
app: nginx
strategy:
rollingUpdate:
maxSurge: 30%
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: retainkeys-demo-ctr
image: nginx
创建 Deployment:
kubectl apply -f https://k8s.io/examples/application/deployment-retainkeys.yaml
这时,Deployment 被创建,并使用 RollingUpdate 策略。
创建一个名为 patch-file-no-retainkeys.yaml 的文件,内容如下:
spec:
strategy:
type: Recreate
修补你的 Deployment:
kubectl patch deployment retainkeys-demo --type strategic --patch-file patch-file-no-retainkeys.yaml
在输出中,你可以看到,当 spec.strategy.rollingUpdate 已经拥有取值定义时,
将其 type 设置为 Recreate 是不可能的。
The Deployment "retainkeys-demo" is invalid: spec.strategy.rollingUpdate: Forbidden: may not be specified when strategy `type` is 'Recreate'
更新 type 取值的同时移除 spec.strategy.rollingUpdate
现有值的方法是为策略性合并操作设置 retainKeys 策略:
创建另一个名为 patch-file-retainkeys.yaml 的文件,内容如下:
spec:
strategy:
$retainKeys:
- type
type: Recreate
使用此 patch,我们表达了希望只保留 strategy 对象的 type 键。
这样,在 patch 操作期间 rollingUpdate 会被删除。
使用新的 patch 重新修补 Deployment:
kubectl patch deployment retainkeys-demo --type strategic --patch-file patch-file-retainkeys.yaml
检查 Deployment 的内容:
kubectl get deployment retainkeys-demo --output yaml
输出显示 Deployment 中的 strategy 对象不再包含 rollingUpdate 键:
spec:
strategy:
type: Recreate
template:
在前文练习中所执行的称作 带 retainKeys 策略的策略合并 patch(Strategic Merge
Patch with retainKeys Strategy)。
这种方法引入了一种新的 $retainKey 指令,具有如下策略:
$retainKeys 列表中给出;$retainKeys 中的所有字段必须 patch 操作所给字段的超集,或者与之完全一致。策略 retainKeys 并不能对所有对象都起作用。它仅对那些 Kubernetes 源码中
patchStrategy 字段标志值包含 retainKeys 的字段有用。
例如 DeploymentSpec 结构的 Strategy 字段就包含了 patchStrategy 为
retainKeys 的标志。
type DeploymentSpec struct {
...
// +patchStrategy=retainKeys
Strategy DeploymentStrategy `json:"strategy,omitempty" patchStrategy:"retainKeys" ...`
...
}
你也可以查看
OpenAPI 规范中的
retainKeys 策略:
"io.k8s.api.apps.v1.DeploymentSpec": {
...,
"strategy": {
"$ref": "#/definitions/io.k8s.api.apps.v1.DeploymentStrategy",
"description": "The deployment strategy to use to replace existing pods with new ones.",
"x-kubernetes-patch-strategy": "retainKeys"
},
....
}
而且你也可以在
Kubernetes API 文档中看到
retainKey 策略。
kubectl patch 命令使用 YAML 或 JSON。它可以接受以文件形式提供的补丁,也可以接受直接在命令行中给出的补丁。
创建一个文件名称是 patch-file.json 内容如下:
{
"spec": {
"template": {
"spec": {
"containers": [
{
"name": "patch-demo-ctr-2",
"image": "redis"
}
]
}
}
}
}
以下命令是等价的:
kubectl patch deployment patch-demo --patch-file patch-file.yaml
kubectl patch deployment patch-demo --patch 'spec:\n template:\n spec:\n containers:\n - name: patch-demo-ctr-2\n image: redis'
kubectl patch deployment patch-demo --patch-file patch-file.json
kubectl patch deployment patch-demo --patch '{"spec": {"template": {"spec": {"containers": [{"name": "patch-demo-ctr-2","image": "redis"}]}}}}'
kubectl patch 和 --subresource 更新一个对象的副本数 Kubernetes v1.24 [alpha]
使用 kubectl 命令(如 get、patch、edit 和 replace)时带上 --subresource=[subresource-name] 标志,
可以获取和更新资源的 status 和 scale 子资源(适用于 kubectl v1.24 或更高版本)。
这个标志可用于带有 status 或 scale 子资源的所有 API 资源 (内置资源和 CR 资源)。
Deployment 是支持这些子资源的其中一个例子。
下面是有两个副本的 Deployment 的清单。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # 告知 Deployment 运行 2 个与该模板匹配的 Pod
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
创建 Deployment:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
查看与 Deployment 关联的 Pod:
kubectl get pods -l app=nginx
在输出中,你可以看到此 Deployment 有两个 Pod。例如:
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fb96c846b-22567 1/1 Running 0 47s
nginx-deployment-7fb96c846b-mlgns 1/1 Running 0 47s
现在用 --subresource=[subresource-name] 标志修补此 Deployment:
kubectl patch deployment nginx-deployment --subresource='scale' --type='merge' -p '{"spec":{"replicas":3}}'
输出为:
scale.autoscaling/nginx-deployment patched
查看与你所修补的 Deployment 关联的 Pod:
kubectl get pods -l app=nginx
在输出中,你可以看到一个新的 Pod 被创建,因此现在你有 3 个正在运行的 Pod。
NAME READY STATUS RESTARTS AGE
nginx-deployment-7fb96c846b-22567 1/1 Running 0 107s
nginx-deployment-7fb96c846b-lxfr2 1/1 Running 0 14s
nginx-deployment-7fb96c846b-mlgns 1/1 Running 0 107s
查看所修补的 Deployment:
kubectl get deployment nginx-deployment -o yaml
...
spec:
replicas: 3
...
status:
...
availableReplicas: 3
readyReplicas: 3
replicas: 3
如果你运行 kubectl patch 并指定 --subresource 标志时,所针对的是不支持特定子资源的资源,
则 API 服务器会返回一个 404 Not Found 错误。
在本练习中,你使用 kubectl patch 更改了 Deployment 对象的当前配置。
你没有更改最初用于创建 Deployment 对象的配置文件。
用于更新 API 对象的其他命令包括
kubectl annotate、
kubectl edit、
kubectl replace、
kubectl scale 和
kubectl apply。
定制资源不支持策略性合并 patch。
本页向你展示如何使用 kubectl 命令行工具来创建、编辑、管理和删除。
Kubernetes Secrets
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
Secret 对象用来存储敏感数据,如 Pod 用于访问服务的凭据。例如,为访问数据库,你可能需要一个
Secret 来存储所需的用户名及密码。
你可以通过在命令中传递原始数据,或将凭据存储文件中,然后再在命令行中创建 Secret。以下命令
将创建一个存储用户名 admin 和密码 S!B\*d$zDsb= 的 Secret。
执行以下命令:
kubectl create secret generic db-user-pass \
--from-literal=username=admin \
--from-literal=password='S!B\*d$zDsb='
你必须使用单引号 '' 转义字符串中的特殊字符,如 $、\、*、=和! 。否则,你的 shell
将会解析这些字符。
Secret 的 stringData 字段与服务端应用不兼容。
将凭据保存到文件:
echo -n 'admin' > ./username.txt
echo -n 'S!B\*d$zDsb=' > ./password.txt
-n 标志用来确保生成文件的文末没有多余的换行符。这很重要,因为当 kubectl
读取文件并将内容编码为 base64 字符串时,额外的换行符也会被编码。
你不需要对文件中包含的字符串中的特殊字符进行转义。
在 kubectl 命令中传递文件路径:
kubectl create secret generic db-user-pass \
--from-file=./username.txt \
--from-file=./password.txt
默认键名为文件名。你也可以通过 --from-file=[key=]source 设置键名,例如:
kubectl create secret generic db-user-pass \
--from-file=username=./username.txt \
--from-file=password=./password.txt
无论使用哪种方法,输出都类似于:
secret/db-user-pass created
检查 Secret 是否已创建:
kubectl get secrets
输出类似于:
NAME TYPE DATA AGE
db-user-pass Opaque 2 51s
查看 Secret 的细节:
kubectl describe secret db-user-pass
输出类似于:
Name: db-user-pass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 12 bytes
username: 5 bytes
kubectl get 和 kubectl describe 命令默认不显示 Secret 的内容。
这是为了防止 Secret 被意外暴露或存储在终端日志中。
查看你所创建的 Secret 内容
kubectl get secret db-user-pass -o jsonpath='{.data}'
输出类似于:
{ "password": "UyFCXCpkJHpEc2I9", "username": "YWRtaW4=" }
解码 password 数据:
echo 'UyFCXCpkJHpEc2I9' | base64 --decode
输出类似于:
S!B\*d$zDsb=
这是一个出于文档编制目的的示例。实际上,该方法可能会导致包含编码数据的命令存储在 Shell 的历史记录中。任何可以访问你的计算机的人都可以找到该命令并对 Secret 进行解码。 更好的办法是将查看和解码命令一同使用。
kubectl get secret db-user-pass -o jsonpath='{.data.password}' | base64 --decode
你可以编辑一个现存的 Secret 对象,除非它是不可改变的。
要想编辑一个 Secret,请执行以下命令:
kubectl edit secrets <secret-name>
这将打开默认编辑器,并允许你更新 data 字段中的 base64 编码的 Secret 值,示例如下:
#请编辑下面的对象。以“#”开头的行将被忽略,
#空文件将中止编辑。如果在保存此文件时发生错误,
#则将重新打开该文件并显示相关的失败。
apiVersion: v1
data:
password: UyFCXCpkJHpEc2I9
username: YWRtaW4=
kind: Secret
metadata:
creationTimestamp: "2022-06-28T17:44:13Z"
name: db-user-pass
namespace: default
resourceVersion: "12708504"
uid: 91becd59-78fa-4c85-823f-6d44436242ac
type: Opaque
要想删除一个 Secret,请执行以下命令:
kubectl delete secret db-user-pass
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你可以先用 JSON 或 YAML 格式在一个清单文件中定义 Secret 对象,然后创建该对象。
Secret
资源包含 2 个键值对:data 和 stringData。
data 字段用来存储 base64 编码的任意数据。
提供 stringData 字段是为了方便,它允许 Secret 使用未编码的字符串。
data 和 stringData 的键必须由字母、数字、-、_ 或 . 组成。
以下示例使用 data 字段在 Secret 中存储两个字符串:
将这些字符串转换为 base64:
echo -n 'admin' | base64
echo -n '1f2d1e2e67df' | base64
Secret 数据的 JSON 和 YAML 序列化结果是以 base64 编码的。
换行符在这些字符串中无效,必须省略。
在 Darwin/macOS 上使用 base64 工具时,用户不应该使用 -b 选项分割长行。
相反地,Linux 用户应该在 base64 地命令中添加 -w 0 选项,
或者在 -w 选项不可用的情况下,输入 base64 | tr -d '\n'。
输出类似于:
YWRtaW4=
MWYyZDFlMmU2N2Rm
创建清单:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
注意,Secret 对象的名称必须是有效的 DNS 子域名。
使用 kubectl apply 创建 Secret:
kubectl apply -f ./secret.yaml
输出类似于:
secret/mysecret created
若要验证 Secret 被创建以及想要解码 Secret 数据, 请参阅使用 kubectl 管理 Secret
对于某些场景,你可能希望使用 stringData 字段。
这个字段可以将一个非 base64 编码的字符串直接放入 Secret 中,
当创建或更新该 Secret 时,此字段将被编码。
上述用例的实际场景可能是这样:当你部署应用时,使用 Secret 存储配置文件, 你希望在部署过程中,填入部分内容到该配置文件。
例如,如果你的应用程序使用以下配置文件:
apiUrl: "https://my.api.com/api/v1"
username: "<user>"
password: "<password>"
你可以使用以下定义将其存储在 Secret 中:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
config.yaml: |
apiUrl: "https://my.api.com/api/v1"
username: <user>
password: <password>
Secret 的 stringData 字段不能很好地与服务器端应用配合使用。
当你检索 Secret 数据时,此命令将返回编码的值,并不是你在 stringData 中提供的纯文本值。
例如,如果你运行以下命令:
kubectl get secret mysecret -o yaml
输出类似于:
apiVersion: v1
data:
config.yaml: YXBpVXJsOiAiaHR0cHM6Ly9teS5hcGkuY29tL2FwaS92MSIKdXNlcm5hbWU6IHt7dXNlcm5hbWV9fQpwYXNzd29yZDoge3twYXNzd29yZH19
kind: Secret
metadata:
creationTimestamp: 2018-11-15T20:40:59Z
name: mysecret
namespace: default
resourceVersion: "7225"
uid: c280ad2e-e916-11e8-98f2-025000000001
type:
data 和 stringData如果你在 data 和 stringData 中设置了同一个字段,则使用来自 stringData 中的值。
例如,如果你定义以下 Secret:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
stringData:
username: administrator
Secret 的 stringData 字段不能很好地与服务器端应用配合使用。
所创建的 Secret 对象如下:
apiVersion: v1
data:
username: YWRtaW5pc3RyYXRvcg==
kind: Secret
metadata:
creationTimestamp: 2018-11-15T20:46:46Z
name: mysecret
namespace: default
resourceVersion: "7579"
uid: 91460ecb-e917-11e8-98f2-025000000001
type: Opaque
YWRtaW5pc3RyYXRvcg== 解码成 administrator。
要编辑使用清单创建的 Secret 中的数据,请修改清单中的 data 或 stringData 字段并将此清单文件应用到集群。
你可以编辑现有的 Secret 对象,除非它是不可变的。
例如,如果你想将上一个示例中的密码更改为 birdsarentreal,请执行以下操作:
编码新密码字符串:
echo -n 'birdsarentreal' | base64
输出类似于:
YmlyZHNhcmVudHJlYWw=
使用你的新密码字符串更新 data 字段:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: YmlyZHNhcmVudHJlYWw=
将清单应用到你的集群:
kubectl apply -f ./secret.yaml
输出类似于:
secret/mysecret configured
Kubernetes 更新现有的 Secret 对象。具体而言,kubectl 工具发现存在一个同名的现有 Secret 对象。
kubectl 获取现有对象,计划对其进行更改,并将更改后的 Secret 对象提交到你的集群控制平面。
如果你指定了 kubectl apply --server-side,则 kubectl
使用服务器端应用(Server-Side Apply)。
删除你创建的 Secret:
kubectl delete secret mysecret
kubectl 管理 Secretkubectl 支持使用 Kustomize 对象管理工具来管理
Secret 和 ConfigMap。你可以使用 Kustomize 创建资源生成器(Resource Generator),
该生成器会生成一个 Secret,让你能够通过 kubectl 应用到 API 服务器。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你可以在 kustomization.yaml 文件中定义 secreteGenerator 字段,
并在定义中引用其它本地文件、.env 文件或文字值生成 Secret。
例如:下面的指令为用户名 admin 和密码 1f2d1e2e67df 创建 Kustomization 文件。
Secret 的 stringData 字段与服务端应用不兼容。
secretGenerator:
- name: database-creds
literals:
- username=admin
- password=1f2d1e2e67df
将凭据存储在文件中。文件名是 Secret 的 key 值:
echo -n 'admin' > ./username.txt
echo -n '1f2d1e2e67df' > ./password.txt
-n 标志确保文件结尾处没有换行符。
创建 kustomization.yaml 文件:
secretGenerator:
- name: database-creds
files:
- username.txt
- password.txt
你也可以使用 .env 文件在 kustomization.yaml 中定义 secretGenerator。
例如下面的 kustomization.yaml 文件从 .env.secret 文件获取数据:
secretGenerator:
- name: db-user-pass
envs:
- .env.secret
在所有情况下,你都不需要对取值作 base64 编码。
YAML 文件的名称必须是 kustomization.yaml 或 kustomization.yml。
若要创建 Secret,应用包含 kustomization 文件的目录。
kubectl apply -k <目录路径>
输出类似于:
secret/database-creds-5hdh7hhgfk created
生成 Secret 时,Secret 的名称最终是由 name 字段和数据的哈希值拼接而成。
这将保证每次修改数据时生成一个新的 Secret。
要验证 Secret 是否已创建并解码 Secret 数据,
kubectl get -k <directory-path> -o jsonpath='{.data}'
输出类似于:
{ "password": "UyFCXCpkJHpEc2I9", "username": "YWRtaW4=" }
echo 'UyFCXCpkJHpEc2I9' | base64 --decode
输出类似于:
S!B\*d$zDsb=
更多信息参阅 使用 kubectl 管理 Secret和 使用 Kustomize 对 Kubernetes 对象进行声明式管理
在 kustomization.yaml 文件中,修改诸如 password 等数据。
应用包含 kustomization 文件的目录:
kubectl apply -k <目录路径>
输出类似于:
secret/db-user-pass-6f24b56cc8 created
编辑过的 Secret 被创建为一个新的 Secret 对象,而不是更新现有的 Secret 对象。
你可能需要在 Pod 中更新对该 Secret 的引用。
要删除 Secret,请使用 kubectl:
kubectl delete secret db-user-pass
本页将展示如何为 Pod 中容器设置启动时要执行的命令及其参数。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
创建 Pod 时,可以为其下的容器设置启动时要执行的命令及其参数。如果要设置命令,就填写在配置文件的
command 字段下,如果要设置命令的参数,就填写在配置文件的 args 字段下。
一旦 Pod 创建完成,该命令及其参数就无法再进行更改了。
如果在配置文件中设置了容器启动时要执行的命令及其参数,那么容器镜像中自带的命令与参数将会被覆盖而不再执行。 如果配置文件中只是设置了参数,却没有设置其对应的命令,那么容器镜像中自带的命令会使用该新参数作为其执行时的参数。
在有些容器运行时中,command 字段对应 entrypoint。
本示例中,将创建一个只包含单个容器的 Pod。在此 Pod 配置文件中设置了一个命令与两个参数:
apiVersion: v1
kind: Pod
metadata:
name: command-demo
labels:
purpose: demonstrate-command
spec:
containers:
- name: command-demo-container
image: debian
command: ["printenv"]
args: ["HOSTNAME", "KUBERNETES_PORT"]
restartPolicy: OnFailure
基于 YAML 文件创建一个 Pod:
kubectl apply -f https://k8s.io/examples/pods/commands.yaml
获取正在运行的 Pod:
kubectl get pods
查询结果显示在 command-demo 这个 Pod 下运行的容器已经启动完成。
如果要获取容器启动时执行命令的输出结果,可以通过 Pod 的日志进行查看:
kubectl logs command-demo
日志中显示了 HOSTNAME 与 KUBERNETES_PORT 这两个环境变量的值:
command-demo
tcp://10.3.240.1:443
在上面的示例中,我们直接将一串字符作为命令的参数。除此之外,我们还可以将环境变量作为命令的参数。
env:
- name: MESSAGE
value: "hello world"
command: ["/bin/echo"]
args: ["$(MESSAGE)"]
这意味着你可以将那些用来设置环境变量的方法应用于设置命令的参数,其中包括了 ConfigMap 与 Secret。
环境变量需要加上括号,类似于 "$(VAR)"。这是在 command 或 args 字段使用变量的格式要求。
有时候,你需要在 Shell 脚本中运行命令。 例如,你要执行的命令可能由多个命令组合而成,或者它就是一个 Shell 脚本。 这时,就可以通过如下方式在 Shell 中执行命令:
command: ["/bin/sh"]
args: ["-c", "while true; do echo hello; sleep 10;done"]
本页展示了如何为 Kubernetes Pod 中的容器定义相互依赖的环境变量。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
当创建一个 Pod 时,你可以为运行在 Pod 中的容器设置相互依赖的环境变量。
若要设置相互依赖的环境变量,你可以在配置清单文件的 env 的 value 中使用 $(VAR_NAME)。
在本练习中,你会创建一个单容器的 Pod。 此 Pod 的配置文件定义了一个已定义常用用法的相互依赖的环境变量。 下面是此 Pod 的配置清单:
apiVersion: v1
kind: Pod
metadata:
name: dependent-envars-demo
spec:
containers:
- name: dependent-envars-demo
args:
- while true; do echo -en '\n'; printf UNCHANGED_REFERENCE=$UNCHANGED_REFERENCE'\n'; printf SERVICE_ADDRESS=$SERVICE_ADDRESS'\n';printf ESCAPED_REFERENCE=$ESCAPED_REFERENCE'\n'; sleep 30; done;
command:
- sh
- -c
image: busybox:1.28
env:
- name: SERVICE_PORT
value: "80"
- name: SERVICE_IP
value: "172.17.0.1"
- name: UNCHANGED_REFERENCE
value: "$(PROTOCOL)://$(SERVICE_IP):$(SERVICE_PORT)"
- name: PROTOCOL
value: "https"
- name: SERVICE_ADDRESS
value: "$(PROTOCOL)://$(SERVICE_IP):$(SERVICE_PORT)"
- name: ESCAPED_REFERENCE
value: "$$(PROTOCOL)://$(SERVICE_IP):$(SERVICE_PORT)"
依据清单创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/dependent-envars.yaml
pod/dependent-envars-demo created
列出运行的 Pod:
kubectl get pods dependent-envars-demo
NAME READY STATUS RESTARTS AGE
dependent-envars-demo 1/1 Running 0 9s
检查 Pod 中运行容器的日志:
kubectl logs pod/dependent-envars-demo
UNCHANGED_REFERENCE=$(PROTOCOL)://172.17.0.1:80
SERVICE_ADDRESS=https://172.17.0.1:80
ESCAPED_REFERENCE=$(PROTOCOL)://172.17.0.1:80
如上所示,你已经定义了 SERVICE_ADDRESS 的正确依赖引用,
UNCHANGED_REFERENCE 的错误依赖引用,
并跳过了 ESCAPED_REFERENCE 的依赖引用。
如果环境变量被引用时已事先定义,则引用可以正确解析,
比如 SERVICE_ADDRESS 的例子。
请注意,env 列表中的顺序很重要。如果某环境变量定义出现在列表的尾部,
则在解析列表前部环境变量时不会视其为“已被定义”。
这就是为什么 UNCHANGED_REFERENCE 在上面的示例中解析 $(PROTOCOL) 失败的原因。
当环境变量未定义或仅包含部分变量时,未定义的变量会被当做普通字符串对待,
比如 UNCHANGED_REFERENCE 的例子。
注意,解析不正确的环境变量通常不会阻止容器启动。
$(VAR_NAME) 这样的语法可以用两个 $ 转义,即:$$(VAR_NAME)。
无论引用的变量是否定义,转义的引用永远不会展开。
这一点可以从上面 ESCAPED_REFERENCE 的例子得到印证。
本页将展示如何为 Kubernetes Pod 下的容器设置环境变量。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
创建 Pod 时,可以为其下的容器设置环境变量。通过配置文件的 env 或者 envFrom 字段来设置环境变量。
env 和 envFrom 字段具有不同的效果。
env
:可以为容器设置环境变量,直接为你所给的每个变量指定一个值。
envFrom
:你可以通过引用 ConfigMap 或 Secret 来设置容器的环境变量。
使用 envFrom 时,引用的 ConfigMap 或 Secret 中的所有键值对都被设置为容器的环境变量。
你也可以指定一个通用的前缀字符串。
你可以阅读有关 ConfigMap 和 Secret 的更多信息。
本页介绍如何使用 env。
本示例中,将创建一个只包含单个容器的 Pod。此 Pod 的配置文件中设置环境变量的名称为 DEMO_GREETING,
其值为 "Hello from the environment"。下面是此 Pod 的配置清单:
apiVersion: v1
kind: Pod
metadata:
name: envar-demo
labels:
purpose: demonstrate-envars
spec:
containers:
- name: envar-demo-container
image: gcr.io/google-samples/node-hello:1.0
env:
- name: DEMO_GREETING
value: "Hello from the environment"
- name: DEMO_FAREWELL
value: "Such a sweet sorrow"
基于配置清单创建一个 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/envars.yaml
获取正在运行的 Pod 信息:
kubectl get pods -l purpose=demonstrate-envars
查询结果应为:
NAME READY STATUS RESTARTS AGE
envar-demo 1/1 Running 0 9s
列出 Pod 容器的环境变量:
kubectl exec envar-demo -- printenv
打印结果应为:
NODE_VERSION=4.4.2
EXAMPLE_SERVICE_PORT_8080_TCP_ADDR=10.3.245.237
HOSTNAME=envar-demo
...
DEMO_GREETING=Hello from the environment
DEMO_FAREWELL=Such a sweet sorrow
通过 env 或 envFrom 字段设置的环境变量将覆盖容器镜像中指定的所有环境变量。
环境变量可以互相引用,但是顺序很重要。 使用在相同上下文中定义的其他变量的变量必须在列表的后面。 同样,请避免使用循环引用。
你在 Pod 的配置中定义的、位于 .spec.containers[*].env[*] 下的环境变量
可以在配置的其他地方使用,例如可用在为 Pod 的容器设置的命令和参数中。
在下面的示例配置中,环境变量 GREETING、HONORIFIC 和 NAME 分别设置为 Warm greetings to、
The Most Honorable 和 Kubernetes。
环境变量 MESSAGE 将所有这些环境变量的集合组合起来,
然后再传递给容器 env-print-demo 的 CLI 参数中使用。
apiVersion: v1
kind: Pod
metadata:
name: print-greeting
spec:
containers:
- name: env-print-demo
image: bash
env:
- name: GREETING
value: "Warm greetings to"
- name: HONORIFIC
value: "The Most Honorable"
- name: NAME
value: "Kubernetes"
command: ["echo"]
args: ["$(GREETING) $(HONORIFIC) $(NAME)"]
创建后,命令 echo Warm greetings to The Most Honorable Kubernetes 将在容器中运行。
此页面展示 Pod 如何使用 downward API 通过环境变量把自身的信息呈现给 Pod 中运行的容器。 你可以使用环境变量来呈现 Pod 的字段、容器字段或两者。
在 Kubernetes 中有两种方式可以将 Pod 和容器字段呈现给运行中的容器:
这两种呈现 Pod 和容器字段的方式统称为 downward API。
Service 是 Kubernetes 管理的容器化应用之间的主要通信模式,因此在运行时能发现这些 Service 是很有帮助的。
在这里 阅读更多关于访问 Service 的信息。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在这部分练习中,你将创建一个包含一个容器的 Pod。并将 Pod 级别的字段作为环境变量投射到正在运行的容器中。
apiVersion: v1
kind: Pod
metadata:
name: dapi-envars-fieldref
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox
command: [ "sh", "-c"]
args:
- while true; do
echo -en '\n';
printenv MY_NODE_NAME MY_POD_NAME MY_POD_NAMESPACE;
printenv MY_POD_IP MY_POD_SERVICE_ACCOUNT;
sleep 10;
done;
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
restartPolicy: Never
这个清单中,你可以看到五个环境变量。env 字段定义了一组环境变量。
数组中第一个元素指定 MY_NODE_NAME 这个环境变量从 Pod 的 spec.nodeName 字段获取变量值。
同样,其它环境变量也是从 Pod 的字段获取它们的变量值。
本示例中的字段是 Pod 字段,不是 Pod 中 Container 的字段。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-envars-pod.yaml
验证 Pod 中的容器运行正常:
# 如果新创建的 Pod 还是处于不健康状态,请重新运行此命令几次。
kubectl get pods
查看容器日志:
kubectl logs dapi-envars-fieldref
输出信息显示了所选择的环境变量的值:
minikube
dapi-envars-fieldref
default
172.17.0.4
default
要了解为什么这些值出现在日志中,请查看配置文件中的 command 和 args 字段。
当容器启动时,它将五个环境变量的值写入标准输出。每十秒重复执行一次。
接下来,进入 Pod 中运行的容器,打开一个 Shell:
kubectl exec -it dapi-envars-fieldref -- sh
在 Shell 中,查看环境变量:
# 在容器内的 `shell` 中运行
printenv
输出信息显示环境变量已经设置为 Pod 字段的值。
MY_POD_SERVICE_ACCOUNT=default
...
MY_POD_NAMESPACE=default
MY_POD_IP=172.17.0.4
...
MY_NODE_NAME=minikube
...
MY_POD_NAME=dapi-envars-fieldref
前面的练习中,你将 Pod 级别的字段作为环境变量的值。 接下来这个练习中,你将传递属于 Pod 定义的字段,但这些字段取自特定容器而不是整个 Pod。
这里是只包含一个容器的 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: dapi-envars-resourcefieldref
spec:
containers:
- name: test-container
image: registry.k8s.io/busybox:1.24
command: [ "sh", "-c"]
args:
- while true; do
echo -en '\n';
printenv MY_CPU_REQUEST MY_CPU_LIMIT;
printenv MY_MEM_REQUEST MY_MEM_LIMIT;
sleep 10;
done;
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
env:
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.cpu
- name: MY_CPU_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.cpu
- name: MY_MEM_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.memory
- name: MY_MEM_LIMIT
valueFrom:
resourceFieldRef:
containerName: test-container
resource: limits.memory
restartPolicy: Never
这个清单中,你可以看到四个环境变量。env 字段定义了一组环境变量。
数组中第一个元素指定 MY_CPU_REQUEST 这个环境变量从容器的 requests.cpu
字段获取变量值。同样,其它的环境变量也是从特定于这个容器的字段中获取它们的变量值。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-envars-container.yaml
验证 Pod 中的容器运行正常:
# 如果新创建的 Pod 还是处于不健康状态,请重新运行此命令几次。
kubectl get pods
查看容器日志:
kubectl logs dapi-envars-resourcefieldref
输出信息显示了所选择的环境变量的值:
1
1
33554432
67108864
在旧版 API 参考中阅读有关 Pod、容器和环境变量的信息:
此页面描述 Pod 如何使用
downwardAPI 卷
把自己的信息呈现给 Pod 中运行的容器。
downwardAPI 卷可以呈现 Pod 和容器的字段。
在 Kubernetes 中,有两种方式可以将 Pod 和容器字段呈现给运行中的容器:
这两种呈现 Pod 和容器字段的方式都称为 downward API。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
在这部分的练习中,你将创建一个包含一个容器的 Pod,并将 Pod 级别的字段作为文件投射到正在运行的容器中。 Pod 的清单如下:
apiVersion: v1
kind: Pod
metadata:
name: kubernetes-downwardapi-volume-example
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
annotations:
build: two
builder: john-doe
spec:
containers:
- name: client-container
image: registry.k8s.io/busybox
command: ["sh", "-c"]
args:
- while true; do
if [[ -e /etc/podinfo/labels ]]; then
echo -en '\n\n'; cat /etc/podinfo/labels; fi;
if [[ -e /etc/podinfo/annotations ]]; then
echo -en '\n\n'; cat /etc/podinfo/annotations; fi;
sleep 5;
done;
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
在 Pod 清单中,你可以看到 Pod 有一个 downwardAPI 类型的卷,并且挂载到容器中的
/etc/podinfo 目录。
查看 downwardAPI 下面的 items 数组。
数组的每个元素定义一个 downwardAPI 卷。
第一个元素指示 Pod 的 metadata.labels 字段的值保存在名为 labels 的文件中。
第二个元素指示 Pod 的 annotations 字段的值保存在名为 annotations 的文件中。
本示例中的字段是 Pod 字段,不是 Pod 中容器的字段。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-volume.yaml
验证 Pod 中的容器运行正常:
kubectl get pods
查看容器的日志:
kubectl logs kubernetes-downwardapi-volume-example
输出显示 labels 文件和 annotations 文件的内容:
cluster="test-cluster1"
rack="rack-22"
zone="us-est-coast"
build="two"
builder="john-doe"
进入 Pod 中运行的容器,打开一个 Shell:
kubectl exec -it kubernetes-downwardapi-volume-example -- sh
在该 Shell中,查看 labels 文件:
/# cat /etc/podinfo/labels
输出显示 Pod 的所有标签都已写入 labels 文件:
cluster="test-cluster1"
rack="rack-22"
zone="us-est-coast"
同样,查看 annotations 文件:
/# cat /etc/podinfo/annotations
查看 /etc/podinfo 目录下的文件:
/# ls -laR /etc/podinfo
在输出中可以看到,labels 和 annotations 文件都在一个临时子目录中。
在这个例子中,这个临时子目录为 ..2982_06_02_21_47_53.299460680。
在 /etc/podinfo 目录中,..data 是指向该临时子目录的符号链接。
另外在 /etc/podinfo 目录中,labels 和 annotations 也是符号链接。
drwxr-xr-x ... Feb 6 21:47 ..2982_06_02_21_47_53.299460680
lrwxrwxrwx ... Feb 6 21:47 ..data -> ..2982_06_02_21_47_53.299460680
lrwxrwxrwx ... Feb 6 21:47 annotations -> ..data/annotations
lrwxrwxrwx ... Feb 6 21:47 labels -> ..data/labels
/etc/..2982_06_02_21_47_53.299460680:
total 8
-rw-r--r-- ... Feb 6 21:47 annotations
-rw-r--r-- ... Feb 6 21:47 labels
用符号链接可实现元数据的动态原子性刷新;更新将写入一个新的临时目录,
然后通过使用 rename(2)
完成 ..data 符号链接的原子性更新。
如果容器以 subPath 卷挂载方式来使用 Downward API,则该容器无法收到更新事件。
退出 Shell:
/# exit
前面的练习中,你使用 downward API 使 Pod 级别的字段可以被 Pod 内正在运行的容器访问。 接下来这个练习,你将只传递由 Pod 定义的部分的字段到 Pod 内正在运行的容器中, 但这些字段取自特定容器而不是整个 Pod。 下面是一个同样只有一个容器的 Pod 的清单:
apiVersion: v1
kind: Pod
metadata:
name: kubernetes-downwardapi-volume-example-2
spec:
containers:
- name: client-container
image: registry.k8s.io/busybox:1.24
command: ["sh", "-c"]
args:
- while true; do
echo -en '\n';
if [[ -e /etc/podinfo/cpu_limit ]]; then
echo -en '\n'; cat /etc/podinfo/cpu_limit; fi;
if [[ -e /etc/podinfo/cpu_request ]]; then
echo -en '\n'; cat /etc/podinfo/cpu_request; fi;
if [[ -e /etc/podinfo/mem_limit ]]; then
echo -en '\n'; cat /etc/podinfo/mem_limit; fi;
if [[ -e /etc/podinfo/mem_request ]]; then
echo -en '\n'; cat /etc/podinfo/mem_request; fi;
sleep 5;
done;
resources:
requests:
memory: "32Mi"
cpu: "125m"
limits:
memory: "64Mi"
cpu: "250m"
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI:
items:
- path: "cpu_limit"
resourceFieldRef:
containerName: client-container
resource: limits.cpu
divisor: 1m
- path: "cpu_request"
resourceFieldRef:
containerName: client-container
resource: requests.cpu
divisor: 1m
- path: "mem_limit"
resourceFieldRef:
containerName: client-container
resource: limits.memory
divisor: 1Mi
- path: "mem_request"
resourceFieldRef:
containerName: client-container
resource: requests.memory
divisor: 1Mi
在这个清单中,你可以看到 Pod 有一个
downwardAPI 卷,
并且这个卷会挂载到 Pod 内的单个容器的 /etc/podinfo 目录。
查看 downwardAPI 下面的 items 数组。
数组的每个元素定义一个 downwardAPI 卷。
第一个元素指定在名为 client-container 的容器中,
以 1m 所指定格式的 limits.cpu 字段的值应推送到名为 cpu_limit 的文件中。
divisor 字段是可选的,默认值为 1。1 的除数表示 CPU 资源的核数或内存资源的字节数。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/dapi-volume-resources.yaml
打开一个 Shell,进入 Pod 中运行的容器:
kubectl exec -it kubernetes-downwardapi-volume-example-2 -- sh
在 Shell 中,查看 cpu_limit 文件:
# 在容器内的 Shell 中运行
cat /etc/podinfo/cpu_limit
你可以使用同样的命令查看 cpu_request、mem_limit 和 mem_request 文件。
你可以将键名投射到指定路径并且指定每个文件的访问权限。 更多信息,请参阅 Secret。
阅读旧版的 API 参考中关于卷的内容:
Volume
API 定义,该 API 在 Pod 中定义通用卷以供容器访问。DownwardAPIVolumeSource
API 定义,该 API 定义包含 Downward API 信息的卷。DownwardAPIVolumeFile
API 定义,该 API 包含对对象或资源字段的引用,用于在 Downward API 卷中填充文件。ResourceFieldSelector
API 定义,该 API 指定容器资源及其输出格式。本文展示如何安全地将敏感数据(如密码和加密密钥)注入到 Pod 中。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
假设用户想要有两条 Secret 数据:用户名 my-app 和密码 39528$vdg7Jb。
首先使用 Base64 编码将用户名和密码转化为 base-64 形式。
下面是一个使用常用的 base64 程序的示例:
echo -n 'my-app' | base64
echo -n '39528$vdg7Jb' | base64
结果显示 base-64 形式的用户名为 bXktYXBw,
base-64 形式的密码为 Mzk1MjgkdmRnN0pi。
使用你的操作系统所能信任的本地工具以降低使用外部工具的风险。
这里是一个配置文件,可以用来创建存有用户名和密码的 Secret:
apiVersion: v1
kind: Secret
metadata:
name: test-secret
data:
username: bXktYXBw
password: Mzk1MjgkdmRnN0pi
创建 Secret:
kubectl apply -f https://k8s.io/examples/pods/inject/secret.yaml
查看 Secret 相关信息:
kubectl get secret test-secret
输出:
NAME TYPE DATA AGE
test-secret Opaque 2 1m
查看 Secret 相关的更多详细信息:
kubectl describe secret test-secret
输出:
Name: test-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 13 bytes
username: 7 bytes
如果你希望略过 Base64 编码的步骤,你也可以使用 kubectl create secret
命令直接创建 Secret。例如:
kubectl create secret generic test-secret --from-literal='username=my-app' --from-literal='password=39528$vdg7Jb'
这是一种更为方便的方法。 前面展示的详细分解步骤有助于了解究竟发生了什么事情。
这里是一个可以用来创建 Pod 的配置文件:
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
spec:
containers:
- name: test-container
image: nginx
volumeMounts:
# name 必须与下面的卷名匹配
- name: secret-volume
mountPath: /etc/secret-volume
readOnly: true
# Secret 数据通过一个卷暴露给该 Pod 中的容器
volumes:
- name: secret-volume
secret:
secretName: test-secret
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/inject/secret-pod.yaml
确认 Pod 正在运行:
kubectl get pod secret-test-pod
输出:
NAME READY STATUS RESTARTS AGE
secret-test-pod 1/1 Running 0 42m
获取一个 Shell 进入 Pod 中运行的容器:
kubectl exec -i -t secret-test-pod -- /bin/bash
Secret 数据通过挂载在 /etc/secret-volume 目录下的卷暴露在容器中。
在 Shell 中,列举 /etc/secret-volume 目录下的文件:
# 在容器中 Shell 运行下面命令
ls /etc/secret-volume
输出包含两个文件,每个对应一个 Secret 数据条目:
password username
在 Shell 中,显示 username 和 password 文件的内容:
# 在容器中 Shell 运行下面命令
echo "$( cat /etc/secret-volume/username )"
echo "$( cat /etc/secret-volume/password )"
输出为用户名和密码:
my-app
39528$vdg7Jb
修改你的镜像或命令行,使程序在 mountPath 目录下查找文件。
Secret data 映射中的每个键都成为该目录中的文件名。
你还可以控制卷内 Secret 键的映射路径。
使用 .spec.volumes[].secret.items 字段来改变每个键的目标路径。
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
当你部署此 Pod 时,会发生以下情况:
mysecret 的键 username 可以在路径 /etc/foo/my-group/my-username
下供容器使用,而不是路径 /etc/foo/username。password 没有映射到任何路径。如果你使用 .spec.volumes[].secret.items 明确地列出键,请考虑以下事项:
items 字段中指定的键才会被映射。items 字段中。你可以为单个 Secret 键设置 POSIX 文件访问权限位。
如果不指定任何权限,默认情况下使用 0644。
你也可以为整个 Secret 卷设置默认的 POSIX 文件模式,需要时你可以重写单个键的权限。
例如,可以像这样指定默认模式:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"
volumes:
- name: foo
secret:
secretName: mysecret
defaultMode: 0400
Secret 被挂载在 /etc/foo 目录下;所有由 Secret 卷挂载创建的文件的访问许可都是 0400。
如果使用 JSON 定义 Pod 或 Pod 模板,请注意 JSON 规范不支持数字的八进制形式,
因为 JSON 将 0400 视为十进制的值 400。
在 JSON 中,要改为使用十进制的 defaultMode。
如果你正在编写 YAML,则可以用八进制编写 defaultMode。
在你的容器中,你可以以环境变量的方式使用 Secret 中的数据。
如果容器已经使用了在环境变量中的 Secret,除非容器重新启动,否则容器将无法感知到 Secret 的更新。 有第三方解决方案可以在 Secret 改变时触发容器重启。
定义环境变量为 Secret 中的键值偶对:
kubectl create secret generic backend-user --from-literal=backend-username='backend-admin'
在 Pod 规约中,将 Secret 中定义的值 backend-username 赋给 SECRET_USERNAME 环境变量。
apiVersion: v1
kind: Pod
metadata:
name: env-single-secret
spec:
containers:
- name: envars-test-container
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: backend-user
key: backend-username
创建 Pod:
kubectl create -f https://k8s.io/examples/pods/inject/pod-single-secret-env-variable.yaml
在 Shell 中,显示容器环境变量 SECRET_USERNAME 的内容:
kubectl exec -i -t env-single-secret -- /bin/sh -c 'echo $SECRET_USERNAME'
输出类似于:
backend-admin
和前面的例子一样,先创建 Secret:
kubectl create secret generic backend-user --from-literal=backend-username='backend-admin'
kubectl create secret generic db-user --from-literal=db-username='db-admin'
在 Pod 规约中定义环境变量:
apiVersion: v1
kind: Pod
metadata:
name: envvars-multiple-secrets
spec:
containers:
- name: envars-test-container
image: nginx
env:
- name: BACKEND_USERNAME
valueFrom:
secretKeyRef:
name: backend-user
key: backend-username
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: db-user
key: db-username
创建 Pod:
kubectl create -f https://k8s.io/examples/pods/inject/pod-multiple-secret-env-variable.yaml
在你的 Shell 中,显示容器环境变量的内容:
kubectl exec -i -t envvars-multiple-secrets -- /bin/sh -c 'env | grep _USERNAME'
输出类似于:
DB_USERNAME=db-admin
BACKEND_USERNAME=backend-admin
此功能在 Kubernetes 1.6 版本之后可用。
创建包含多个键值偶对的 Secret:
kubectl create secret generic test-secret --from-literal=username='my-app' --from-literal=password='39528$vdg7Jb'
使用 envFrom 来将 Secret 中的所有数据定义为环境变量。
Secret 中的键名成为容器中的环境变量名:
apiVersion: v1
kind: Pod
metadata:
name: envfrom-secret
spec:
containers:
- name: envars-test-container
image: nginx
envFrom:
- secretRef:
name: test-secret
创建 Pod:
kubectl create -f https://k8s.io/examples/pods/inject/pod-secret-envFrom.yaml
在 Shell 中,显示环境变量 username 和 password 的内容:
kubectl exec -i -t envfrom-secret -- /bin/sh -c 'echo "username: $username\npassword: $password\n"'
输出类似于:
username: my-app
password: 39528$vdg7Jb
此示例展示的是一个使用了包含生产环境凭据的 Secret 的 Pod 和一个使用了包含测试环境凭据的 Secret 的 Pod。
创建用于生产环境凭据的 Secret:
kubectl create secret generic prod-db-secret --from-literal=username=produser --from-literal=password=Y4nys7f11
输出类似于:
secret "prod-db-secret" created
为测试环境凭据创建 Secret。
kubectl create secret generic test-db-secret --from-literal=username=testuser --from-literal=password=iluvtests
输出类似于:
secret "test-db-secret" created
$、\、*、= 和 ! 这类特殊字符会被你的 Shell
解释,需要进行转义。
在大多数 Shell 中,最简单的密码转义方法是使用单引号(')将密码包起来。
例如,如果你的实际密码是 S!B\*d$zDsb=,则应执行以下命令:
kubectl create secret generic dev-db-secret --from-literal=username=devuser --from-literal=password='S!B\*d$zDsb='
你无需转义来自文件(--from-file)的密码中的特殊字符。
创建 Pod 清单:
cat <<EOF > pod.yaml
apiVersion: v1
kind: List
items:
- kind: Pod
apiVersion: v1
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: prod-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
- kind: Pod
apiVersion: v1
metadata:
name: test-db-client-pod
labels:
name: test-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: test-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
EOF
这两个 Pod 的规约只在一个字段上有所不同;这样便于从一个通用的 Pod 模板创建具有不同权能的 Pod。
通过运行以下命令将所有这些对象应用到 API 服务器:
kubectl create -f pod.yaml
两个容器的文件系统中都将存在以下文件,其中包含每个容器环境的值:
/etc/secret-volume/username
/etc/secret-volume/password
你可以通过使用两个服务账号进一步简化基础 Pod 规约:
prod-db-secret 的 prod-usertest-db-secret 的 test-userPod 规约精简为:
apiVersion: v1
kind: Pod
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
serviceAccount: prod-db-client
containers:
- name: db-client-container
image: myClientImage
本文介绍如何通过 Kubernetes Deployment 对象去运行一个应用。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.9. 要获知版本信息,请输入kubectl version.
你可以通过创建一个 Kubernetes Deployment 对象来运行一个应用, 且你可以在一个 YAML 文件中描述 Deployment。例如,下面这个 YAML 文件描述了一个运行 nginx:1.14.2 Docker 镜像的 Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # 告知 Deployment 运行 2 个与该模板匹配的 Pod
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
通过 YAML 文件创建一个 Deployment:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
显示该 Deployment 的相关信息:
kubectl describe deployment nginx-deployment
输出类似于这样:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 30 Aug 2016 18:11:37 -0700
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.14.2
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1771418926 (2/2 replicas created)
No events.
列出该 Deployment 创建的 Pod:
kubectl get pods -l app=nginx
输出类似于这样:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1771418926-7o5ns 1/1 Running 0 16h
nginx-deployment-1771418926-r18az 1/1 Running 0 16h
展示某一个 Pod 信息:
kubectl describe pod <pod-name>
这里的 <pod-name> 是某一 Pod 的名称。
你可以通过应用一个新的 YAML 文件来更新 Deployment。下面的 YAML 文件指定该 Deployment 镜像更新为 nginx 1.16.1。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1 # 将 nginx 版本从 1.14.2 更新为 1.16.1
ports:
- containerPort: 80
应用新的 YAML:
kubectl apply -f https://k8s.io/examples/application/deployment-update.yaml
查看该 Deployment 以新的名称创建 Pod 同时删除旧的 Pod:
kubectl get pods -l app=nginx
你可以通过应用新的 YAML 文件来增加 Deployment 中 Pod 的数量。
下面的 YAML 文件将 replicas 设置为 4,指定该 Deployment 应有 4 个 Pod:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 4 # 将副本数从 2 更新为 4
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
ports:
- containerPort: 80
应用新的 YAML 文件:
kubectl apply -f https://k8s.io/examples/application/deployment-scale.yaml
验证该 Deployment 有 4 个 Pod:
kubectl get pods -l app=nginx
输出的结果类似于:
NAME READY STATUS RESTARTS AGE
nginx-deployment-148880595-4zdqq 1/1 Running 0 25s
nginx-deployment-148880595-6zgi1 1/1 Running 0 25s
nginx-deployment-148880595-fxcez 1/1 Running 0 2m
nginx-deployment-148880595-rwovn 1/1 Running 0 2m
基于名称删除 Deployment:
kubectl delete deployment nginx-deployment
创建一个多副本应用首选方法是使用 Deployment,该 Deployment 内部将轮流使用 ReplicaSet。 在 Deployment 和 ReplicaSet 被引入到 Kubernetes 之前,多副本应用通过 ReplicationController 来配置。
本文介绍在 Kubernetes 中如何使用 PersistentVolume 和 Deployment 运行一个单实例有状态应用。 该示例应用是 MySQL。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
你需要有一个带有默认 StorageClass的 动态 PersistentVolume 供应程序, 或者自己静态的提供 PersistentVolume 来满足这里使用的 PersistentVolumeClaim。
你可以通过创建一个 Kubernetes Deployment 并使用 PersistentVolumeClaim 将其连接到 某已有的 PersistentVolume 来运行一个有状态的应用。 例如,这里的 YAML 描述的是一个运行 MySQL 的 Deployment,其中引用了 PersistentVolumeClaim。 文件为 /var/lib/mysql 定义了卷挂载,并创建了一个 PersistentVolumeClaim,寻找一个 20G 大小的卷。 该申领可以通过现有的满足需求的卷来满足,也可以通过动态供应卷的机制来满足。
注意:在配置的 YAML 文件中定义密码的做法是不安全的。具体安全解决方案请参考 Kubernetes Secrets。
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
# 在实际中使用 secret
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
apiVersion: v1
kind: PersistentVolume
metadata:
name: mysql-pv-volume
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
部署 YAML 文件中定义的 PV 和 PVC:
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-pv.yaml
部署 YAML 文件中定义的 Deployment:
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-deployment.yaml
展示 Deployment 相关信息:
kubectl describe deployment mysql
输出类似于:
Name: mysql
Namespace: default
CreationTimestamp: Tue, 01 Nov 2016 11:18:45 -0700
Labels: app=mysql
Annotations: deployment.kubernetes.io/revision=1
Selector: app=mysql
Replicas: 1 desired | 1 updated | 1 total | 0 available | 1 unavailable
StrategyType: Recreate
MinReadySeconds: 0
Pod Template:
Labels: app=mysql
Containers:
mysql:
Image: mysql:5.6
Port: 3306/TCP
Environment:
MYSQL_ROOT_PASSWORD: password
Mounts:
/var/lib/mysql from mysql-persistent-storage (rw)
Volumes:
mysql-persistent-storage:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: mysql-pv-claim
ReadOnly: false
Conditions:
Type Status Reason
---- ------ ------
Available False MinimumReplicasUnavailable
Progressing True ReplicaSetUpdated
OldReplicaSets: <none>
NewReplicaSet: mysql-63082529 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
33s 33s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set mysql-63082529 to 1
列举出 Deployment 创建的 Pod:
kubectl get pods -l app=mysql
输出类似于:
NAME READY STATUS RESTARTS AGE
mysql-63082529-2z3ki 1/1 Running 0 3m
查看 PersistentVolumeClaim:
kubectl describe pvc mysql-pv-claim
输出类似于:
Name: mysql-pv-claim
Namespace: default
StorageClass:
Status: Bound
Volume: mysql-pv-volume
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed=yes
pv.kubernetes.io/bound-by-controller=yes
Capacity: 20Gi
Access Modes: RWO
Events: <none>
前面 YAML 文件中创建了一个允许集群内其他 Pod 访问的数据库 Service。该 Service 中选项
clusterIP: None 让 Service 的 DNS 名称直接解析为 Pod 的 IP 地址。
当在一个 Service 下只有一个 Pod 并且不打算增加 Pod 的数量这是最好的。
运行 MySQL 客户端以连接到服务器:
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -ppassword
此命令在集群内创建一个新的 Pod 并运行 MySQL 客户端,并通过 Service 连接到服务器。 如果连接成功,你就知道有状态的 MySQL 数据库正处于运行状态。
Waiting for pod default/mysql-client-274442439-zyp6i to be running, status is Pending, pod ready: false
If you don't see a command prompt, try pressing enter.
mysql>
Deployment 中镜像或其他部分同往常一样可以通过 kubectl apply 命令更新。
以下是特定于有状态应用的一些注意事项:
strategy: type: Recreate。
该选项指示 Kubernetes 不使用滚动升级。滚动升级无法工作,因为这里一次不能运行多个
Pod。在使用更新的配置文件创建新的 Pod 前,Recreate 策略将保证先停止第一个 Pod。通过名称删除部署的对象:
kubectl delete deployment,svc mysql
kubectl delete pvc mysql-pv-claim
kubectl delete pv mysql-pv-volume
如果通过手动的方式供应 PersistentVolume,那么也需要手动删除它以释放下层资源。 如果是用动态供应方式创建的 PersistentVolume,在删除 PersistentVolumeClaim 后 PersistentVolume 将被自动删除。 一些存储服务(比如 EBS 和 PD)也会在 PersistentVolume 被删除时自动回收下层资源。
欲进一步了解 Deployment 对象,请参考 Deployment 对象
进一步了解部署应用
本页展示如何使用 StatefulSet 控制器运行一个有状态的应用程序。此例是多副本的 MySQL 数据库。 示例应用的拓扑结构有一个主服务器和多个副本,使用异步的基于行(Row-Based) 的数据复制。
这一配置不适合生产环境。 MySQL 设置都使用的是不安全的默认值,这是因为我们想把重点放在 Kubernetes 中运行有状态应用程序的一般模式上。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你需要有一个带有默认 StorageClass的 动态 PersistentVolume 供应程序, 或者自己静态的提供 PersistentVolume 来满足这里使用的 PersistentVolumeClaim。
MySQL 示例部署包含一个 ConfigMap、两个 Service 与一个 StatefulSet。
使用以下的 YAML 配置文件创建 ConfigMap :
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
data:
primary.cnf: |
# 仅在主服务器上应用此配置
[mysqld]
log-bin
replica.cnf: |
# 仅在副本服务器上应用此配置
[mysqld]
super-read-only
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-configmap.yaml
这个 ConfigMap 提供 my.cnf 覆盖设置,使你可以独立控制 MySQL 主服务器和副本服务器的配置。
在这里,你希望主服务器能够将复制日志提供给副本服务器,
并且希望副本服务器拒绝任何不是通过复制进行的写操作。
ConfigMap 本身没有什么特别之处,因而也不会出现不同部分应用于不同的 Pod 的情况。 每个 Pod 都会在初始化时基于 StatefulSet 控制器提供的信息决定要查看的部分。
使用以下 YAML 配置文件创建服务:
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# 用于连接到任一 MySQL 实例执行读操作的客户端服务
# 对于写操作,你必须连接到主服务器:mysql-0.mysql
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
app.kubernetes.io/name: mysql
readonly: "true"
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-services.yaml
这个无头 Service 给 StatefulSet 控制器
为集合中每个 Pod 创建的 DNS 条目提供了一个宿主。
因为无头服务名为 mysql,所以可以通过在同一 Kubernetes 集群和命名空间中的任何其他 Pod
内解析 <Pod 名称>.mysql 来访问 Pod。
客户端 Service 称为 mysql-read,是一种常规 Service,具有其自己的集群 IP。
该集群 IP 在报告就绪的所有 MySQL Pod 之间分配连接。
可能的端点集合包括 MySQL 主节点和所有副本节点。
请注意,只有读查询才能使用负载平衡的客户端 Service。 因为只有一个 MySQL 主服务器,所以客户端应直接连接到 MySQL 主服务器 Pod (通过其在无头 Service 中的 DNS 条目)以执行写入操作。
最后,使用以下 YAML 配置文件创建 StatefulSet:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
app.kubernetes.io/name: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
# 基于 Pod 序号生成 MySQL 服务器的 ID。
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 添加偏移量以避免使用 server-id=0 这一保留值。
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 将合适的 conf.d 文件从 config-map 复制到 emptyDir。
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# 如果已有数据,则跳过克隆。
[[ -d /var/lib/mysql/mysql ]] && exit 0
# 跳过主实例(序号索引 0)的克隆。
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 从原来的对等节点克隆数据。
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 准备备份。
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 1Gi
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# 检查我们是否可以通过 TCP 执行查询(skip-networking 是关闭的)。
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: gcr.io/google-samples/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 确定克隆数据的 binlog 位置(如果有的话)。
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup 已经生成了部分的 “CHANGE MASTER TO” 查询
# 因为我们从一个现有副本进行克隆。(需要删除末尾的分号!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# 在这里要忽略 xtrabackup_binlog_info (它是没用的)。
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 我们直接从主实例进行克隆。解析 binlog 位置。
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 检查我们是否需要通过启动复制来完成克隆。
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# 如果容器重新启动,最多尝试一次。
mv change_master_to.sql.in change_master_to.sql.orig
fi
# 当对等点请求时,启动服务器发送备份。
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 100m
memory: 100Mi
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
kubectl apply -f https://k8s.io/examples/application/mysql/mysql-statefulset.yaml
你可以通过运行以下命令查看启动进度:
kubectl get pods -l app=mysql --watch
一段时间后,你应该看到所有 3 个 Pod 进入 Running 状态:
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 2m
mysql-1 2/2 Running 0 1m
mysql-2 2/2 Running 0 1m
输入 Ctrl+C 结束监视操作。
如果你看不到任何进度,确保已启用前提条件中提到的动态 PersistentVolume 制备器。
此清单使用多种技术来管理作为 StatefulSet 的一部分的有状态 Pod。 下一节重点介绍其中的一些技巧,以解释 StatefulSet 创建 Pod 时发生的状况。
StatefulSet 控制器按序数索引顺序地每次启动一个 Pod。 它一直等到每个 Pod 报告就绪才再启动下一个 Pod。
此外,控制器为每个 Pod 分配一个唯一、稳定的名称,形如 <statefulset 名称>-<序数索引>,
其结果是 Pod 名为 mysql-0、mysql-1 和 mysql-2。
上述 StatefulSet 清单中的 Pod 模板利用这些属性来执行 MySQL 副本的有序启动。
在启动 Pod 规约中的任何容器之前,Pod 首先按顺序运行所有的 Init 容器。
第一个名为 init-mysql 的 Init 容器根据序号索引生成特殊的 MySQL 配置文件。
该脚本通过从 Pod 名称的末尾提取索引来确定自己的序号索引,而 Pod 名称由 hostname 命令返回。
然后将序数(带有数字偏移量以避免保留值)保存到 MySQL conf.d 目录中的文件 server-id.cnf。
这一操作将 StatefulSet 所提供的唯一、稳定的标识转换为 MySQL 服务器 ID,
而这些 ID 也是需要唯一性、稳定性保证的。
通过将内容复制到 conf.d 中,init-mysql 容器中的脚本也可以应用 ConfigMap 中的
primary.cnf 或 replica.cnf。
由于示例部署结构由单个 MySQL 主节点和任意数量的副本节点组成,
因此脚本仅将序数 0 指定为主节点,而将其他所有节点指定为副本节点。
与 StatefulSet 控制器的部署顺序保证相结合, 可以确保 MySQL 主服务器在创建副本服务器之前已准备就绪,以便它们可以开始复制。
通常,当新 Pod 作为副本节点加入集合时,必须假定 MySQL 主节点可能已经有数据。 还必须假设复制日志可能不会一直追溯到时间的开始。
这些保守的假设是允许正在运行的 StatefulSet 随时间扩大和缩小而不是固定在其初始大小的关键。
第二个名为 clone-mysql 的 Init 容器,第一次在带有空 PersistentVolume 的副本 Pod
上启动时,会在从属 Pod 上执行克隆操作。
这意味着它将从另一个运行中的 Pod 复制所有现有数据,使此其本地状态足够一致,
从而可以开始从主服务器复制。
MySQL 本身不提供执行此操作的机制,因此本示例使用了一种流行的开源工具 Percona XtraBackup。
在克隆期间,源 MySQL 服务器性能可能会受到影响。
为了最大程度地减少对 MySQL 主服务器的影响,该脚本指示每个 Pod 从序号较低的 Pod 中克隆。
可以这样做的原因是 StatefulSet 控制器始终确保在启动 Pod N+1 之前 Pod N 已准备就绪。
Init 容器成功完成后,应用容器将运行。MySQL Pod 由运行实际 mysqld 服务的 mysql
容器和充当辅助工具的
xtrabackup 容器组成。
xtrabackup sidecar 容器查看克隆的数据文件,并确定是否有必要在副本服务器上初始化 MySQL 复制。
如果是这样,它将等待 mysqld 准备就绪,然后使用从 XtraBackup 克隆文件中提取的复制参数执行
CHANGE MASTER TO 和 START SLAVE 命令。
一旦副本服务器开始复制后,它会记住其 MySQL 主服务器,并且如果服务器重新启动或连接中断也会自动重新连接。
另外,因为副本服务器会以其稳定的 DNS 名称查找主服务器(mysql-0.mysql),
即使由于重新调度而获得新的 Pod IP,它们也会自动找到主服务器。
最后,开始复制后,xtrabackup 容器监听来自其他 Pod 的连接,处理其数据克隆请求。
如果 StatefulSet 扩大规模,或者下一个 Pod 失去其 PersistentVolumeClaim 并需要重新克隆,
则此服务器将无限期保持运行。
你可以通过运行带有 mysql:5.7 镜像的临时容器并运行 mysql 客户端二进制文件,
将测试查询发送到 MySQL 主服务器(主机名 mysql-0.mysql)。
kubectl run mysql-client --image=mysql:5.7 -i --rm --restart=Never --\
mysql -h mysql-0.mysql <<EOF
CREATE DATABASE test;
CREATE TABLE test.messages (message VARCHAR(250));
INSERT INTO test.messages VALUES ('hello');
EOF
使用主机名 mysql-read 将测试查询发送到任何报告为就绪的服务器:
kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-read -e "SELECT * FROM test.messages"
你应该获得如下输出:
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
为了演示 mysql-read 服务在服务器之间分配连接,你可以在循环中运行 SELECT @@server_id:
kubectl run mysql-client-loop --image=mysql:5.7 -i -t --rm --restart=Never --\
bash -ic "while sleep 1; do mysql -h mysql-read -e 'SELECT @@server_id,NOW()'; done"
你应该看到报告的 @@server_id 发生随机变化,因为每次尝试连接时都可能选择了不同的端点:
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 100 | 2006-01-02 15:04:05 |
+-------------+---------------------+
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 102 | 2006-01-02 15:04:06 |
+-------------+---------------------+
+-------------+---------------------+
| @@server_id | NOW() |
+-------------+---------------------+
| 101 | 2006-01-02 15:04:07 |
+-------------+---------------------+
要停止循环时可以按 Ctrl+C ,但是让它在另一个窗口中运行非常有用, 这样你就可以看到以下步骤的效果。
为了证明从副本节点缓存而不是单个服务器读取数据的可用性提高,请在使 Pod 退出 Ready
状态时,保持上述 SELECT @@server_id 循环一直运行。
mysql 容器的就绪态探测
运行命令 mysql -h 127.0.0.1 -e 'SELECT 1',以确保服务器已启动并能够执行查询。
迫使就绪态探测失败的一种方法就是中止该命令:
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql /usr/bin/mysql.off
此命令会进入 Pod mysql-2 的实际容器文件系统,重命名 mysql 命令,导致就绪态探测无法找到它。
几秒钟后, Pod 会报告其中一个容器未就绪。你可以通过运行以下命令进行检查:
kubectl get pod mysql-2
在 READY 列中查找 1/2:
NAME READY STATUS RESTARTS AGE
mysql-2 1/2 Running 0 3m
此时,你应该会看到 SELECT @@server_id 循环继续运行,尽管它不再报告 102。
回想一下,init-mysql 脚本将 server-id 定义为 100 + $ordinal,
因此服务器 ID 102 对应于 Pod mysql-2。
现在修复 Pod,几秒钟后它应该重新出现在循环输出中:
kubectl exec mysql-2 -c mysql -- mv /usr/bin/mysql.off /usr/bin/mysql
如果删除了 Pod,则 StatefulSet 还会重新创建 Pod,类似于 ReplicaSet 对无状态 Pod 所做的操作。
kubectl delete pod mysql-2
StatefulSet 控制器注意到不再存在 mysql-2 Pod,于是创建一个具有相同名称并链接到相同
PersistentVolumeClaim 的新 Pod。
你应该看到服务器 ID 102 从循环输出中消失了一段时间,然后又自行出现。
如果你的 Kubernetes 集群具有多个节点,则可以通过发出以下 drain 命令来模拟节点停机(就好像节点在被升级)。
首先确定 MySQL Pod 之一在哪个节点上:
kubectl get pod mysql-2 -o wide
节点名称应显示在最后一列中:
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Running 0 15m 10.244.5.27 kubernetes-node-9l2t
接下来,通过运行以下命令腾空节点,该命令将其保护起来,以使新的 Pod 不能调度到该节点,
然后逐出所有现有的 Pod。将 <节点名称> 替换为在上一步中找到的节点名称。
腾空一个 Node 可能影响到在该节点上运行的其他负载和应用。 只应在测试集群上执行下列步骤。
# 关于对其他负载的影响,参见前文建议
kubectl drain <节点名称> --force --delete-local-data --ignore-daemonsets
现在,你可以监视 Pod 被重新调度到其他节点上:
kubectl get pod mysql-2 -o wide --watch
它看起来应该像这样:
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2 2/2 Terminating 0 15m 10.244.1.56 kubernetes-node-9l2t
[...]
mysql-2 0/2 Pending 0 0s <none> kubernetes-node-fjlm
mysql-2 0/2 Init:0/2 0 0s <none> kubernetes-node-fjlm
mysql-2 0/2 Init:1/2 0 20s 10.244.5.32 kubernetes-node-fjlm
mysql-2 0/2 PodInitializing 0 21s 10.244.5.32 kubernetes-node-fjlm
mysql-2 1/2 Running 0 22s 10.244.5.32 kubernetes-node-fjlm
mysql-2 2/2 Running 0 30s 10.244.5.32 kubernetes-node-fjlm
再次,你应该看到服务器 ID 102 从 SELECT @@server_id
循环输出中消失一段时间,然后再次出现。
现在去掉节点保护(Uncordon),使其恢复为正常模式:
kubectl uncordon <节点名称>
使用 MySQL 复制时,你可以通过添加副本节点来扩展读取查询的能力。 对于 StatefulSet,你可以使用单个命令实现此目的:
kubectl scale statefulset mysql --replicas=5
运行下面的命令,监视新的 Pod 启动:
kubectl get pods -l app=mysql --watch
一旦 Pod 启动,你应该看到服务器 ID 103 和 104 开始出现在 SELECT @@server_id
循环输出中。
你还可以验证这些新服务器在存在之前已添加了数据:
kubectl run mysql-client --image=mysql:5.7 -i -t --rm --restart=Never --\
mysql -h mysql-3.mysql -e "SELECT * FROM test.messages"
Waiting for pod default/mysql-client to be running, status is Pending, pod ready: false
+---------+
| message |
+---------+
| hello |
+---------+
pod "mysql-client" deleted
向下缩容操作也是很平滑的:
kubectl scale statefulset mysql --replicas=3
扩容操作会自动创建新的 PersistentVolumeClaim,但是缩容时不会自动删除这些 PVC。 这使你可以选择保留那些已被初始化的 PVC,以加速再次扩容,或者在删除它们之前提取数据。
你可以通过运行以下命令查看此效果:
kubectl get pvc -l app=mysql
这表明,尽管将 StatefulSet 缩小为 3,所有 5 个 PVC 仍然存在:
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
data-mysql-0 Bound pvc-8acbf5dc-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-1 Bound pvc-8ad39820-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-2 Bound pvc-8ad69a6d-b103-11e6-93fa-42010a800002 10Gi RWO 20m
data-mysql-3 Bound pvc-50043c45-b1c5-11e6-93fa-42010a800002 10Gi RWO 2m
data-mysql-4 Bound pvc-500a9957-b1c5-11e6-93fa-42010a800002 10Gi RWO 2m
如果你不打算重复使用多余的 PVC,则可以删除它们:
kubectl delete pvc data-mysql-3
kubectl delete pvc data-mysql-4
通过在终端上按 Ctrl+C 取消 SELECT @@server_id 循环,或从另一个终端运行以下命令:
kubectl delete pod mysql-client-loop --now
删除 StatefulSet。这也会开始终止 Pod。
kubectl delete statefulset mysql
验证 Pod 消失。它们可能需要一些时间才能完成终止。
kubectl get pods -l app=mysql
当上述命令返回如下内容时,你就知道 Pod 已终止:
No resources found.
删除 ConfigMap、Service 和 PersistentVolumeClaim。
kubectl delete configmap,service,pvc -l app=mysql
本文介绍如何扩缩 StatefulSet。StatefulSet 的扩缩指的是增加或者减少副本个数。
StatefulSets 仅适用于 Kubernetes 1.5 及以上版本。
要查看你的 Kubernetes 版本,运行 kubectl version。
不是所有 Stateful 应用都能很好地执行扩缩操作。 如果你不是很确定是否要扩缩你的 StatefulSet,可先参阅 StatefulSet 概念 或者 StatefulSet 教程。
仅当你确定你的有状态应用的集群是完全健康的,才可执行扩缩操作.
kubectl 扩缩 StatefulSet 首先,找到你要扩缩的 StatefulSet。
kubectl get statefulsets <statefulset 名称>
更改 StatefulSet 中副本个数:
kubectl scale statefulsets <statefulset 名称> --replicas=<新的副本数>
另外, 你可以就地更新 StatefulSet。
如果你的 StatefulSet 最初通过 kubectl apply 或 kubectl create --save-config 创建,
你可以更新 StatefulSet 清单中的 .spec.replicas,然后执行命令 kubectl apply:
kubectl apply -f <更新后的 statefulset 文件>
否则,可以使用 kubectl edit 编辑副本字段:
kubectl edit statefulsets <statefulset 名称>
或者使用 kubectl patch:
kubectl patch statefulsets <statefulset 名称> -p '{"spec":{"replicas":<new-replicas>}}'
当 Stateful 所管理的任何 Pod 不健康时,你不能对该 StatefulSet 执行缩容操作。 仅当 StatefulSet 的所有 Pod 都处于运行状态和 Ready 状况后才可缩容。
如果 spec.replicas 大于 1,Kubernetes 无法判定 Pod 不健康的原因。
Pod 不健康可能是由于永久性故障造成也可能是瞬态故障。
瞬态故障可能是节点升级或维护而引起的节点重启造成的。
如果该 Pod 不健康是由于永久性故障导致,则在不纠正该故障的情况下进行缩容可能会导致 StatefulSet 进入一种状态,其成员 Pod 数量低于应正常运行的副本数。 这种状态也许会导致 StatefulSet 不可用。
如果由于瞬态故障而导致 Pod 不健康并且 Pod 可能再次变为可用,那么瞬态错误可能会干扰你对 StatefulSet 的扩容/缩容操作。一些分布式数据库在同时有节点加入和离开时会遇到问题。 在这些情况下,最好是在应用级别进行分析扩缩操作的状态,并且只有在确保 Stateful 应用的集群是完全健康时才执行扩缩操作。
本任务展示如何删除 StatefulSet。
你可以像删除 Kubernetes 中的其他资源一样删除 StatefulSet:
使用 kubectl delete 命令,并按文件或者名字指定 StatefulSet。
kubectl delete -f <file.yaml>
kubectl delete statefulsets <statefulset 名称>
删除 StatefulSet 之后,你可能需要单独删除关联的无头服务(Headless Service)。
kubectl delete service <Service 名称>
当通过 kubectl 删除 StatefulSet 时,StatefulSet 会被缩容为 0。
属于该 StatefulSet 的所有 Pod 也被删除。
如果你只想删除 StatefulSet 而不删除 Pod,使用 --cascade=orphan。
kubectl delete -f <file.yaml> --cascade=orphan
通过将 --cascade=orphan 传递给 kubectl delete,在删除 StatefulSet 对象之后,
StatefulSet 管理的 Pod 会被保留下来。如果 Pod 具有标签 app.kubernetes.io/name=MyApp,
则可以按照如下方式删除它们:
kubectl delete pods -l app.kubernetes.io/name=MyApp
删除 StatefulSet 管理的 Pod 并不会删除关联的卷。这是为了确保你有机会在删除卷之前从卷中复制数据。 在 Pod 已经终止后删除 PVC 可能会触发删除背后的 PV 持久卷,具体取决于存储类和回收策略。 永远不要假定在 PVC 删除后仍然能够访问卷。
删除 PVC 时要谨慎,因为这可能会导致数据丢失。
要删除 StatefulSet 中的所有内容,包括关联的 Pod, 你可以运行如下所示的一系列命令:
grace=$(kubectl get pods <stateful-set-pod> --template '{{.spec.terminationGracePeriodSeconds}}')
kubectl delete statefulset -l app.kubernetes.io/name=MyApp
sleep $grace
kubectl delete pvc -l app.kubernetes.io/name=MyApp
在上面的例子中,Pod 的标签为 app.kubernetes.io/name=MyApp;适当地替换你自己的标签。
如果你发现 StatefulSet 的某些 Pod 长时间处于 'Terminating' 或者 'Unknown' 状态, 则可能需要手动干预以强制从 API 服务器中删除这些 Pod。这是一项有点危险的任务。 详细信息请阅读强制删除 StatefulSet 的 Pod。
进一步了解强制删除 StatefulSet 的 Pod。
本文介绍如何删除 StatefulSet 管理的 Pod,并解释这样操作时需要记住的一些注意事项。
在正常操作 StatefulSet 时,永远不需要强制删除 StatefulSet 管理的 Pod。 StatefulSet 控制器负责创建、 扩缩和删除 StatefulSet 管理的 Pod。此控制器尽力确保指定数量的从序数 0 到 N-1 的 Pod 处于活跃状态并准备就绪。StatefulSet 确保在任何时候,集群中最多只有一个具有给定标识的 Pod。 这就是所谓的由 StatefulSet 提供的最多一个(At Most One) Pod 的语义。
应谨慎进行手动强制删除操作,因为它可能会违反 StatefulSet 固有的至多一个的语义。 StatefulSet 可用于运行分布式和集群级的应用,这些应用需要稳定的网络标识和可靠的存储。 这些应用通常配置为具有固定标识固定数量的成员集合。 具有相同身份的多个成员可能是灾难性的,并且可能导致数据丢失 (例如票选系统中的脑裂场景)。
你可以使用下面的命令执行体面地删除 Pod:
kubectl delete pods <pod>
为了让上面操作能够体面地终止 Pod,Pod 一定不能设置 pod.Spec.TerminationGracePeriodSeconds 为 0。
将 pod.Spec.TerminationGracePeriodSeconds 设置为 0 秒的做法是不安全的,强烈建议 StatefulSet 类型的
Pod 不要使用。体面删除是安全的,并且会在 kubelet 从 API 服务器中删除资源名称之前确保
体面地结束 Pod。
当某个节点不可达时,不会引发自动删除 Pod。在无法访问的节点上运行的 Pod 在超时后会进入 “Terminating” 或者 “Unknown” 状态。 当用户尝试体面地删除无法访问的节点上的 Pod 时 Pod 也可能会进入这些状态。 从 API 服务器上删除处于这些状态 Pod 的仅有可行方法如下:
推荐使用第一种或者第二种方法。 如果确认节点已经不可用了(比如,永久断开网络、断电等), 则应删除 Node 对象。 如果节点遇到网裂问题,请尝试解决该问题或者等待其解决。 当网裂愈合时,kubelet 将完成 Pod 的删除并从 API 服务器上释放其名字。
通常,Pod 一旦不在节点上运行,或者管理员删除了节点,系统就会完成其删除动作。 你也可以通过强制删除 Pod 来绕过这一机制。
强制删除不会等待来自 kubelet 对 Pod 已终止的确认消息。 无论强制删除是否成功杀死了 Pod,它都会立即从 API 服务器中释放该名字。 这将让 StatefulSet 控制器创建一个具有相同标识的替身 Pod;因而可能导致正在运行 Pod 的重复, 并且如果所述 Pod 仍然可以与 StatefulSet 的成员通信,则将违反 StatefulSet 所要保证的最多一个的语义。
当你强制删除 StatefulSet 类型的 Pod 时,你要确保有问题的 Pod 不会再和 StatefulSet 管理的其他 Pod 通信并且可以安全地释放其名字以便创建替代 Pod。
如果要使用 kubectl 1.5 以上版本强制删除 Pod,请执行下面命令:
kubectl delete pods <pod> --grace-period=0 --force
如果你使用 kubectl 的 1.4 以下版本,则应省略 --force 选项:
kubectl delete pods <pod> --grace-period=0
如果在执行这些命令后 Pod 仍处于 Unknown 状态,请使用以下命令从集群中删除 Pod:
kubectl patch pod <pod> -p '{"metadata":{"finalizers":null}}'
请始终谨慎地执行强制删除 StatefulSet 类型的 Pod,并充分了解强制删除操作所涉及的风险。
进一步了解调试 StatefulSet。
在 Kubernetes 中,HorizontalPodAutoscaler 自动更新工作负载资源 (例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与“垂直(Vertical)”扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
水平 Pod 自动扩缩不适用于无法扩缩的对象(例如:DaemonSet。)
HorizontalPodAutoscaler 被实现为 Kubernetes API 资源和控制器。
资源决定了控制器的行为。 在 Kubernetes 控制平面内运行的水平 Pod 自动扩缩控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标, 例如,平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标。
使用水平 Pod 自动扩缩演练示例。
图 1. HorizontalPodAutoscaler 控制 Deployment 及其 ReplicaSet 的规模
Kubernetes 将水平 Pod 自动扩缩实现为一个间歇运行的控制回路(它不是一个连续的过程)。间隔由
kube-controller-manager
的 --horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
在每个时间段内,控制器管理器都会根据每个 HorizontalPodAutoscaler 定义中指定的指标查询资源利用率。
控制器管理器找到由 scaleTargetRef 定义的目标资源,然后根据目标资源的 .spec.selector 标签选择 Pod,
并从资源指标 API(针对每个 Pod 的资源指标)或自定义指标获取指标 API(适用于所有其他指标)。
对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果设置了目标使用率,控制器获取每个 Pod 中的容器资源使用情况, 并计算资源使用率。如果设置了 target 值,将直接使用原始数据(不再计算百分比)。 接下来,控制器根据平均的资源使用率或原始值计算出扩缩的比例,进而计算出目标副本数。
需要注意的是,如果 Pod 某些容器不支持资源采集,那么控制器将不会使用该 Pod 的 CPU 使用率。 下面的算法细节章节将会介绍详细的算法。
autoscaling/v2 版本 API 中,这个指标也可以根据 Pod 数量平分后再计算。HorizontalPodAutoscaler 的常见用途是将其配置为从聚合 API
(metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)获取指标。
metrics.k8s.io API 通常由名为 Metrics Server 的插件提供,需要单独启动。有关资源指标的更多信息,
请参阅 Metrics Server。
对 Metrics API 的支持解释了这些不同 API 的稳定性保证和支持状态。
HorizontalPodAutoscaler 控制器访问支持扩缩的相应工作负载资源(例如:Deployment 和 StatefulSet)。
这些资源每个都有一个名为 scale 的子资源,该接口允许你动态设置副本的数量并检查它们的每个当前状态。
有关 Kubernetes API 子资源的一般信息,
请参阅 Kubernetes API 概念。
从最基本的角度来看,Pod 水平自动扩缩控制器根据当前指标和期望指标来计算扩缩比例。
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
例如,如果当前指标值为 200m,而期望值为 100m,则副本数将加倍,
因为 200.0 / 100.0 == 2.0 如果当前值为 50m,则副本数将减半,
因为 50.0 / 100.0 == 0.5。如果比率足够接近 1.0(在全局可配置的容差范围内,默认为 0.1),
则控制平面会跳过扩缩操作。
如果 HorizontalPodAutoscaler 指定的是 targetAverageValue 或 targetAverageUtilization,
那么将会把指定 Pod 度量值的平均值做为 currentMetricValue。
在检查容差并决定最终值之前,控制平面还会考虑是否缺少任何指标,
以及有多少 Pod Ready。
所有设置了删除时间戳的 Pod(带有删除时间戳的对象正在关闭/移除的过程中)都会被忽略, 所有失败的 Pod 都会被丢弃。
如果某个 Pod 缺失度量值,它将会被搁置,只在最终确定扩缩数量时再考虑。
当使用 CPU 指标来扩缩时,任何还未就绪(还在初始化,或者可能是不健康的)状态的 Pod 或最近的指标度量值采集于就绪状态前的 Pod,该 Pod 也会被搁置。
由于技术限制,HorizontalPodAutoscaler 控制器在确定是否保留某些 CPU 指标时无法准确确定 Pod 首次就绪的时间。
相反,如果 Pod 未准备好并在其启动后的一个可配置的短时间窗口内转换为准备好,它会认为 Pod “尚未准备好”。
该值使用 --horizontal-pod-autoscaler-initial-readiness-delay 标志配置,默认值为 30 秒。
一旦 Pod 准备就绪,如果它发生在自启动后较长的、可配置的时间内,它就会认为任何向准备就绪的转换都是第一个。
该值由 -horizontal-pod-autoscaler-cpu-initialization-period 标志配置,默认为 5 分钟。
在排除掉被搁置的 Pod 后,扩缩比例就会根据 currentMetricValue/desiredMetricValue
计算出来。
如果缺失某些度量值,控制平面会更保守地重新计算平均值,在需要缩小时假设这些 Pod 消耗了目标值的 100%, 在需要放大时假设这些 Pod 消耗了 0% 目标值。这可以在一定程度上抑制扩缩的幅度。
此外,如果存在任何尚未就绪的 Pod,工作负载会在不考虑遗漏指标或尚未就绪的 Pod 的情况下进行扩缩, 控制器保守地假设尚未就绪的 Pod 消耗了期望指标的 0%,从而进一步降低了扩缩的幅度。
考虑到尚未准备好的 Pod 和缺失的指标后,控制器会重新计算使用率。 如果新的比率与扩缩方向相反,或者在容差范围内,则控制器不会执行任何扩缩操作。 在其他情况下,新比率用于决定对 Pod 数量的任何更改。
注意,平均利用率的原始值是通过 HorizontalPodAutoscaler 状态体现的, 而不考虑尚未准备好的 Pod 或缺少的指标,即使使用新的使用率也是如此。
如果创建 HorizontalPodAutoscaler 时指定了多个指标,
那么会按照每个指标分别计算扩缩副本数,取最大值进行扩缩。
如果任何一个指标无法顺利地计算出扩缩副本数(比如,通过 API 获取指标时出错),
并且可获取的指标建议缩容,那么本次扩缩会被跳过。
这表示,如果一个或多个指标给出的 desiredReplicas 值大于当前值,HPA 仍然能实现扩容。
最后,在 HPA 控制器执行扩缩操作之前,会记录扩缩建议信息。
控制器会在操作时间窗口中考虑所有的建议信息,并从中选择得分最高的建议。
这个值可通过 kube-controller-manager 服务的启动参数
--horizontal-pod-autoscaler-downscale-stabilization 进行配置,
默认值为 5 分钟。
这个配置可以让系统更为平滑地进行缩容操作,从而消除短时间内指标值快速波动产生的影响。
HorizontalPodAutoscaler 是 Kubernetes autoscaling API 组中的 API 资源。
当前的稳定版本可以在 autoscaling/v2 API 版本中找到,其中包括对基于内存和自定义指标执行扩缩的支持。
在使用 autoscaling/v1 时,autoscaling/v2 中引入的新字段作为注释保留。
创建 HorizontalPodAutoscaler 对象时,需要确保所给的名称是一个合法的 DNS 子域名。 有关 API 对象的更多信息,请查阅 HorizontalPodAutoscaler 对象文档。
在使用 HorizontalPodAutoscaler 管理一组副本的规模时,由于评估的指标的动态特性, 副本的数量可能会经常波动。这有时被称为 抖动(thrashing) 或 波动(flapping)。 它类似于控制论中的 滞后(hysteresis) 概念。
Kubernetes 允许你在 Deployment 上执行滚动更新。在这种情况下,Deployment 为你管理下层的 ReplicaSet。
当你为一个 Deployment 配置自动扩缩时,你要为每个 Deployment 绑定一个 HorizontalPodAutoscaler。
HorizontalPodAutoscaler 管理 Deployment 的 replicas 字段。
Deployment Controller 负责设置下层 ReplicaSet 的 replicas 字段,
以便确保在上线及后续过程副本个数合适。
如果你对一个副本个数被自动扩缩的 StatefulSet 执行滚动更新,该 StatefulSet 会直接管理它的 Pod 集合(不存在类似 ReplicaSet 这样的中间资源)。
HPA 的任何目标资源都可以基于其中的 Pod 的资源用量来实现扩缩。
在定义 Pod 规约时,类似 cpu 和 memory 这类资源请求必须被设定。
这些设定值被用来确定资源利用量并被 HPA 控制器用来对目标资源完成扩缩操作。
要使用基于资源利用率的扩缩,可以像下面这样指定一个指标源:
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
基于这一指标设定,HPA 控制器会维持扩缩目标中的 Pods 的平均资源利用率在 60%。 利用率是 Pod 的当前资源用量与其请求值之间的比值。 关于如何计算利用率以及如何计算平均值的细节可参考算法小节。
由于所有的容器的资源用量都会被累加起来,Pod 的总体资源用量值可能不会精确体现各个容器的资源用量。 这一现象也会导致一些问题,例如某个容器运行时的资源用量非常高,但因为 Pod 层面的资源用量总值让人在可接受的约束范围内,HPA 不会执行扩大目标对象规模的操作。
Kubernetes v1.27 [beta]
HorizontalPodAutoscaler API 也支持容器指标源,这时 HPA 可以跟踪记录一组 Pod 中各个容器的资源用量,进而触发扩缩目标对象的操作。 容器资源指标的支持使得你可以为特定 Pod 中最重要的容器配置规模扩缩阈值。 例如,如果你有一个 Web 应用和一个执行日志操作的边车容器,你可以基于 Web 应用的资源用量来执行扩缩,忽略边车容器的存在及其资源用量。
如果你更改扩缩目标对象,令其使用新的、包含一组不同的容器的 Pod 规约,你就需要修改 HPA 的规约才能基于新添加的容器来执行规模扩缩操作。 如果指标源中指定的容器不存在或者仅存在于部分 Pod 中,那么这些 Pod 会被忽略, HPA 会重新计算资源用量值。参阅算法小节进一步了解计算细节。 要使用容器资源用量来完成自动扩缩,可以像下面这样定义指标源:
type: ContainerResource
containerResource:
name: cpu
container: application
target:
type: Utilization
averageUtilization: 60
在上面的例子中,HPA 控制器会对目标对象执行扩缩操作以确保所有 Pod 中
application 容器的平均 CPU 用量为 60%。
如果你要更改 HorizontalPodAutoscaler 所跟踪记录的容器的名称,你可以按一定顺序来执行这一更改, 确保在应用更改的过程中用来判定扩缩行为的容器可用。 在更新定义容器的资源(如 Deployment)之前,你需要更新相关的 HPA, 使之能够同时跟踪记录新的和老的容器名称。这样,HPA 就能够在整个更新过程中继续计算并提供扩缩操作建议。
一旦你已经将容器名称变更这一操作应用到整个负载对象至上,就可以从 HPA 的规约中去掉老的容器名称,完成清理操作。
Kubernetes v1.23 [stable]
(之前的 autoscaling/v2beta2 API 版本将此功能作为 beta 功能提供)
如果你使用 autoscaling/v2 API 版本,则可以将 HorizontalPodAutoscaler
配置为基于自定义指标(未内置于 Kubernetes 或任何 Kubernetes 组件)进行扩缩。
HorizontalPodAutoscaler 控制器能够从 Kubernetes API 查询这些自定义指标。
有关要求,请参阅对 Metrics APIs 的支持。
Kubernetes v1.23 [stable]
(之前的 autoscaling/v2beta2 API 版本将此功能作为 beta 功能提供)
如果你使用 autoscaling/v2 API 版本,你可以为 HorizontalPodAutoscaler 指定多个指标以进行扩缩。
HorizontalPodAutoscaler 控制器评估每个指标,并根据该指标提出一个新的比例。
HorizontalPodAutoscaler 采用为每个指标推荐的最大比例,
并将工作负载设置为该大小(前提是这不大于你配置的总体最大值)。
默认情况下,HorizontalPodAutoscaler 控制器会从一系列的 API 中检索度量值。 集群管理员需要确保下述条件,以保证 HPA 控制器能够访问这些 API:
启用了 API 聚合层
相应的 API 已注册:
对于资源指标,将使用 metrics.k8s.io API,
一般由 metrics-server 提供。
它可以作为集群插件启动。
对于自定义指标,将使用 custom.metrics.k8s.io API。
它由其他度量指标方案厂商的“适配器(Adapter)” API 服务器提供。
检查你的指标管道以查看是否有可用的 Kubernetes 指标适配器。
对于外部指标,将使用 external.metrics.k8s.io API。
可能由上面的自定义指标适配器提供。
关于指标来源以及其区别的更多信息,请参阅相关的设计文档, HPA V2, custom.metrics.k8s.io 和 external.metrics.k8s.io。
关于如何使用它们的示例, 请参考使用自定义指标的教程 和使用外部指标的教程。
Kubernetes v1.23 [stable]
(之前的 autoscaling/v2beta2 API 版本将此功能作为 beta 功能提供)
如果你使用 v2 HorizontalPodAutoscaler API,你可以使用 behavior 字段
(请参阅 API 参考)
来配置单独的放大和缩小行为。你可以通过在行为字段下设置 scaleUp 和/或 scaleDown 来指定这些行为。
你可以指定一个“稳定窗口”,以防止扩缩目标的副本计数发生波动。 扩缩策略还允许你在扩缩时控制副本的变化率。
可以在规约的 behavior 部分中指定一个或多个扩缩策略。当指定多个策略时,
允许最大更改量的策略是默认选择的策略。以下示例显示了缩小时的这种行为:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
periodSeconds 表示在过去的多长时间内要求策略值为真。
你可以设置 periodSeconds 的最大值为 1800(半小时)。
第一个策略(Pods)允许在一分钟内最多缩容 4 个副本。第二个策略(Percent)
允许在一分钟内最多缩容当前副本个数的百分之十。
由于默认情况下会选择容许更大程度作出变更的策略,只有 Pod 副本数大于 40 时, 第二个策略才会被采用。如果副本数为 40 或者更少,则应用第一个策略。 例如,如果有 80 个副本,并且目标必须缩小到 10 个副本,那么在第一步中将减少 8 个副本。 在下一轮迭代中,当副本的数量为 72 时,10% 的 Pod 数为 7.2,但是这个数字向上取整为 8。 在 autoscaler 控制器的每个循环中,将根据当前副本的数量重新计算要更改的 Pod 数量。 当副本数量低于 40 时,应用第一个策略(Pods),一次减少 4 个副本。
可以指定扩缩方向的 selectPolicy 字段来更改策略选择。
通过设置 Min 的值,它将选择副本数变化最小的策略。
将该值设置为 Disabled 将完全禁用该方向的扩缩。
当用于扩缩的指标不断波动时,稳定窗口用于限制副本计数的波动。 自动扩缩算法使用此窗口来推断先前的期望状态并避免对工作负载规模进行不必要的更改。
例如,在以下示例代码段中,为 scaleDown 指定了稳定窗口。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
当指标显示目标应该缩容时,自动扩缩算法查看之前计算的期望状态,并使用指定时间间隔内的最大值。 在上面的例子中,过去 5 分钟的所有期望状态都会被考虑。
这近似于滚动最大值,并避免了扩缩算法频繁删除 Pod 而又触发重新创建等效 Pod。
要使用自定义扩缩,不必指定所有字段。 只有需要自定义的字段才需要指定。 这些自定义值与默认值合并。 默认值与 HPA 算法中的现有行为匹配。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
用于缩小稳定窗口的时间为 300 秒(或是 --horizontal-pod-autoscaler-downscale-stabilization
参数设定值)。
只有一种缩容的策略,允许 100% 删除当前运行的副本,这意味着扩缩目标可以缩小到允许的最小副本数。
对于扩容,没有稳定窗口。当指标显示目标应该扩容时,目标会立即扩容。
这里有两种策略,每 15 秒最多添加 4 个 Pod 或 100% 当前运行的副本数,直到 HPA 达到稳定状态。
将下面的 behavior 配置添加到 HPA 中,可提供一个 1 分钟的自定义缩容稳定窗口:
behavior:
scaleDown:
stabilizationWindowSeconds: 60
将下面的 behavior 配置添加到 HPA 中,可限制 Pod 被 HPA 删除速率为每分钟 10%:
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
为了确保每分钟删除的 Pod 数不超过 5 个,可以添加第二个缩容策略,大小固定为 5,并将 selectPolicy 设置为最小值。
将 selectPolicy 设置为 Min 意味着 autoscaler 会选择影响 Pod 数量最小的策略:
behavior:
scaleDown:
policies:
- type: Percent
value: 10
periodSeconds: 60
- type: Pods
value: 5
periodSeconds: 60
selectPolicy: Min
selectPolicy 的值 Disabled 会关闭对给定方向的缩容。
因此使用以下策略,将会阻止缩容:
behavior:
scaleDown:
selectPolicy: Disabled
与每个 API 资源一样,HorizontalPodAutoscaler 都被 kubectl 以标准方式支持。
你可以使用 kubectl create 命令创建一个新的自动扩缩器。
你可以通过 kubectl get hpa 列出自动扩缩器或通过 kubectl describe hpa 获取详细描述。
最后,你可以使用 kubectl delete hpa 删除自动扩缩器。
此外,还有一个特殊的 kubectl autoscale 命令用于创建 HorizontalPodAutoscaler 对象。
例如,执行 kubectl autoscale rs foo --min=2 --max=5 --cpu-percent=80
将为 ReplicaSet foo 创建一个自动扩缩器,目标 CPU 利用率设置为 80%,副本数在 2 到 5 之间。
你可以在不必更改 HPA 配置的情况下隐式地为某个目标禁用 HPA。
如果此目标的期望副本个数被设置为 0,而 HPA 的最小副本个数大于 0,
则 HPA 会停止调整目标(并将其自身的 ScalingActive 状况设置为 false),
直到你通过手动调整目标的期望副本个数或 HPA 的最小副本个数来重新激活。
当启用 HPA 时,建议从它们的清单中删除
Deployment 和/或 StatefulSet 的 spec.replicas 的值。
如果不这样做,则只要应用对该对象的更改,例如通过 kubectl apply -f deployment.yaml,
这将指示 Kubernetes 将当前 Pod 数量扩缩到 spec.replicas 键的值。这可能不是所希望的,
并且当 HPA 处于活动状态时可能会很麻烦。
请记住,删除 spec.replicas 可能会导致 Pod 计数一次性降级,因为此键的默认值为 1
(参考 Deployment Replicas)。
更新后,除 1 之外的所有 Pod 都将开始其终止程序。之后的任何部署应用程序都将正常运行,
并根据需要遵守滚动更新配置。你可以根据修改部署的方式选择以下两种方法之一来避免这种降级:
kubectl apply edit-last-applied deployment/<Deployment 名称>spec.replicas。当你保存并退出编辑器时,kubectl 会应用更新。
在此步骤中不会更改 Pod 计数。spec.replicas。如果你使用源代码管理,
还应提交你的更改或采取任何其他步骤来修改源代码,以适应你如何跟踪更新。kubectl apply -f deployment.yaml
使用服务器端 Apply 机制, 你可以遵循交出所有权说明, 该指南涵盖了这个确切的用例。
如果你在集群中配置自动扩缩,你可能还需要考虑运行集群级别的自动扩缩器, 例如 Cluster Autoscaler。
有关 HorizontalPodAutoscaler 的更多信息:
kubectl autoscale 的文档。HorizontalPodAutoscaler(简称 HPA ) 自动更新工作负载资源(例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与“垂直(Vertical)”扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
本文档将引导你完成启用 HorizontalPodAutoscaler 以自动管理示例 Web 应用程序的扩缩的示例。 此示例工作负载是运行一些 PHP 代码的 Apache httpd。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.23. 要获知版本信息,请输入kubectl version.
如果你运行的是旧版本的 Kubernetes,请参阅该版本的文档版本 (可用的文档版本)。
按照本演练进行操作,你需要一个部署并配置了 Metrics Server 的集群。 Kubernetes Metrics Server 从集群中的 kubelets 收集资源指标, 并通过 Kubernetes API 公开这些指标, 使用 APIService 添加代表指标读数的新资源。
要了解如何部署 Metrics Server,请参阅 metrics-server 文档。
如果你正在运行 Minikube,运行以下命令以启用 metrics-server:
minikube addons enable metrics-server
为了演示 HorizontalPodAutoscaler,你将首先启动一个 Deployment 用 hpa-example 镜像运行一个容器,
然后使用以下清单文件将其暴露为一个 服务(Service):
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
为此,运行下面的命令:
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
deployment.apps/php-apache created
service/php-apache created
现在服务器正在运行,使用 kubectl 创建自动扩缩器。
kubectl autoscale 子命令是 kubectl 的一部分,
可以帮助你执行此操作。
你将很快运行一个创建 HorizontalPodAutoscaler 的命令, 该 HorizontalPodAutoscaler 维护由你在这些说明的第一步中创建的 php-apache Deployment 控制的 Pod 存在 1 到 10 个副本。
粗略地说,HPA 控制器将增加和减少副本的数量
(通过更新 Deployment)以保持所有 Pod 的平均 CPU 利用率为 50%。
Deployment 然后更新 ReplicaSet —— 这是所有 Deployment 在 Kubernetes 中工作方式的一部分 ——
然后 ReplicaSet 根据其 .spec 的更改添加或删除 Pod。
由于每个 Pod 通过 kubectl run 请求 200 milli-cores,这意味着平均 CPU 使用率为 100 milli-cores。
有关算法的更多详细信息,
请参阅算法详细信息。
创建 HorizontalPodAutoscaler:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
你可以通过运行以下命令检查新制作的 HorizontalPodAutoscaler 的当前状态:
# 你可以使用 “hpa” 或 “horizontalpodautoscaler”;任何一个名字都可以。
kubectl get hpa
输出类似于:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
(如果你看到其他具有不同名称的 HorizontalPodAutoscalers,这意味着它们已经存在,这通常不是问题)。
请注意当前的 CPU 利用率是 0%,这是由于我们尚未发送任何请求到服务器
(TARGET 列显示了相应 Deployment 所控制的所有 Pod 的平均 CPU 利用率)。
接下来,看看自动扩缩器如何对增加的负载做出反应。 为此,你将启动一个不同的 Pod 作为客户端。 客户端 Pod 中的容器在无限循环中运行,向 php-apache 服务发送查询。
# 在单独的终端中运行它
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
现在执行:
# 准备好后按 Ctrl+C 结束观察
kubectl get hpa php-apache --watch
一分钟时间左右之后,通过以下命令,我们可以看到 CPU 负载升高了;例如:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m
然后,更多的副本被创建。例如:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 7 3m
这时,由于请求增多,CPU 利用率已经升至请求值的 305%。 可以看到,Deployment 的副本数量已经增长到了 7:
kubectl get deployment php-apache
你应该会看到与 HorizontalPodAutoscaler 中的数字与副本数匹配
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 7/7 7 7 19m
要完成该示例,请停止发送负载。
在我们创建 busybox 容器的终端中,输入 <Ctrl> + C 来终止负载的产生。
然后验证结果状态(大约一分钟后):
# 准备好后按 Ctrl+C 结束观察
kubectl get hpa php-apache --watch
输出类似于:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
Deployment 也显示它已经缩小了:
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 27m
一旦 CPU 利用率降至 0,HPA 会自动将副本数缩减为 1。
自动扩缩完成副本数量的改变可能需要几分钟的时间。
利用 autoscaling/v2 API 版本,你可以在自动扩缩 php-apache 这个
Deployment 时使用其他度量指标。
首先,将 HorizontalPodAutoscaler 的 YAML 文件改为 autoscaling/v2 格式:
kubectl get hpa php-apache -o yaml > /tmp/hpa-v2.yaml
在编辑器中打开 /tmp/hpa-v2.yaml,你应看到如下所示的 YAML 文件:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
status:
observedGeneration: 1
lastScaleTime: <some-time>
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
需要注意的是,targetCPUUtilizationPercentage 字段已经被名为 metrics 的数组所取代。
CPU 利用率这个度量指标是一个 resource metric(资源度量指标),因为它表示容器上指定资源的百分比。
除 CPU 外,你还可以指定其他资源度量指标。默认情况下,目前唯一支持的其他资源度量指标为内存。
只要 metrics.k8s.io API 存在,这些资源度量指标就是可用的,并且他们不会在不同的 Kubernetes 集群中改变名称。
你还可以指定资源度量指标使用绝对数值,而不是百分比,你需要将 target.type 从
Utilization 替换成 AverageValue,同时设置 target.averageValue
而非 target.averageUtilization 的值。
还有两种其他类型的度量指标,他们被认为是 custom metrics(自定义度量指标): 即 Pod 度量指标和 Object 度量指标。 这些度量指标可能具有特定于集群的名称,并且需要更高级的集群监控设置。
第一种可选的度量指标类型是 Pod 度量指标。这些指标从某一方面描述了 Pod,
在不同 Pod 之间进行平均,并通过与一个目标值比对来确定副本的数量。
它们的工作方式与资源度量指标非常相像,只是它们仅支持 target 类型为 AverageValue。
Pod 度量指标通过如下代码块定义:
type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
第二种可选的度量指标类型是对象 (Object)度量指标。
这些度量指标用于描述在相同名字空间中的别的对象,而非 Pod。
请注意这些度量指标不一定来自某对象,它们仅用于描述这些对象。
对象度量指标支持的 target 类型包括 Value 和 AverageValue。
如果是 Value 类型,target 值将直接与 API 返回的度量指标比较,
而对于 AverageValue 类型,API 返回的度量值将按照 Pod 数量拆分,
然后再与 target 值比较。
下面的 YAML 文件展示了一个表示 requests-per-second 的度量指标。
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
如果你指定了多个上述类型的度量指标,HorizontalPodAutoscaler 将会依次考量各个指标。 HorizontalPodAutoscaler 将会计算每一个指标所提议的副本数量,然后最终选择一个最高值。
比如,如果你的监控系统能够提供网络流量数据,你可以通过 kubectl edit
命令将上述 Horizontal Pod Autoscaler 的定义更改为:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
status:
observedGeneration: 1
lastScaleTime: <some-time>
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource
resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
current:
value: 10k
这样,你的 HorizontalPodAutoscaler 将会尝试确保每个 Pod 的 CPU 利用率在 50% 以内, 每秒能够服务 1000 个数据包请求, 并确保所有在 Ingress 后的 Pod 每秒能够服务的请求总数达到 10000 个。
许多度量流水线允许你通过名称或附加的标签来描述度量指标。
对于所有非资源类型度量指标(Pod、Object 和后面将介绍的 External),
可以额外指定一个标签选择算符。例如,如果你希望收集包含 verb 标签的
http_requests 度量指标,可以按如下所示设置度量指标块,使得扩缩操作仅针对
GET 请求执行:
type: Object
object:
metric:
name: http_requests
selector: {matchLabels: {verb: GET}}
这个选择算符使用与 Kubernetes 标签选择算符相同的语法。
如果名称和标签选择算符匹配到多个系列,监测管道会决定如何将多个系列合并成单个值。
选择算符是可以累加的,它不会选择目标以外的对象(类型为 Pods 的目标 Pod 或者类型为 Object 的目标对象)。
运行在 Kubernetes 上的应用程序可能需要基于与 Kubernetes 集群中的任何对象没有明显关系的度量指标进行自动扩缩, 例如那些描述与任何 Kubernetes 名字空间中的服务都无直接关联的度量指标。 在 Kubernetes 1.10 及之后版本中,你可以使用外部度量指标(external metrics)。
使用外部度量指标时,需要了解你所使用的监控系统,相关的设置与使用自定义指标时类似。
外部度量指标使得你可以使用你的监控系统的任何指标来自动扩缩你的集群。
你需要在 metric 块中提供 name 和 selector,同时将类型由 Object 改为 External。
如果 metricSelector 匹配到多个度量指标,HorizontalPodAutoscaler 将会把它们加和。
外部度量指标同时支持 Value 和 AverageValue 类型,这与 Object 类型的度量指标相同。
例如,如果你的应用程序处理来自主机上消息队列的任务, 为了让每 30 个任务有 1 个工作者实例,你可以将下面的内容添加到 HorizontalPodAutoscaler 的配置中。
- type: External
external:
metric:
name: queue_messages_ready
selector:
matchLabels:
queue: "worker_tasks"
target:
type: AverageValue
averageValue: 30
如果可能,还是推荐定制度量指标而不是外部度量指标,因为这便于让系统管理员加固定制度量指标 API。 而外部度量指标 API 可以允许访问所有的度量指标。 当暴露这些服务时,系统管理员需要仔细考虑这个问题。
使用 autoscaling/v2 格式的 HorizontalPodAutoscaler 时,你将可以看到
Kubernetes 为 HorizongtalPodAutoscaler 设置的状态条件(Status Conditions)。
这些状态条件可以显示当前 HorizontalPodAutoscaler 是否能够执行扩缩以及是否受到一定的限制。
status.conditions 字段展示了这些状态条件。
可以通过 kubectl describe hpa 命令查看当前影响 HorizontalPodAutoscaler
的各种状态条件信息:
kubectl describe hpa cm-test
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )
"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range
Events:
对于上面展示的这个 HorizontalPodAutoscaler,我们可以看出有若干状态条件处于健康状态。
首先,AbleToScale 表明 HPA 是否可以获取和更新扩缩信息,以及是否存在阻止扩缩的各种回退条件。
其次,ScalingActive 表明 HPA 是否被启用(即目标的副本数量不为零)以及是否能够完成扩缩计算。
当这一状态为 False 时,通常表明获取度量指标存在问题。
最后一个条件 ScalingLimited 表明所需扩缩的值被 HorizontalPodAutoscaler
所定义的最大或者最小值所限制(即已经达到最大或者最小扩缩值)。
这通常表明你可能需要调整 HorizontalPodAutoscaler 所定义的最大或者最小副本数量的限制了。
HorizontalPodAutoscaler 和 度量指标 API 中的所有的度量指标使用 Kubernetes
中称为量纲(Quantity)的特殊整数表示。
例如,数量 10500m 用十进制表示为 10.5。
如果可能的话,度量指标 API 将返回没有后缀的整数,否则返回以千分单位的数量。
这意味着你可能会看到你的度量指标在 1 和 1500m(也就是在十进制记数法中的 1 和 1.5)之间波动。
除了使用 kubectl autoscale 命令,也可以使用以下清单以声明方式创建 HorizontalPodAutoscaler:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
使用如下命令创建 Autoscaler:
kubectl create -f https://k8s.io/examples/application/hpa/php-apache.yaml
horizontalpodautoscaler.autoscaling/php-apache created
Kubernetes v1.21 [stable]
本文展示如何限制应用程序的并发干扰数量,在允许集群管理员管理集群节点的同时保证高可用。
kubectl version.
用户想要保护通过内置的 Kubernetes 控制器指定的应用,这是最常见的使用场景:
在这种情况下,在控制器的 .spec.selector 字段中做记录,并在 PDB 的
.spec.selector 字段中加入同样的选择算符。
从 1.15 版本开始,PDB 支持启用 Scale 子资源 的自定义控制器。
用户也可以用 PDB 来保护不受上述控制器控制的 Pod,或任意的 Pod 集合,但是正如 任意工作负载和任意选择算符中描述的,这里存在一些限制。
确定在自发干扰时,多少实例可以在短时间内同时关闭。
minAvailable 或 maxUnavailable 的值可以表示为整数或百分比。
minAvailable 设置为 10,
那么即使在干扰期间,也必须始终有 10 个 Pod 可用。"50%")来指定百分比时,它表示占总 Pod 数的百分比。
例如,如果将 minAvailable 设置为 "50%",则干扰期间至少 50% 的 Pod 保持可用。如果将值指定为百分比,则可能无法映射到确切数量的 Pod。例如,如果你有 7 个 Pod,
并且你将 minAvailable 设置为 "50%",具体是 3 个 Pod 或 4 个 Pod 必须可用并非显而易见。
Kubernetes 采用向上取整到最接近的整数的办法,因此在这种情况下,必须有 4 个 Pod。
当你将 maxUnavailable 值指定为一个百分比时,Kubernetes 将可以干扰的 Pod 个数向上取整。
因此干扰可以超过你定义的 maxUnavailable 百分比。
你可以检查控制此行为的代码。
一个 PodDisruptionBudget 有 3 个字段:
.spec.selector 用于指定其所作用的 Pod 集合,该字段为必需字段。.spec.minAvailable 表示驱逐后仍须保证可用的 Pod 数量。即使因此影响到 Pod 驱逐
(即该条件在和 Pod 驱逐发生冲突时优先保证)。
minAvailable 值可以是绝对值,也可以是百分比。.spec.maxUnavailable (Kubernetes 1.7 及更高的版本中可用)表示驱逐后允许不可用的
Pod 的最大数量。其值可以是绝对值或是百分比。policy/v1beta1 和 policy/v1 API 中 PodDisruptionBudget 的空选择算符的行为
略有不同。在 policy/v1beta1 中,空的选择算符不会匹配任何 Pod,而
policy/v1 中,空的选择算符会匹配名字空间中所有 Pod。
用户在同一个 PodDisruptionBudget 中只能够指定 maxUnavailable 和 minAvailable 中的一个。
maxUnavailable 只能够用于控制存在相应控制器的 Pod 的驱逐(即不受控制器控制的 Pod 不在
maxUnavailable 控制范围内)。在下面的示例中,
“所需副本”指的是相应控制器的 scale,控制器对 PodDisruptionBudget 所选择的 Pod 进行管理。
示例 1:设置 minAvailable 值为 5 的情况下,驱逐时需保证 PodDisruptionBudget 的 selector
选中的 Pod 中 5 个或 5 个以上处于健康状态。
示例 2:设置 minAvailable 值为 30% 的情况下,驱逐时需保证 Pod 所需副本的至少 30% 处于健康状态。
示例 3:设置 maxUnavailable 值为 5 的情况下,驱逐时需保证所需副本中最多 5 个处于不可用状态。
示例 4:设置 maxUnavailable 值为 30% 的情况下,只要不健康的副本数量不超过所需副本总数的 30%
(取整到最接近的整数),就允许驱逐。如果所需副本的总数仅为一个,则仍允许该单个副本中断,
从而导致不可用性实际达到 100%。
在典型用法中,干扰预算会被用于一个控制器管理的一组 Pod 中 —— 例如:一个 ReplicaSet 或 StatefulSet 中的 Pod。
干扰预算并不能真正保证指定数量/百分比的 Pod 一直处于运行状态。例如:当 Pod 集合的规模处于预算指定的最小值时,承载集合中某个 Pod 的节点发生了故障,这样就导致集合中可用 Pod 的数量低于预算指定值。预算只能够针对自发的驱逐提供保护,而不能针对所有 Pod 不可用的诱因。
如果你将 maxUnavailable 的值设置为 0%(或 0)或设置 minAvailable 值为 100%(或等于副本数)
则会阻止所有的自愿驱逐。
当你为 ReplicaSet 等工作负载对象设置阻止自愿驱逐时,你将无法成功地腾空运行其中一个 Pod 的节点。
如果你尝试腾空正在运行着被阻止驱逐的 Pod 的节点,则腾空永远不会完成。
按照 PodDisruptionBudget 的语义,这是允许的。
用户可以在下面看到 Pod 干扰预算定义的示例,它们与带有 app: zookeeper 标签的 Pod 相匹配:
使用 minAvailable 的 PDB 示例:
使用 maxUnavailable 的 PDB 示例:
例如,如果上述 zk-pdb 选择的是一个规格为 3 的 StatefulSet 对应的 Pod,
那么上面两种规范的含义完全相同。
推荐使用 maxUnavailable,因为它自动响应控制器副本数量的变化。
你可以使用 kubectl 创建或更新 PDB 对象。
kubectl apply -f mypdb.yaml
使用 kubectl 来确认 PDB 被创建。
假设用户的名字空间下没有匹配 app: zookeeper 的 Pod,用户会看到类似下面的信息:
kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 0 7s
假设有匹配的 Pod(比如说 3 个),那么用户会看到类似下面的信息:
kubectl get poddisruptionbudgets
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
zk-pdb 2 N/A 1 7s
ALLOWED DISRUPTIONS 值非 0 意味着干扰控制器已经感知到相应的 Pod,对匹配的 Pod 进行统计,
并更新了 PDB 的状态。
用户可以通过以下命令获取更多 PDB 状态相关信息:
kubectl get poddisruptionbudgets zk-pdb -o yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
annotations:
…
creationTimestamp: "2020-03-04T04:22:56Z"
generation: 1
name: zk-pdb
…
status:
currentHealthy: 3
desiredHealthy: 2
disruptionsAllowed: 1
expectedPods: 3
observedGeneration: 1
如果 Pod 的 .status.conditions 中包含 type="Ready" 和 status="True" 的项,
则当前实现将其视为健康的 Pod。这些 Pod 通过 PDB 状态中的 .status.currentHealthy 字段被跟踪。
Kubernetes v1.26 [beta]
守护应用程序的 PodDisruptionBudget 通过不允许驱逐健康的 Pod 来确保 .status.currentHealthy 的 Pod
数量不低于 .status.desiredHealthy 中指定的数量。通过使用 .spec.unhealthyPodEvictionPolicy,
你还可以定义条件来判定何时应考虑驱逐不健康的 Pod。未指定策略时的默认行为对应于 IfHealthyBudget 策略。
策略包含:
IfHealthyBudget.status.phase="Running"),只有所守护的应用程序不受干扰
(.status.currentHealthy 至少等于 .status.desiredHealthy)时才能被驱逐。此策略确保已受干扰的应用程序所运行的 Pod 会尽可能成为健康。
这对腾空节点有负面影响,可能会因 PDB 守护的应用程序行为错误而阻止腾空。
更具体地说,这些应用程序的 Pod 处于 CrashLoopBackOff 状态
(由于漏洞或错误配置)或其 Pod 只是未能报告 Ready 状况。
AlwaysAllow.status.phase="Running")将被视为已受干扰且可以被驱逐,
与是否满足 PDB 中的判决条件无关。这意味着受干扰的应用程序所运行的 Pod 可能没有机会恢复健康。
通过使用此策略,集群管理器可以轻松驱逐由 PDB 所守护的行为错误的应用程序。
更具体地说,这些应用程序的 Pod 处于 CrashLoopBackOff 状态
(由于漏洞或错误配置)或其 Pod 只是未能报告 Ready 状况。
处于 Pending、Succeeded 或 Failed 阶段的 Pod 总是被考虑驱逐。
如果你只针对内置的工作负载资源(Deployment、ReplicaSet、StatefulSet 和 ReplicationController)
或在实现了 scale 子资源
的自定义资源使用 PDB,
并且 PDB 选择算符与 Pod 所属资源的选择算符完全匹配,那么可以跳过这一节。
你可以针对由其他资源、某个 "operator" 控制的或者“裸的(不受控制器控制)” Pod 使用 PDB,但存在以下限制:
.spec.minAvailable,而不能够使用 .spec.maxUnavailable。.spec.minAvailable 的值,而不能使用百分比。你无法使用其他的可用性配置,因为如果没有被支持的属主资源,Kubernetes 无法推导出 Pod 的总数。
你可以使用能够选择属于工作负载资源的 Pod 的子集或超集的选择算符。 驱逐 API 将不允许驱逐被多个 PDB 覆盖的任何 Pod,因此大多数用户都希望避免重叠的选择算符。 重叠 PDB 的一种合理用途是将 Pod 从一个 PDB 转交到另一个 PDB 的场合。
本指南演示了如何从 Pod 中访问 Kubernetes API。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
从 Pod 内部访问 API 时,定位 API 服务器和向服务器认证身份的操作与外部客户端场景不同。
从 Pod 使用 Kubernetes API 的最简单的方法就是使用官方的 客户端库。 这些库可以自动发现 API 服务器并进行身份验证。
从一个 Pod 内部连接到 Kubernetes API 的推荐方式为:
对于 Go 语言客户端,使用官方的 Go 客户端库。
函数 rest.InClusterConfig() 自动处理 API 主机发现和身份认证。
参见这里的一个例子。
对于 Python 客户端,使用官方的 Python 客户端库。
函数 config.load_incluster_config() 自动处理 API 主机的发现和身份认证。
参见这里的一个例子。
还有一些其他可用的客户端库,请参阅客户端库页面。
在以上场景中,客户端库都使用 Pod 的服务账号凭据来与 API 服务器安全地通信。
在运行在 Pod 中时,你的容器可以通过获取 KUBERNETES_SERVICE_HOST 和
KUBERNETES_SERVICE_PORT_HTTPS 环境变量为 Kubernetes API
服务器生成一个 HTTPS URL。
API 服务器的集群内地址也发布到 default 命名空间中名为 kubernetes 的 Service 中,
从而 Pod 可以引用 kubernetes.default.svc 作为本地 API 服务器的 DNS 名称。
Kubernetes 不保证 API 服务器具有主机名 kubernetes.default.svc 的有效证书;
但是,控制平面应该为 $KUBERNETES_SERVICE_HOST 代表的主机名或 IP 地址提供有效证书。
向 API 服务器进行身份认证的推荐做法是使用
服务账号凭据。
默认情况下,每个 Pod 与一个服务账号关联,该服务账号的凭据(令牌)放置在此 Pod
中每个容器的文件系统树中的 /var/run/secrets/kubernetes.io/serviceaccount/token 处。
如果证书包可用,则凭据包被放入每个容器的文件系统树中的
/var/run/secrets/kubernetes.io/serviceaccount/ca.crt 处,
且将被用于验证 API 服务器的服务证书。
最后,用于命名空间域 API 操作的默认命名空间放置在每个容器中的
/var/run/secrets/kubernetes.io/serviceaccount/namespace 文件中。
如果你希望不使用官方客户端库就完成 API 查询,可以将 kubectl proxy 作为
command
在 Pod 中启动一个边车(Sidecar)容器。这样,kubectl proxy 自动完成对 API
的身份认证,并将其暴露到 Pod 的 localhost 接口,从而 Pod
中的其他容器可以直接使用 API。
通过将认证令牌直接发送到 API 服务器,也可以避免运行 kubectl proxy 命令。 内部的证书机制能够为连接提供保护。
# 指向内部 API 服务器的主机名
APISERVER=https://kubernetes.default.svc
# 服务账号令牌的路径
SERVICEACCOUNT=/var/run/secrets/kubernetes.io/serviceaccount
# 读取 Pod 的名字空间
NAMESPACE=$(cat ${SERVICEACCOUNT}/namespace)
# 读取服务账号的持有者令牌
TOKEN=$(cat ${SERVICEACCOUNT}/token)
# 引用内部证书机构(CA)
CACERT=${SERVICEACCOUNT}/ca.crt
# 使用令牌访问 API
curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET ${APISERVER}/api
输出类似于:
{
"kind": "APIVersions",
"versions": ["v1"],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
本页演示如何使用 Kubernetes CronJob 对象运行自动化任务。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
CronJob 需要一个配置文件。 以下是针对一个 CronJob 的清单,该 CronJob 每分钟运行一个简单的演示任务:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
执行以下命令以运行此 CronJob 示例:
kubectl create -f https://k8s.io/examples/application/job/cronjob.yaml
输出类似于:
cronjob.batch/hello created
创建好 CronJob 后,使用下面的命令来获取其状态:
kubectl get cronjob hello
输出类似于:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 10s
就像你从命令返回结果看到的那样,CronJob 还没有调度或执行任何任务。大约需要一分钟任务才能创建好。
kubectl get jobs --watch
输出类似于:
NAME COMPLETIONS DURATION AGE
hello-4111706356 0/1 0s
hello-4111706356 0/1 0s 0s
hello-4111706356 1/1 5s 5s
现在你已经看到了一个运行中的任务被 “hello” CronJob 调度。 你可以停止监视这个任务,然后再次查看 CronJob 就能看到它调度任务:
kubectl get cronjob hello
输出类似于:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 50s 75s
你应该能看到 hello CronJob 在 LAST SCHEDULE 声明的时间点成功地调度了一次任务。
目前有 0 个活跃的任务,这意味着任务执行完毕或者执行失败。
现在,找到最后一次调度任务创建的 Pod 并查看一个 Pod 的标准输出。
# 在你的系统上将 "hello-4111706356" 替换为 Job 名称
pods=$(kubectl get pods --selector=job-name=hello-4111706356 --output=jsonpath={.items..metadata.name})
查看 Pod 日志:
kubectl logs $pods
输出类似于:
Fri Feb 22 11:02:09 UTC 2019
Hello from the Kubernetes cluster
当你不再需要 CronJob 时,可以用 kubectl delete cronjob <cronjob name> 删掉它:
kubectl delete cronjob hello
删除 CronJob 会清除它创建的所有任务和 Pod,并阻止它创建额外的任务。 你可以查阅垃圾收集。
本例中,你将会运行包含多个并行工作进程的 Kubernetes Job。
本例中,每个 Pod 一旦被创建,会立即从任务队列中取走一个工作单元并完成它,然后将工作单元从队列中删除后再退出。
下面是本次示例的主要步骤:
启动一个消息队列服务。 本例中,我们使用 RabbitMQ,你也可以用其他的消息队列服务。 在实际工作环境中,你可以创建一次消息队列服务然后在多个任务中重复使用。
创建一个队列,放上消息数据。 每个消息表示一个要执行的任务。本例中,每个消息是一个整数值。 我们将基于这个整数值执行很长的计算操作。
启动一个在队列中执行这些任务的 Job。 该 Job 启动多个 Pod。每个 Pod 从消息队列中取走一个任务,处理任务,然后退出。
你应当熟悉 Job 的基本用法(非并行的),请参考 Job。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你需要一个容器镜像仓库,用来向其中上传镜像以在集群中运行。
此任务示例还假设你已在本地安装了 Docker。
本例使用了 RabbitMQ,但你可以更改该示例,使用其他 AMQP 类型的消息服务。
在实际工作中,在集群中一次性部署某个消息队列服务,之后在很多 Job 中复用,包括需要长期运行的服务。
按下面的方法启动 RabbitMQ:
# 为 StatefulSet 创建一个 Service 来使用
kubectl create -f https://kubernetes.io/examples/application/job/rabbitmq/rabbitmq-service.yaml
service "rabbitmq-service" created
kubectl create -f https://kubernetes.io/examples/application/job/rabbitmq/rabbitmq-statefulset.yaml
statefulset "rabbitmq" created
现在,我们可以试着访问消息队列。我们将会创建一个临时的可交互的 Pod, 在它上面安装一些工具,然后用队列做实验。
首先创建一个临时的可交互的 Pod:
# 创建一个临时的可交互的 Pod
kubectl run -i --tty temp --image ubuntu:22.04
Waiting for pod default/temp-loe07 to be running, status is Pending, pod ready: false
... [ previous line repeats several times .. hit return when it stops ] ...
请注意你的 Pod 名称和命令提示符将会不同。
接下来安装 amqp-tools,这样你就能用消息队列了。
下面是在该 Pod 的交互式 shell 中需要运行的命令:
apt-get update && apt-get install -y curl ca-certificates amqp-tools python3 dnsutils
后续,你将制作一个包含这些包的容器镜像。
接着,你将要验证可以发现 RabbitMQ 服务:
# 在 Pod 内运行这些命令
# 请注意 rabbitmq-service 拥有一个由 Kubernetes 提供的 DNS 名称:
nslookup rabbitmq-service
Server: 10.0.0.10
Address: 10.0.0.10#53
Name: rabbitmq-service.default.svc.cluster.local
Address: 10.0.147.152
(IP 地址会有所不同)
如果 kube-dns 插件没有正确安装,上一步可能会出错。 你也可以在环境变量中找到该服务的 IP 地址。
# 在 Pod 内运行此检查
env | grep RABBITMQ_SERVICE | grep HOST
RABBITMQ_SERVICE_SERVICE_HOST=10.0.147.152
(IP 地址会有所不同)
接下来,你将验证是否可以创建队列以及发布和使用消息。
# 在 Pod 内运行这些命令
# 下一行,rabbitmq-service 是访问 rabbitmq-service 的主机名。5672是 rabbitmq 的标准端口。
export BROKER_URL=amqp://guest:guest@rabbitmq-service:5672
# 如果上一步中你不能解析 "rabbitmq-service",可以用下面的命令替换:
BROKER_URL=amqp://guest:guest@$RABBITMQ_SERVICE_SERVICE_HOST:5672
# 现在创建队列:
/usr/bin/amqp-declare-queue --url=$BROKER_URL -q foo -d foo
foo
向队列推送一条消息:
/usr/bin/amqp-publish --url=$BROKER_URL -r foo -p -b Hello
# 然后取回它:
/usr/bin/amqp-consume --url=$BROKER_URL -q foo -c 1 cat && echo
Hello
最后一个命令中,amqp-consume 工具从队列中取走了一个消息,并把该消息传递给了随机命令的标准输出。
在这种情况下,cat 会打印它从标准输入中读取的字符,echo 会添加回车符以便示例可读。
现在用一些模拟任务填充队列。在此示例中,任务是多个待打印的字符串。
实践中,消息的内容可以是:
如果有大量的数据需要被 Job 的所有 Pod 读取,典型的做法是把它们放在一个共享文件系统中, 如 NFS(Network File System 网络文件系统),并以只读的方式挂载到所有 Pod,或者 Pod 中的程序从类似 HDFS (Hadoop Distributed File System 分布式文件系统)的集群文件系统中读取。
例如,你将创建队列并使用 AMQP 命令行工具向队列中填充消息。实践中,你可以写个程序来利用 AMQP 客户端库来填充这些队列。
# 在你的计算机上运行此命令,而不是在 Pod 中
/usr/bin/amqp-declare-queue --url=$BROKER_URL -q job1 -d
job1
将这几项添加到队列中:
for f in apple banana cherry date fig grape lemon melon
do
/usr/bin/amqp-publish --url=$BROKER_URL -r job1 -p -b $f
done
你给队列中填充了 8 个消息。
现在你可以创建一个做为 Job 来运行的镜像。
这个 Job 将用 amqp-consume 实用程序从队列中读取消息并进行实际工作。
这里给出一个非常简单的示例程序:
#!/usr/bin/env python
# Just prints standard out and sleeps for 10 seconds.
import sys
import time
print("Processing " + sys.stdin.readlines()[0])
time.sleep(10)
赋予脚本执行权限:
chmod +x worker.py
现在,编译镜像。创建一个临时目录,切换到这个目录。下载 Dockerfile 和 worker.py。 无论哪种情况,都可以用下面的命令编译镜像:
docker build -t job-wq-1 .
对于 Docker Hub, 给你的应用镜像打上标签,
标签为你的用户名,然后用下面的命令推送到 Hub。用你的 Hub 用户名替换 <username>。
docker tag job-wq-1 <username>/job-wq-1
docker push <username>/job-wq-1
如果你使用替代的镜像仓库,请标记该镜像并将其推送到那里。
这里给出一个 Job 的清单。你需要复制一份 Job 清单的副本(将其命名为 ./job.yaml),
并编辑容器镜像的名称以匹配使用的名称。
apiVersion: batch/v1
kind: Job
metadata:
name: job-wq-1
spec:
completions: 8
parallelism: 2
template:
metadata:
name: job-wq-1
spec:
containers:
- name: c
image: gcr.io/<project>/job-wq-1
env:
- name: BROKER_URL
value: amqp://guest:guest@rabbitmq-service:5672
- name: QUEUE
value: job1
restartPolicy: OnFailure
本例中,每个 Pod 使用队列中的一个消息然后退出。
这样,Job 的完成计数就代表了完成的工作项的数量。
这就是示例清单将 .spec.completions 设置为 8 的原因。
运行 Job:
kubectl apply -f ./job.yaml
你可以等待 Job 在某个超时时间后成功:
# 状况名称的检查不区分大小写
kubectl wait --for=condition=complete --timeout=300s job/job-wq-1
接下来查看 Job:
kubectl describe jobs/job-wq-1
Name: job-wq-1
Namespace: default
Selector: controller-uid=41d75705-92df-11e7-b85e-fa163ee3c11f
Labels: controller-uid=41d75705-92df-11e7-b85e-fa163ee3c11f
job-name=job-wq-1
Annotations: <none>
Parallelism: 2
Completions: 8
Start Time: Wed, 06 Sep 2022 16:42:02 +0000
Pods Statuses: 0 Running / 8 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=41d75705-92df-11e7-b85e-fa163ee3c11f
job-name=job-wq-1
Containers:
c:
Image: container-registry.example/causal-jigsaw-637/job-wq-1
Port:
Environment:
BROKER_URL: amqp://guest:guest@rabbitmq-service:5672
QUEUE: job1
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
───────── ──────── ───── ──── ───────────── ────── ────── ───────
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-hcobb
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-weytj
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-qaam5
27s 27s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-b67sr
26s 26s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-xe5hj
15s 15s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-w2zqe
14s 14s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-d6ppa
14s 14s 1 {job } Normal SuccessfulCreate Created pod: job-wq-1-p17e0
该 Job 的所有 Pod 都已成功!你完成了。
本文所讲述的处理方法的好处是你不需要修改你的 "worker" 程序使其知道工作队列的存在。 你可以将未修改的工作程序包含在容器镜像中。
使用此方法需要你运行消息队列服务。如果不方便运行消息队列服务, 你也许会考虑另外一种任务模式。
本文所述的方法为每个工作项创建了一个 Pod。 如果你的工作项仅需数秒钟,为每个工作项创建 Pod 会增加很多的常规消耗。 考虑另一种设计,例如精细并行工作队列示例, 这种方案可以实现每个 Pod 执行多个工作项。
示例中,你使用了 amqp-consume 从消息队列读取消息并执行真正的程序。
这样的好处是你不需要修改你的程序使其知道队列的存在。
要了解怎样使用客户端库和工作队列通信,
请参考精细并行工作队列示例。
如果设置的完成数量小于队列中的消息数量,会导致一部分消息项不会被执行。
如果设置的完成数量大于队列中的消息数量,当队列中所有的消息都处理完成后, Job 也会显示为未完成。Job 将创建 Pod 并阻塞等待消息输入。 你需要建立自己的机制来发现何时有工作要做,并测量队列的大小,设置匹配的完成数量。
当发生下面两种情况时,即使队列中所有的消息都处理完了,Job 也不会显示为完成状态:
amqp-consume 命令拿到消息和容器成功退出之间的时间段内,执行杀死容器操作;在此例中,你将以索引完成模式运行一个 Job, 并通过配置使得该 Job 所创建的各 Pod 之间可以使用 Pod 主机名而不是 Pod IP 地址进行通信。
某 Job 内的 Pod 之间可能需要通信。每个 Pod 中运行的用户工作负载可以查询 Kubernetes API 服务器以获知其他 Pod 的 IP,但使用 Kubernetes 内置的 DNS 解析会更加简单。
索引完成模式下的 Job 自动将 Pod 的主机名设置为 ${jobName}-${completionIndex} 的格式。
你可以使用此格式确定性地构建 Pod 主机名并启用 Pod 通信,无需创建到 Kubernetes
控制平面的客户端连接来通过 API 请求获取 Pod 主机名/IP。
此配置可用于需要 Pod 联网但不想依赖 Kubernetes API 服务器网络连接的使用场景。
你应该已熟悉了 Job 的基本用法。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.21. 要获知版本信息,请输入kubectl version.
如果你正在使用 MiniKube 或类似的工具, 你可能需要采取额外的步骤来确保你拥有 DNS。
要在某 Job 中启用使用 Pod 主机名的 Pod 间通信,你必须执行以下操作:
对于 Job 所创建的那些 Pod,
使用一个有效的标签选择算符创建无头服务。
该无头服务必须位于与该 Job 相同的名字空间内。
实现这一目的的一种简单的方式是使用 job-name: <任务名称> 作为选择算符,
因为 job-name 标签将由 Kubernetes 自动添加。
此配置将触发 DNS 系统为运行 Job 的 Pod 创建其主机名的记录。
通过将以下值包括到你的 Job 模板规约中,针对该 Job 的 Pod,将无头服务配置为其子域服务:
subdomain: <无头服务的名称>
以下是启用通过 Pod 主机名来完成 Pod 间通信的 Job 示例。 只有在使用主机名成功 ping 通所有 Pod 之后,此 Job 才会结束。
在以下示例中的每个 Pod 中执行的 Bash 脚本中,如果需要从名字空间外到达 Pod, Pod 主机名也可以带有该名字空间作为前缀。
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None # clusterIP 必须为 None 以创建无头服务
selector:
job-name: example-job # 必须与 Job 名称匹配
---
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
completions: 3
parallelism: 3
completionMode: Indexed
template:
spec:
subdomain: headless-svc # 必须与 Service 名称匹配
restartPolicy: Never
containers:
- name: example-workload
image: bash:latest
command:
- bash
- -c
- |
for i in 0 1 2
do
gotStatus="-1"
wantStatus="0"
while [ $gotStatus -ne $wantStatus ]
do
ping -c 1 example-job-${i}.headless-svc > /dev/null 2>&1
gotStatus=$?
if [ $gotStatus -ne $wantStatus ]; then
echo "Failed to ping pod example-job-${i}.headless-svc, retrying in 1 second..."
sleep 1
fi
done
echo "Successfully pinged pod: example-job-${i}.headless-svc"
done
应用上述示例之后,使用 <Pod 主机名>.<无头服务名> 通过网络到达彼此。
你应看到类似以下的输出:
kubectl logs example-job-0-qws42
Failed to ping pod example-job-0.headless-svc, retrying in 1 second...
Successfully pinged pod: example-job-0.headless-svc
Successfully pinged pod: example-job-1.headless-svc
Successfully pinged pod: example-job-2.headless-svc
谨记此例中使用的 <Pod 主机名>.<无头服务名称> 名称格式不适用于设置为 None 或 Default 的 DNS 策略。
你可以在此处了解有关
Pod DNS 策略的更多信息。
在此示例中,你将运行一个 Kubernetes Job,该 Job 将多个并行任务作为工作进程运行, 每个任务在单独的 Pod 中运行。
在这个例子中,当每个 Pod 被创建时,它会从一个任务队列中获取一个工作单元,处理它,然后重复,直到到达队列的尾部。
下面是这个示例的步骤概述:
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你将需要一个容器镜像仓库,可以向其中上传镜像以在集群中运行。 此示例使用的是 Docker Hub, 当然你可以将其调整为别的容器镜像仓库。
此任务示例还假设你已在本地安装了 Docker,并使用 Docker 来构建容器镜像。
熟悉基本的、非并行的 Job。
对于这个例子,为了简单起见,你将启动一个单实例的 Redis。 了解如何部署一个可伸缩、高可用的 Redis 例子,请查看 Redis 示例
你也可以直接下载如下文件:
要启动一个 Redis 实例,你需要创建 Redis Pod 和 Redis 服务:
kubectl apply -f https://k8s.io/examples/application/job/redis/redis-pod.yaml
kubectl apply -f https://k8s.io/examples/application/job/redis/redis-service.yaml
现在,让我们往队列里添加一些“任务”。在这个例子中,我们的任务是一些将被打印出来的字符串。
启动一个临时的可交互的 Pod 用于运行 Redis 命令行界面。
kubectl run -i --tty temp --image redis --command "/bin/sh"
输出类似于:
Waiting for pod default/redis2-c7h78 to be running, status is Pending, pod ready: false
Hit enter for command prompt
现在按回车键,启动 Redis 命令行界面,然后创建一个存在若干个工作项的列表。
redis-cli -h redis
redis:6379> rpush job2 "apple"
(integer) 1
redis:6379> rpush job2 "banana"
(integer) 2
redis:6379> rpush job2 "cherry"
(integer) 3
redis:6379> rpush job2 "date"
(integer) 4
redis:6379> rpush job2 "fig"
(integer) 5
redis:6379> rpush job2 "grape"
(integer) 6
redis:6379> rpush job2 "lemon"
(integer) 7
redis:6379> rpush job2 "melon"
(integer) 8
redis:6379> rpush job2 "orange"
(integer) 9
redis:6379> lrange job2 0 -1
1) "apple"
2) "banana"
3) "cherry"
4) "date"
5) "fig"
6) "grape"
7) "lemon"
8) "melon"
9) "orange"
因此,这个键为 job2 的列表就是工作队列。
注意:如果你还没有正确地配置 Kube DNS,你可能需要将上面的第一步改为
redis-cli -h $REDIS_SERVICE_HOST。
现在你已准备好创建一个镜像来处理该队列中的工作。
你将使用一个带有 Redis 客户端的 Python 工作程序从消息队列中读出消息。
这里提供了一个简单的 Redis 工作队列客户端库,名为 rediswq.py
(下载)。
Job 中每个 Pod 内的“工作程序” 使用工作队列客户端库获取工作。具体如下:
#!/usr/bin/env python
import time
import rediswq
host="redis"
# 如果你未在运行 Kube-DNS,请取消下面两行的注释
# import os
# host = os.getenv("REDIS_SERVICE_HOST")
q = rediswq.RedisWQ(name="job2", host=host)
print("Worker with sessionID: " + q.sessionID())
print("Initial queue state: empty=" + str(q.empty()))
while not q.empty():
item = q.lease(lease_secs=10, block=True, timeout=2)
if item is not None:
itemstr = item.decode("utf-8")
print("Working on " + itemstr)
time.sleep(10) # 将你的实际工作放在此处来取代 sleep
q.complete(item)
else:
print("Waiting for work")
print("Queue empty, exiting")
你也可以下载 worker.py、
rediswq.py 和
Dockerfile 文件。然后构建容器镜像。
以下是使用 Docker 进行镜像构建的示例:
docker build -t job-wq-2 .
对于 Docker Hub,请先用你的用户名给镜像打上标签,
然后使用下面的命令 push 你的镜像到仓库。请将 <username> 替换为你自己的 Hub 用户名。
docker tag job-wq-2 <username>/job-wq-2
docker push <username>/job-wq-2
你需要将镜像 push 到一个公共仓库或者 配置集群访问你的私有仓库。
以下是你将创建的 Job 的清单:
apiVersion: batch/v1
kind: Job
metadata:
name: job-wq-2
spec:
parallelism: 2
template:
metadata:
name: job-wq-2
spec:
containers:
- name: c
image: gcr.io/myproject/job-wq-2
restartPolicy: OnFailure
请确保将 Job 清单中的 gcr.io/myproject 更改为你自己的路径。
在这个例子中,每个 Pod 处理了队列中的多个项目,直到队列中没有项目时便退出。 因为是由工作程序自行检测工作队列是否为空,并且 Job 控制器不知道工作队列的存在, 这依赖于工作程序在完成工作时发出信号。 工作程序以成功退出的形式发出信号表示工作队列已经为空。 所以,只要有任意一个工作程序成功退出,控制器就知道工作已经完成了,所有的 Pod 将很快会退出。 因此,你不需要设置 Job 的完成次数。Job 控制器还是会等待其它 Pod 完成。
现在运行这个 Job:
# 这假设你已经下载并编辑了清单
kubectl apply -f ./job.yaml
稍等片刻,然后检查这个 Job:
kubectl describe jobs/job-wq-2
Name: job-wq-2
Namespace: default
Selector: controller-uid=b1c7e4e3-92e1-11e7-b85e-fa163ee3c11f
Labels: controller-uid=b1c7e4e3-92e1-11e7-b85e-fa163ee3c11f
job-name=job-wq-2
Annotations: <none>
Parallelism: 2
Completions: <unset>
Start Time: Mon, 11 Jan 2022 17:07:59 +0000
Pods Statuses: 1 Running / 0 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=b1c7e4e3-92e1-11e7-b85e-fa163ee3c11f
job-name=job-wq-2
Containers:
c:
Image: container-registry.example/exampleproject/job-wq-2
Port:
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
33s 33s 1 {job-controller } Normal SuccessfulCreate Created pod: job-wq-2-lglf8
你可以等待 Job 成功,等待时长有超时限制:
# 状况名称的检查不区分大小写
kubectl wait --for=condition=complete --timeout=300s job/job-wq-2
kubectl logs pods/job-wq-2-7r7b2
Worker with sessionID: bbd72d0a-9e5c-4dd6-abf6-416cc267991f
Initial queue state: empty=False
Working on banana
Working on date
Working on lemon
你可以看到,此 Job 中的一个 Pod 处理了若干个工作单元。
如果你不方便运行一个队列服务或者修改你的容器用于运行一个工作队列,你可以考虑其它的 Job 模式。
如果你有持续的后台处理业务,那么可以考虑使用 ReplicaSet 来运行你的后台业务, 和运行一个类似 https://github.com/resque/resque 的后台处理库。
Kubernetes v1.24 [stable]
在此示例中,你将运行一个使用多个并行工作进程的 Kubernetes Job。 每个 worker 都是在自己的 Pod 中运行的不同容器。 Pod 具有控制平面自动设置的索引编号(index number), 这些编号使得每个 Pod 能识别出要处理整个任务的哪个部分。
Pod 索引在注解
batch.kubernetes.io/job-completion-index 中呈现,具体表示为一个十进制值字符串。
为了让容器化的任务进程获得此索引,你可以使用
downward API
机制发布注解的值。为方便起见,
控制平面自动设置 Downward API 以在 JOB_COMPLETION_INDEX 环境变量中公开索引。
以下是此示例中步骤的概述:
Indexed)的 Job。你应该已经熟悉 Job 的基本的、非并行的用法。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.21. 要获知版本信息,请输入kubectl version.
要从工作程序访问工作项,你有几个选项:
JOB_COMPLETION_INDEX 环境变量。Job
控制器自动将此变量链接到包含完成索引的注解。对于此示例,假设你选择了选项 3 并且想要运行 rev 实用程序。 这个程序接受一个文件作为参数并按逆序打印其内容。
rev data.txt
你将使用 busybox 容器镜像中的 rev 工具。
由于这只是一个例子,每个 Pod 只做一小部分工作(反转一个短字符串)。 例如,在实际工作负载中,你可能会创建一个表示基于场景数据制作 60 秒视频任务的 Job 。 此视频渲染 Job 中的每个工作项都将渲染该视频剪辑的特定帧。 索引完成意味着 Job 中的每个 Pod 都知道通过从剪辑开始计算帧数,来确定渲染和发布哪一帧。
这是一个使用 Indexed 完成模式的示例 Job 清单:
apiVersion: batch/v1
kind: Job
metadata:
name: 'indexed-job'
spec:
completions: 5
parallelism: 3
completionMode: Indexed
template:
spec:
restartPolicy: Never
initContainers:
- name: 'input'
image: 'docker.io/library/bash'
command:
- "bash"
- "-c"
- |
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
volumeMounts:
- mountPath: /input
name: input
containers:
- name: 'worker'
image: 'docker.io/library/busybox'
command:
- "rev"
- "/input/data.txt"
volumeMounts:
- mountPath: /input
name: input
volumes:
- name: input
emptyDir: {}
在上面的示例中,你使用 Job 控制器为所有容器设置的内置 JOB_COMPLETION_INDEX 环境变量。
Init 容器
将索引映射到一个静态值,并将其写入一个文件,该文件通过
emptyDir 卷
与运行 worker 的容器共享。或者,你可以
通过 Downward API 定义自己的环境变量
将索引发布到容器。你还可以选择从
包含 ConfigMap 的环境变量或文件
加载值列表。
或者也可以直接 使用 Downward API 将注解值作为卷文件传递, 如下例所示:
apiVersion: batch/v1
kind: Job
metadata:
name: 'indexed-job'
spec:
completions: 5
parallelism: 3
completionMode: Indexed
template:
spec:
restartPolicy: Never
containers:
- name: 'worker'
image: 'docker.io/library/busybox'
command:
- "rev"
- "/input/data.txt"
volumeMounts:
- mountPath: /input
name: input
volumes:
- name: input
downwardAPI:
items:
- path: "data.txt"
fieldRef:
fieldPath: metadata.annotations['batch.kubernetes.io/job-completion-index']现在执行 Job:
# 使用第一种方法(依赖于 $JOB_COMPLETION_INDEX)
kubectl apply -f https://kubernetes.io/examples/application/job/indexed-job.yaml
当你创建此 Job 时,控制平面会创建一系列 Pod,你指定的每个索引都会运行一个 Pod。
.spec.parallelism 的值决定了一次可以运行多少个 Pod,
而 .spec.completions 决定了 Job 总共创建了多少个 Pod。
因为 .spec.parallelism 小于 .spec.completions,
所以控制平面在启动更多 Pod 之前,将等待第一批的某些 Pod 完成。
你可以等待 Job 成功,等待时间可以设置超时限制:
# 状况名称的检查不区分大小写
kubectl wait --for=condition=complete --timeout=300s job/indexed-job
现在,描述 Job 并检查它是否成功。
kubectl describe jobs/indexed-job
输出类似于:
Name: indexed-job
Namespace: default
Selector: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Annotations: <none>
Parallelism: 3
Completions: 5
Start Time: Thu, 11 Mar 2021 15:47:34 +0000
Pods Statuses: 2 Running / 3 Succeeded / 0 Failed
Completed Indexes: 0-2
Pod Template:
Labels: controller-uid=bf865e04-0b67-483b-9a90-74cfc4c3e756
job-name=indexed-job
Init Containers:
input:
Image: docker.io/library/bash
Port: <none>
Host Port: <none>
Command:
bash
-c
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Containers:
worker:
Image: docker.io/library/busybox
Port: <none>
Host Port: <none>
Command:
rev
/input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Volumes:
input:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-njkjj
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-9kd4h
Normal SuccessfulCreate 4s job-controller Created pod: indexed-job-qjwsz
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-fdhq5
Normal SuccessfulCreate 1s job-controller Created pod: indexed-job-ncslj
在此示例中,你使用每个索引的自定义值运行 Job。 你可以检查其中一个 Pod 的输出:
kubectl logs indexed-job-fdhq5 # 更改它以匹配来自该 Job 的 Pod 的名称
输出类似于:
xuq
本任务展示基于一个公共的模板运行多个Jobs。 你可以用这种方法来并行执行批处理任务。
在本任务示例中,只有三个工作条目:apple、banana 和 cherry。 示例任务处理每个条目时打印一个字符串之后结束。
参考在真实负载中使用 Job了解更适用于真实使用场景的模式。
你应先熟悉基本的、非并行的 Job 的用法。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
任务中的基本模板示例要求安装命令行工具 sed。
要使用较高级的模板示例,你需要安装 Python,
并且要安装 Jinja2 模板库。
一旦 Python 已经安装好,你可以运行下面的命令安装 Jinja2:
pip install --user jinja2
首先,将以下作业模板下载到名为 job-tmpl.yaml 的文件中。
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox:1.28
command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
# 使用 curl 下载 job-tmpl.yaml
curl -L -s -O https://k8s.io/examples/application/job/job-tmpl.yaml
你所下载的文件不是一个合法的 Kubernetes 清单。
这里的模板只是 Job 对象的 yaml 表示,其中包含一些占位符,在使用它之前需要被填充。
$ITEM 语法对 Kubernetes 没有意义。
下面的 Shell 代码片段使用 sed 将字符串 $ITEM 替换为循环变量,
并将结果写入到一个名为 jobs 的临时目录。
# 展开模板文件到多个文件中,每个文件对应一个要处理的条目
mkdir ./jobs
for i in apple banana cherry
do
cat job-tmpl.yaml | sed "s/\$ITEM/$i/" > ./jobs/job-$i.yaml
done
检查上述脚本的输出:
ls jobs/
输出类似于:
job-apple.yaml
job-banana.yaml
job-cherry.yaml
你可以使用任何一种模板语言(例如:Jinja2、ERB),或者编写一个程序来 生成 Job 清单。
接下来用一个 kubectl 命令创建所有的 Job:
kubectl create -f ./jobs
输出类似于:
job.batch/process-item-apple created
job.batch/process-item-banana created
job.batch/process-item-cherry created
现在检查 Job:
kubectl get jobs -l jobgroup=jobexample
输出类似于:
NAME COMPLETIONS DURATION AGE
process-item-apple 1/1 14s 22s
process-item-banana 1/1 12s 21s
process-item-cherry 1/1 12s 20s
使用 kubectl 的 -l 选项可以仅选择属于当前 Job 组的对象
(系统中可能存在其他不相关的 Job)。
你可以使用相同的 标签选择算符 来过滤 Pods:
kubectl get pods -l jobgroup=jobexample
输出类似于:
NAME READY STATUS RESTARTS AGE
process-item-apple-kixwv 0/1 Completed 0 4m
process-item-banana-wrsf7 0/1 Completed 0 4m
process-item-cherry-dnfu9 0/1 Completed 0 4m
我们可以用下面的命令查看所有 Job 的输出:
kubectl logs -f -l jobgroup=jobexample
输出类似于:
Processing item apple
Processing item banana
Processing item cherry
# 删除所创建的 Job
# 集群会自动清理 Job 对应的 Pod
kubectl delete job -l jobgroup=jobexample
在第一个例子中,模板的每个示例都有一个参数 而该参数也用在 Job 名称中。不过,对象 名称 被限制只能使用某些字符。
这里的略微复杂的例子使用 Jinja 模板语言 来生成清单,并基于清单来生成对象,每个 Job 都有多个参数。
在本任务中,你将会使用一个一行的 Python 脚本,将模板转换为一组清单文件。
首先,复制下面的 Job 对象模板到一个名为 job.yaml.jinja2 的文件。
{% set params = [{ "name": "apple", "url": "http://dbpedia.org/resource/Apple", },
{ "name": "banana", "url": "http://dbpedia.org/resource/Banana", },
{ "name": "cherry", "url": "http://dbpedia.org/resource/Cherry" }]
%}
{% for p in params %}
{% set name = p["name"] %}
{% set url = p["url"] %}
---
apiVersion: batch/v1
kind: Job
metadata:
name: jobexample-{{ name }}
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox:1.28
command: ["sh", "-c", "echo Processing URL {{ url }} && sleep 5"]
restartPolicy: Never
{% endfor %}
上面的模板使用 python 字典列表(第 1-4 行)定义每个作业对象的参数。
然后使用 for 循环为每组参数(剩余行)生成一个作业 yaml 对象。
我们利用了多个 YAML 文档(这里的 Kubernetes 清单)可以用 --- 分隔符连接的事实。
我们可以将输出直接传递给 kubectl 来创建对象。
接下来我们用单行的 Python 程序将模板展开。
alias render_template='python -c "from jinja2 import Template; import sys; print(Template(sys.stdin.read()).render());"'
使用 render_template 将参数和模板转换成一个 YAML 文件,其中包含 Kubernetes
资源清单:
# 此命令需要之前定义的别名
cat job.yaml.jinja2 | render_template > jobs.yaml
你可以查看 jobs.yaml 以验证 render_template 脚本是否正常工作。
当你对输出结果比较满意时,可以用管道将其输出发送给 kubectl,如下所示:
cat job.yaml.jinja2 | render_template | kubectl apply -f -
Kubernetes 接收清单文件并执行你所创建的 Job。
# 删除所创建的 Job
# 集群会自动清理 Job 对应的 Pod
kubectl delete job -l jobgroup=jobexample
在真实的负载中,每个 Job 都会执行一些重要的计算,例如渲染电影的一帧,
或者处理数据库中的若干行。这时,$ITEM 参数将指定帧号或行范围。
在此任务中,你运行一个命令通过取回 Pod 的日志来收集其输出。 在真实应用场景中,Job 的每个 Pod 都会在结束之前将其输出写入到某持久性存储中。 你可以为每个 Job 指定 PersistentVolume 卷,或者使用其他外部存储服务。 例如,如果你在渲染视频帧,你可能会使用 HTTP 协议将渲染完的帧数据 用 'PUT' 请求发送到某 URL,每个帧使用不同的 URl。
你创建了 Job 之后,Kubernetes 自动为 Job 的 Pod 添加 标签,以便能够将一个 Job 的 Pod 与另一个 Job 的 Pod 区分开来。
在本例中,每个 Job 及其 Pod 模板有一个标签:jobgroup=jobexample。
Kubernetes 自身对标签名 jobgroup 没有什么要求。
为创建自同一模板的所有 Job 使用同一标签使得我们可以方便地同时操作组中的所有作业。
在第一个例子中,你使用模板来创建了若干 Job。
模板确保每个 Pod 都能够获得相同的标签,这样你可以用一条命令检查这些模板化
Job 所生成的全部 Pod。
jobgroup 没什么特殊的,也不是保留字。 你可以选择你自己的标签方案。
如果愿意,有一些建议的标签
可供使用。
如果你有计划创建大量 Job 对象,你可能会发现:
还有一些其他作业模式 可供选择,这些模式都能用来处理大量任务而又不会创建过多的 Job 对象。
你也可以考虑编写自己的控制器 来自动管理 Job 对象。
Kubernetes v1.26 [beta]
本文向你展示如何结合默认的 Pod 回退失效策略来使用 Pod 失效策略, 以改善 Job 内处理容器级别或 Pod 级别的失效。
Pod 失效策略的定义可以帮助你:
你应该已熟悉了 Job 的基本用法。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.25. 要获知版本信息,请输入kubectl version.
确保特性门控
PodDisruptionConditions 和 JobPodFailurePolicy 在你的集群中均已启用。
借用以下示例,你可以学习在 Pod 失效表明有一个不可重试的软件漏洞时如何使用 Pod 失效策略来避免不必要的 Pod 重启。
首先,基于配置创建一个 Job:
apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-failjob
spec:
completions: 8
parallelism: 2
template:
spec:
restartPolicy: Never
containers:
- name: main
image: docker.io/library/bash:5
command: ["bash"]
args:
- -c
- echo "Hello world! I'm going to exit with 42 to simulate a software bug." && sleep 30 && exit 42
backoffLimit: 6
podFailurePolicy:
rules:
- action: FailJob
onExitCodes:
containerName: main
operator: In
values: [42]
运行以下命令:
kubectl create -f job-pod-failure-policy-failjob.yaml
大约 30 秒后,整个 Job 应被终止。通过运行以下命令来查看 Job 的状态:
kubectl get jobs -l job-name=job-pod-failure-policy-failjob -o yaml
在 Job 状态中,看到一个任务状况为 Failed,其 reason 字段等于 PodFailurePolicy。
此外,message 字段包含有关 Job 终止更详细的信息,例如:
Container main for pod default/job-pod-failure-policy-failjob-8ckj8 failed with exit code 42 matching FailJob rule at index 0。
为了比较,如果 Pod 失效策略被禁用,将会让 Pod 重试 6 次,用时至少 2 分钟。
删除你创建的 Job:
kubectl delete jobs/job-pod-failure-policy-failjob
集群自动清理这些 Pod。
通过以下示例,你可以学习如何使用 Pod 失效策略将 Pod 重试计数器朝着 .spec.backoffLimit 限制递增来忽略 Pod 干扰。
这个示例的时机比较重要,因此你可能需要在执行之前阅读这些步骤。 为了触发 Pod 干扰,重要的是在 Pod 在其上运行时(自 Pod 调度后的 90 秒内)腾空节点。
基于配置创建 Job:
apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-ignore
spec:
completions: 4
parallelism: 2
template:
spec:
restartPolicy: Never
containers:
- name: main
image: docker.io/library/bash:5
command: ["bash"]
args:
- -c
- echo "Hello world! I'm going to exit with 0 (success)." && sleep 90 && exit 0
backoffLimit: 0
podFailurePolicy:
rules:
- action: Ignore
onPodConditions:
- type: DisruptionTarget
运行以下命令:
kubectl create -f job-pod-failure-policy-ignore.yaml
运行以下这条命令检查将 Pod 调度到的 nodeName:
nodeName=$(kubectl get pods -l job-name=job-pod-failure-policy-ignore -o jsonpath='{.items[0].spec.nodeName}')
腾空该节点以便在 Pod 完成任务之前将其驱逐(90 秒内):
kubectl drain nodes/$nodeName --ignore-daemonsets --grace-period=0
查看 .status.failed 以检查针对 Job 的计数器未递增:
kubectl get jobs -l job-name=job-pod-failure-policy-ignore -o yaml
解除节点的保护:
kubectl uncordon nodes/$nodeName
Job 恢复并成功完成。
为了比较,如果 Pod 失效策略被禁用,Pod 干扰将使得整个 Job 终止(随着 .spec.backoffLimit 设置为 0)。
删除你创建的 Job:
kubectl delete jobs/job-pod-failure-policy-ignore
集群自动清理 Pod。
根据以下示例,你可以学习如何基于自定义 Pod 状况使用 Pod 失效策略避免不必要的 Pod 重启。
以下示例自 v1.27 起开始生效,因为它依赖于将已删除的 Pod 从 Pending 阶段过渡到终止阶段
(参阅 Pod 阶段)。
首先基于配置创建一个 Job:
apiVersion: batch/v1
kind: Job
metadata:
name: job-pod-failure-policy-config-issue
spec:
completions: 8
parallelism: 2
template:
spec:
restartPolicy: Never
containers:
- name: main
image: "non-existing-repo/non-existing-image:example"
backoffLimit: 6
podFailurePolicy:
rules:
- action: FailJob
onPodConditions:
- type: ConfigIssue
执行以下命令:
kubectl create -f job-pod-failure-policy-config-issue.yaml
请注意,镜像配置不正确,因为该镜像不存在。
通过执行以下命令检查任务 Pod 的状态:
kubectl get pods -l job-name=job-pod-failure-policy-config-issue -o yaml
你将看到类似以下输出:
containerStatuses:
- image: non-existing-repo/non-existing-image:example
...
state:
waiting:
message: Back-off pulling image "non-existing-repo/non-existing-image:example"
reason: ImagePullBackOff
...
phase: Pending
请注意,Pod 依然处于 Pending 阶段,因为它无法拉取错误配置的镜像。
原则上讲这可能是一个暂时问题,镜像还是会被拉取。然而这种情况下,
镜像不存在,因为我们通过一个自定义状况表明了这个事实。
添加自定义状况。执行以下命令先准备补丁:
cat <<EOF > patch.yaml
status:
conditions:
- type: ConfigIssue
status: "True"
reason: "NonExistingImage"
lastTransitionTime: "$(date -u +"%Y-%m-%dT%H:%M:%SZ")"
EOF
其次,执行以下命令选择通过任务创建的其中一个 Pod:
podName=$(kubectl get pods -l job-name=job-pod-failure-policy-config-issue -o jsonpath='{.items[0].metadata.name}')
随后执行以下命令将补丁应用到其中一个 Pod 上:
kubectl patch pod $podName --subresource=status --patch-file=patch.yaml
如果被成功应用,你将看到类似以下的一条通知:
pod/job-pod-failure-policy-config-issue-k6pvp patched
执行以下命令删除此 Pod 将其过渡到 Failed 阶段:
kubectl delete pods/$podName
执行以下命令查验 Job 的状态:
kubectl get jobs -l job-name=job-pod-failure-policy-config-issue -o yaml
在 Job 状态中,看到任务 Failed 状况的 reason 字段等于 PodFailurePolicy。
此外,message 字段包含了与 Job 终止相关的更多详细信息,例如:
Pod default/job-pod-failure-policy-config-issue-k6pvp has condition ConfigIssue matching FailJob rule at index 0。
在生产环境中,第 3 和 4 步应由用户提供的控制器进行自动化处理。
删除你创建的 Job:
kubectl delete jobs/job-pod-failure-policy-config-issue
集群自动清理 Pod。
通过指定 Job 的 .spec.backoffLimit 字段,你可以完全依赖
Pod 回退失效策略。
然而在许多情况下,难题在于如何找到一个平衡,为 .spec.backoffLimit 设置一个较小的值以避免不必要的 Pod 重试,
同时这个值又足以确保 Job 不会因 Pod 干扰而终止。
Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。 你可以使用 Dashboard 获取运行在集群中的应用的概览信息,也可以创建或者修改 Kubernetes 资源 (如 Deployment,Job,DaemonSet 等等)。 例如,你可以对 Deployment 实现弹性伸缩、发起滚动升级、重启 Pod 或者使用向导创建新的应用。
Dashboard 同时展示了 Kubernetes 集群中的资源状态信息和所有报错信息。
默认情况下不会部署 Dashboard。可以通过以下命令部署:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
为了保护你的集群数据,默认情况下,Dashboard 会使用最少的 RBAC 配置进行部署。 当前,Dashboard 仅支持使用 Bearer 令牌登录。 要为此样本演示创建令牌,你可以按照 创建示例用户 上的指南进行操作。
在教程中创建的样本用户将具有管理特权,并且仅用于教育目的。
你可以使用 kubectl 命令行工具来启用 Dashboard 访问,命令如下:
kubectl proxy
kubectl 会使得 Dashboard 可以通过 http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/ 访问。
UI 只能 通过执行这条命令的机器进行访问。更多选项参见 kubectl proxy --help。
Kubeconfig 身份验证方法不支持外部身份提供程序或基于 x509 证书的身份验证。
当访问空集群的 Dashboard 时,你会看到欢迎界面。
页面包含一个指向此文档的链接,以及一个用于部署第一个应用程序的按钮。
此外,你可以看到在默认情况下有哪些默认系统应用运行在 kube-system
名字空间 中,比如 Dashboard 自己。
通过一个简单的部署向导,你可以使用 Dashboard 将容器化应用作为一个 Deployment 和可选的 Service 进行创建和部署。你可以手工指定应用的详细配置,或者上传一个包含应用配置的 YAML 或 JSON _清单_文件。
点击任何页面右上角的 CREATE 按钮以开始。
部署向导需要你提供以下信息:
应用名称(必填):应用的名称。内容为 应用名称 的
标签
会被添加到任何将被部署的 Deployment 和 Service。
在选定的 Kubernetes 名字空间 中, 应用名称必须唯一。必须由小写字母开头,以数字或者小写字母结尾, 并且只含有小写字母、数字和中划线(-)。小于等于24个字符。开头和结尾的空格会被忽略。
Pod 的数量(必填):你希望应用程序部署的 Pod 的数量。值必须为正整数。
系统会创建一个 Deployment 以保证集群中运行期望的 Pod 数量。
服务(可选):对于部分应用(比如前端),你可能想对外暴露一个 Service,这个 Service 可能用的是集群之外的公网 IP 地址(外部 Service)。
对于外部服务,你可能需要开放一个或多个端口才行。
其它只能对集群内部可见的 Service 称为内部 Service。
不管哪种 Service 类型,如果你选择创建一个 Service,而且容器在一个端口上开启了监听(入向的), 那么你需要定义两个端口。创建的 Service 会把(入向的)端口映射到容器可见的目标端口。 该 Service 会把流量路由到你部署的 Pod。支持 TCP 协议和 UDP 协议。 这个 Service 的内部 DNS 解析名就是之前你定义的应用名称的值。
如果需要,你可以打开 Advanced Options 部分,这里你可以定义更多设置:
标签:应用默认使用的 标签 是应用名称和版本。 你可以为 Deployment、Service(如果有)定义额外的标签,比如 release(版本)、 environment(环境)、tier(层级)、partition(分区) 和 release track(版本跟踪)。
例子:
release=1.0
tier=frontend
environment=pod
track=stable
名字空间:Kubernetes 支持多个虚拟集群依附于同一个物理集群。 这些虚拟集群被称为 名字空间, 可以让你将资源划分为逻辑命名的组。
Dashboard 通过下拉菜单提供所有可用的名字空间,并允许你创建新的名字空间。 名字空间的名称最长可以包含 63 个字母或数字和中横线(-),但是不能包含大写字母。
名字空间的名称不能只包含数字。如果名字被设置成一个数字,比如 10,pod 就
在名字空间创建成功的情况下,默认会使用新创建的名字空间。如果创建失败,那么第一个名字空间会被选中。
镜像拉取 Secret:如果要使用私有的 Docker 容器镜像,需要拉取 Secret 凭证。
Dashboard 通过下拉菜单提供所有可用的 Secret,并允许你创建新的 Secret。
Secret 名称必须遵循 DNS 域名语法,比如 new.image-pull.secret。
Secret 的内容必须是 base64 编码的,并且在一个
.dockercfg
文件中声明。Secret 名称最大可以包含 253 个字符。
在镜像拉取 Secret 创建成功的情况下,默认会使用新创建的 Secret。 如果创建失败,则不会使用任何 Secret。
$(VAR_NAME) 语法关联其他变量。Kubernetes 支持声明式配置。所有的配置都存储在清单文件 (YAML 或者 JSON 配置文件)中。这些 清单使用 Kubernetes API 定义的资源模式。
作为一种替代在部署向导中指定应用详情的方式,你可以在一个或多个清单文件中定义应用,并且使用 Dashboard 上传文件。
以下各节描述了 Kubernetes Dashboard UI 视图;包括它们提供的内容,以及怎么使用它们。
当在集群中定义 Kubernetes 对象时,Dashboard 会在初始视图中显示它们。 默认情况下只会显示 默认 名字空间中的对象,可以通过更改导航栏菜单中的名字空间筛选器进行改变。
Dashboard 展示大部分 Kubernetes 对象,并将它们分组放在几个菜单类别中。
集群和名字空间管理的视图,Dashboard 会列出节点、名字空间和持久卷,并且有它们的详细视图。 节点列表视图包含从所有节点聚合的 CPU 和内存使用的度量值。 详细信息视图显示了一个节点的度量值,它的规格、状态、分配的资源、事件和这个节点上运行的 Pod。
显示选中的名字空间中所有运行的应用。 视图按照负载类型(例如:Deployment、ReplicaSet、StatefulSet)罗列应用,并且每种负载都可以单独查看。 列表总结了关于负载的可执行信息,比如一个 ReplicaSet 的就绪状态的 Pod 数量,或者目前一个 Pod 的内存用量。
工作负载的详情视图展示了对象的状态、详细信息和相互关系。 例如,ReplicaSet 所控制的 Pod,或者 Deployment 所关联的新 ReplicaSet 和 HorizontalPodAutoscalers。
展示允许暴露给外网服务和允许集群内部发现的 Kubernetes 资源。 因此,Service 和 Ingress 视图展示他们关联的 Pod、给集群连接使用的内部端点和给外部用户使用的外部端点。
存储视图展示持久卷申领(PVC)资源,这些资源被应用程序用来存储数据。
展示的所有 Kubernetes 资源是在集群中运行的应用程序的实时配置。 通过这个视图可以编辑和管理配置对象,并显示那些默认隐藏的 Secret。
Pod 列表和详细信息页面可以链接到 Dashboard 内置的日志查看器。 查看器可以深入查看属于同一个 Pod 的不同容器的日志。
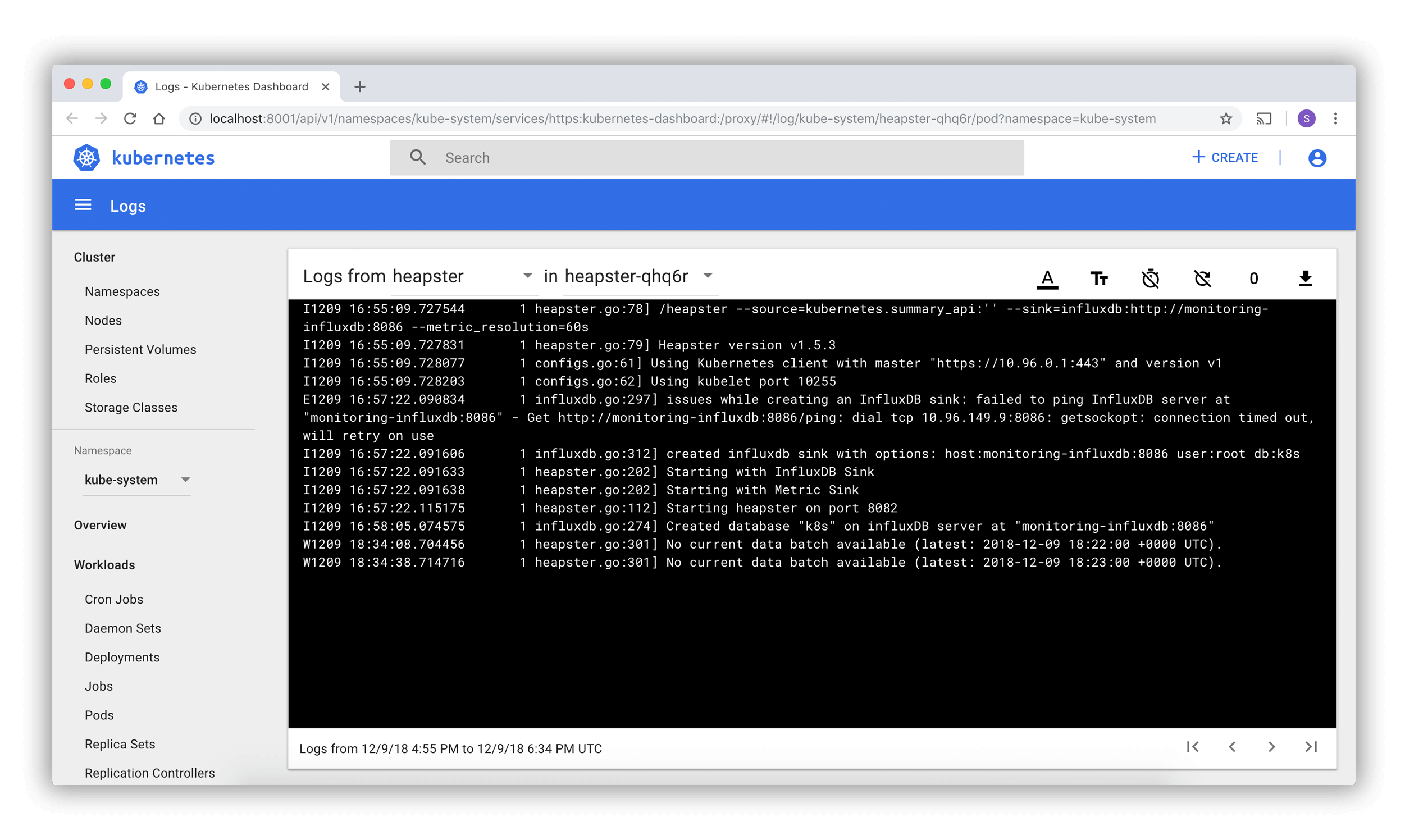
更多信息,参见 Kubernetes Dashboard 项目页面.
本文阐述多种与集群交互的方法。
当你第一次访问 Kubernetes API 的时候,我们建议你使用 Kubernetes CLI 工具 kubectl。
访问集群时,你需要知道集群的地址并且拥有访问的凭证。通常, 这些在你通过启动安装安装集群时都是自动安装好的, 或者其他人安装时也应该提供了凭证和集群地址。
通过以下命令检查 kubectl 是否知道集群地址及凭证:
kubectl config view
有许多例子介绍了如何使用 kubectl, 可以在 kubectl 参考中找到更完整的文档。
Kubectl 处理 apiserver 的定位和身份验证。 如果要使用 curl 或 wget 等 http 客户端或浏览器直接访问 REST API, 可以通过多种方式查找和验证:
以下命令以反向代理的模式运行 kubectl。它处理 apiserver 的定位和验证。 像这样运行:
kubectl proxy --port=8080
参阅 kubectl proxy 获取更多详细信息。
然后,你可以使用 curl、wget 或浏览器访问 API,如果是 IPv6 则用 [::1] 替换 localhost, 如下所示:
curl http://localhost:8080/api/
输出类似于:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
使用 kubectl apply 和 kubectl describe secret ... 及 grep 和剪切操作来为 default 服务帐户创建令牌,如下所示:
首先,创建 Secret,请求默认 ServiceAccount 的令牌:
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: default-token
annotations:
kubernetes.io/service-account.name: default
type: kubernetes.io/service-account-token
EOF
接下来,等待令牌控制器使用令牌填充 Secret:
while ! kubectl describe secret default-token | grep -E '^token' >/dev/null; do
echo "waiting for token..." >&2
sleep 1
done
捕获并使用生成的令牌:
APISERVER=$(kubectl config view --minify | grep server | cut -f 2- -d ":" | tr -d " ")
TOKEN=$(kubectl describe secret default-token | grep -E '^token' | cut -f2 -d':' | tr -d " ")
curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
输出类似于:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
jsonpath 方法实现:
APISERVER=$(kubectl config view --minify -o jsonpath='{.clusters[0].cluster.server}')
TOKEN=$(kubectl get secret default-token -o jsonpath='{.data.token}' | base64 --decode)
curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
输出类似于:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
上面的例子使用了 --insecure 参数,这使得它很容易受到 MITM 攻击。
当 kubectl 访问集群时,它使用存储的根证书和客户端证书来访问服务器
(它们安装在 ~/.kube 目录中)。
由于集群证书通常是自签名的,因此可能需要特殊配置才能让你的 http 客户端使用根证书。
在一些集群中,apiserver 不需要身份验证;它可能只服务于 localhost,或者被防火墙保护, 这个没有一定的标准。 配置对 API 的访问 描述了集群管理员如何进行配置。此类方法可能与未来的高可用性支持相冲突。
Kubernetes 官方提供对 Go 和 Python 的客户端库支持。
go get k8s.io/client-go@kubernetes-<kubernetes-version-number>,
有关详细安装说明,请参阅 INSTALL.md。
请参阅 https://github.com/kubernetes/client-go 以查看支持的版本。import "k8s.io/client-go/kubernetes" 才是对的。Go 客户端可以像 kubectl CLI 一样使用相同的 kubeconfig 文件 来定位和验证 apiserver。可参阅 示例。
如果应用程序以 Pod 的形式部署在集群中,那么请参阅 下一章。
如果想要使用 Python 客户端,
请运行命令:pip install kubernetes。参阅
Python Client Library page
以获得更详细的安装参数。
Python 客户端可以像 kubectl CLI 一样使用相同的 kubeconfig 文件 来定位和验证 apiserver,可参阅 示例。
目前有多个客户端库 为其它语言提供访问 API 的方法。 参阅其它库的相关文档以获取他们是如何验证的。
当你从 Pod 中访问 API 时,定位和验证 API 服务器会有些许不同。
请参阅从 Pod 中访问 API 了解更多详情。
上一节介绍了如何连接到 Kubernetes API 服务器。 有关连接到 Kubernetes 集群上运行的其他服务的信息, 请参阅访问集群服务。
重定向功能已弃用并被删除。请改用代理(见下文)。
使用 Kubernetes 时可能会遇到几种不同的代理:
位于 apiserver 之前的 Proxy/Load-balancer:
外部服务上的云负载均衡器:
LoadBalancer 时自动创建除了前两种类型之外,Kubernetes 用户通常不需要担心任何其他问题。 集群管理员通常会确保后者的正确配置。
本文展示如何使用配置文件来配置对多个集群的访问。
在将集群、用户和上下文定义在一个或多个配置文件中之后,用户可以使用
kubectl config use-context 命令快速地在集群之间进行切换。
用于配置集群访问的文件有时被称为 kubeconfig 文件。
这是一种引用配置文件的通用方式,并不意味着存在一个名为 kubeconfig 的文件。
只使用来源可靠的 kubeconfig 文件。使用特制的 kubeconfig 文件可能会导致恶意代码执行或文件暴露。 如果必须使用不受信任的 kubeconfig 文件,请首先像检查 shell 脚本一样仔细检查它。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要检查 kubectl 是否安装,
执行 kubectl version --client 命令。kubectl 的版本应该与集群的 API
服务器使用同一次版本号。
假设用户有两个集群,一个用于开发工作(development),一个用于测试工作(test)。
在 development 集群中,前端开发者在名为 frontend 的名字空间下工作,
存储开发者在名为 storage 的名字空间下工作。在 test 集群中,
开发人员可能在默认名字空间下工作,也可能视情况创建附加的名字空间。
访问开发集群需要通过证书进行认证。
访问测试集群需要通过用户名和密码进行认证。
创建名为 config-exercise 的目录。在
config-exercise 目录中,创建名为 config-demo 的文件,其内容为:
apiVersion: v1
kind: Config
preferences: {}
clusters:
- cluster:
name: development
- cluster:
name: test
users:
- name: developer
- name: experimenter
contexts:
- context:
name: dev-frontend
- context:
name: dev-storage
- context:
name: exp-test
配置文件描述了集群、用户名和上下文。config-demo 文件中含有描述两个集群、
两个用户和三个上下文的框架。
进入 config-exercise 目录。输入以下命令,将集群详细信息添加到配置文件中:
kubectl config --kubeconfig=config-demo set-cluster development --server=https://1.2.3.4 --certificate-authority=fake-ca-file
kubectl config --kubeconfig=config-demo set-cluster test --server=https://5.6.7.8 --insecure-skip-tls-verify
将用户详细信息添加到配置文件中:
将密码保存到 Kubernetes 客户端配置中有风险。 一个较好的替代方式是使用凭据插件并单独保存这些凭据。 参阅 client-go 凭据插件
kubectl config --kubeconfig=config-demo set-credentials developer --client-certificate=fake-cert-file --client-key=fake-key-seefile
kubectl config --kubeconfig=config-demo set-credentials experimenter --username=exp --password=some-password
kubectl --kubeconfig=config-demo config unset users.<name>kubectl --kubeconfig=config-demo config unset clusters.<name>kubectl --kubeconfig=config-demo config unset contexts.<name>将上下文详细信息添加到配置文件中:
kubectl config --kubeconfig=config-demo set-context dev-frontend --cluster=development --namespace=frontend --user=developer
kubectl config --kubeconfig=config-demo set-context dev-storage --cluster=development --namespace=storage --user=developer
kubectl config --kubeconfig=config-demo set-context exp-test --cluster=test --namespace=default --user=experimenter
打开 config-demo 文件查看添加的详细信息。也可以使用 config view
命令进行查看:
kubectl config --kubeconfig=config-demo view
输出展示了两个集群、两个用户和三个上下文:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
- cluster:
insecure-skip-tls-verify: true
server: https://5.6.7.8
name: test
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: test
namespace: default
user: experimenter
name: exp-test
current-context: ""
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
- name: experimenter
user:
# 文档说明(本注释不属于命令输出)。
# 将密码保存到 Kubernetes 客户端配置有风险。
# 一个较好的替代方式是使用凭据插件并单独保存这些凭据。
# 参阅 https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/authentication/#client-go-credential-plugins
password: some-password
username: exp
其中的 fake-ca-file、fake-cert-file 和 fake-key-file 是证书文件路径名的占位符。
你需要更改这些值,使之对应你的环境中证书文件的实际路径名。
有时你可能希望在这里使用 BASE64 编码的数据而不是一个个独立的证书文件。
如果是这样,你需要在键名上添加 -data 后缀。例如,
certificate-authority-data、client-certificate-data 和 client-key-data。
每个上下文包含三部分(集群、用户和名字空间),例如,
dev-frontend 上下文表明:使用 developer 用户的凭证来访问 development 集群的
frontend 名字空间。
设置当前上下文:
kubectl config --kubeconfig=config-demo use-context dev-frontend
现在当输入 kubectl 命令时,相应动作会应用于 dev-frontend 上下文中所列的集群和名字空间,
同时,命令会使用 dev-frontend 上下文中所列用户的凭证。
使用 --minify 参数,来查看与当前上下文相关联的配置信息。
kubectl config --kubeconfig=config-demo view --minify
输出结果展示了 dev-frontend 上下文相关的配置信息:
apiVersion: v1
clusters:
- cluster:
certificate-authority: fake-ca-file
server: https://1.2.3.4
name: development
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
current-context: dev-frontend
kind: Config
preferences: {}
users:
- name: developer
user:
client-certificate: fake-cert-file
client-key: fake-key-file
现在假设用户希望在测试集群中工作一段时间。
将当前上下文更改为 exp-test:
kubectl config --kubeconfig=config-demo use-context exp-test
现在你发出的所有 kubectl 命令都将应用于 test 集群的默认名字空间。
同时,命令会使用 exp-test 上下文中所列用户的凭证。
查看更新后的当前上下文 exp-test 相关的配置:
kubectl config --kubeconfig=config-demo view --minify
最后,假设用户希望在 development 集群中的 storage 名字空间下工作一段时间。
将当前上下文更改为 dev-storage:
kubectl config --kubeconfig=config-demo use-context dev-storage
查看更新后的当前上下文 dev-storage 相关的配置:
kubectl config --kubeconfig=config-demo view --minify
在 config-exercise 目录中,创建名为 config-demo-2 的文件,其中包含以下内容:
apiVersion: v1
kind: Config
preferences: {}
contexts:
- context:
cluster: development
namespace: ramp
user: developer
name: dev-ramp-up
上述配置文件定义了一个新的上下文,名为 dev-ramp-up。
查看是否有名为 KUBECONFIG 的环境变量。
如有,保存 KUBECONFIG 环境变量当前的值,以便稍后恢复。
例如:
export KUBECONFIG_SAVED="$KUBECONFIG"
$Env:KUBECONFIG_SAVED=$ENV:KUBECONFIG
KUBECONFIG 环境变量是配置文件路径的列表,该列表在 Linux 和 Mac 中以冒号分隔,
在 Windows 中以分号分隔。
如果有 KUBECONFIG 环境变量,请熟悉列表中的配置文件。
临时添加两条路径到 KUBECONFIG 环境变量中。例如:
export KUBECONFIG="${KUBECONFIG}:config-demo:config-demo-2"
$Env:KUBECONFIG=("config-demo;config-demo-2")
在 config-exercise 目录中输入以下命令:
kubectl config view
输出展示了 KUBECONFIG 环境变量中所列举的所有文件合并后的信息。
特别地,注意合并信息中包含来自 config-demo-2 文件的 dev-ramp-up 上下文和来自
config-demo 文件的三个上下文:
contexts:
- context:
cluster: development
namespace: frontend
user: developer
name: dev-frontend
- context:
cluster: development
namespace: ramp
user: developer
name: dev-ramp-up
- context:
cluster: development
namespace: storage
user: developer
name: dev-storage
- context:
cluster: test
namespace: default
user: experimenter
name: exp-test
关于 kubeconfig 文件如何合并的更多信息, 请参考使用 kubeconfig 文件组织集群访问
如果用户已经拥有一个集群,可以使用 kubectl 与集群进行交互,
那么很可能在 $HOME/.kube 目录下有一个名为 config 的文件。
进入 $HOME/.kube 目录,看看那里有什么文件。通常会有一个名为
config 的文件,目录中可能还有其他配置文件。请简单地熟悉这些文件的内容。
如果有 $HOME/.kube/config 文件,并且还未列在 KUBECONFIG 环境变量中,
那么现在将它追加到 KUBECONFIG 环境变量中。例如:
export KUBECONFIG="${KUBECONFIG}:${HOME}/.kube/config"
$Env:KUBECONFIG="$Env:KUBECONFIG;$HOME\.kube\config"
在配置练习目录中输入以下命令,查看当前 KUBECONFIG 环境变量中列举的所有文件合并后的配置信息:
kubectl config view
将 KUBECONFIG 环境变量还原为原始值。例如:
export KUBECONFIG="$KUBECONFIG_SAVED"
$Env:KUBECONFIG=$ENV:KUBECONFIG_SAVED
你在通过集群的身份验证后将获得哪些属性(用户名、组),这一点并不总是很明显。 如果你同时管理多个集群,这可能会更具挑战性。
对于你所选择的 Kubernetes 客户端上下文,有一个 kubectl 子命令可以检查用户名等主体属性:
kubectl alpha auth whoami。
更多细节请参阅通过 API 访问客户端的身份验证信息。
本文展示如何使用 kubectl port-forward 连接到在 Kubernetes 集群中运行的 MongoDB 服务。
这种类型的连接对数据库调试很有用。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.10. 要获知版本信息,请输入kubectl version.
创建一个运行 MongoDB 的 Deployment:
kubectl apply -f https://k8s.io/examples/application/mongodb/mongo-deployment.yaml
成功执行的命令的输出可以证明创建了 Deployment:
deployment.apps/mongo created
查看 Pod 状态,检查其是否准备就绪:
kubectl get pods
输出显示创建的 Pod:
NAME READY STATUS RESTARTS AGE
mongo-75f59d57f4-4nd6q 1/1 Running 0 2m4s
查看 Deployment 状态:
kubectl get deployment
输出显示创建的 Deployment:
NAME READY UP-TO-DATE AVAILABLE AGE
mongo 1/1 1 1 2m21s
该 Deployment 自动管理一个 ReplicaSet。查看该 ReplicaSet 的状态:
kubectl get replicaset
输出显示 ReplicaSet 已被创建:
NAME DESIRED CURRENT READY AGE
mongo-75f59d57f4 1 1 1 3m12s
创建一个在网络上公开的 MongoDB 服务:
kubectl apply -f https://k8s.io/examples/application/mongodb/mongo-service.yaml
成功执行的命令的输出可以证明 Service 已经被创建:
service/mongo created
检查所创建的 Service:
kubectl get service mongo
输出显示已被创建的 Service:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mongo ClusterIP 10.96.41.183 <none> 27017/TCP 11s
验证 MongoDB 服务是否运行在 Pod 中并且在监听 27017 端口:
# 将 mongo-75f59d57f4-4nd6q 改为 Pod 的名称
kubectl get pod mongo-75f59d57f4-4nd6q --template='{{(index (index .spec.containers 0).ports 0).containerPort}}{{"\n"}}'
输出应该显示对应 Pod 中 MongoDB 的端口:
27017
27017 是 MongoDB 的官方 TCP 端口。
kubectl port-forward 允许使用资源名称
(例如 Pod 名称)来选择匹配的 Pod 来进行端口转发。
# 将 mongo-75f59d57f4-4nd6q 改为 Pod 的名称
kubectl port-forward mongo-75f59d57f4-4nd6q 28015:27017
这相当于
kubectl port-forward pods/mongo-75f59d57f4-4nd6q 28015:27017
或者
kubectl port-forward deployment/mongo 28015:27017
或者
kubectl port-forward replicaset/mongo-75f59d57f4 28015:27017
或者
kubectl port-forward service/mongo 28015:27017
以上所有命令都有效。输出类似于:
Forwarding from 127.0.0.1:28015 -> 27017
Forwarding from [::1]:28015 -> 27017
kubectl port-forward 不会返回。你需要打开另一个终端来继续这个练习。
启动 MongoDB 命令行接口:
mongosh --port 28015
在 MongoDB 命令行提示符下,输入 ping 命令:
db.runCommand( { ping: 1 } )
成功的 ping 请求应该返回:
{ ok: 1 }
如果你不需要指定特定的本地端口,你可以让 kubectl 来选择和分配本地端口,
这样你就不需要管理本地端口冲突。该命令使用稍微不同的语法:
kubectl port-forward deployment/mongo :27017
kubectl 工具会找到一个未被使用的本地端口号(避免使用低段位的端口号,
因为他们可能会被其他应用程序使用)。输出类似于:
Forwarding from 127.0.0.1:63753 -> 27017
Forwarding from [::1]:63753 -> 27017
与本地 28015 端口建立的连接将被转发到运行 MongoDB 服务器的 Pod 的 27017 端口。 通过此连接,你可以使用本地工作站来调试在 Pod 中运行的数据库。
kubectl port-forward 仅实现了 TCP 端口 支持。
在 issue 47862
中跟踪了对 UDP 协议的支持。
进一步了解 kubectl port-forward。
本文展示如何创建一个 Kubernetes 服务对象,能让外部客户端访问在集群中运行的应用。 该服务为一个应用的两个运行实例提供负载均衡。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
这是应用程序部署的配置文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world
spec:
selector:
matchLabels:
run: load-balancer-example
replicas: 2
template:
metadata:
labels:
run: load-balancer-example
spec:
containers:
- name: hello-world
image: gcr.io/google-samples/node-hello:1.0
ports:
- containerPort: 8080
protocol: TCP
在你的集群中运行一个 Hello World 应用。 使用上面的文件创建应用程序 Deployment:
kubectl apply -f https://k8s.io/examples/service/access/hello-application.yaml
上面的命令创建一个 Deployment 对象 和一个关联的 ReplicaSet 对象。 这个 ReplicaSet 有两个 Pod, 每个 Pod 都运行着 Hello World 应用。
展示 Deployment 的信息:
kubectl get deployments hello-world
kubectl describe deployments hello-world
展示你的 ReplicaSet 对象信息:
kubectl get replicasets
kubectl describe replicasets
创建一个服务对象来暴露 Deployment:
kubectl expose deployment hello-world --type=NodePort --name=example-service
展示 Service 信息:
kubectl describe services example-service
输出类似于:
Name: example-service
Namespace: default
Labels: run=load-balancer-example
Annotations: <none>
Selector: run=load-balancer-example
Type: NodePort
IP: 10.32.0.16
Port: <unset> 8080/TCP
TargetPort: 8080/TCP
NodePort: <unset> 31496/TCP
Endpoints: 10.200.1.4:8080,10.200.2.5:8080
Session Affinity: None
Events: <none>
注意 Service 中的 NodePort 值。例如在上面的输出中,NodePort 值是 31496。
列出运行 Hello World 应用的 Pod:
kubectl get pods --selector="run=load-balancer-example" --output=wide
输出类似于:
NAME READY STATUS ... IP NODE
hello-world-2895499144-bsbk5 1/1 Running ... 10.200.1.4 worker1
hello-world-2895499144-m1pwt 1/1 Running ... 10.200.2.5 worker2
获取运行 Hello World 的 pod 的其中一个节点的公共 IP 地址。如何获得此地址取决于你设置集群的方式。
例如,如果你使用的是 Minikube,则可以通过运行 kubectl cluster-info 来查看节点地址。
如果你使用的是 Google Compute Engine 实例,
则可以使用 gcloud compute instances list 命令查看节点的公共地址。
在你选择的节点上,创建一个防火墙规则以开放节点端口上的 TCP 流量。 例如,如果你的服务的 NodePort 值为 31568,请创建一个防火墙规则以允许 31568 端口上的 TCP 流量。 不同的云提供商提供了不同方法来配置防火墙规则。
使用节点地址和 node port 来访问 Hello World 应用:
curl http://<public-node-ip>:<node-port>
这里的 <public-node-ip> 是你节点的公共 IP 地址,<node-port> 是你服务的 NodePort 值。
对于请求成功的响应是一个 hello 消息:
Hello Kubernetes!
作为 kubectl expose 的替代方法,
你可以使用服务配置文件来创建服务。
想要删除服务,输入以下命令:
kubectl delete services example-service
想要删除运行 Hello World 应用的 Deployment、ReplicaSet 和 Pod,输入以下命令:
kubectl delete deployment hello-world
跟随教程使用 Service 连接到应用。
本任务会描述如何创建前端(Frontend)微服务和后端(Backend)微服务。后端微服务是一个 hello 欢迎程序。 前端通过 nginx 和一个 Kubernetes 服务 暴露后端所提供的服务。
hello 后端微服务nginx 前端微服务type=LoadBalancer 的 Service 对象将前端微服务暴露到集群外部你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
本任务使用外部负载均衡服务, 所以需要对应的可支持此功能的环境。如果你的环境不能支持,你可以使用 NodePort 类型的服务代替。
后端是一个简单的 hello 欢迎微服务应用。这是后端应用的 Deployment 配置文件:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
spec:
selector:
matchLabels:
app: hello
tier: backend
track: stable
replicas: 3
template:
metadata:
labels:
app: hello
tier: backend
track: stable
spec:
containers:
- name: hello
image: "gcr.io/google-samples/hello-go-gke:1.0"
ports:
- name: http
containerPort: 80
...创建后端 Deployment:
kubectl apply -f https://k8s.io/examples/service/access/backend-deployment.yaml
查看后端的 Deployment 信息:
kubectl describe deployment backend
输出类似于:
Name: backend
Namespace: default
CreationTimestamp: Mon, 24 Oct 2016 14:21:02 -0700
Labels: app=hello
tier=backend
track=stable
Annotations: deployment.kubernetes.io/revision=1
Selector: app=hello,tier=backend,track=stable
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=hello
tier=backend
track=stable
Containers:
hello:
Image: "gcr.io/google-samples/hello-go-gke:1.0"
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: hello-3621623197 (3/3 replicas created)
Events:
...
hello Service 对象 将请求从前端发送到后端的关键是后端 Service。Service 创建一个固定 IP 和 DNS 解析名入口, 使得后端微服务总是可达。Service 使用 选择算符 来寻找目标 Pod。
首先,浏览 Service 的配置文件:
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
selector:
app: hello
tier: backend
ports:
- protocol: TCP
port: 80
targetPort: http
...配置文件中,你可以看到名为 hello 的 Service 将流量路由到包含 app: hello
和 tier: backend 标签的 Pod。
创建后端 Service:
kubectl apply -f https://k8s.io/examples/service/access/backend-service.yaml
此时,你已经有了一个运行着 hello 应用的三个副本的 backend Deployment,你也有了
一个 Service 用于路由网络流量。不过,这个服务在集群外部无法访问也无法解析。
现在你已经有了运行中的后端应用,你可以创建一个可在集群外部访问的前端,并通过代理 前端的请求连接到后端。
前端使用被赋予后端 Service 的 DNS 名称将请求发送到后端工作 Pods。这一 DNS
名称为 hello,也就是 examples/service/access/backend-service.yaml 配置
文件中 name 字段的取值。
前端 Deployment 中的 Pods 运行一个 nginx 镜像,这个已经配置好的镜像会将请求转发
给后端的 hello Service。下面是 nginx 的配置文件:
# Backend 是 nginx 的内部标识符,用于命名以下特定的 upstream
upstream Backend {
# hello 是 Kubernetes 中的后端服务所使用的内部 DNS 名称
server hello;
}
server {
listen 80;
location / {
# 以下语句将流量通过代理方式转发到名为 Backend 的上游
proxy_pass http://Backend;
}
}
与后端类似,前端用包含一个 Deployment 和一个 Service。后端与前端服务之间的一个
重要区别是前端 Service 的配置文件包含了 type: LoadBalancer,也就是说,Service
会使用你的云服务商的默认负载均衡设备,从而实现从集群外访问的目的。
---
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
selector:
app: hello
tier: frontend
ports:
- protocol: "TCP"
port: 80
targetPort: 80
type: LoadBalancer
...---
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
selector:
matchLabels:
app: hello
tier: frontend
track: stable
replicas: 1
template:
metadata:
labels:
app: hello
tier: frontend
track: stable
spec:
containers:
- name: nginx
image: "gcr.io/google-samples/hello-frontend:1.0"
lifecycle:
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
...创建前端 Deployment 和 Service:
kubectl apply -f https://k8s.io/examples/service/access/frontend-deployment.yaml
kubectl apply -f https://k8s.io/examples/service/access/frontend-service.yaml
通过输出确认两个资源都已经被创建:
deployment.apps/frontend created
service/frontend created
一旦你创建了 LoadBalancer 类型的 Service,你可以使用这条命令查看外部 IP:
kubectl get service frontend --watch
外部 IP 字段的生成可能需要一些时间。如果是这种情况,外部 IP 会显示为 <pending>。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.51.252.116 <pending> 80/TCP 10s
当外部 IP 地址被分配可用时,配置会更新,在 EXTERNAL-IP 头部下显示新的 IP:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
frontend LoadBalancer 10.51.252.116 XXX.XXX.XXX.XXX 80/TCP 1m
这一新的 IP 地址就可以用来从集群外与 frontend 服务交互了。
前端和后端已经完成连接了。你可以使用 curl 命令通过你的前端 Service 的外部 IP 访问服务端点。
curl http://${EXTERNAL_IP} # 将 EXTERNAL_IP 替换为你之前看到的外部 IP
输出显示后端生成的消息:
{"message":"Hello"}
要删除服务,输入下面的命令:
kubectl delete services frontend backend
要删除在前端和后端应用中运行的 Deployment、ReplicaSet 和 Pod,输入下面的命令:
kubectl delete deployment frontend backend
本文展示如何创建一个外部负载均衡器。
创建服务时,你可以选择自动创建云网络负载均衡器。 负载均衡器提供外部可访问的 IP 地址,可将流量发送到集群节点上的正确端口上 (假设集群在支持的环境中运行,并配置了正确的云负载均衡器驱动包)。
你还可以使用 Ingress 代替 Service。 更多信息,请参阅 Ingress 文档。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的集群必须在已经支持配置外部负载均衡器的云或其他环境中运行。
要创建外部负载均衡器,请将以下内容添加到你的 Service 清单文件:
type: LoadBalancer
你的清单文件可能会如下所示:
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- port: 8765
targetPort: 9376
type: LoadBalancer
你也可以使用 kubectl expose 命令及其 --type=LoadBalancer 参数创建服务:
kubectl expose deployment example --port=8765 --target-port=9376 \
--name=example-service --type=LoadBalancer
此命令通过使用与引用资源(在上面的示例的情况下,名为 example 的
Deployment)
相同的选择器来创建一个新的服务。
更多信息(包括更多的可选参数),请参阅
kubectl expose 指南。
你可以通过 kubectl 获取服务信息,找到为你的服务创建的 IP 地址:
kubectl describe services example-service
这将获得类似如下输出:
Name: example-service
Namespace: default
Labels: app=example
Annotations: <none>
Selector: app=example
Type: LoadBalancer
IP Families: <none>
IP: 10.3.22.96
IPs: 10.3.22.96
LoadBalancer Ingress: 192.0.2.89
Port: <unset> 8765/TCP
TargetPort: 9376/TCP
NodePort: <unset> 30593/TCP
Endpoints: 172.17.0.3:9376
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
负载均衡器的 IP 地址列在 LoadBalancer Ingress 旁边。
如果你在 Minikube 上运行服务,你可以通过以下命令找到分配的 IP 地址和端口:
minikube service example-service --url
默认情况下,目标容器中看到的源 IP 将不是客户端的原始源 IP。
要启用保留客户端 IP,可以在服务的 .spec 中配置以下字段:
.spec.externalTrafficPolicy - 表示此 Service 是否希望将外部流量路由到节点本地或集群范围的端点。
有两个可用选项:Cluster(默认)和 Local。
Cluster 隐藏了客户端源 IP,可能导致第二跳到另一个节点,但具有良好的整体负载分布。
Local 保留客户端源 IP 并避免 LoadBalancer 和 NodePort 类型服务的第二跳,
但存在潜在的不均衡流量传播风险。.spec.healthCheckNodePort - 指定服务的 healthcheck nodePort(数字端口号)。
如果你未指定 healthCheckNodePort,服务控制器从集群的 NodePort 范围内分配一个端口。
你可以通过设置 API 服务器的命令行选项 --service-node-port-range 来配置上述范围。
在服务 type 设置为 LoadBalancer 并且 externalTrafficPolicy 设置为 Local 时,
Service 将会使用用户指定的 healthCheckNodePort 值(如果你指定了它)。可以通过在服务的清单文件中将 externalTrafficPolicy 设置为 Local 来激活此功能。比如:
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- port: 8765
targetPort: 9376
externalTrafficPolicy: Local
type: LoadBalancer
一些云服务供应商的负载均衡服务不允许你为每个目标配置不同的权重。
由于每个目标在向节点发送流量方面的权重相同,因此外部流量不会在不同 Pod 之间平均负载。 外部负载均衡器不知道每个节点上用作目标的 Pod 数量。
在 NumServicePods << NumNodes 或 NumServicePods >> NumNodes 时,
即使没有权重,也会看到接近相等的分布。
内部 Pod 到 Pod 的流量应该与 ClusterIP 服务类似,所有 Pod 的概率相同。
Kubernetes v1.17 [stable]
在通常情况下,应在删除 LoadBalancer 类型 Service 后立即清除云服务供应商中的相关负载均衡器资源。 但是,众所周知,在删除关联的服务后,云资源被孤立的情况很多。 引入了针对服务负载均衡器的终结器保护,以防止这种情况发生。 通过使用终结器,在删除相关的负载均衡器资源之前,也不会删除服务资源。
具体来说,如果服务具有 type LoadBalancer,则服务控制器将附加一个名为
service.kubernetes.io/load-balancer-cleanup 的终结器。
仅在清除负载均衡器资源后才能删除终结器。
即使在诸如服务控制器崩溃之类的极端情况下,这也可以防止负载均衡器资源悬空。
请务必注意,此功能的数据路径由 Kubernetes 集群外部的负载均衡器提供。
当服务 type 设置为 LoadBalancer 时,Kubernetes 向集群中的 Pod 提供的功能等同于
type 设置为 ClusterIP,并通过使用托管了相关 Kubernetes Pod 的节点作为条目对负载均衡器
(从外部到 Kubernetes)进行编程来扩展它。
Kubernetes 控制平面自动创建外部负载均衡器、健康检查(如果需要)和包过滤规则(如果需要)。
一旦云服务供应商为负载均衡器分配了 IP 地址,控制平面就会查找该外部 IP 地址并将其填充到 Service 对象中。
本文展示如何使用 kubectl 来列出集群中所有运行 Pod 的容器的镜像
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
在本练习中,你将使用 kubectl 来获取集群中运行的所有 Pod,并格式化输出来提取每个 Pod 中的容器列表。
kubectl get pods --all-namespaces 获取所有命名空间下的所有 Pod-o jsonpath={.items[*].spec['initContainers', 'containers'][*].image} 来格式化输出,以仅包含容器镜像名称。
这将以递归方式从返回的 json 中解析出 image 字段。
tr, sort, uniq
tr 以用换行符替换空格sort 来对结果进行排序uniq 来聚合镜像计数kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" |\
tr -s '[[:space:]]' '\n' |\
sort |\
uniq -c
jsonpath 解释如下:
.items[*]: 对于每个返回的值.spec: 获取 spec['initContainers', 'containers'][*]: 对于每个容器.image: 获取镜像kubectl get pod nginx,路径的 .items[*] 部分应该省略,
因为返回的是一个 Pod 而不是一个项目列表。
可以使用 range 操作进一步控制格式化,以单独操作每个元素。
kubectl get pods --all-namespaces -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{":\t"}{range .spec.containers[*]}{.image}{", "}{end}{end}' |\
sort
要获取匹配特定标签的 Pod,请使用 -l 参数。以下匹配仅与标签 app=nginx 相符的 Pod。
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" -l app=nginx
要获取匹配特定命名空间的 Pod,请使用 namespace 参数。以下仅匹配 kube-system 命名空间下的 Pod。
kubectl get pods --namespace kube-system -o jsonpath="{.items[*].spec.containers[*].image}"
作为 jsonpath 的替代,Kubectl 支持使用 go-templates 来格式化输出:
kubectl get pods --all-namespaces -o go-template --template="{{range .items}}{{range .spec.containers}}{{.image}} {{end}}{{end}}"
Ingress是一种 API 对象, 其中定义了一些规则使得集群中的服务可以从集群外访问。 Ingress 控制器负责满足 Ingress 中所设置的规则。
本节为你展示如何配置一个简单的 Ingress,根据 HTTP URI 将服务请求路由到服务 web 或 web2。
本教程假设你正在使用 minikube 运行一个本地 Kubernetes 集群。
参阅安装工具了解如何安装 minikube。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.19. 要获知版本信息,请输入kubectl version.
如果你使用的是较早的 Kubernetes 版本,请切换到该版本的文档。
如果你还未在本地搭建集群,运行 minikube start 创建集群。
为了启用 NGINIX Ingress 控制器,可以运行下面的命令:
minikube addons enable ingress
检查验证 NGINX Ingress 控制器处于运行状态:
kubectl get pods -n ingress-nginx
最多可能需要等待一分钟才能看到这些 Pod 运行正常。
输出类似于:
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-g9g49 0/1 Completed 0 11m
ingress-nginx-admission-patch-rqp78 0/1 Completed 1 11m
ingress-nginx-controller-59b45fb494-26npt 1/1 Running 0 11m
使用下面的命令创建一个 Deployment:
kubectl create deployment web --image=gcr.io/google-samples/hello-app:1.0
输出:
deployment.apps/web created
将 Deployment 暴露出来:
kubectl expose deployment web --type=NodePort --port=8080
输出类似于:
service/web exposed
验证 Service 已经创建,并且可以从节点端口访问:
kubectl get service web
输出类似于:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web NodePort 10.104.133.249 <none> 8080:31637/TCP 12m
使用节点端口信息访问服务:
minikube service web --url
输出类似于:
http://172.17.0.15:31637
curl http://172.17.0.15:31637
输出类似于:
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
你现在应该可以通过 Minikube 的 IP 地址和节点端口来访问示例应用了。 下一步是让自己能够通过 Ingress 资源来访问应用。
下面是一个定义 Ingress 的配置文件,负责通过 hello-world.info
将请求转发到你的服务。
根据下面的 YAML 创建文件 example-ingress.yaml:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
rules:
- host: hello-world.info
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: web
port:
number: 8080通过运行下面的命令创建 Ingress 对象:
kubectl apply -f https://k8s.io/examples/service/networking/example-ingress.yaml
输出类似于:
ingress.networking.k8s.io/example-ingress created
验证 IP 地址已被设置:
kubectl get ingress
此操作可能需要几分钟时间。
接下来你将会在 ADDRESS 列中看到 IPv4 地址,例如:
NAME CLASS HOSTS ADDRESS PORTS AGE
example-ingress <none> hello-world.info 172.17.0.15 80 38s
验证 Ingress 控制器能够转发请求流量:
curl --resolve "hello-world.info:80:$( minikube ip )" -i http://hello-world.info
你应该看到类似输出:
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
你也可以从浏览器访问 hello-world.info。
可选
查看 Minikube 报告的外部 IP 地址:
minikube ip
将类似以下这一行添加到你计算机上的 /etc/hosts 文件的末尾(需要管理员访问权限):
172.17.0.15 hello-world.info
更改 IP 地址以匹配 `minikube ip` 的输出。更改完成后,在浏览器中访问 URL hello-world.info,请求将被发送到 Minikube。
使用下面的命令创建第二个 Deployment:
kubectl create deployment web2 --image=gcr.io/google-samples/hello-app:2.0
输出类似于:
deployment.apps/web2 created
将第二个 Deployment 暴露出来:
kubectl expose deployment web2 --port=8080 --type=NodePort
输出类似于:
service/web2 exposed
编辑现有的 example-ingress.yaml,在文件最后添加以下行:
- path: /v2
pathType: Prefix
backend:
service:
name: web2
port:
number: 8080
应用变更:
kubectl apply -f example-ingress.yaml
输出类似于:
ingress.networking/example-ingress configured
访问 Hello World 应用的第一个版本:
curl --resolve "hello-world.info:80:$( minikube ip )" -i http://hello-world.info
输出类似于:
Hello, world!
Version: 1.0.0
Hostname: web-55b8c6998d-8k564
访问 Hello World 应用的第二个版本:
curl --resolve "hello-world.info:80:$( minikube ip )" -i http://hello-world.info/v2
输出类似于:
Hello, world!
Version: 2.0.0
Hostname: web2-75cd47646f-t8cjk
如果你执行了更新 /etc/hosts 的可选步骤,你也可以从你的浏览器中访问
hello-world.info 和 hello-world.info/v2。
本文旨在说明如何让一个 Pod 内的两个容器使用一个卷(Volume)进行通信。 参阅如何让两个进程跨容器通过 共享进程名字空间。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
在这个练习中,你会创建一个包含两个容器的 Pod。两个容器共享一个卷用于他们之间的通信。 Pod 的配置文件如下:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Never
volumes:
- name: shared-data
emptyDir: {}
containers:
- name: nginx-container
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]
在配置文件中,你可以看到 Pod 有一个共享卷,名为 shared-data。
配置文件中的第一个容器运行了一个 nginx 服务器。共享卷的挂载路径是 /usr/share/nginx/html。
第二个容器是基于 debian 镜像的,有一个 /pod-data 的挂载路径。第二个容器运行了下面的命令然后终止。
echo Hello from the debian container > /pod-data/index.html
注意,第二个容器在 nginx 服务器的根目录下写了 index.html 文件。
创建一个包含两个容器的 Pod:
kubectl apply -f https://k8s.io/examples/pods/two-container-pod.yaml
查看 Pod 和容器的信息:
kubectl get pod two-containers --output=yaml
这是输出的一部分:
apiVersion: v1
kind: Pod
metadata:
...
name: two-containers
namespace: default
...
spec:
...
containerStatuses:
- containerID: docker://c1d8abd1 ...
image: debian
...
lastState:
terminated:
...
name: debian-container
...
- containerID: docker://96c1ff2c5bb ...
image: nginx
...
name: nginx-container
...
state:
running:
...
你可以看到 debian 容器已经被终止了,而 nginx 服务器依然在运行。
进入 nginx 容器的 shell:
kubectl exec -it two-containers -c nginx-container -- /bin/bash
在 shell 中,确认 nginx 还在运行。
root@two-containers:/# apt-get update
root@two-containers:/# apt-get install curl procps
root@two-containers:/# ps aux
输出类似于这样:
USER PID ... STAT START TIME COMMAND
root 1 ... Ss 21:12 0:00 nginx: master process nginx -g daemon off;
回忆一下,debian 容器在 nginx 的根目录下创建了 index.html 文件。
使用 curl 向 nginx 服务器发送一个 GET 请求:
root@two-containers:/# curl localhost
输出表示 nginx 向外提供了 debian 容器所写就的页面:
Hello from the debian container
Pod 能有多个容器的主要原因是为了支持辅助应用(helper applications),以协助主应用(primary application)。 辅助应用的典型例子是数据抽取,数据推送和代理。辅助应用和主应用经常需要相互通信。 就如这个练习所示,通信通常是通过共享文件系统完成的,或者,也通过回环网络接口 localhost 完成。 举个网络接口的例子,web 服务器带有一个协助程序用于拉取 Git 仓库的更新。
在本练习中的卷为 Pod 生命周期中的容器相互通信提供了一种方法。如果 Pod 被删除或者重建了, 任何共享卷中的数据都会丢失。
Kubernetes 提供 DNS 集群插件,大多数支持的环境默认情况下都会启用。 在 Kubernetes 1.11 及其以后版本中,推荐使用 CoreDNS, kubeadm 默认会安装 CoreDNS。
要了解关于如何为 Kubernetes 集群配置 CoreDNS 的更多信息,参阅 定制 DNS 服务。 关于如何利用 kube-dns 配置 kubernetes DNS 的演示例子,参阅 Kubernetes DNS 插件示例。
本文展示了如何连接 Kubernetes 集群上运行的服务。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
在 Kubernetes 里,节点、 Pod 和 服务 都有自己的 IP。 许多情况下,集群上的节点 IP、Pod IP 和某些服务 IP 是路由不可达的, 所以不能从集群之外访问它们,例如从你自己的台式机。
你有多种可选方式从集群外连接节点、Pod 和服务:
NodePort 或 LoadBalancer 的 Service,可以从外部访问它们。
请查阅 Service 和
kubectl expose 文档。典型情况下,kube-system 名字空间中会启动集群的几个服务。
使用 kubectl cluster-info 命令获取这些服务的列表:
kubectl cluster-info
输出类似于:
Kubernetes master is running at https://192.0.2.1
elasticsearch-logging is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
kibana-logging is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/kibana-logging/proxy
kube-dns is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/kube-dns/proxy
grafana is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
heapster is running at https://192.0.2.1/api/v1/namespaces/kube-system/services/monitoring-heapster/proxy
这一输出显示了用 proxy 动词访问每个服务时可用的 URL。例如,此集群
(使用 Elasticsearch)启用了集群层面的日志。如果提供合适的凭据,可以通过
https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/
访问,或通过一个 kubectl proxy 来访问:
http://localhost:8080/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/。
kubectl proxy。
如前所述,你可以使用 kubectl cluster-info 命令取得服务的代理 URL。
为了创建包含服务末端、后缀和参数的代理 URLs,你可以在服务的代理 URL 中添加:
http://kubernetes_master_address/api/v1/namespaces/namespace_name/services/service_name[:port_name]/proxy
如果还没有为你的端口指定名称,你可以不用在 URL 中指定 port_name。 对于命名和未命名端口,你还可以使用端口号代替 port_name。
默认情况下,API 服务器使用 HTTP 为你的服务提供代理。 要使用 HTTPS,请在服务名称前加上 https::
http://<kubernetes_master_address>/api/v1/namespaces/<namespace_name>/services/<service_name>/proxy
URL 的 <service_name> 段支持的格式为:
<service_name> - 使用 http 代理到默认或未命名端口<service_name>:<port_name> - 使用 http 代理到指定的端口名称或端口号https:<service_name>: - 使用 https 代理到默认或未命名端口(注意尾随冒号)https:<service_name>:<port_name> - 使用 https 代理到指定的端口名称或端口号如要访问 Elasticsearch 服务末端 _search?q=user:kimchy,你可以使用以下地址:
http://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_search?q=user:kimchy
如要访问 Elasticsearch 集群健康信息_cluster/health?pretty=true,你可以使用以下地址:
https://192.0.2.1/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_cluster/health?pretty=true
健康信息与下面的例子类似:
{
"cluster_name" : "kubernetes_logging",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 5
}
如要访问 https Elasticsearch 服务健康信息 _cluster/health?pretty=true,你可以使用以下地址:
https://192.0.2.1/api/v1/namespaces/kube-system/services/https:elasticsearch-logging:/proxy/_cluster/health?pretty=true
你或许能够将 API 服务器代理的 URL 放入浏览器的地址栏,然而:
配置聚合层可以允许 Kubernetes apiserver 使用其它 API 扩展,这些 API 不是核心 Kubernetes API 的一部分。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
要使聚合层在你的环境中正常工作以支持代理服务器和扩展 apiserver 之间的相互 TLS 身份验证, 需要满足一些设置要求。Kubernetes 和 kube-apiserver 具有多个 CA, 因此请确保代理是由聚合层 CA 签名的,而不是由 Kubernetes 通用 CA 签名的。
对不同的客户端类型重复使用相同的 CA 会对集群的功能产生负面影响。 有关更多信息,请参见 CA 重用和冲突。
与自定义资源定义(CRD)不同,除标准的 Kubernetes apiserver 外,Aggregation API 还涉及另一个服务器:扩展 apiserver。 Kubernetes apiserver 将需要与你的扩展 apiserver 通信,并且你的扩展 apiserver 也需要与 Kubernetes apiserver 通信。 为了确保此通信的安全,Kubernetes apiserver 使用 x509 证书向扩展 apiserver 认证。
本节介绍身份认证和鉴权流程的工作方式以及如何配置它们。
大致流程如下:
本节的其余部分详细描述了这些步骤。
该流程可以在下图中看到。
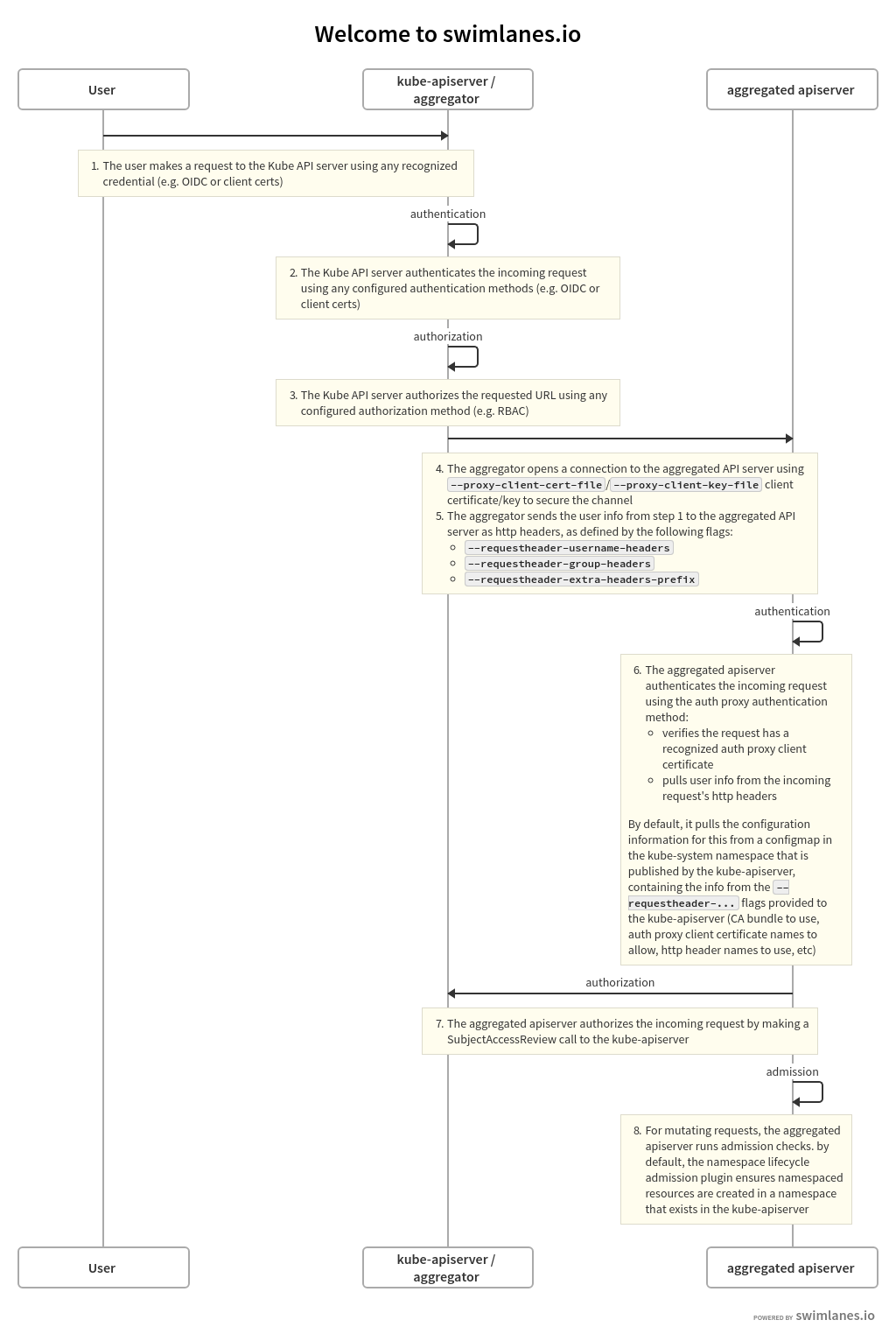
以上泳道的来源可以在本文档的源码中找到。
由扩展 apiserver 服务的对 API 路径的请求以与所有 API 请求相同的方式开始: 与 Kubernetes apiserver 的通信。该路径已通过扩展 apiserver 在 Kubernetes apiserver 中注册。
用户与 Kubernetes apiserver 通信,请求访问路径。 Kubernetes apiserver 使用它的标准认证和授权配置来对用户认证,以及对特定路径的鉴权。
有关对 Kubernetes 集群认证的概述, 请参见对集群认证。 有关对 Kubernetes 集群资源的访问鉴权的概述, 请参见鉴权概述。
到目前为止,所有内容都是标准的 Kubernetes API 请求,认证与鉴权。
Kubernetes apiserver 现在准备将请求发送到扩展 apiserver。
Kubernetes apiserver 现在将请求发送或代理到注册以处理该请求的扩展 apiserver。 为此,它需要了解几件事:
Kubernetes apiserver 应该如何向扩展 apiserver 认证,以通知扩展 apiserver 通过网络发出的请求来自有效的 Kubernetes apiserver?
Kubernetes apiserver 应该如何通知扩展 apiserver 原始请求已通过认证的用户名和组?
为提供这两条信息,你必须使用若干标志来配置 Kubernetes apiserver。
Kubernetes apiserver 通过 TLS 连接到扩展 apiserver,并使用客户端证书认证。 你必须在启动时使用提供的标志向 Kubernetes apiserver 提供以下内容:
--proxy-client-key-file 指定私钥文件--proxy-client-cert-file 签名的客户端证书文件--requestheader-client-ca-file 签署客户端证书文件的 CA 证书--requestheader-allowed-names 在签署的客户端证书中有效的公用名(CN)Kubernetes apiserver 将使用由 --proxy-client-*-file 指示的文件来向扩展 apiserver认证。
为了使合规的扩展 apiserver 能够将该请求视为有效,必须满足以下条件:
--requestheader-client-ca-file 中。--requestheader-allowed-names 中列出的证书之一。你可以将此选项设置为空白,即为--requestheader-allowed-names=""。
这将向扩展 apiserver 指示任何 CN 都是可接受的。
使用这些选项启动时,Kubernetes apiserver 将:
kube-system 命名空间中创建一个名为
extension-apiserver-authentication 的 ConfigMap,
它将在其中放置 CA 证书和允许的 CN。
反过来,扩展 apiserver 可以检索这些内容以验证请求。请注意,Kubernetes apiserver 使用相同的客户端证书对所有扩展 apiserver 认证。 它不会为每个扩展 apiserver 创建一个客户端证书,而是创建一个证书作为 Kubernetes apiserver 认证。所有扩展 apiserver 请求都重复使用相同的请求。
当 Kubernetes apiserver 将请求代理到扩展 apiserver 时, 它将向扩展 apiserver 通知原始请求已成功通过其验证的用户名和组。 它在其代理请求的 HTTP 头部中提供这些。你必须将要使用的标头名称告知 Kubernetes apiserver。
--requestheader-username-headers 标明用来保存用户名的头部--requestheader-group-headers 标明用来保存 group 的头部--requestheader-extra-headers-prefix 标明用来保存拓展信息前缀的头部这些头部名称也放置在 extension-apiserver-authentication ConfigMap 中,
因此扩展 apiserver 可以检索和使用它们。
扩展 apiserver 在收到来自 Kubernetes apiserver 的代理请求后, 必须验证该请求确实确实来自有效的身份验证代理, 该认证代理由 Kubernetes apiserver 履行。扩展 apiserver 通过以下方式对其认证:
如上所述,从 kube-system 中的 ConfigMap 中检索以下内容:
使用以下证书检查 TLS 连接是否已通过认证:
如果以上均通过,则该请求是来自合法认证代理(在本例中为 Kubernetes apiserver) 的有效代理请求。
请注意,扩展 apiserver 实现负责提供上述内容。
默认情况下,许多扩展 apiserver 实现利用 k8s.io/apiserver/ 软件包来做到这一点。
也有一些实现可能支持使用命令行选项来覆盖这些配置。
为了具有检索 configmap 的权限,扩展 apiserver 需要适当的角色。
在 kube-system 名字空间中有一个默认角色
extension-apiserver-authentication-reader 可用于设置。
扩展 apiserver 现在可以验证从标头检索的user/group是否有权执行给定请求。
通过向 Kubernetes apiserver 发送标准
SubjectAccessReview 请求来实现。
为了使扩展 apiserver 本身被鉴权可以向 Kubernetes apiserver 提交 SubjectAccessReview 请求,
它需要正确的权限。
Kubernetes 包含一个具有相应权限的名为 system:auth-delegator 的默认 ClusterRole,
可以将其授予扩展 apiserver 的服务帐户。
如果 SubjectAccessReview 通过,则扩展 apiserver 执行请求。
通过以下 kube-apiserver 标志启用聚合层。
你的服务提供商可能已经为你完成了这些工作:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
Kubernetes apiserver 有两个客户端 CA 选项:
--client-ca-file--requestheader-client-ca-file这些功能中的每个功能都是独立的;如果使用不正确,可能彼此冲突。
--client-ca-file:当请求到达 Kubernetes apiserver 时,如果启用了此选项,
则 Kubernetes apiserver 会检查请求的证书。
如果它是由 --client-ca-file 引用的文件中的 CA 证书之一签名的,
并且用户是公用名 CN= 的值,而组是组织 O= 的取值,则该请求被视为合法请求。
请参阅关于 TLS 身份验证的文档。
--requestheader-client-ca-file:当请求到达 Kubernetes apiserver 时,
如果启用此选项,则 Kubernetes apiserver 会检查请求的证书。
如果它是由文件引用中的 --requestheader-client-ca-file 所签署的 CA 证书之一签名的,
则该请求将被视为潜在的合法请求。
然后,Kubernetes apiserver 检查通用名称 CN= 是否是
--requestheader-allowed-names 提供的列表中的名称之一。
如果名称允许,则请求被批准;如果不是,则请求被拒绝。
如果同时提供了 --client-ca-file 和 --requestheader-client-ca-file,
则首先检查 --requestheader-client-ca-file CA,然后再检查 --client-ca-file。
通常,这些选项中的每一个都使用不同的 CA(根 CA 或中间 CA)。
常规客户端请求与 --client-ca-file 相匹配,而聚合请求要与
--requestheader-client-ca-file 相匹配。
但是,如果两者都使用同一个 CA,则通常会通过 --client-ca-file
传递的客户端请求将失败,因为 CA 将与 --requestheader-client-ca-file
中的 CA 匹配,但是通用名称 CN= 将不匹配 --requestheader-allowed-names
中可接受的通用名称之一。
这可能导致你的 kubelet 和其他控制平面组件以及最终用户无法向
Kubernetes apiserver 认证。
因此,请对用于控制平面组件和最终用户鉴权的 --client-ca-file
选项和用于聚合 apiserver 鉴权的 --requestheader-client-ca-file
选项使用不同的 CA 证书。
除非你了解风险和保护 CA 用法的机制,否则不要重用在不同上下文中使用的 CA。
如果你未在运行 API 服务器的主机上运行 kube-proxy,则必须确保使用以下
kube-apiserver 标志启用系统:
--enable-aggregator-routing=true
你可以动态配置将哪些客户端请求代理到扩展 apiserver。以下是注册示例:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: <注释对象名称>
spec:
group: <扩展 Apiserver 的 API 组名>
version: <扩展 Apiserver 的 API 版本>
groupPriorityMinimum: <APIService 对应组的优先级, 参考 API 文档>
versionPriority: <版本在组中的优先排序, 参考 API 文档>
service:
namespace: <拓展 Apiserver 服务的名字空间>
name: <拓展 Apiserver 服务的名称>
caBundle: <PEM 编码的 CA 证书,用于对 Webhook 服务器的证书签名>
APIService 对象的名称必须是合法的路径片段名称。
一旦 Kubernetes apiserver 确定应将请求发送到扩展 apiserver, 它需要知道如何调用它。
service 部分是对扩展 apiserver 的服务的引用。
服务的名字空间和名字是必需的。端口是可选的,默认为 443。
下面是一个扩展 apiserver 的配置示例,它被配置为在端口 1234 上调用。
并针对 ServerName my-service-name.my-service-namespace.svc
使用自定义的 CA 包来验证 TLS 连接使用自定义 CA 捆绑包的
my-service-name.my-service-namespace.svc。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
...
spec:
...
service:
namespace: my-service-namespace
name: my-service-name
port: 1234
caBundle: "Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"
...
本页展示如何使用 CustomResourceDefinition 将定制资源(Custom Resource) 安装到 Kubernetes API 上。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.16. 要获知版本信息,请输入kubectl version.
如果你在使用较老的、仍处于被支持范围的 Kubernetes 版本, 请切换到该版本的文档查看对于你的集群而言有用的建议。
当你创建新的 CustomResourceDefinition(CRD)时,Kubernetes API 服务器会为你所指定的每个版本生成一个新的
RESTful 资源路径。
基于 CRD 对象所创建的自定义资源可以是名字空间作用域的,也可以是集群作用域的,
取决于 CRD 对象 spec.scope 字段的设置。
与其它的内置对象一样,删除名字空间也将删除该名字空间中的所有自定义对象。 CustomResourceDefinitions 本身是无名字空间的,可在所有名字空间中访问。
例如,如果你将下面的 CustomResourceDefinition 保存到 resourcedefinition.yaml
文件:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# 名字必需与下面的 spec 字段匹配,并且格式为 '<名称的复数形式>.<组名>'
name: crontabs.stable.example.com
spec:
# 组名称,用于 REST API: /apis/<组>/<版本>
group: stable.example.com
# 列举此 CustomResourceDefinition 所支持的版本
versions:
- name: v1
# 每个版本都可以通过 served 标志来独立启用或禁止
served: true
# 其中一个且只有一个版本必需被标记为存储版本
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL:/apis/<组>/<版本>/<名称的复数形式>
plural: crontabs
# 名称的单数形式,作为命令行使用时和显示时的别名
singular: crontab
# kind 通常是单数形式的驼峰命名(CamelCased)形式。你的资源清单会使用这一形式。
kind: CronTab
# shortNames 允许你在命令行使用较短的字符串来匹配资源
shortNames:
- ct
之后创建它:
kubectl apply -f resourcedefinition.yaml
这样一个新的受名字空间约束的 RESTful API 端点会被创建在:
/apis/stable.example.com/v1/namespaces/*/crontabs/...
此端点 URL 自此可以用来创建和管理定制对象。对象的 kind 将是来自你上面创建时
所用的 spec 中指定的 CronTab。
创建端点的操作可能需要几秒钟。你可以监测你的 CustomResourceDefinition 的
Established 状况变为 true,或者监测 API 服务器的发现信息等待你的资源出现在
那里。
在创建了 CustomResourceDefinition 对象之后,你可以创建定制对象(Custom
Objects)。定制对象可以包含定制字段。这些字段可以包含任意的 JSON 数据。
在下面的例子中,在类别为 CronTab 的定制对象中,设置了cronSpec 和 image
定制字段。类别 CronTab 来自你在上面所创建的 CRD 的规约。
如果你将下面的 YAML 保存到 my-crontab.yaml:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
并执行创建命令:
kubectl apply -f my-crontab.yaml
你就可以使用 kubectl 来管理你的 CronTab 对象了。例如:
kubectl get crontab
应该会输出如下列表:
NAME AGE
my-new-cron-object 6s
使用 kubectl 时,资源名称是大小写不敏感的,而且你既可以使用 CRD 中所定义的单数 形式或复数形式,也可以使用其短名称:
kubectl get ct -o yaml
你可以看到输出中包含了你创建定制对象时在 YAML 文件中指定的定制字段 cronSpec
和 image:
apiVersion: v1
items:
- apiVersion: stable.example.com/v1
kind: CronTab
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"stable.example.com/v1","kind":"CronTab","metadata":{"annotations":{},"name":"my-new-cron-object","namespace":"default"},"spec":{"cronSpec":"* * * * */5","image":"my-awesome-cron-image"}}
creationTimestamp: "2021-06-20T07:35:27Z"
generation: 1
name: my-new-cron-object
namespace: default
resourceVersion: "1326"
uid: 9aab1d66-628e-41bb-a422-57b8b3b1f5a9
spec:
cronSpec: '* * * * */5'
image: my-awesome-cron-image
kind: List
metadata:
resourceVersion: ""
selfLink: ""
当你删除某 CustomResourceDefinition 时,服务器会卸载其 RESTful API 端点,并删除服务器上存储的所有定制对象。
kubectl delete -f resourcedefinition.yaml
kubectl get crontabs
Error from server (NotFound): Unable to list {"stable.example.com" "v1" "crontabs"}: the server could not
find the requested resource (get crontabs.stable.example.com)
如果你在以后创建相同的 CustomResourceDefinition 时,该 CRD 会是一个空的结构。
CustomResource 对象在定制字段中保存结构化的数据,这些字段和内置的字段
apiVersion、kind 和 metadata 等一起存储,不过内置的字段都会被 API
服务器隐式完成合法性检查。有了 OpenAPI v3.0 检查
能力之后,你可以设置一个模式(Schema),在创建和更新定制对象时,这一模式会被用来
对对象内容进行合法性检查。参阅下文了解这类模式的细节和局限性。
在 apiextensions.k8s.io/v1 版本中,CustomResourceDefinition 的这一结构化模式
定义是必需的。
在 CustomResourceDefinition 的 beta 版本中,结构化模式定义是可选的。
结构化模式本身是一个 OpenAPI v3.0 验证模式,其中:
type),对每个
object 节点的每个字段(藉由 OpenAPI 中的 properties 或 additionalProperties)以及
array 节点的每个条目(藉由 OpenAPI 中的 items)也要设置非空的 type 值,
除非:
x-kubernetes-int-or-string: truex-kubernetes-preserve-unknown-fields: trueallOf、anyOf、oneOf
或 not,则模式也要指定这些逻辑组合之外的字段或条目(试比较例 1 和例 2)。allOf、anyOf、oneOf 或 not 上下文内不设置 description、type、default、
additionalProperties 或者 nullable。此规则的例外是
x-kubernetes-int-or-string 的两种模式(见下文)。metadata 被设置,则只允许对 metadata.name 和 metadata.generateName 设置约束。非结构化的例 1:
allOf:
- properties:
foo:
...
违反了第 2 条规则。下面的是正确的:
properties:
foo:
...
allOf:
- properties:
foo:
...
非结构化的例 2:
allOf:
- items:
properties:
foo:
...
违反了第 2 条规则。下面的是正确的:
items:
properties:
foo:
...
allOf:
- items:
properties:
foo:
...
非结构化的例 3:
properties:
foo:
pattern: "abc"
metadata:
type: object
properties:
name:
type: string
pattern: "^a"
finalizers:
type: array
items:
type: string
pattern: "my-finalizer"
anyOf:
- properties:
bar:
type: integer
minimum: 42
required: ["bar"]
description: "foo bar object"
不是一个结构化的模式,因为其中存在以下违例:
foo 的 type 缺失(规则 1)anyOf 中的 bar 未在外部指定(规则 2)bar 的 type 位于 anyOf 中(规则 3)anyOf 中设置了 description (规则 3)metadata.finalizers 不可以被限制 (规则 4)作为对比,下面的 YAML 所对应的模式则是结构化的:
type: object
description: "foo bar object"
properties:
foo:
type: string
pattern: "abc"
bar:
type: integer
metadata:
type: object
properties:
name:
type: string
pattern: "^a"
anyOf:
- properties:
bar:
minimum: 42
required: ["bar"]
如果违反了结构化模式规则,CustomResourceDefinition 的 NonStructural
状况中会包含报告信息。
CustomResourceDefinition 在集群的持久性存储 etcd 中保存经过合法性检查的资源数据。 就像原生的 Kubernetes 资源,例如 ConfigMap, 如果你指定了 API 服务器所无法识别的字段,则该未知字段会在保存资源之前被 剪裁(Pruned) 掉(删除)。
从 apiextensions.k8s.io/v1beta1 转换到 apiextensions.k8s.io/v1 的 CRD
可能没有结构化的模式定义,因此其 spec.preserveUnknownFields 可能为 true。
对于使用 apiextensions.k8s.io/v1beta1 且将 spec.preserveUnknownFields 设置为 true
创建的旧 CustomResourceDefinition 对象,有以下表现:
为了与 apiextensions.k8s.io/v1 兼容,将你的定制资源定义更新为:
spec.preserveUnknownFields 设置为 false。如果你将下面的 YAML 保存到 my-crontab.yaml 文件:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
someRandomField: 42
并创建之:
kubectl create --validate=false -f my-crontab.yaml -o yaml
输出类似于:
apiVersion: stable.example.com/v1
kind: CronTab
metadata:
creationTimestamp: 2017-05-31T12:56:35Z
generation: 1
name: my-new-cron-object
namespace: default
resourceVersion: "285"
uid: 9423255b-4600-11e7-af6a-28d2447dc82b
spec:
cronSpec: '* * * * */5'
image: my-awesome-cron-image
注意其中的字段 someRandomField 已经被剪裁掉。
本例中通过 --validate=false 命令行选项 关闭了客户端的合法性检查以展示 API 服务器的行为,
因为 OpenAPI 合法性检查模式也会发布到
客户端,kubectl 也会检查未知的字段并在对象被发送到 API
服务器之前就拒绝它们。
默认情况下,定制资源的所有版本中的所有未规定的字段都会被剪裁掉。
通过在结构化的 OpenAPI v3 检查模式定义
中为特定字段的子树添加 x-kubernetes-preserve-unknown-fields: true 属性,
可以选择不对其执行剪裁操作。
例如:
type: object
properties:
json:
x-kubernetes-preserve-unknown-fields: true
字段 json 可以保存任何 JSON 值,其中内容不会被剪裁掉。
你也可以部分地指定允许的 JSON 数据格式;例如:
type: object
properties:
json:
x-kubernetes-preserve-unknown-fields: true
type: object
description: this is arbitrary JSON
通过这样设置,JSON 中只能设置 object 类型的值。
对于所指定的每个属性(或 additionalProperties),剪裁会再次被启用。
type: object
properties:
json:
x-kubernetes-preserve-unknown-fields: true
type: object
properties:
spec:
type: object
properties:
foo:
type: string
bar:
type: string
对于上述定义,如果提供的数值如下:
json:
spec:
foo: abc
bar: def
something: x
status:
something: x
则该值会被剪裁为:
json:
spec:
foo: abc
bar: def
status:
something: x
这意味着所指定的 spec 对象中的 something 字段被剪裁掉,而其外部的内容都被保留。
模式定义中标记了 x-kubernetes-int-or-string: true 的节点不受前述规则 1
约束,因此下面的定义是结构化的模式:
type: object
properties:
foo:
x-kubernetes-int-or-string: true
此外,所有这类节点也不再受规则 3 约束,也就是说,下面两种模式是被允许的 (注意,仅限于这两种模式,不支持添加新字段的任何其他变种):
x-kubernetes-int-or-string: true
anyOf:
- type: integer
- type: string
...
和
x-kubernetes-int-or-string: true
allOf:
- anyOf:
- type: integer
- type: string
- ... # zero or more
...
在以上两种规约中,整数值和字符串值都会被认为是合法的。
在合法性检查模式定义的发布时,
x-kubernetes-int-or-string: true 会被展开为上述两种模式之一。
RawExtensions(就像在
k8s.io/apimachinery
项目中 runtime.RawExtension 所定义的那样)
可以保存完整的 Kubernetes 对象,也就是,其中会包含 apiVersion 和 kind
字段。
通过 x-kubernetes-embedded-resource: true 来设定这些嵌套对象的规约
(无论是完全无限制还是部分指定都可以)是可能的。例如:
type: object
properties:
foo:
x-kubernetes-embedded-resource: true
x-kubernetes-preserve-unknown-fields: true
这里,字段 foo 包含一个完整的对象,例如:
foo:
apiVersion: v1
kind: Pod
spec:
...
由于字段上设置了 x-kubernetes-preserve-unknown-fields: true,其中的内容不会
被剪裁。不过,在这个语境中,x-kubernetes-preserve-unknown-fields: true 的
使用是可选的。
设置了 x-kubernetes-embedded-resource: true 之后,apiVersion、kind 和
metadata 都是隐式设定并隐式完成合法性验证。
关于如何为你的 CustomResourceDefinition 提供多个版本的支持, 以及如何将你的对象从一个版本迁移到另一个版本, 详细信息可参阅 CustomResourceDefinition 的版本管理。
Finalizer 能够让控制器实现异步的删除前(Pre-delete)回调。 与内置对象类似,定制对象也支持 Finalizer。
你可以像下面一样为定制对象添加 Finalizer:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
finalizers:
- stable.example.com/finalizer
自定义 Finalizer 的标识符包含一个域名、一个正向斜线和 finalizer 的名称。 任何控制器都可以在任何对象的 finalizer 列表中添加新的 finalizer。
对带有 Finalizer 的对象的第一个删除请求会为其 metadata.deletionTimestamp
设置一个值,但不会真的删除对象。一旦此值被设置,finalizers 列表中的表项只能被移除。
在列表中仍然包含 finalizer 时,无法强制删除对应的对象。
当 metadata.deletionTimestamp 字段被设置时,监视该对象的各个控制器会执行它们所能处理的
finalizer,并在完成处理之后将其从列表中移除。
每个控制器负责将其 finalizer 从列表中删除。
metadata.deletionGracePeriodSeconds 的取值控制对更新的轮询周期。
一旦 finalizers 列表为空时,就意味着所有 finalizer 都被执行过, Kubernetes 会最终删除该资源,
定制资源是通过
OpenAPI v3 模式定义
来执行合法性检查的,当启用验证规则特性时,通过 x-kubernetes-validations 验证,
你可以通过使用准入控制 Webhook
来添加额外的合法性检查逻辑。
此外,对模式定义存在以下限制:
以下字段不可设置:
definitionsdependenciesdeprecateddiscriminatoridpatternPropertiesreadOnlywriteOnlyxml$ref字段 uniqueItems 不可设置为 true
字段 additionalProperties 不可设置为 false
字段 additionalProperties 与 properties 互斥,不可同时使用
当验证规则特性被启用并且 CustomResourceDefinition
模式是一个结构化的模式定义时,
x-kubernetes-validations
扩展可以使用通用表达式语言 (CEL)表达式来验证定制资源。
关于对某些 CustomResourceDefinition 特性所必需的限制, 可参见结构化的模式定义小节。
模式定义是在 CustomResourceDefinition 中设置的。在下面的例子中, CustomResourceDefinition 对定制对象执行以下合法性检查:
spec.cronSpec 必须是一个字符串,必须是正则表达式所描述的形式;spec.replicas 必须是一个整数,且其最小值为 1、最大值为 10。将此 CustomResourceDefinition 保存到 resourcedefinition.yaml 文件中:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
versions:
- name: v1
served: true
storage: true
schema:
# openAPIV3Schema 是验证自定义对象的模式。
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
pattern: '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
image:
type: string
replicas:
type: integer
minimum: 1
maximum: 10
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
并创建 CustomResourceDefinition:
kubectl apply -f resourcedefinition.yaml
对于一个创建 CronTab 类别对象的定制对象的请求而言,如果其字段中包含非法值,则 该请求会被拒绝。 在下面的例子中,定制对象中包含带非法值的字段:
spec.cronSpec 与正则表达式不匹配spec.replicas 数值大于 10。如果你将下面的 YAML 保存到 my-crontab.yaml:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * *"
image: my-awesome-cron-image
replicas: 15
并尝试创建定制对象:
kubectl apply -f my-crontab.yaml
你会看到下面的错误信息:
The CronTab "my-new-cron-object" is invalid: []: Invalid value: map[string]interface {}{"apiVersion":"stable.example.com/v1", "kind":"CronTab", "metadata":map[string]interface {}{"name":"my-new-cron-object", "namespace":"default", "deletionTimestamp":interface {}(nil), "deletionGracePeriodSeconds":(*int64)(nil), "creationTimestamp":"2017-09-05T05:20:07Z", "uid":"e14d79e7-91f9-11e7-a598-f0761cb232d1", "clusterName":""}, "spec":map[string]interface {}{"cronSpec":"* * * *", "image":"my-awesome-cron-image", "replicas":15}}:
validation failure list:
spec.cronSpec in body should match '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
spec.replicas in body should be less than or equal to 10
如果所有字段都包含合法值,则对象创建的请求会被接受。
将下面的 YAML 保存到 my-crontab.yaml 文件:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
replicas: 5
并创建定制对象:
kubectl apply -f my-crontab.yaml
crontab "my-new-cron-object" created
Kubernetes v1.28 [alpha]
你需要启用 CRDValidationRatcheting
特性门控,
才能使用这种行为,并将其应用到集群中的所有 CustomResourceDefinition。
只要你启用了此特性门控,Kubernetes 就会对 CustomResourceDefinition 实施验证逐步升级。 即使更新后的资源无效,API 服务器也愿意接受对资源的更新, 只要资源中未通过验证的每个部分都没有被更新操作改变。 换句话说,资源中任何无效的部分如果仍然无效,那它必须之前就是错误的。 你不能使用此机制来更新一个有效资源,使其变为无效。
此特性使得 CRD 的作者能够在某些条件下有信心地向 OpenAPIV3 模式定义中添加新的验证。 用户可以安全地更新到新的模式定义,而不必提升对象的版本或破坏工作流。
尽管大多数放在 CRD 的 OpenAPIV3 模式定义中的验证都支持逐步升级,仍存在一些例外。 Kubernetes 1.29 下实现的验证逐步升级不支持下面所列举的 OpenAPIV3 模式检查, 如果检查时发现违例,会和以往一样抛出错误:
allOfoneOfanyOfnotx-kubernetes-validations
在 Kubernetes 1.28 中,CRD 验证规则被逐步升级所忽略。
从 Kubernetes 1.29 的 Alpha 2 开始,x-kubernetes-validations 的检查也用逐步升级机制处理。
转换规则(Transition Rules)永远不会被逐步升级机制处理:只有那些不使用
oldSelf 的规则引发的错误会在其值未更改时自动按逐步升级机制处理。
x-kubernetes-list-type
更改子模式的列表类型引发的错误不会被逐步升级机制处理。
例如,在具有重复项的列表上添加 set 一定会出错。
x-kubernetes-map-keys
由于更改列表模式定义的映射键而引起的错误将不会被逐步升级机制处理。
required
由于更改必需字段列表而引起的错误将不会被逐步升级处理。
properties
添加、移除、修改属性的名称不会被逐步升级处理,但如果属性名称保持不变, 如果更改各属性的模式定义和子模式定义中的合法性检查规则,可能会被逐步升级机制处理。
additionalProperties
移除先前指定的 additionalProperties 合法性检查时,不会被逐步升级机制处理。
metadata
因更改对象的 metadata 中的字段而引起的错误不会被逐步升级机制处理。
Kubernetes v1.29 [stable]
验证规则使用通用表达式语言(CEL)来验证定制资源的值。
验证规则使用 x-kubernetes-validations 扩展包含在 CustomResourceDefinition 模式定义中。
规则的作用域是模式定义中 x-kubernetes-validations 扩展所在的位置。
CEL 表达式中的 self 变量被绑定到限定作用域的取值。
所有验证规则都是针对当前对象的:不支持跨对象或有状态的验证规则。
例如:
...
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-validations:
- rule: "self.minReplicas <= self.replicas"
message: "replicas should be greater than or equal to minReplicas."
- rule: "self.replicas <= self.maxReplicas"
message: "replicas should be smaller than or equal to maxReplicas."
properties:
...
minReplicas:
type: integer
replicas:
type: integer
maxReplicas:
type: integer
required:
- minReplicas
- replicas
- maxReplicas
将拒绝创建这个定制资源的请求:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
minReplicas: 0
replicas: 20
maxReplicas: 10
返回响应为:
The CronTab "my-new-cron-object" is invalid:
* spec: Invalid value: map[string]interface {}{"maxReplicas":10, "minReplicas":0, "replicas":20}: replicas should be smaller than or equal to maxReplicas.
x-kubernetes-validations 可以有多条规则。
x-kubernetes-validations 下的 rule 代表将由 CEL 评估的表达式。
message 代表验证失败时显示的信息。如果消息没有设置,上述响应将是:
The CronTab "my-new-cron-object" is invalid:
* spec: Invalid value: map[string]interface {}{"maxReplicas":10, "minReplicas":0, "replicas":20}: failed rule: self.replicas <= self.maxReplicas
当 CRD 被创建/更新时,验证规则被编译。 如果验证规则的编译失败,CRD 的创建/更新请求将失败。 编译过程也包括类型检查。
编译失败:
no_matching_overload:此函数没有参数类型的重载。
例如,像 self == true 这样的规则对一个整数类型的字段将得到错误:
Invalid value: apiextensions.ValidationRule{Rule:"self == true", Message:""}: compilation failed: ERROR: \<input>:1:6: found no matching overload for '_==_' applied to '(int, bool)'
no_such_field:不包含所需的字段。
例如,针对一个不存在的字段,像 self.nonExistingField > 0 这样的规则将返回错误:
Invalid value: apiextensions.ValidationRule{Rule:"self.nonExistingField > 0", Message:""}: compilation failed: ERROR: \<input>:1:5: undefined field 'nonExistingField'
invalid argument:对宏的无效参数。
例如,像 has(self) 这样的规则将返回错误:
Invalid value: apiextensions.ValidationRule{Rule:"has(self)", Message:""}: compilation failed: ERROR: <input>:1:4: invalid argument to has() macro
验证规则例子:
| 规则 | 目的 |
|---|---|
self.minReplicas <= self.replicas && self.replicas <= self.maxReplicas |
验证定义副本数的三个字段大小顺序是否正确 |
'Available' in self.stateCounts |
验证映射中是否存在键名为 Available的条目 |
(size(self.list1) == 0) != (size(self.list2) == 0) |
检查两个列表之一是非空的,但不是二者都非空 |
!('MY_KEY' in self.map1) || self['MY_KEY'].matches('^[a-zA-Z]*$') |
如果某个特定的键在映射中,验证映射中对应键的取值 |
self.envars.filter(e, e.name = 'MY_ENV').all(e, e.value.matches('^[a-zA-Z]*$') |
验证一个 listMap 中主键 'name' 为 'MY_ENV' 的表项的取值 |
has(self.expired) && self.created + self.ttl < self.expired |
验证 'Expired' 日期是否晚于 'Create' 日期加上 'ttl' 时长 |
self.health.startsWith('ok') |
验证 'health' 字符串字段有前缀 'ok' |
self.widgets.exists(w, w.key == 'x' && w.foo < 10) |
验证键为 'x' 的 listMap 项的 'foo' 属性是否小于 10 |
type(self) == string ? self == '100%' : self == 1000 |
在 int 型和 string 型两种情况下验证 int-or-string 字段 |
self.metadata.name.startsWith(self.prefix) |
验证对象的名称是否以另一个字段值为前缀 |
self.set1.all(e, !(e in self.set2)) |
验证两个 listSet 是否不相交 |
size(self.names) == size(self.details) && self.names.all(n, n in self.details) |
验证 'details' 映射中的 'names' 来自于 listSet |
size(self.clusters.filter(c, c.name == self.primary)) == 1 |
验证 'primary' 属性在 'clusters' listMap 中出现一次且只有一次 |
参考:CEL 中支持的求值
如果规则的作用域是某资源的根,则它可以对 CRD 的 OpenAPIv3 模式表达式中声明的任何字段进行字段选择,
以及 apiVersion、kind、metadata.name 和 metadata.generateName。
这包括在同一表达式中对 spec 和 status 的字段进行选择:
...
openAPIV3Schema:
type: object
x-kubernetes-validations:
- rule: "self.status.availableReplicas >= self.spec.minReplicas"
properties:
spec:
type: object
properties:
minReplicas:
type: integer
...
status:
type: object
properties:
availableReplicas:
type: integer
如果规则的作用域是具有属性的对象,那么可以通过 self.field 对该对象的可访问属性进行字段选择,
而字段存在与否可以通过 has(self.field) 来检查。
在 CEL 表达式中,Null 值的字段被视为不存在的字段。
...
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-validations:
- rule: "has(self.foo)"
properties:
...
foo:
type: integer
如果规则的作用域是一个带有 additionalProperties 的对象(即map),那么 map 的值
可以通过 self[mapKey] 访问,map 的包含性可以通过 mapKey in self 检查,
map 中的所有条目可以通过 CEL 宏和函数如 self.all(...) 访问。
...
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-validations:
- rule: "self['xyz'].foo > 0"
additionalProperties:
...
type: object
properties:
foo:
type: integer
如果规则的作用域是 array,则 array 的元素可以通过 self[i] 访问,也可以通过宏和函数访问。
...
openAPIV3Schema:
type: object
properties:
...
foo:
type: array
x-kubernetes-validations:
- rule: "size(self) == 1"
items:
type: string
如果规则的作用域为标量,则 self 将绑定到标量值。
...
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
...
foo:
type: integer
x-kubernetes-validations:
- rule: "self > 0"
例子:
| 规则作用域字段类型 | 规则示例 |
|---|---|
| 根对象 | self.status.actual <= self.spec.maxDesired |
| 对象映射 | self.components['Widget'].priority < 10 |
| 整数列表 | self.values.all(value, value >= 0 && value < 100) |
| 字符串 | self.startsWith('kube') |
apiVersion、kind、metadata.name 和 metadata.generateName
始终可以从对象的根目录和任何带有 x-kubernetes-embedded-resource 注解的对象访问。
其他元数据属性都不可访问。
通过 x-kubernetes-preserve-unknown-fields 保存在定制资源中的未知数据在 CEL 表达中无法访问。
这包括:
使用 x-kubernetes-preserve-unknown-fields 的对象模式保留的未知字段值。
属性模式为"未知类型(Unknown Type)"的对象属性。一个"未知类型"被递归定义为:
x-kubernetes-preserve-unknown-fields 设置为 true。只有 [a-zA-Z_.-/][a-zA-Z0-9_.-/]* 形式的属性名是可访问的。
当在表达式中访问时,可访问的属性名称会根据以下规则进行转义:
| 转义序列 | 属性名称等效为 |
|---|---|
__underscores__ |
__ |
__dot__ |
. |
__dash__ |
- |
__slash__ |
/ |
__{keyword}__ |
CEL 保留关键字 |
注意:CEL 保留关键字需要与要转义的确切属性名匹配(例如,单词 sprint 中的 int 不会转义)。
转义的例子:
| 属性名 | 转义属性名规则 |
|---|---|
| namespace | self.__namespace__ > 0 |
| x-prop | self.x__dash__prop > 0 |
| redact__d | self.redact__underscores__d > 0 |
| string | self.startsWith('kube') |
set 或 map 的 x-Kubernetes-list-type 的数组的等值比较会忽略元素顺序,即 [1,2] == [2,1]。
使用 x-kubernetes-list-type 对数组进行串联时,使用 List 类型的语义:
set:X + Y 执行一个并集操作,其中 X 中所有元素的数组位置被保留,
Y 中不相交的元素被追加,保留其部分顺序。
map:X + Y执行合并,其中 X 中所有键的数组位置被保留,
但当 X 和 Y 的键集相交时,其值被 Y 中的值覆盖。
Y 中键值不相交的元素被附加,保留其部分顺序。
以下是 OpenAPIV3 和 CEL 类型之间的声明类型映射:
| OpenAPIv3 类型 | CEL 类型 |
|---|---|
| 带有 Properties 的对象 | 对象 / "消息类型" |
| 带有 AdditionalProperties 的对象 | map |
| 带有 x-kubernetes-embedded-type 的对象 | 对象 / "消息类型",'apiVersion'、'kind'、'metadata.name' 和 'metadata.generateName' 都隐式包含在模式中 |
| 带有 x-kubernetes-preserve-unknown-fields 的对象 | 对象 / "消息类型",未知字段无法从 CEL 表达式中访问 |
| x-kubernetes-int-or-string | 可能是整数或字符串的动态对象,可以用 type(value) 来检查类型 |
| 数组 | list |
| 带有 x-kubernetes-list-type=map 的数组 | 列表,基于集合等值和唯一键名保证的 map 组成 |
| 带有 x-kubernetes-list-type=set 的数组 | 列表,基于集合等值和唯一键名保证的 set 组成 |
| 布尔值 | boolean |
| 数字 (各种格式) | double |
| 整数 (各种格式) | int (64) |
| 'null' | null_type |
| 字符串 | string |
| 带有 format=byte (base64 编码)字符串 | bytes |
| 带有 format=date 字符串 | timestamp (google.protobuf.Timestamp) |
| 带有 format=datetime 字符串 | timestamp (google.protobuf.Timestamp) |
| 带有 format=duration 字符串 | duration (google.protobuf.Duration) |
参考:CEL 类型、 OpenAPI 类型、 Kubernetes 结构化模式。
messageExpression 字段 message 字段定义因验证规则失败时提示的字符串,与它类似,
messageExpression 允许你使用 CEL 表达式构造消息字符串。
这使你可以在验证失败消息中插入更详细的信息。messageExpression
必须计算为字符串,并且可以使用在 rule 字段中可用的变量。
例如:
x-kubernetes-validations:
- rule: "self.x <= self.maxLimit"
messageExpression: '"x exceeded max limit of " + string(self.maxLimit)'
请记住,CEL 字符串连接(+ 运算符)不会自动转换为字符串。
如果你有一个非字符串标量,请使用 string(<value>) 函数将标量转换为字符串,如上例所示。
messageExpression 必须计算为一个字符串,并且在编写 CRD 时进行检查。
请注意,可以在同一个规则上设置 message 和 messageExpression,如果两者都存在,则将使用 messageExpression。
但是,如果 messageExpression 计算出错,则将使用 message 中定义的字符串,而 messageExpression 的错误将被打印到日志。
如果在 messageExpression 中定义的 CEL 表达式产生一个空字符串或包含换行符的字符串,也会发生这种回退。
如果满足上述条件之一且未设置 message 字段,则将使用默认的检查失败消息。
messageExpression 是一个 CEL 表达式,
因此验证函数的资源使用中所列出的限制也适用于它。
如果在 messageExpression 执行期间由于资源限制而导致计算停止,则不会继续处理其他合法性检查规则。
messageExpression 设置是可选的。
message 字段 如果你要设置一个静态消息,可以提供 message 而不是 messageExpression。
如果合法性检查失败,则 message 的值将被用作不透明的错误字符串。
message 设置是可选的。
reason 字段 你可以在 validation 中添加一个机器可读的验证失败原因,以便在请求未通过此验证规则时返回。
例如:
x-kubernetes-validations:
- rule: "self.x <= self.maxLimit"
reason: "FieldValueInvalid"
返回给调用者的 HTTP 状态码将与第一个失败的验证规则的原因匹配。 目前支持的原因有:"FieldValueInvalid"、"FieldValueForbidden"、"FieldValueRequired"、"FieldValueDuplicate"。 如果未设置或原因未知,默认使用 "FieldValueInvalid"。
reason 设置是可选的。
fieldPath 字段 你可以指定在验证失败时返回的字段路径。
例如:
x-kubernetes-validations:
- rule: "self.foo.test.x <= self.maxLimit"
fieldPath: ".foo.test.x"
在上面的示例中,验证检查字段 x 的值应小于 maxLimit 的值。
如果未指定 fieldPath,当验证失败时,fieldPath 将默认为 self 的作用范围。
如果指定了 fieldPath,返回的错误将正确地将 fieldPath 指向字段 x 的位置。
fieldPath 值必须是相对 JSON 路径,且限定为此 x-kubernetes-validations 扩展在模式定义中的位置。
此外,它应该指向模式定义中的一个现有字段。例如,当验证检查 testMap 映射下的特定属性 foo 时,
你可以将 fieldPath 设置为 ".testMap.foo" 或 .testMap['foo']'。
如果验证要求检查两个列表中的唯一属性,fieldPath 可以设置为其中一个列表。
例如,它可以设置为 .testList1 或 .testList2。它目前支持引用现有字段的取子操作。
更多信息请参阅 Kubernetes 中的 JSONPath 支持。
fieldPath 字段不支持按数字下表索引数组。
fieldPath 设置是可选的。
optionalOldSelf 字段 Kubernetes v1.29 [alpha]
要使用此字段,必须启用特性 CRDValidationRatcheting。
optionalOldSelf 字段是一个布尔字段,它会改变下文所述的转换规则的行为。
通常,在对象创建期间或在更新中引入新值时,如果无法确定 oldSelf,则不会处理转换规则。
如果 optionalOldSelf 设置为 true,则一定会处理转换规则,并且 oldSelf 的类型会被更改为
CEL Optional 类型。
optionalOldSelf 在以下情况下很有用,
模式的作者希望拥有比默认的基于相等性的行为的控制力更强的工具,
以便对新值引入更严格的约束,同时仍允许旧值通过旧的验证进行 "grandfathered"(溯源)或作逐步升级处理。
示例用法:
| CEL | 描述 |
|---|---|
| `self.foo == "foo" | |
| [oldSelf.orValue(""), self].all(x, ["OldCase1", "OldCase2"].exists(case, x == case)) | |
| oldSelf.optMap(o, o.size()).orValue(0) < 4 |
可用的函数包括:
包含引用标识符 oldSself 的表达式的规则被隐式视为 转换规则(Transition Rule)。
转换规则允许模式作者阻止两个原本有效的状态之间的某些转换。例如:
type: string
enum: ["low", "medium", "high"]
x-kubernetes-validations:
- rule: "!(self == 'high' && oldSelf == 'low') && !(self == 'low' && oldSelf == 'high')"
message: cannot transition directly between 'low' and 'high'
与其他规则不同,转换规则仅适用于满足以下条件的操作:
spec.foo[10].bar)不一定能在现有对象和后来对同一对象的更新之间产生关联。如果一个模式节点包含一个永远不能应用的转换规则,在 CRD 写入时将会产生错误,例如: "path: update rule rule cannot be set on schema because the schema or its parent schema is not mergeable"。
转换规则只允许在模式的 可关联部分(Correlatable Portions) 中使用。
如果所有 array 父模式都是 x-kubernetes-list-type=map类型的,那么该模式的一部分就是可关联的;
任何 set 或者 atomic 数组父模式都不支持确定性地将 self 与 oldSelf 关联起来。
这是一些转换规则的例子:
| 用例 | 规则 |
|---|---|
| 不可变 | self.foo == oldSelf.foo |
| 赋值后禁止修改/删除 | oldSelf != 'bar' || self == 'bar' or !has(oldSelf.field) || has(self.field) |
| 仅附加的 set | self.all(element, element in oldSelf) |
| 如果之前的值为 X,则新值只能为 A 或 B,不能为 Y 或 Z | oldSelf != 'X' || self in ['A', 'B'] |
| 单调(非递减)计数器 | self >= oldSelf |
当你创建或更新一个使用验证规则的 CustomResourceDefinition 时, API 服务器会检查运行这些验证规则可能产生的影响。 如果一个规则的执行成本过高,API 服务器会拒绝创建或更新操作,并返回一个错误信息。
运行时也使用类似的系统来观察解释器的行动。如果解释器执行了太多的指令,规则的执行将被停止,并且会产生一个错误。
每个 CustomResourceDefinition 也被允许有一定数量的资源来完成其所有验证规则的执行。 如果在创建时估计其规则的总和超过了这个限制,那么也会发生验证错误。
如果你只指定那些无论输入量有多大都要花费相同时间的规则,你不太可能遇到验证的资源预算问题。
例如,一个断言 self.foo == 1 的规则本身不存在因为资源预算组验证而导致被拒绝的风险。
但是,如果 foo 是一个字符串,而你定义了一个验证规则 self.foo.contains("someString"),
这个规则需要更长的时间来执行,取决于 foo 有多长。
另一个例子是如果 foo 是一个数组,而你指定了验证规则 self.foo.all(x, x > 5)。
如果没有给出 foo 的长度限制,成本系统总是假设最坏的情况,这将发生在任何可以被迭代的事物上(list、map 等)。
因此,通过 maxItems,maxProperties 和 maxLength 进行限制被认为是最佳实践,
以在验证规则中处理任何内容,以防止在成本估算期间验证错误。例如,给定具有一个规则的模式:
openAPIV3Schema:
type: object
properties:
foo:
type: array
items:
type: string
x-kubernetes-validations:
- rule: "self.all(x, x.contains('a string'))"
API 服务器以验证预算为由拒绝该规则,并显示错误:
spec.validation.openAPIV3Schema.properties[spec].properties[foo].x-kubernetes-validations[0].rule: Forbidden:
CEL rule exceeded budget by more than 100x (try simplifying the rule, or adding maxItems, maxProperties, and
maxLength where arrays, maps, and strings are used)
这个拒绝会发生是因为 self.all 意味着对 foo 中的每一个字符串调用 contains(),
而这又会检查给定的字符串是否包含 'a string'。如果没有限制,这是一个非常昂贵的规则。
如果你不指定任何验证限制,这个规则的估计成本将超过每条规则的成本限制。 但如果你在适当的地方添加限制,该规则将被允许:
openAPIV3Schema:
type: object
properties:
foo:
type: array
maxItems: 25
items:
type: string
maxLength: 10
x-kubernetes-validations:
- rule: "self.all(x, x.contains('a string'))"
成本评估系统除了考虑规则本身的估计成本外,还考虑到规则将被执行的次数。 例如,下面这个规则的估计成本与前面的例子相同(尽管该规则现在被定义在单个数组项上):
openAPIV3Schema:
type: object
properties:
foo:
type: array
maxItems: 25
items:
type: string
x-kubernetes-validations:
- rule: "self.contains('a string'))"
maxLength: 10
如果在一个列表内部的一个列表有一个使用 self.all 的验证规则,那就会比具有相同规则的非嵌套列表的成本高得多。
一个在非嵌套列表中被允许的规则可能需要在两个嵌套列表中设置较低的限制才能被允许。
例如,即使没有设置限制,下面的规则也是允许的:
openAPIV3Schema:
type: object
properties:
foo:
type: array
items:
type: integer
x-kubernetes-validations:
- rule: "self.all(x, x == 5)"
但是同样的规则在下面的模式中(添加了一个嵌套数组)产生了一个验证错误:
openAPIV3Schema:
type: object
properties:
foo:
type: array
items:
type: array
items:
type: integer
x-kubernetes-validations:
- rule: "self.all(x, x == 5)"
这是因为 foo 的每一项本身就是一个数组,而每一个子数组依次调用 self.all。
在使用验证规则的地方,尽可能避免嵌套的列表和字典。
要使用设置默认值功能,你的 CustomResourceDefinition 必须使用 API 版本 apiextensions.k8s.io/v1。
设置默认值的功能允许在 OpenAPI v3 合法性检查模式定义中设置默认值:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
versions:
- name: v1
served: true
storage: true
schema:
# openAPIV3Schema 是用来检查定制对象的模式定义
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
pattern: '^(\d+|\*)(/\d+)?(\s+(\d+|\*)(/\d+)?){4}$'
default: "5 0 * * *"
image:
type: string
replicas:
type: integer
minimum: 1
maximum: 10
default: 1
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
使用此 CRD 定义时,cronSpec 和 replicas 都会被设置默认值:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
image: my-awesome-cron-image
会生成:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "5 0 * * *"
image: my-awesome-cron-image
replicas: 1
默认值设定的行为发生在定制对象上:
从 etcd 中读取数据时所应用的默认值设置不会被写回到 etcd 中。 需要通过 API 执行更新请求才能将这种方式设置的默认值写回到 etcd。
默认值一定会被剪裁(除了 metadata 字段的默认值设置),且必须通过所提供的模式定义的检查。
针对 x-kubernetes-embedded-resource: true 节点(或者包含 metadata 字段的结构的默认值)
的 metadata 字段的默认值设置不会在 CustomResourceDefinition 创建时被剪裁,
而是在处理请求的字段剪裁阶段被删除。
对于未设置其 nullable 标志的字段或者将该标志设置为 false 的字段,其空值(Null)
会在设置默认值之前被剪裁掉。如果对应字段存在默认值,则默认值会被赋予该字段。
当 nullable 被设置为 true 时,字段的空值会被保留,且不会在设置默认值时被覆盖。
例如,给定下面的 OpenAPI 模式定义:
type: object
properties:
spec:
type: object
properties:
foo:
type: string
nullable: false
default: "default"
bar:
type: string
nullable: true
baz:
type: string
像下面这样创建一个为 foo、bar 和 baz 设置空值的对象时:
spec:
foo: null
bar: null
baz: null
其结果会是这样:
spec:
foo: "default"
bar: null
其中的 foo 字段被剪裁掉并重新设置默认值,因为该字段是不可为空的。
bar 字段的 nullable: true 使得其能够保有其空值。
baz 字段则被完全剪裁掉,因为该字段是不可为空的,并且没有默认值设置。
CustomResourceDefinition 的结构化的、 启用了剪裁的 OpenAPI v3 合法性检查模式会在 Kubernetes API 服务器上作为 OpenAPI 3 和 OpenAPI v2 发布出来。建议使用 OpenAPI v3 文档,因为它是 CustomResourceDefinition OpenAPI v3 验证模式的无损表示,而 OpenAPI v2 表示有损转换。
kubectl 命令行工具会基于所发布的模式定义来执行客户端的合法性检查
(kubectl create 和 kubectl apply),为定制资源的模式定义提供解释(kubectl explain)。
所发布的模式还可被用于其他目的,例如生成客户端或者生成文档。
为了与 OpenAPI V2 兼容,OpenAPI v3 验证模式会对 OpenAPI v2 模式进行有损转换。
该模式显示在 OpenAPI v2 规范中的
definitions 和 paths 字段中。
OpenAPI v3 合法性检查模式定义会被转换为 OpenAPI v2 模式定义,并出现在
OpenAPI v2 规范的
definitions 和 paths 字段中。
在转换过程中会发生以下修改,目的是保持与 1.13 版本以前的 kubectl 工具兼容。 这些修改可以避免 kubectl 过于严格,以至于拒绝它无法理解的 OpenAPI 模式定义。 转换过程不会更改 CRD 中定义的合法性检查模式定义,因此不会影响到 API 服务器中的合法性检查。
以下字段会被移除,因为它们在 OpenAPI v2 中不支持。
allOf、anyOf、oneOf 和 not 会被删除如果设置了 nullable: true,我们会丢弃 type、nullable、items 和 properties
OpenAPI v2 无法表达 Nullable。为了避免 kubectl 拒绝正常的对象,这一转换是必要的。
kubectl 工具依赖服务器端的输出格式化。你的集群的 API 服务器决定 kubectl get 命令要显示的列有哪些。
你可以为 CustomResourceDefinition 定制这些要打印的列。
下面的例子添加了 Spec、Replicas 和 Age 列:
将此 CustomResourceDefinition 保存到 resourcedefinition.yaml 文件:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
additionalPrinterColumns:
- name: Spec
type: string
description: The cron spec defining the interval a CronJob is run
jsonPath: .spec.cronSpec
- name: Replicas
type: integer
description: The number of jobs launched by the CronJob
jsonPath: .spec.replicas
- name: Age
type: date
jsonPath: .metadata.creationTimestamp
创建 CustomResourceDefinition:
kubectl apply -f resourcedefinition.yaml
使用前文中的 my-crontab.yaml 创建一个实例。
启用服务器端打印输出:
kubectl get crontab my-new-cron-object
注意输出中的 NAME、SPEC、REPLICAS 和 AGE 列:
NAME SPEC REPLICAS AGE
my-new-cron-object * * * * * 1 7s
NAME 列是隐含的,不需要在 CustomResourceDefinition 中定义。
每个列都包含一个 priority(优先级)字段。当前,优先级用来区分标准视图(Standard
View)和宽视图(Wide View)(使用 -o wide 标志)中显示的列:
0 的列会在标准视图中显示。0 的列只会在宽视图中显示。列的 type 字段可以是以下值之一
(比较 OpenAPI v3 数据类型):
integer – 非浮点数字number – 浮点数字string – 字符串boolean – true 或 falsedate – 显示为以自此时间戳以来经过的时长如果定制资源中的值与列中指定的类型不匹配,该值会被忽略。 你可以通过定制资源的合法性检查来确保取值类型是正确的。
列的 format 字段可以是以下值之一:
int32int64floatdoublebytedatedate-timepassword列的 format 字段控制 kubectl 打印对应取值时采用的风格。
定制资源支持 /status 和 /scale 子资源。
通过在 CustomResourceDefinition 中定义 status 和 scale,
可以有选择地启用这些子资源。
当启用了 status 子资源时,对应定制资源的 /status 子资源会被暴露出来。
status 和 spec 内容分别用定制资源内的 .status 和 .spec JSON 路径来表达;
对 /status 子资源的 PUT 请求要求使用定制资源对象作为其输入,但会忽略
status 之外的所有内容。
对 /status 子资源的 PUT 请求仅对定制资源的 status 内容进行合法性检查。
对定制资源的 PUT、POST、PATCH 请求会忽略 status 内容的改变。
对所有变更请求,除非改变是针对 .metadata 或 .status,.metadata.generation
的取值都会增加。
在 CRD OpenAPI 合法性检查模式定义的根节点,只允许存在以下结构:
descriptionexampleexclusiveMaximumexclusiveMinimumexternalDocsformatitemsmaximummaxItemsmaxLengthminimumminItemsminLengthmultipleOfpatternpropertiesrequiredtitletypeuniqueItems当启用了 scale 子资源时,定制资源的 /scale 子资源就被暴露出来。
针对 /scale 所发送的对象是 autoscaling/v1.Scale。
为了启用 scale 子资源,CustomResourceDefinition 定义了以下字段:
specReplicasPath 指定定制资源内与 scale.spec.replicas 对应的 JSON 路径。
.spec 下的 JSON 路径,只可使用带句点的路径。specReplicasPath 下没有取值,则针对 /scale 子资源执行 GET
操作时会返回错误。statusReplicasPath 指定定制资源内与 scale.status.replicas 对应的 JSON 路径。
.status 下的 JSON 路径,只可使用带句点的路径。statusReplicasPath 下没有取值,则针对 /scale
子资源的副本个数状态值默认为 0。labelSelectorPath 指定定制资源内与 Scale.Status.Selector 对应的 JSON 路径。
.status 或 .spec 下的 JSON 路径,只可使用带句点的路径。labelSelectorPath 下没有取值,则针对 /scale
子资源的选择算符状态值默认为空字符串。在下面的例子中,status 和 scale 子资源都被启用。
将此 CustomResourceDefinition 保存到 resourcedefinition.yaml 文件:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
status:
type: object
properties:
replicas:
type: integer
labelSelector:
type: string
# subresources 描述定制资源的子资源
subresources:
# status 启用 status 子资源
status: {}
# scale 启用 scale 子资源
scale:
# specReplicasPath 定义定制资源中对应 scale.spec.replicas 的 JSON 路径
specReplicasPath: .spec.replicas
# statusReplicasPath 定义定制资源中对应 scale.status.replicas 的 JSON 路径
statusReplicasPath: .status.replicas
# labelSelectorPath 定义定制资源中对应 scale.status.selector 的 JSON 路径
labelSelectorPath: .status.labelSelector
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
之后创建此 CustomResourceDefinition:
kubectl apply -f resourcedefinition.yaml
CustomResourceDefinition 对象创建完毕之后,你可以创建定制对象,。
如果你将下面的 YAML 保存到 my-crontab.yaml 文件:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
replicas: 3
并创建定制对象:
kubectl apply -f my-crontab.yaml
那么会创建新的、命名空间作用域的 RESTful API 端点:
/apis/stable.example.com/v1/namespaces/*/crontabs/status
和
/apis/stable.example.com/v1/namespaces/*/crontabs/scale
定制资源可以使用 kubectl scale 命令来扩缩其规模。
例如下面的命令将前面创建的定制资源的 .spec.replicas 设置为 5:
kubectl scale --replicas=5 crontabs/my-new-cron-object
crontabs "my-new-cron-object" scaled
kubectl get crontabs my-new-cron-object -o jsonpath='{.spec.replicas}'
5
你可以使用 PodDisruptionBudget 来保护启用了 scale 子资源的定制资源。
分类(Categories)是定制资源所归属的分组资源列表(例如,all)。
你可以使用 kubectl get <分类名称> 来列举属于某分类的所有资源。
下面的示例在 CustomResourceDefinition 中将 all 添加到分类列表中,
并展示了如何使用 kubectl get all 来输出定制资源:
将下面的 CustomResourceDefinition 保存到 resourcedefinition.yaml 文件中:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: crontabs.stable.example.com
spec:
group: stable.example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
scope: Namespaced
names:
plural: crontabs
singular: crontab
kind: CronTab
shortNames:
- ct
# categories 是定制资源所归属的分类资源列表
categories:
- all
之后创建此 CRD:
kubectl apply -f resourcedefinition.yaml
创建了 CustomResourceDefinition 对象之后,你可以创建定制对象。
将下面的 YAML 保存到 my-crontab.yaml 中:
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
并创建定制对象:
kubectl apply -f my-crontab.yaml
你可以在使用 kubectl get 时指定分类:
kubectl get all
输出中将包含类别为 CronTab 的定制资源:
NAME AGE
crontabs/my-new-cron-object 3s
本页介绍如何添加版本信息到 CustomResourceDefinitions。 目的是标明 CustomResourceDefinitions 的稳定级别或者服务于 API 升级。 API 升级时需要在不同 API 表示形式之间进行转换。 本页还描述如何将对象从一个版本升级到另一个版本。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你应该对定制资源有一些初步了解。
你的 Kubernetes 服务器版本必须不低于版本 v1.16. 要获知版本信息,请输入kubectl version.
CustomResourceDefinition API 提供了引入和升级 CustomResourceDefinition 新版本所用的工作流程。
创建 CustomResourceDefinition 时,会在 CustomResourceDefinition spec.versions
列表设置适当的稳定级别和版本号。例如,v1beta1 表示第一个版本尚未稳定。
所有定制资源对象将首先用这个版本保存。
创建 CustomResourceDefinition 后,客户端可以开始使用 v1beta1 API。
稍后可能需要添加新版本,例如 v1。
添加新版本:
None 转换策略,为不同版本提供服务时只有 apiVersion 字段会被改变。served:true,加入到
spec.versions 列表。另外,还要设置 spec.conversion 字段为所选的转换策略。
如果使用转换 Webhook,请配置 spec.conversion.webhookClientConfig 来调用 Webhook。添加新版本后,客户端可以逐步迁移到新版本。 让某些客户使用旧版本的同时支持其他人使用新版本是相当安全的。
将存储的对象迁移到新版本:
请参阅将现有对象升级到新的存储版本节。
对于客户来说,在将对象升级到新的存储版本之前、期间和之后使用旧版本和新版本都是安全的。
删除旧版本:
spec.versions 列表中将旧版本的 served 设置为 false。
如果仍有客户端意外地使用旧版本,他们可能开始会报告采用旧版本尝试访问定制资源的错误消息。
如果发生这种情况,请将旧版本的 served:true 恢复,然后迁移余下的客户端使用新版本,然后重复此步骤。spec.versions 列表中,确认新版本的
storage 已被设置为 true。status.storedVersions 中。spec.versions 列表中删除旧版本。CustomResourceDefinition API 的 versions 字段可用于支持你所开发的定制资源的多个版本。
版本可以具有不同的模式,并且转换 Webhook 可以在多个版本之间转换定制资源。
在适当的情况下,Webhook 转换应遵循
Kubernetes API 约定。
具体来说,请查阅
API 变更文档
以获取一些有用的问题和建议。
在 apiextensions.k8s.io/v1beta1 版本中曾经有一个 version 字段,
名字不叫做 versions。该 version 字段已经被废弃,成为可选项。
不过如果该字段不是空,则必须与 versions 字段中的第一个条目匹配。
下面的示例显示了两个版本的 CustomResourceDefinition。 第一个例子中假设所有的版本使用相同的模式而它们之间没有转换。 YAML 中的注释提供了更多背景信息。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name 必须匹配后面 spec 中的字段,且使用格式 <plural>.<group>
name: crontabs.example.com
spec:
# 组名,用于 REST API: /apis/<group>/<version>
group: example.com
# 此 CustomResourceDefinition 所支持的版本列表
versions:
- name: v1beta1
# 每个 version 可以通过 served 标志启用或禁止
served: true
# 有且只能有一个 version 必须被标记为存储版本
storage: true
# schema 是必需字段
schema:
openAPIV3Schema:
type: object
properties:
host:
type: string
port:
type: string
- name: v1
served: true
storage: false
schema:
openAPIV3Schema:
type: object
properties:
host:
type: string
port:
type: string
# conversion 节是 Kubernetes 1.13+ 版本引入的,其默认值为无转换,即 strategy 子字段设置为 None。
conversion:
# None 转换假定所有版本采用相同的模式定义,仅仅将定制资源的 apiVersion 设置为合适的值.
strategy: None
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL: /apis/<group>/<version>/<plural>
plural: crontabs
# 名称的单数形式,用于在命令行接口和显示时作为其别名
singular: crontab
# kind 通常是驼峰编码(CamelCased)的单数形式,用于资源清单中
kind: CronTab
# shortNames 允许你在命令行接口中使用更短的字符串来匹配你的资源
shortNames:
- ct
# 在 v1.16 中被弃用以推荐使用 apiextensions.k8s.io/v1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
# name 必须匹配后面 spec 中的字段,且使用格式 <plural>.<group>
name: crontabs.example.com
spec:
# 组名,用于 REST API: /apis/<group>/<version>
group: example.com
# 此 CustomResourceDefinition 所支持的版本列表
versions:
- name: v1beta1
# 每个 version 可以通过 served 标志启用或禁止
served: true
# 有且只能有一个 version 必须被标记为存储版本
storage: true
- name: v1
served: true
storage: false
validation:
openAPIV3Schema:
type: object
properties:
host:
type: string
port:
type: string
# conversion 节是 Kubernetes 1.13+ 版本引入的,其默认值为无转换,即 strategy 子字段设置为 None。
conversion:
# None 转换假定所有版本采用相同的模式定义,仅仅将定制资源的 apiVersion 设置为合适的值.
strategy: None
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL: /apis/<group>/<version>/<plural>
plural: crontabs
# 名称的单数形式,用于在命令行接口和显示时作为其别名
singular: crontab
# kind 通常是大驼峰编码(PascalCased)的单数形式,用于资源清单中
kind: CronTab
# shortNames 允许你在命令行接口中使用更短的字符串来匹配你的资源
shortNames:
- ct
你可以将 CustomResourceDefinition 存储在 YAML 文件中,然后使用
kubectl apply 来创建它。
kubectl apply -f my-versioned-crontab.yaml
在创建之后,API 服务器开始在 HTTP REST 端点上为每个已启用的版本提供服务。
在上面的示例中,API 版本可以在 /apis/example.com/v1beta1 和
/apis/example.com/v1 处获得。
不考虑 CustomResourceDefinition 中版本被定义的顺序,kubectl 使用具有最高优先级的版本作为访问对象的默认版本。 优先级是通过解析 name 字段来确定版本号、稳定性(GA、Beta 或 Alpha) 以及该稳定性级别内的序列。
用于对版本进行排序的算法在设计上与 Kubernetes 项目对 Kubernetes 版本进行排序的方式相同。
版本以 v 开头跟一个数字,一个可选的 beta 或者 alpha 和一个可选的附加数字作为版本信息。
从广义上讲,版本字符串可能看起来像 v2 或者 v2beta1。
使用以下算法对版本进行排序:
beta 或 alpha,它们首先按去掉 beta 或
alpha 之后的版本号排序(相当于 GA 版本),之后按 beta 先、alpha 后的顺序排序,beta 或 alpha 之后还有另一个数字,那么也会针对这些数字从大到小排序。foo1 排在 foo10 之前。
这与遵循 Kubernetes 版本模式的条目的数字部分排序不同。如果查看以下版本排序列表,这些规则就容易懂了:
- v10
- v2
- v1
- v11beta2
- v10beta3
- v3beta1
- v12alpha1
- v11alpha2
- foo1
- foo10
对于指定多个版本中的示例,版本排序顺序为
v1,后跟着 v1beta1。
这导致了 kubectl 命令使用 v1 作为默认版本,除非所提供的对象指定了版本。
Kubernetes v1.19 [stable]
从 v1.19 开始,CustomResourceDefinition 可以指示其定义的资源的特定版本已废弃。 当该资源的已废弃版本发出 API 请求时,会在 API 响应中以报头的形式返回警告消息。 如果需要,可以自定义每个不推荐使用的资源版本的警告消息。
定制的警告消息应该标明废弃的 API 组、版本和类别(kind), 并且应该标明应该使用(如果有的话)哪个 API 组、版本和类别作为替代。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
name: crontabs.example.com
spec:
group: example.com
names:
plural: crontabs
singular: crontab
kind: CronTab
scope: Namespaced
versions:
- name: v1alpha1
served: true
storage: false
# 此属性标明此定制资源的 v1alpha1 版本已被弃用。
# 发给此版本的 API 请求会在服务器响应中收到警告消息头。
deprecated: true
# 此属性设置用来覆盖返回给发送 v1alpha1 API 请求的客户端的默认警告信息。
deprecationWarning: "example.com/v1alpha1 CronTab is deprecated; see http://example.com/v1alpha1-v1 for instructions to migrate to example.com/v1 CronTab"
schema: ...
- name: v1beta1
served: true
# 此属性标明该定制资源的 v1beta1 版本已被弃用。
# 发给此版本的 API 请求会在服务器响应中收到警告消息头。
# 针对此版本的请求所返回的是默认的警告消息。
deprecated: true
schema: ...
- name: v1
served: true
storage: true
schema: ...
# 在 v1.16 中弃用以推荐使用 apiextensions.k8s.io/v1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: crontabs.example.com
spec:
group: example.com
names:
plural: crontabs
singular: crontab
kind: CronTab
scope: Namespaced
validation: ...
versions:
- name: v1alpha1
served: true
storage: false
# 此属性标明此定制资源的 v1alpha1 版本已被弃用。
# 发给此版本的 API 请求会在服务器响应中收到警告消息头。
deprecated: true
# 此属性设置用来覆盖返回给发送 v1alpha1 API 请求的客户端的默认警告信息。
deprecationWarning: "example.com/v1alpha1 CronTab is deprecated; see http://example.com/v1alpha1-v1 for instructions to migrate to example.com/v1 CronTab"
- name: v1beta1
served: true
# 此属性标明该定制资源的 v1beta1 版本已被弃用。
# 发给此版本的 API 请求会在服务器响应中收到警告消息头。
# 针对此版本的请求所返回的是默认的警告消息。
deprecated: true
- name: v1
served: true
storage: true
在为所有提供旧版本自定义资源的集群将现有存储数据迁移到新 API 版本,并且从 CustomResourceDefinition 的
status.storedVersions 中删除旧版本之前,无法从 CustomResourceDefinition 清单文件中删除旧 API 版本。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
name: crontabs.example.com
spec:
group: example.com
names:
plural: crontabs
singular: crontab
kind: CronTab
scope: Namespaced
versions:
- name: v1beta1
# 此属性标明该自定义资源的 v1beta1 版本已不再提供。
# 发给此版本的 API 请求会在服务器响应中收到未找到的错误。
served: false
schema: ...
- name: v1
served: true
# 新提供的版本应该设置为存储版本。
storage: true
schema: ...
Kubernetes v1.16 [stable]
Webhook 转换在 Kubernetes 1.13 版本作为 Alpha 功能引入,在 Kubernetes 1.15 版本中成为 Beta 功能。
要使用此功能,应启用 CustomResourceWebhookConversion 特性。
在大多数集群上,这类 Beta 特性应该是自动启用的。
请参阅特性门控文档以获得更多信息。
上面的例子在版本之间有一个 None 转换,它只在转换时设置 apiVersion 字段而不改变对象的其余部分。
API 服务器还支持在需要转换时调用外部服务的 webhook 转换。例如:
为了涵盖所有这些情况并优化 API 服务器所作的转换,转换请求可以包含多个对象, 以便减少外部调用。Webhook 应该独立执行各个转换。
请参考定制资源转换 Webhook 服务器的实现;
该实现在 Kubernetes e2e 测试中得到验证。
Webhook 处理由 API 服务器发送的 ConversionReview 请求,并在
ConversionResponse 中封装发回转换结果。
请注意,请求包含需要独立转换的定制资源列表,这些对象在被转换之后不能改变其在列表中的顺序。
该示例服务器的组织方式使其可以复用于其他转换。大多数常见代码都位于
framework 文件中,
只留下一个函数用于实现不同的转换。
转换 Webhook 服务器示例中将 ClientAuth
字段设置为空,
默认为 NoClientCert。
这意味着 webhook 服务器没有验证客户端(也就是 API 服务器)的身份。
如果你需要双向 TLS 或者其他方式来验证客户端,
请参阅如何验证 API 服务。
转换 Webhook 不可以更改被转换对象的 metadata 中除 labels 和 annotations
之外的任何属性。
尝试更改 name、UID 和 namespace 时都会导致引起转换的请求失败。
所有其他变更都被忽略。
用于部署转换 Webhook
的文档与准入 Webhook 服务示例相同。
这里的假设是转换 Webhook 服务器被部署为 default 名字空间中名为
example-conversion-webhook-server 的服务,并在路径 /crdconvert
上处理请求。
当 Webhook 服务器作为一个服务被部署到 Kubernetes 集群中时,它必须通过端口 443 公开其服务(服务器本身可以使用任意端口,但是服务对象应该将它映射到端口 443)。 如果为服务器使用不同的端口,则 API 服务器和 Webhook 服务器之间的通信可能会失败。
通过修改 spec 中的 conversion 部分,可以扩展 None 转换示例来使用转换 Webhook。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name 必须匹配后面 spec 中的字段,且使用格式 <plural>.<group>
name: crontabs.example.com
spec:
# 组名,用于 REST API: /apis/<group>/<version>
group: example.com
# 此 CustomResourceDefinition 所支持的版本列表
versions:
- name: v1beta1
# 每个 version 可以通过 served 标志启用或禁止
served: true
# 有且只能有一个 version 必须被标记为存储版本
storage: true
# 当不存在顶级模式定义时,每个版本(version)可以定义其自身的模式
schema:
openAPIV3Schema:
type: object
properties:
hostPort:
type: string
- name: v1
served: true
storage: false
schema:
openAPIV3Schema:
type: object
properties:
host:
type: string
port:
type: string
conversion:
# Webhook strategy 告诉 API 服务器调用外部 Webhook 来完成定制资源之间的转换
strategy: Webhook
# 当 strategy 为 "Webhook" 时,webhook 属性是必需的,该属性配置将被 API 服务器调用的 Webhook 端点
webhook:
# conversionReviewVersions 标明 Webhook 所能理解或偏好使用的
# ConversionReview 对象版本。
# API 服务器所能理解的列表中的第一个版本会被发送到 Webhook
# Webhook 必须按所接收到的版本响应一个 ConversionReview 对象
conversionReviewVersions: ["v1","v1beta1"]
clientConfig:
service:
namespace: default
name: example-conversion-webhook-server
path: /crdconvert
caBundle: "Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL: /apis/<group>/<version>/<plural>
plural: crontabs
# 名称的单数形式,用于在命令行接口和显示时作为其别名
singular: crontab
# kind 通常是驼峰编码(CamelCased)的单数形式,用于资源清单中
kind: CronTab
# shortNames 允许你在命令行接口中使用更短的字符串来匹配你的资源
shortNames:
- ct
# 在 v1.16 中被弃用以推荐使用 apiextensions.k8s.io/v1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
# name 必须匹配后面 spec 中的字段,且使用格式 <plural>.<group>
name: crontabs.example.com
spec:
# 组名,用于 REST API: /apis/<group>/<version>
group: example.com
# 裁剪掉下面的 OpenAPI 模式中未曾定义的对象字段
preserveUnknownFields: false
# 此 CustomResourceDefinition 所支持的版本列表
versions:
- name: v1beta1
# 每个 version 可以通过 served 标志启用或禁止
served: true
# 有且只能有一个 version 必须被标记为存储版本
storage: true
# 当不存在顶级模式定义时,每个版本(version)可以定义其自身的模式
schema:
openAPIV3Schema:
type: object
properties:
hostPort:
type: string
- name: v1
served: true
storage: false
schema:
openAPIV3Schema:
type: object
properties:
host:
type: string
port:
type: string
conversion:
# Webhook strategy 告诉 API 服务器调用外部 Webhook 来完成定制资源
strategy: Webhook
# 当 strategy 为 "Webhook" 时,webhookClientConfig 属性是必需的
# 该属性配置将被 API 服务器调用的 Webhook 端点
webhookClientConfig:
service:
namespace: default
name: example-conversion-webhook-server
path: /crdconvert
caBundle: "Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL: /apis/<group>/<version>/<plural>
plural: crontabs
# 名称的单数形式,用于在命令行接口和显示时作为其别名
singular: crontab
# kind 通常是驼峰编码(CamelCased)的单数形式,用于资源清单中
kind: CronTab
# shortNames 允许你在命令行接口中使用更短的字符串来匹配你的资源
shortNames:
- ct
你可以将 CustomResourceDefinition 保存在 YAML 文件中,然后使用
kubectl apply 来应用它。
kubectl apply -f my-versioned-crontab-with-conversion.yaml
在应用新更改之前,请确保转换服务器已启动并正在运行。
API 服务器一旦确定请求应发送到转换 Webhook,它需要知道如何调用 Webhook。
这是在 webhookClientConfig 中指定的 Webhook 配置。
转换 Webhook 可以通过 URL 或服务引用来调用,并且可以选择包含自定义 CA 包, 以用于验证 TLS 连接。
url 以标准 URL 形式给出 Webhook 的位置(scheme://host:port/path)。
host 不应引用集群中运行的服务,而应通过指定 service 字段来提供服务引用。
在某些 API 服务器中,host 可以通过外部 DNS 进行解析(即
kube-apiserver 无法解析集群内 DNS,那样会违反分层规则)。
host 也可以是 IP 地址。
请注意,除非你非常小心地在所有运行着可能调用 Webhook 的 API 服务器的主机上运行此 Webhook,
否则将 localhost 或 127.0.0.1 用作 host 是风险很大的。
这样的安装可能是不可移植的,或者不容易在一个新的集群中运行。
HTTP 协议必须为 https;URL 必须以 https:// 开头。
尝试使用用户或基本身份验证(例如,使用 user:password@)是不允许的。
URL 片段(#...)和查询参数(?...)也是不允许的。
下面是为调用 URL 来执行转换 Webhook 的示例,其中期望使用系统信任根来验证 TLS 证书,因此未指定 caBundle:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
...
spec:
...
conversion:
strategy: Webhook
webhook:
clientConfig:
url: "https://my-webhook.example.com:9443/my-webhook-path"
...
# 在 v1.16 中已弃用以推荐使用 apiextensions.k8s.io/v1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
...
spec:
...
conversion:
strategy: Webhook
webhookClientConfig:
url: "https://my-webhook.example.com:9443/my-webhook-path"
...
webhookClientConfig 内部的 service 段是对转换 Webhook 服务的引用。
如果 Webhook 在集群中运行,则应使用 service 而不是 url。
服务的名字空间和名称是必需的。端口是可选的,默认为 443。
路径是可选的,默认为/。
下面配置中,服务配置为在端口 1234、子路径 /my-path 上被调用。
例子中针对 ServerName my-service-name.my-service-namespace.svc,
使用自定义 CA 包验证 TLS 连接。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
...
spec:
...
conversion:
strategy: Webhook
webhook:
clientConfig:
service:
namespace: my-service-namespace
name: my-service-name
path: /my-path
port: 1234
caBundle: "Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"
...
# v1.16 中被弃用以推荐使用 apiextensions.k8s.io/v1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
...
spec:
...
conversion:
strategy: Webhook
webhookClientConfig:
service:
namespace: my-service-namespace
name: my-service-name
path: /my-path
port: 1234
caBundle: "Ci0tLS0tQk...<base64-encoded PEM bundle>...tLS0K"
...
向 Webhook 发起请求的动词是 POST,请求的 Content-Type 为 application/json。
请求的主题为 JSON 序列化形式的
apiextensions.k8s.io API 组的 ConversionReview API 对象。
Webhook 可以在其 CustomResourceDefinition 中使用 conversionReviewVersions
字段设置它们接受的 ConversionReview 对象的版本:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
...
spec:
...
conversion:
strategy: Webhook
webhook:
conversionReviewVersions: ["v1", "v1beta1"]
...
创建 apiextensions.k8s.io/v1 版本的自定义资源定义时,
conversionReviewVersions 是必填字段。
Webhook 要求支持至少一个 ConversionReview 当前和以前的 API 服务器可以理解的版本。
# v1.16 已弃用以推荐使用 apiextensions.k8s.io/v1
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
...
spec:
...
conversion:
strategy: Webhook
conversionReviewVersions: ["v1", "v1beta1"]
...
创建 apiextensions.k8s.io/v1beta1 定制资源定义时若未指定
conversionReviewVersions,则默认值为 v1beta1。
API 服务器将 conversionReviewVersions 列表中他们所支持的第一个
ConversionReview 资源版本发送给 Webhook。
如果列表中的版本都不被 API 服务器支持,则无法创建自定义资源定义。
如果某 API 服务器遇到之前创建的转换 Webhook 配置,并且该配置不支持
API 服务器知道如何发送的任何 ConversionReview 版本,调用 Webhook
的尝试会失败。
下面的示例显示了包含在 ConversionReview 对象中的数据,
该请求意在将 CronTab 对象转换为 example.com/v1:
{
"apiVersion": "apiextensions.k8s.io/v1",
"kind": "ConversionReview",
"request": {
# 用来唯一标识此转换调用的随机 UID
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",
# 对象要转换到的目标 API 组和版本
"desiredAPIVersion": "example.com/v1",
# 要转换的对象列表,其中可能包含一个或多个对象,版本可能相同也可能不同
"objects": [
{
"kind": "CronTab",
"apiVersion": "example.com/v1beta1",
"metadata": {
"creationTimestamp": "2019-09-04T14:03:02Z",
"name": "local-crontab",
"namespace": "default",
"resourceVersion": "143",
"uid": "3415a7fc-162b-4300-b5da-fd6083580d66"
},
"hostPort": "localhost:1234"
},
{
"kind": "CronTab",
"apiVersion": "example.com/v1beta1",
"metadata": {
"creationTimestamp": "2019-09-03T13:02:01Z",
"name": "remote-crontab",
"resourceVersion": "12893",
"uid": "359a83ec-b575-460d-b553-d859cedde8a0"
},
"hostPort": "example.com:2345"
}
]
}
}
{
# v1.16 中已废弃以推荐使用 apiextensions.k8s.io/v1
"apiVersion": "apiextensions.k8s.io/v1beta1",
"kind": "ConversionReview",
"request": {
# 用来唯一标识此转换调用的随机 UID
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",
# 对象要转换到的目标 API 组和版本
"desiredAPIVersion": "example.com/v1",
# 要转换的对象列表,其中可能包含一个或多个对象,版本可能相同也可能不同
"objects": [
{
"kind": "CronTab",
"apiVersion": "example.com/v1beta1",
"metadata": {
"creationTimestamp": "2019-09-04T14:03:02Z",
"name": "local-crontab",
"namespace": "default",
"resourceVersion": "143",
"uid": "3415a7fc-162b-4300-b5da-fd6083580d66"
},
"hostPort": "localhost:1234"
},
{
"kind": "CronTab",
"apiVersion": "example.com/v1beta1",
"metadata": {
"creationTimestamp": "2019-09-03T13:02:01Z",
"name": "remote-crontab",
"resourceVersion": "12893",
"uid": "359a83ec-b575-460d-b553-d859cedde8a0"
},
"hostPort": "example.com:2345"
}
]
}
}
Webhook 响应包含 200 HTTP 状态代码、Content-Type: application/json,
在主体中包含 JSON 序列化形式的数据,在 response 节中给出
ConversionReview 对象(与发送的版本相同)。
如果转换成功,则 Webhook 应该返回包含以下字段的 response 节:
uid,从发送到 webhook 的 request.uid 复制而来result,设置为 {"status":"Success"}}convertedObjects,包含来自 request.objects 的所有对象,均已转换为
request.desiredVersionWebhook 的最简单成功响应示例:
{
"apiVersion": "apiextensions.k8s.io/v1",
"kind": "ConversionReview",
"response": {
# 必须与 <request.uid> 匹配
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",
"result": {
"status": "Success"
},
# 这里的对象必须与 request.objects 中的对象顺序相同并且其 apiVersion 被设置为 <request.desiredAPIVersion>。
# kind、metadata.uid、metadata.name 和 metadata.namespace 等字段都不可被 Webhook 修改。
# Webhook 可以更改 metadata.labels 和 metadata.annotations 字段值。
# Webhook 对 metadata 中其他字段的更改都会被忽略
"convertedObjects": [
{
"kind": "CronTab",
"apiVersion": "example.com/v1",
"metadata": {
"creationTimestamp": "2019-09-04T14:03:02Z",
"name": "local-crontab",
"namespace": "default",
"resourceVersion": "143",
"uid": "3415a7fc-162b-4300-b5da-fd6083580d66"
},
"host": "localhost",
"port": "1234"
},
{
"kind": "CronTab",
"apiVersion": "example.com/v1",
"metadata": {
"creationTimestamp": "2019-09-03T13:02:01Z",
"name": "remote-crontab",
"resourceVersion": "12893",
"uid": "359a83ec-b575-460d-b553-d859cedde8a0"
},
"host": "example.com",
"port": "2345"
}
]
}
}
{
# v1.16 中已弃用以推荐使用 apiextensions.k8s.io/v1
"apiVersion": "apiextensions.k8s.io/v1beta1",
"kind": "ConversionReview",
"response": {
# 必须与 <request.uid> 匹配
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",
"result": {
"status": "Failed"
},
# 这里的对象必须与 request.objects 中的对象顺序相同并且其 apiVersion 被设置为 <request.desiredAPIVersion>。
# kind、metadata.uid、metadata.name 和 metadata.namespace 等字段都不可被 Webhook 修改。
# Webhook 可以更改 metadata.labels 和 metadata.annotations 字段值。
# Webhook 对 metadata 中其他字段的更改都会被忽略。
"convertedObjects": [
{
"kind": "CronTab",
"apiVersion": "example.com/v1",
"metadata": {
"creationTimestamp": "2019-09-04T14:03:02Z",
"name": "local-crontab",
"namespace": "default",
"resourceVersion": "143",
"uid": "3415a7fc-162b-4300-b5da-fd6083580d66"
},
"host": "localhost",
"port": "1234"
},
{
"kind": "CronTab",
"apiVersion": "example.com/v1",
"metadata": {
"creationTimestamp": "2019-09-03T13:02:01Z",
"name": "remote-crontab",
"resourceVersion": "12893",
"uid": "359a83ec-b575-460d-b553-d859cedde8a0"
},
"host": "example.com",
"port": "2345"
}
]
}
}
如果转换失败,则 Webhook 应该返回包含以下字段的 response 节:
uid,从发送到 Webhook 的 request.uid 复制而来result,设置为 {"status": "Failed"}转换失败会破坏对定制资源的读写访问,包括更新或删除资源的能力。 转换失败应尽可能避免,并且不可用于实施合法性检查约束 (应改用验证模式或 Webhook 准入插件)。
来自 Webhook 的响应示例,指示转换请求失败,并带有可选消息:
{
"apiVersion": "apiextensions.k8s.io/v1",
"kind": "ConversionReview",
"response": {
"uid": "<value from request.uid>",
"result": {
"status": "Failed",
"message": "hostPort could not be parsed into a separate host and port"
}
}
}
{
# v1.16 中弃用以推荐使用 apiextensions.k8s.io/v1
"apiVersion": "apiextensions.k8s.io/v1beta1",
"kind": "ConversionReview",
"response": {
"uid": "<value from request.uid>",
"result": {
"status": "Failed",
"message": "hostPort could not be parsed into a separate host and port"
}
}
}
写入对象时,将存储为写入时指定的存储版本。如果存储版本发生变化, 现有对象永远不会被自动转换。然而,新创建或被更新的对象将以新的存储版本写入。 对象写入的版本不再被支持是有可能的。
当读取对象时,你需要在路径中指定版本。 你可以请求当前提供的任意版本的对象。 如果所指定的版本与对象的存储版本不同,Kubernetes 会按所请求的版本将对象返回, 但磁盘上存储的对象不会更改。
在为读取请求提供服务时正返回的对象会发生什么取决于 CRD 的 spec.conversion 中指定的内容:
strategy 值是默认的 None,则针对对象的唯一修改是更改其 apiVersion 字符串,
并且可能修剪未知字段(取决于配置)。
请注意,如果存储和请求版本之间的模式不同,这不太可能导致好的结果。
尤其是如果在相同的数据类不同版本中采用不同字段来表示时,不应使用此策略。如果你更新一个现有对象,它将以当前的存储版本被重写。 这是可以将对象从一个版本改到另一个版本的唯一办法。
为了说明这一点,请考虑以下假设的一系列事件:
v1beta1。你创建一个对象。该对象以版本 v1beta1 存储。v1,并将其指定为存储版本。
此处 v1 和 v1beta1 的模式是相同的,这通常是在 Kubernetes 生态系统中将 API 提升为稳定版时的情况。v1beta1 来读取你的对象,然后你再次用版本 v1 读取对象。
除了 apiVersion 字段之外,返回的两个对象是完全相同的。v1。
你现在有两个对象,其中一个是 v1beta1,另一个是 v1。v1 保存,因为 v1 是当前的存储版本。API 服务器在状态字段 storedVersions 中记录曾被标记为存储版本的每个版本。
对象可能以任何曾被指定为存储版本的版本保存。
存储中不会出现从未成为存储版本的版本的对象。
弃用版本并删除其支持时,请选择存储升级过程。
选项 1: 使用存储版本迁移程序(Storage Version Migrator)
status.storedVersions 字段中去掉老的版本。选项 2: 手动将现有对象升级到新的存储版本
以下是从 v1beta1 升级到 v1 的示例过程。
v1 设置为存储版本,并使用 kubectl 应用它。
storedVersions现在是 v1beta1, v1。v1)写入对象。status.storedVersions 字段中删除 v1beta1。--subresource 标志在 kubectl get、patch、edit 和 replace 命令中用于获取和更新所有支持它们的
API 资源的子资源、status 和 scale。此标志从 kubectl 版本 v1.24 开始可用。
以前通过 kubectl 读取子资源(如 status)涉及使用 kubectl --raw,并且根本不可能使用 kubectl 更新子资源。
从 v1.24 开始,kubectl 工具可用于编辑或修补有关 CRD 对象的 status 子资源。
请参阅如何使用子资源标志修补 Deployment。
此页面是 Kubernetes v1.29 文档的一部分。 如果你运行的是不同版本的 Kubernetes,请查阅相应版本的文档。
以下是如何使用 kubectl 为一个 CRD 对象修补 status 子资源的示例:
kubectl patch customresourcedefinitions <CRD_Name> --subresource='status' --type='merge' -p '{"status":{"storedVersions":["v1"]}}'
安装扩展的 API 服务器来使用聚合层以让 Kubernetes API 服务器使用 其它 API 进行扩展, 这些 API 不是核心 Kubernetes API 的一部分。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
以下步骤描述如何 在一个高层次 设置一个扩展的 apiserver。无论你使用的是 YAML 配置还是使用 API,这些步骤都适用。 目前我们正在尝试区分出两者的区别。有关使用 YAML 配置的具体示例,你可以在 Kubernetes 库中查看 sample-apiserver。
或者,你可以使用现有的第三方解决方案,例如 apiserver-builder, 它将生成框架并自动执行以下所有步骤。
--runtime-config)。默认应该是启用的,除非被特意关闭了。<service name>.<service name namespace>.svc。system:auth-delegator
集群角色,以将 auth 决策委派给 Kubernetes 核心 API 服务器。extension-apiserver-authentication-reader 角色。
这将让你的扩展 api-server 能够访问 extension-apiserver-authentication configmap。Kubernetes 自带了一个默认调度器,其详细描述请查阅 这里。 如果默认调度器不适合你的需求,你可以实现自己的调度器。 而且,你甚至可以和默认调度器一起同时运行多个调度器,并告诉 Kubernetes 为每个 Pod 使用哪个调度器。 让我们通过一个例子讲述如何在 Kubernetes 中运行多个调度器。
关于实现调度器的具体细节描述超出了本文范围。 请参考 kube-scheduler 的实现,规范示例代码位于 pkg/scheduler。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
将调度器可执行文件打包到容器镜像中。出于示例目的,可以使用默认调度器 (kube-scheduler)作为第二个调度器。 克隆 GitHub 上 Kubernetes 源代码, 并编译构建源代码。
git clone https://github.com/kubernetes/kubernetes.git
cd kubernetes
make
创建一个包含 kube-scheduler 二进制文件的容器镜像。用于构建镜像的 Dockerfile 内容如下:
FROM busybox
ADD ./_output/local/bin/linux/amd64/kube-scheduler /usr/local/bin/kube-scheduler
将文件保存为 Dockerfile,构建镜像并将其推送到镜像仓库。
此示例将镜像推送到 Google 容器镜像仓库(GCR)。
有关详细信息,请阅读 GCR 文档。
或者,你也可以使用 Docker Hub。
有关更多详细信息,请参阅 Docker Hub
文档。
# 这里使用的镜像名称和仓库只是一个例子
docker build -t gcr.io/my-gcp-project/my-kube-scheduler:1.0 .
gcloud docker -- push gcr.io/my-gcp-project/my-kube-scheduler:1.0
现在将调度器放在容器镜像中,为它创建一个 Pod 配置,并在 Kubernetes 集群中
运行它。但是与其在集群中直接创建一个 Pod,不如使用
Deployment。
Deployment 管理一个 ReplicaSet,
ReplicaSet 再管理 Pod,从而使调度器能够免受一些故障的影响。
以下是 Deployment 配置,将其保存为 my-scheduler.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-kube-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ConfigMap
metadata:
name: my-scheduler-config
namespace: kube-system
data:
my-scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler
leaderElection:
leaderElect: false
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: my-scheduler-as-volume-scheduler
subjects:
- kind: ServiceAccount
name: my-scheduler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:volume-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
tier: control-plane
name: my-scheduler
namespace: kube-system
spec:
selector:
matchLabels:
component: scheduler
tier: control-plane
replicas: 1
template:
metadata:
labels:
component: scheduler
tier: control-plane
version: second
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: gcr.io/my-gcp-project/my-kube-scheduler:1.0
livenessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts:
- name: config-volume
mountPath: /etc/kubernetes/my-scheduler
hostNetwork: false
hostPID: false
volumes:
- name: config-volume
configMap:
name: my-scheduler-config
在以上的清单中,你使用 KubeSchedulerConfiguration
来自定义调度器实现的行为。当使用 --config 选项进行初始化时,该配置被传递到 kube-scheduler。
my-scheduler-config ConfigMap 存储配置数据。
my-scheduler Deployment 的 Pod 将 my-scheduler-config ConfigMap 挂载为一个卷。
在前面提到的调度器配置中,你的调度器呈现为一个 KubeSchedulerProfile。
要确定一个调度器是否可以调度特定的 Pod,PodTemplate 或 Pod 清单中的 spec.schedulerName
字段必须匹配 KubeSchedulerProfile 中的 schedulerName 字段。
运行在集群中的所有调度器必须拥有唯一的名称。
还要注意,我们创建了一个专用的服务账号 my-scheduler 并将集群角色 system:kube-scheduler
绑定到它,以便它可以获得与 kube-scheduler 相同的权限。
请参阅 kube-scheduler 文档
获取其他命令行参数以及 Scheduler 配置参考
获取自定义 kube-scheduler 配置的详细说明。
为了在 Kubernetes 集群中运行我们的第二个调度器,在 Kubernetes 集群中创建上面配置中指定的 Deployment:
kubectl create -f my-scheduler.yaml
验证调度器 Pod 正在运行:
kubectl get pods --namespace=kube-system
输出类似于:
NAME READY STATUS RESTARTS AGE
....
my-scheduler-lnf4s-4744f 1/1 Running 0 2m
...
此列表中,除了默认的 kube-scheduler Pod 之外,你应该还能看到处于 “Running” 状态的
my-scheduler Pod。
要在启用了 leader 选举的情况下运行多调度器,你必须执行以下操作:
更新你的 YAML 文件中的 my-scheduler-config ConfigMap 里的 KubeSchedulerConfiguration 相关字段如下:
leaderElection.leaderElect to trueleaderElection.resourceNamespace to <lock-object-namespace>leaderElection.resourceName to <lock-object-name>控制平面会为你创建锁对象,但是命名空间必须已经存在。
你可以使用 kube-system 命名空间。
如果在集群上启用了 RBAC,则必须更新 system:kube-scheduler 集群角色。
将调度器名称添加到应用了 endpoints 和 leases 资源的规则的 resourceNames 中,如以下示例所示:
kubectl edit clusterrole system:kube-scheduler
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-scheduler
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- create
- apiGroups:
- coordination.k8s.io
resourceNames:
- kube-scheduler
- my-scheduler
resources:
- leases
verbs:
- get
- update
- apiGroups:
- ""
resourceNames:
- kube-scheduler
- my-scheduler
resources:
- endpoints
verbs:
- delete
- get
- patch
- update
现在第二个调度器正在运行,创建一些 Pod,并指定它们由默认调度器或部署的调度器进行调度。 为了使用特定的调度器调度给定的 Pod,在那个 Pod 的 spec 中指定调度器的名称。让我们看看三个例子。
Pod spec 没有任何调度器名称
apiVersion: v1
kind: Pod
metadata:
name: no-annotation
labels:
name: multischeduler-example
spec:
containers:
- name: pod-with-no-annotation-container
image: registry.k8s.io/pause:2.0如果未提供调度器名称,则会使用 default-scheduler 自动调度 pod。
将此文件另存为 pod1.yaml,并将其提交给 Kubernetes 集群。
kubectl create -f pod1.yaml
Pod spec 设置为 default-scheduler
apiVersion: v1
kind: Pod
metadata:
name: annotation-default-scheduler
labels:
name: multischeduler-example
spec:
schedulerName: default-scheduler
containers:
- name: pod-with-default-annotation-container
image: registry.k8s.io/pause:2.0
通过将调度器名称作为 spec.schedulerName 参数的值来指定调度器。
在这种情况下,我们提供默认调度器的名称,即 default-scheduler。
将此文件另存为 pod2.yaml,并将其提交给 Kubernetes 集群。
kubectl create -f pod2.yaml
Pod spec 设置为 my-scheduler
apiVersion: v1
kind: Pod
metadata:
name: annotation-second-scheduler
labels:
name: multischeduler-example
spec:
schedulerName: my-scheduler
containers:
- name: pod-with-second-annotation-container
image: registry.k8s.io/pause:2.0
在这种情况下,我们指定此 Pod 使用我们部署的 my-scheduler 来调度。
请注意,spec.schedulerName 参数的值应该与调度器提供的 KubeSchedulerProfile 中的 schedulerName 字段相匹配。
将此文件另存为 pod3.yaml,并将其提交给 Kubernetes 集群。
kubectl create -f pod3.yaml
确认所有三个 Pod 都在运行。
kubectl get pods
为了更容易地完成这些示例,我们没有验证 Pod 实际上是使用所需的调度程序调度的。
我们可以通过更改 Pod 的顺序和上面的部署配置提交来验证这一点。
如果我们在提交调度器部署配置之前将所有 Pod 配置提交给 Kubernetes 集群,
我们将看到注解了 annotation-second-scheduler 的 Pod 始终处于 Pending 状态,
而其他两个 Pod 被调度。
一旦我们提交调度器部署配置并且我们的新调度器开始运行,注解了
annotation-second-scheduler 的 Pod 就能被调度。
或者,可以查看事件日志中的 Scheduled 条目,以验证是否由所需的调度器调度了 Pod。
kubectl get events
你也可以使用自定义调度器配置 或自定义容器镜像,用于集群的主调度器,方法是在相关控制平面节点上修改其静态 Pod 清单。
本文说明如何使用 HTTP 代理访问 Kubernetes API。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
要获知版本信息,请输入kubectl version.
如果你的集群中还没有任何应用,使用如下命令启动一个 Hello World 应用:
kubectl create deployment node-hello --image=gcr.io/google-samples/node-hello:1.0 --port=8080
使用如下命令启动 Kubernetes API 服务器的代理:
kubectl proxy --port=8080
当代理服务器在运行时,你可以通过 curl、wget 或者浏览器访问 API。
获取 API 版本:
curl http://localhost:8080/api/
输出应该类似这样:
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.2.15:8443"
}
]
}
获取 Pod 列表:
curl http://localhost:8080/api/v1/namespaces/default/pods
输出应该类似这样:
{
"kind": "PodList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "33074"
},
"items": [
{
"metadata": {
"name": "kubernetes-bootcamp-2321272333-ix8pt",
"generateName": "kubernetes-bootcamp-2321272333-",
"namespace": "default",
"uid": "ba21457c-6b1d-11e6-85f7-1ef9f1dab92b",
"resourceVersion": "33003",
"creationTimestamp": "2016-08-25T23:43:30Z",
"labels": {
"pod-template-hash": "2321272333",
"run": "kubernetes-bootcamp"
},
...
}
想了解更多信息,请参阅 kubectl 代理。
Kubernetes v1.24 [stable]
本文展示了如何使用 SOCKS5 代理访问远程 Kubernetes 集群的 API。 当你要访问的集群不直接在公共 Internet 上公开其 API 时,这很有用。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 v1.24. 要获知版本信息,请输入kubectl version.
你需要 SSH 客户端软件(ssh 工具),并在远程服务器上运行 SSH 服务。
你必须能够登录到远程服务器上的 SSH 服务。
此示例使用 SSH 隧道传输流量,SSH 客户端和服务器充当 SOCKS 代理。 你可以使用其他任意类型的 SOCKS5 代理代替。
图 1 表示你将在此任务中实现的目标。
图 1. SOCKS5 教程组件
下面的命令在你的客户端计算机和远程 SOCKS 服务器之间启动一个 SOCKS5 代理:
# 运行此命令后,SSH 隧道继续在前台运行
ssh -D 1080 -q -N username@kubernetes-remote-server.example
-D 1080: 在本地端口 1080 上打开一个 SOCKS 代理。-q: 静音模式。导致大多数警告和诊断消息被抑制。-N: 不执行远程命令。仅用于转发端口。username@kubernetes-remote-server.example:运行 Kubernetes 集群的远程 SSH 服务器(例如:堡垒主机)。要通过代理访问 Kubernetes API 服务器,你必须指示 kubectl 通过我们之前创建的 SOCKS5
代理发送查询。
这可以通过设置适当的环境变量或通过 kubeconfig 文件中的 proxy-url 属性来实现。
使用环境变量:
export HTTPS_PROXY=socks5://localhost:1080
要始终在特定的 kubectl 上下文中使用此设置,请在 ~/.kube/config 文件中为相关的
cluster 条目设置 proxy-url 属性。例如:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LRMEMMW2 # 简化以便阅读
# “Kubernetes API”服务器,换言之,kubernetes-remote-server.example 的 IP 地址
server: https://<API_SERVER_IP_ADDRESS>:6443
# 上图中的 “SSH SOCKS5代理”(内置 DNS 解析)
proxy-url: socks5://localhost:1080
name: default
contexts:
- context:
cluster: default
user: default
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: default
user:
client-certificate-data: LS0tLS1CR== # 节略,为了便于阅读
client-key-data: LS0tLS1CRUdJT= # 节略,为了便于阅读
一旦你通过前面提到的 SSH 命令创建了隧道,并定义了环境变量或 proxy-url 属性,
你就可以通过该代理与你的集群交互。例如:
kubectl get pods
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-85cb69466-klwq8 1/1 Running 0 5m46s
kubectl 1.24 之前,大多数 kubectl 命令在使用 socks 代理时都有效,除了 kubectl exec。kubectl 支持读取 HTTPS_PROXY 和 https_proxy 环境变量。 这些被其他支持 SOCKS 的程序使用,例如 curl。
因此在某些情况下,在命令行上定义环境变量会更好:
HTTPS_PROXY=socks5://localhost:1080 kubectl get pods
proxy-url 时,代理仅用于相关的 kubectl 上下文,而环境变量将影响所有上下文。socks5h 协议名称而不是上面显示的更广为人知的 socks5 协议,
可以进一步保护 k8s API 服务器主机名免受 DNS 泄漏影响。
这种情况下,kubectl 将要求代理服务器(例如 SSH 堡垒机)解析 k8s API 服务器域名,
而不是在运行 kubectl 的系统上进行解析。
另外还要注意,使用 socks5h 时,像 https://localhost:6443/api 这样的 k8s API 服务器 URL 并不是指你的本地客户端计算机。
相反,它指向的是代理服务器(例如 SSH 堡垒机)上已知的 localhost。通过在运行它的终端上按 CTRL+C 来停止 SSH 端口转发进程。
在终端中键入 unset https_proxy 以停止通过代理转发 http 流量。
Konnectivity 服务为控制平面提供集群通信的 TCP 级别代理。
你需要有一个 Kubernetes 集群,并且 kubectl 命令可以与集群通信。 建议在至少有两个不充当控制平面主机的节点的集群上运行本教程。 如果你还没有集群,可以使用 minikube 创建一个集群。
接下来的步骤需要出口配置,比如:
apiVersion: apiserver.k8s.io/v1beta1
kind: EgressSelectorConfiguration
egressSelections:
# 由于我们要控制集群的出站流量,所以将 “cluster” 用作 name。
# 其他支持的值有 “etcd” 和 “controlplane”。
- name: cluster
connection:
# 这一属性将控制 API 服务器 Konnectivity 服务器之间的协议。
# 支持的值为 “GRPC” 和 “HTTPConnect”。
# 最终用户不会察觉这两种模式之间的差异。
# 你需要将 Konnectivity 服务器设为在相同模式下工作。
proxyProtocol: GRPC
transport:
# 此属性控制 API 服务器使用哪种传输方式与 Konnectivity 服务器通信。
# 如果 Konnectivity 服务器与 API 服务器位于同一台机器上,建议使用 UDS。
# 你需要将 Konnectivity 服务器配置为侦听同一个 UDS 套接字。
# 另一个支持的传输方式是 “tcp”。
# 你将需要设置 TLS config 以确保 TCP 传输的安全。
uds:
udsName: /etc/kubernetes/konnectivity-server/konnectivity-server.socket
你需要配置 API 服务器来使用 Konnectivity 服务,并将网络流量定向到集群节点:
确保服务账号令牌卷投射特性被启用。 该特性自 Kubernetes v1.20 起默认已被启用。
创建一个出站流量配置文件,比如 admin/konnectivity/egress-selector-configuration.yaml。
将 API 服务器的 --egress-selector-config-file 参数设置为你的 API
服务器的离站流量配置文件路径。
如果你在使用 UDS 连接,须将卷配置添加到 kube-apiserver:
spec:
containers:
volumeMounts:
- name: konnectivity-uds
mountPath: /etc/kubernetes/konnectivity-server
readOnly: false
volumes:
- name: konnectivity-uds
hostPath:
path: /etc/kubernetes/konnectivity-server
type: DirectoryOrCreate
为 konnectivity-server 生成或者取得证书和 kubeconfig 文件。
例如,你可以使用 OpenSSL 命令行工具,基于存放在某控制面主机上
/etc/kubernetes/pki/ca.crt 文件中的集群 CA 证书来发放一个 X.509 证书。
openssl req -subj "/CN=system:konnectivity-server" -new -newkey rsa:2048 -nodes -out konnectivity.csr -keyout konnectivity.key
openssl x509 -req -in konnectivity.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out konnectivity.crt -days 375 -sha256
SERVER=$(kubectl config view -o jsonpath='{.clusters..server}')
kubectl --kubeconfig /etc/kubernetes/konnectivity-server.conf config set-credentials system:konnectivity-server --client-certificate konnectivity.crt --client-key konnectivity.key --embed-certs=true
kubectl --kubeconfig /etc/kubernetes/konnectivity-server.conf config set-cluster kubernetes --server "$SERVER" --certificate-authority /etc/kubernetes/pki/ca.crt --embed-certs=true
kubectl --kubeconfig /etc/kubernetes/konnectivity-server.conf config set-context system:konnectivity-server@kubernetes --cluster kubernetes --user system:konnectivity-server
kubectl --kubeconfig /etc/kubernetes/konnectivity-server.conf config use-context system:konnectivity-server@kubernetes
rm -f konnectivity.crt konnectivity.key konnectivity.csr
接下来,你需要部署 Konnectivity 服务器和代理。 kubernetes-sigs/apiserver-network-proxy 是一个参考实现。
在控制面节点上部署 Konnectivity 服务。
下面提供的 konnectivity-server.yaml 配置清单假定在你的集群中
Kubernetes 组件都是部署为静态 Pod 的。
如果不是,你可以将 Konnectivity 服务部署为 DaemonSet。
apiVersion: v1
kind: Pod
metadata:
name: konnectivity-server
namespace: kube-system
spec:
priorityClassName: system-cluster-critical
hostNetwork: true
containers:
- name: konnectivity-server-container
image: registry.k8s.io/kas-network-proxy/proxy-server:v0.0.37
command: ["/proxy-server"]
args: [
"--logtostderr=true",
# 下一行需与 egressSelectorConfiguration 中设置的值一致。
"--uds-name=/etc/kubernetes/konnectivity-server/konnectivity-server.socket",
"--delete-existing-uds-file",
# 下面两行假定 Konnectivity 服务器被部署在与 apiserver 相同的机器上,
# 并且该 API 服务器的证书和密钥位于指定的位置。
"--cluster-cert=/etc/kubernetes/pki/apiserver.crt",
"--cluster-key=/etc/kubernetes/pki/apiserver.key",
# 下一行需与 egressSelectorConfiguration 中设置的值一致。
"--mode=grpc",
"--server-port=0",
"--agent-port=8132",
"--admin-port=8133",
"--health-port=8134",
"--agent-namespace=kube-system",
"--agent-service-account=konnectivity-agent",
"--kubeconfig=/etc/kubernetes/konnectivity-server.conf",
"--authentication-audience=system:konnectivity-server"
]
livenessProbe:
httpGet:
scheme: HTTP
host: 127.0.0.1
port: 8134
path: /healthz
initialDelaySeconds: 30
timeoutSeconds: 60
ports:
- name: agentport
containerPort: 8132
hostPort: 8132
- name: adminport
containerPort: 8133
hostPort: 8133
- name: healthport
containerPort: 8134
hostPort: 8134
volumeMounts:
- name: k8s-certs
mountPath: /etc/kubernetes/pki
readOnly: true
- name: kubeconfig
mountPath: /etc/kubernetes/konnectivity-server.conf
readOnly: true
- name: konnectivity-uds
mountPath: /etc/kubernetes/konnectivity-server
readOnly: false
volumes:
- name: k8s-certs
hostPath:
path: /etc/kubernetes/pki
- name: kubeconfig
hostPath:
path: /etc/kubernetes/konnectivity-server.conf
type: FileOrCreate
- name: konnectivity-uds
hostPath:
path: /etc/kubernetes/konnectivity-server
type: DirectoryOrCreate
在你的集群中部署 Konnectivity 代理:
apiVersion: apps/v1
# 作为另一种替代方案,你可以将代理部署为 Deployment。
# 没有必要在每个节点上都有一个代理。
kind: DaemonSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: konnectivity-agent
namespace: kube-system
name: konnectivity-agent
spec:
selector:
matchLabels:
k8s-app: konnectivity-agent
template:
metadata:
labels:
k8s-app: konnectivity-agent
spec:
priorityClassName: system-cluster-critical
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
containers:
- image: us.gcr.io/k8s-artifacts-prod/kas-network-proxy/proxy-agent:v0.0.37
name: konnectivity-agent
command: ["/proxy-agent"]
args: [
"--logtostderr=true",
"--ca-cert=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt",
# 由于 konnectivity 服务器以 hostNetwork=true 运行,
# 所以这是控制面节点的 IP 地址。
"--proxy-server-host=35.225.206.7",
"--proxy-server-port=8132",
"--admin-server-port=8133",
"--health-server-port=8134",
"--service-account-token-path=/var/run/secrets/tokens/konnectivity-agent-token"
]
volumeMounts:
- mountPath: /var/run/secrets/tokens
name: konnectivity-agent-token
livenessProbe:
httpGet:
port: 8134
path: /healthz
initialDelaySeconds: 15
timeoutSeconds: 15
serviceAccountName: konnectivity-agent
volumes:
- name: konnectivity-agent-token
projected:
sources:
- serviceAccountToken:
path: konnectivity-agent-token
audience: system:konnectivity-server
最后,如果你的集群启用了 RBAC,请创建相关的 RBAC 规则:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:konnectivity-server
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: system:konnectivity-server
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: konnectivity-agent
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
Kubernetes 提供 certificates.k8s.io API,可让你配置由你控制的证书颁发机构(CA)
签名的 TLS 证书。 你的工作负载可以使用这些 CA 和证书来建立信任。
certificates.k8s.io API使用的协议类似于
ACME 草案。
使用 certificates.k8s.io API 创建的证书由指定 CA 颁发。
将集群配置为使用集群根目录 CA 可以达到这个目的,但是你永远不要依赖这一假定。
不要以为这些证书将针对群根目录 CA 进行验证。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你需要 cfssl 工具。
你可以从 https://github.com/cloudflare/cfssl/releases
下载 cfssl。
本文中某些步骤使用 jq 工具。如果你没有 jq,你可以通过操作系统的软件源安装,
或者从 https://jqlang.github.io/jq/ 获取。
信任 Pod 中运行的应用程序所提供的自定义 CA 通常需要一些额外的应用程序配置。
你需要将 CA 证书包添加到 TLS 客户端或服务器信任的 CA 证书列表中。
例如,你可以使用 Golang TLS 配置通过解析证书链并将解析的证书添加到
tls.Config 结构中的 RootCAs
字段中。
即使自定义 CA 证书可能包含在文件系统中(在 ConfigMap kube-root-ca.crt 中),
除了验证内部 Kubernetes 端点之外,你不应将该证书颁发机构用于任何目的。
内部 Kubernetes 端点的一个示例是默认命名空间中名为 kubernetes 的服务。
如果你想为你的工作负载使用自定义证书颁发机构,你应该单独生成该 CA, 并使用你的 Pod 有读权限的 ConfigMap 分发该 CA 证书。
以下部分演示如何为通过 DNS 访问的 Kubernetes 服务创建 TLS 证书。
通过运行以下命令生成私钥和证书签名请求(或 CSR):
cat <<EOF | cfssl genkey - | cfssljson -bare server
{
"hosts": [
"my-svc.my-namespace.svc.cluster.local",
"my-pod.my-namespace.pod.cluster.local",
"192.0.2.24",
"10.0.34.2"
],
"CN": "my-pod.my-namespace.pod.cluster.local",
"key": {
"algo": "ecdsa",
"size": 256
}
}
EOF
其中 192.0.2.24 是服务的集群 IP,my-svc.my-namespace.svc.cluster.local
是服务的 DNS 名称,10.0.34.2 是 Pod 的 IP,而
my-pod.my-namespace.pod.cluster.local 是 Pod 的 DNS 名称。
你能看到的输出类似于:
2022/02/01 11:45:32 [INFO] generate received request
2022/02/01 11:45:32 [INFO] received CSR
2022/02/01 11:45:32 [INFO] generating key: ecdsa-256
2022/02/01 11:45:32 [INFO] encoded CSR
此命令生成两个文件;它生成包含 PEM 编码
PKCS#10 证书请求的 server.csr,
以及 PEM 编码密钥的 server-key.pem,用于待生成的证书。
你可以使用以下命令创建 CSR 清单(YAML 格式),并发送到 API 服务器:
cat <<EOF | kubectl apply -f -
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: my-svc.my-namespace
spec:
request: $(cat server.csr | base64 | tr -d '\n')
signerName: example.com/serving
usages:
- digital signature
- key encipherment
- server auth
EOF
请注意,在步骤 1 中创建的 server.csr 文件是 base64 编码并存储在
.spec.request 字段中的。你还要求提供 “digital signature(数字签名)”,
“密钥加密(key encipherment)” 和 “服务器身份验证(server auth)” 密钥用途,
由 example.com/serving 示例签名程序签名的证书。
你也可以要求使用特定的 signerName。更多信息可参阅
支持的签署者名称。
在 API server 中可以看到这些 CSR 处于 Pending 状态。执行下面的命令你将可以看到:
kubectl describe csr my-svc.my-namespace
Name: my-svc.my-namespace
Labels: <none>
Annotations: <none>
CreationTimestamp: Tue, 01 Feb 2022 11:49:15 -0500
Requesting User: yourname@example.com
Signer: example.com/serving
Status: Pending
Subject:
Common Name: my-pod.my-namespace.pod.cluster.local
Serial Number:
Subject Alternative Names:
DNS Names: my-pod.my-namespace.pod.cluster.local
my-svc.my-namespace.svc.cluster.local
IP Addresses: 192.0.2.24
10.0.34.2
Events: <none>
证书签名请求
的批准或者是通过自动批准过程完成的,或由集群管理员一次性完成。
如果你被授权批准证书请求,你可以使用 kubectl 来手动完成此操作;例如:
kubectl certificate approve my-svc.my-namespace
certificatesigningrequest.certificates.k8s.io/my-svc.my-namespace approved
你现在应该能看到如下输出:
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
my-svc.my-namespace 10m example.com/serving yourname@example.com <none> Approved
这意味着证书请求已被批准,并正在等待请求的签名者对其签名。
接下来,你将扮演证书签署者的角色,颁发证书并将其上传到 API 服务器。
签名者通常会使用其 signerName 查看对象的 CertificateSigningRequest API,
检查它们是否已被批准,为这些请求签署证书,并使用已颁发的证书更新 API 对象状态。
你需要授权在新证书上提供数字签名。
首先,通过运行以下命令创建签名证书:
cat <<EOF | cfssl gencert -initca - | cfssljson -bare ca
{
"CN": "My Example Signer",
"key": {
"algo": "rsa",
"size": 2048
}
}
EOF
你应该看到类似于以下的输出:
2022/02/01 11:50:39 [INFO] generating a new CA key and certificate from CSR
2022/02/01 11:50:39 [INFO] generate received request
2022/02/01 11:50:39 [INFO] received CSR
2022/02/01 11:50:39 [INFO] generating key: rsa-2048
2022/02/01 11:50:39 [INFO] encoded CSR
2022/02/01 11:50:39 [INFO] signed certificate with serial number 263983151013686720899716354349605500797834580472
这会产生一个证书颁发机构密钥文件(ca-key.pem)和证书(ca.pem)。
{
"signing": {
"default": {
"usages": [
"digital signature",
"key encipherment",
"server auth"
],
"expiry": "876000h",
"ca_constraint": {
"is_ca": false
}
}
}
}使用 server-signing-config.json 签名配置、证书颁发机构密钥文件和证书来签署证书请求:
kubectl get csr my-svc.my-namespace -o jsonpath='{.spec.request}' | \
base64 --decode | \
cfssl sign -ca ca.pem -ca-key ca-key.pem -config server-signing-config.json - | \
cfssljson -bare ca-signed-server
你应该看到类似于以下的输出:
2022/02/01 11:52:26 [INFO] signed certificate with serial number 576048928624926584381415936700914530534472870337
这会生成一个签名的服务证书文件,ca-signed-server.pem。
最后,在 API 对象的状态中填充签名证书:
kubectl get csr my-svc.my-namespace -o json | \
jq '.status.certificate = "'$(base64 ca-signed-server.pem | tr -d '\n')'"' | \
kubectl replace --raw /apis/certificates.k8s.io/v1/certificatesigningrequests/my-svc.my-namespace/status -f -
这使用命令行工具 jq
在 .status.certificate 字段中填充 base64 编码的内容。
如果你没有 jq 工具,你还可以将 JSON 输出保存到文件中,手动填充此字段,然后上传结果文件。
批准 CSR 并上传签名证书后,运行:
kubectl get csr
输入类似于:
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
my-svc.my-namespace 20m example.com/serving yourname@example.com <none> Approved,Issued
现在,作为请求用户,你可以通过运行以下命令下载颁发的证书并将其保存到 server.crt 文件中:
CSR 被签署并获得批准后,你应该看到以下内容:
kubectl get csr my-svc.my-namespace -o jsonpath='{.status.certificate}' \
| base64 --decode > server.crt
现在你可以将 server.crt 和 server-key.pem 填充到
Secret 中,
稍后你可以将其挂载到 Pod 中(例如,用于提供 HTTPS 的网络服务器)。
kubectl create secret tls server --cert server.crt --key server-key.pem
secret/server created
最后,你可以将 ca.pem 填充到
ConfigMap
并将其用作信任根来验证服务证书:
kubectl create configmap example-serving-ca --from-file ca.crt=ca.pem
configmap/example-serving-ca created
Kubernetes 管理员(具有适当权限)可以使用 kubectl certificate approve 和
kubectl certificate deny 命令手动批准(或拒绝)证书签名请求(CSR)。
但是,如果你打算大量使用此 API,则可以考虑编写自动化的证书控制器。
批准证书 CSR 的能力决定了在你的环境中谁信任谁。 不应广泛或轻率地授予批准 CSR 的能力。
在授予 approve 权限之前,你应该确保自己充分了解批准人的验证要求和颁发特定证书的后果。
无论上述机器或人使用 kubectl,“批准者”的作用是验证 CSR 满足如下两个要求:
当且仅当满足这两个要求时,审批者应该批准 CSR,否则拒绝 CSR。
有关证书批准和访问控制的更多信息, 请阅读证书签名请求参考页。
本页面假设已经为 certificates API 配置了签名者。
Kubernetes 控制器管理器提供了一个签名者的默认实现。要启用它,请为控制器管理器设置
--cluster-signing-cert-file 和 --cluster-signing-key-file 参数,
使之取值为你的证书机构的密钥对的路径。
本页展示如何手动轮换证书机构(CA)证书。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
确保备份你的证书目录、配置文件以及其他必要文件。
这里的方法假定 Kubernetes 的控制面通过运行多个 API 服务器以高可用配置模式运行。 另一假定是 API 服务器可体面地终止,因而客户端可以彻底地与一个 API 服务器断开 连接并连接到另一个 API 服务器。
如果集群中只有一个 API 服务器,则在 API 服务器重启期间会经历服务中断期。
ca.crt、ca.key、front-proxy-ca.crt 和
front-proxy-client.key)分发到所有控制面节点,放在其 Kubernetes 证书目录下。更新 kube-controller-manager
的 --root-ca-file 标志,使之同时包含老的和新的 CA,之后重启
kube-controller-manager。
自此刻起,所创建的所有ServiceAccount 都会获得同时包含老的 CA 和新的 CA 的 Secret。
kube-controller-manager 标志 --client-ca-file 和 --cluster-signing-cert-file
所引用的文件不能是 CA 证书包。如果这些标志和 --root-ca-file 指向同一个 ca.crt 包文件
(包含老的和新的 CA 证书),你将会收到出错信息。
要解决这个问题,可以将新的 CA 证书复制到单独的文件中,并将 --client-ca-file 和
--cluster-signing-cert-file 标志指向该副本。一旦 ca.crt 不再是证书包文件,
就可以恢复有问题的标志指向 ca.crt 并删除该副本。
kubeadm 的 Issue 1350 在跟踪一个导致 kube-controller-manager 无法接收 CA 证书包的问题。
等待该控制器管理器更新服务账号 Secret 中的 ca.crt,使之同时包含老的和新的 CA 证书。
如果在 API 服务器使用新的 CA 之前启动了新的 Pod,这些新的 Pod 也会获得此更新并且同时信任老的和新的 CA 证书。
重启所有使用集群内配置的 Pod(例如:kube-proxy、CoreDNS 等),以便这些 Pod 能够使用与 ServiceAccount 相关联的 Secret 中的、已更新的证书机构数据。
将老的和新的 CA 都追加到 kube-apiserver 配置的 --client-ca-file 和
--kubelet-certificate-authority 标志所指的文件。
将老的和新的 CA 都追加到 kube-scheduler 配置的 --client-ca-file 标志所指的文件。
通过替换 client-certificate-data 和 client-key-data 中的内容,更新用户账号的证书。
有关为独立用户账号创建证书的更多信息,可参阅 为用户帐号配置证书。
另外,还要更新 kubeconfig 文件中的 certificate-authority-data 节,
使之包含 Base64 编码的老的和新的证书机构数据。
更新 云控制器管理器(Cloud Controller Manager) 的 --root-ca-file
标志值,使之同时包含老的和新的 CA,之后重新启动 cloud-controller-manager。
如果你的集群中不包含 cloud-controller-manager,你可以略过这一步。
遵循下列步骤执行滚动更新
重新启动所有其他被聚合的 API 服务器 或者 Webhook 处理程序,使之信任新的 CA 证书。
在所有节点上更新 kubelet 配置中的 clientCAFile 所指文件以及 kubelet.conf 中的
certificate-authority-data 并重启 kubelet 以同时使用老的和新的 CA 证书。
如果你的 kubelet 并未使用客户端证书轮换,则在所有节点上更新 kubelet.conf 中
client-certificate-data 和 client-key-data 以及 kubelet
客户端证书文件(通常位于 /var/lib/kubelet/pki 目录下)
apiserver.crt、apiserver-kubelet-client.crt 和 front-proxy-client.crt)
来重启 API 服务器。
你可以使用现有的私钥,也可以使用新的私钥。
如果你改变了私钥,则要将更新的私钥也放到 Kubernetes 证书目录下。 由于集群中的 Pod 既信任老的 CA 也信任新的 CA,Pod 中的客户端会经历短暂的连接断开状态,
之后再使用新的 CA 所签名的证书连接到新的 API 服务器。
* 重启 kube-scheduler 以使用并信任新的
CA 证书。
要使用 `openssl` 命令行为集群生成新的证书和私钥,可参阅
[证书(`openssl`)](/zh-cn/docs/tasks/administer-cluster/certificates/#openssl)。
你也可以使用[`cfssl`](/zh-cn/docs/tasks/administer-cluster/certificates/#cfssl).for namespace in $(kubectl get namespace -o jsonpath='{.items[*].metadata.name}'); do
for name in $(kubectl get deployments -n $namespace -o jsonpath='{.items[*].metadata.name}'); do
kubectl patch deployment -n ${namespace} ${name} -p '{"spec":{"template":{"metadata":{"annotations":{"ca-rotation": "1"}}}}}';
done
for name in $(kubectl get daemonset -n $namespace -o jsonpath='{.items[*].metadata.name}'); do
kubectl patch daemonset -n ${namespace} ${name} -p '{"spec":{"template":{"metadata":{"annotations":{"ca-rotation": "1"}}}}}';
done
done
要限制应用可能受到的并发干扰数量,
可以参阅[配置 Pod 干扰预算](/zh-cn/docs/tasks/run-application/configure-pdb/)。 取决于你在如何使用 StatefulSet,你可能需要对其执行类似的滚动替换操作。
如果你的集群使用启动引导令牌来添加节点,则需要更新 kube-public 名字空间下的
ConfigMap cluster-info,使之包含新的 CA 证书。
base64_encoded_ca="$(base64 -w0 /etc/kubernetes/pki/ca.crt)"
kubectl get cm/cluster-info --namespace kube-public -o yaml | \
/bin/sed "s/\(certificate-authority-data:\).*/\1 ${base64_encoded_ca}/" | \
kubectl apply -f -
验证集群的功能正常。
检查控制面组件以及 kubelet 和 kube-proxy 的日志,确保其中没有抛出 TLS 错误,
参阅查看日志。
验证被聚合的 API 服务器的日志,以及所有使用集群内配置的 Pod 的日志。
完成集群功能的检查之后:
更新所有的服务账号令牌,使之仅包含新的 CA 证书。
从 kubeconfig 文件和 --client-ca-file 以及 --root-ca-file 标志所指向的文件
中去除老的 CA 数据,之后重启控制面组件。
在每个节点上,移除 clientCAFile 标志所指向的文件,以删除老的 CA 数据,并从
kubelet kubeconfig 文件中去掉老的 CA,重启 kubelet。
你应该用滚动更新的方式来执行这一步骤的操作。
如果你的集群允许你执行这一变更,你也可以通过替换节点而不是重新配置节点的方式来将其上线。
本文展示如何在 kubelet 中启用并配置证书轮换。
Kubernetes v1.19 [stable]
Kubelet 使用证书进行 Kubernetes API 的认证。 默认情况下,这些证书的签发期限为一年,所以不需要太频繁地进行更新。
Kubernetes 包含特性 kubelet 证书轮换, 在当前证书即将过期时, 将自动生成新的秘钥,并从 Kubernetes API 申请新的证书。 一旦新的证书可用,它将被用于与 Kubernetes API 间的连接认证。
kubelet 进程接收 --rotate-certificates 参数,该参数决定 kubelet 在当前使用的
证书即将到期时,是否会自动申请新的证书。
kube-controller-manager 进程接收 --cluster-signing-duration 参数
(在 1.19 版本之前为 --experimental-cluster-signing-duration),用来
控制签发证书的有效期限。
当 kubelet 启动时,如被配置为自举(使用--bootstrap-kubeconfig 参数),kubelet
会使用其初始证书连接到 Kubernetes API ,并发送证书签名的请求。
可以通过以下方式查看证书签名请求的状态:
kubectl get csr
最初,来自节点上 kubelet 的证书签名请求处于 Pending 状态。 如果证书签名请求满足特定条件,
控制器管理器会自动批准,此时请求会处于 Approved 状态。 接下来,控制器管理器会签署证书,
证书的有效期限由 --cluster-signing-duration 参数指定,签署的证书会被附加到证书签名请求中。
Kubelet 会从 Kubernetes API 取回签署的证书,并将其写入磁盘,存储位置通过 --cert-dir
参数指定。
然后 kubelet 会使用新的证书连接到 Kubernetes API。
当签署的证书即将到期时,kubelet 会使用 Kubernetes API,自动发起新的证书签名请求。 该请求会发生在证书的有效时间剩下 30% 到 10% 之间的任意时间点。 同样地,控制器管理器会自动批准证书请求,并将签署的证书附加到证书签名请求中。 Kubelet 会从 Kubernetes API 取回签署的证书,并将其写入磁盘。 然后它会更新与 Kubernetes API 的连接,使用新的证书重新连接到 Kubernetes API。
本文介绍了如何对 DaemonSet 执行滚动更新。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
DaemonSet 有两种更新策略:
OnDelete:使用 OnDelete 更新策略时,在更新 DaemonSet 模板后,只有当你手动删除老的
DaemonSet Pod 之后,新的 DaemonSet Pod 才会被自动创建。跟 Kubernetes 1.6 以前的版本类似。RollingUpdate:这是默认的更新策略。使用 RollingUpdate 更新策略时,在更新 DaemonSet 模板后,
老的 DaemonSet Pod 将被终止,并且将以受控方式自动创建新的 DaemonSet Pod。
更新期间,最多只能有 DaemonSet 的一个 Pod 运行于每个节点上。要启用 DaemonSet 的滚动更新功能,必须设置 .spec.updateStrategy.type 为 RollingUpdate。
你可能想设置
.spec.updateStrategy.rollingUpdate.maxUnavailable(默认为 1)、
.spec.minReadySeconds(默认为 0)和
.spec.updateStrategy.rollingUpdate.maxSurge
(默认为 0)。
RollingUpdate 更新策略的 DaemonSet 下面的 YAML 包含一个 DaemonSet,其更新策略为 'RollingUpdate':
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 这些容忍度设置是为了让该守护进程集在控制平面节点上运行
# 如果你不希望自己的控制平面节点运行 Pod,可以删除它们
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
检查了 DaemonSet 清单中更新策略的设置之后,创建 DaemonSet:
kubectl create -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml
另一种方式是如果你希望使用 kubectl apply 来更新 DaemonSet 的话,
也可以使用 kubectl apply 来创建 DaemonSet:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml
首先,检查 DaemonSet 的更新策略,确保已经将其设置为 RollingUpdate:
kubectl get ds/fluentd-elasticsearch -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}' -n kube-system
如果还没在系统中创建 DaemonSet,请使用以下命令检查 DaemonSet 的清单:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset.yaml --dry-run=client -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}'
两个命令的输出都应该为:
RollingUpdate
如果输出不是 RollingUpdate,请返回并相应地修改 DaemonSet 对象或者清单。
对 RollingUpdate DaemonSet 的 .spec.template 的任何更新都将触发滚动更新。
这可以通过几个不同的 kubectl 命令来完成。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
# 这些容忍度设置是为了让该守护进程集在控制平面节点上运行
# 如果你不希望自己的控制平面节点运行 Pod,可以删除它们
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
如果你使用配置文件来更新
DaemonSet,请使用 kubectl apply:
kubectl apply -f https://k8s.io/examples/controllers/fluentd-daemonset-update.yaml
如果你使用指令式命令来更新
DaemonSets,请使用 kubectl edit:
kubectl edit ds/fluentd-elasticsearch -n kube-system
如果你只需要更新 DaemonSet 模板里的容器镜像,比如 .spec.template.spec.containers[*].image,
请使用 kubectl set image:
kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=quay.io/fluentd_elasticsearch/fluentd:v2.6.0 -n kube-system
最后,观察 DaemonSet 最新滚动更新的进度:
kubectl rollout status ds/fluentd-elasticsearch -n kube-system
当滚动更新完成时,输出结果如下:
daemonset "fluentd-elasticsearch" successfully rolled out
有时,DaemonSet 滚动更新可能卡住,以下是一些可能的原因:
DaemonSet 滚动更新可能会卡住,其 Pod 至少在某个节点上无法调度运行。 当节点上可用资源耗尽时, 这是可能的。
发生这种情况时,通过对 kubectl get nodes 和下面命令行的输出作比较,
找出没有调度 DaemonSet Pod 的节点:
kubectl get pods -l name=fluentd-elasticsearch -o wide -n kube-system
一旦找到这些节点,从节点上删除一些非 DaemonSet Pod,为新的 DaemonSet Pod 腾出空间。
如果最近的 DaemonSet 模板更新被破坏了,比如,容器处于崩溃循环状态或者容器镜像不存在 (通常由于拼写错误),就会发生 DaemonSet 滚动更新中断。
要解决此问题,需再次更新 DaemonSet 模板。新的滚动更新不会被以前的不健康的滚动更新阻止。
如果在 DaemonSet 中指定了 .spec.minReadySeconds,主控节点和工作节点之间的时钟偏差会使
DaemonSet 无法检测到正确的滚动更新进度。
从名字空间中删除 DaemonSet:
kubectl delete ds fluentd-elasticsearch -n kube-system
本文展示了如何对 DaemonSet 执行回滚。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须不低于版本 1.7. 要获知版本信息,请输入kubectl version.
你应该已经了解如何为 DaemonSet 执行滚动更新。
如果只想回滚到最后一个版本,可以跳过这一步。
列出 DaemonSet 的所有版本:
kubectl rollout history daemonset <daemonset-name>
此命令返回 DaemonSet 版本列表:
daemonsets "<daemonset-name>"
REVISION CHANGE-CAUSE
1 ...
2 ...
...
kubernetes.io/change-cause 注解(annotation)
复制到其修订版本中。用户可以在 kubectl 命令中设置 --record=true,
将执行的命令记录在变化原因注解中。执行以下命令,来查看指定版本的详细信息:
kubectl rollout history daemonset <daemonset-name> --revision=1
该命令返回相应修订版本的详细信息:
daemonsets "<daemonset-name>" with revision #1
Pod Template:
Labels: foo=bar
Containers:
app:
Image: ...
Port: ...
Environment: ...
Mounts: ...
Volumes: ...
# 在 --to-revision 中指定你从步骤 1 中获取的修订版本
kubectl rollout undo daemonset <daemonset-name> --to-revision=<revision>
如果成功,命令会返回:
daemonset "<daemonset-name>" rolled back
--to-revision 参数未指定,将选中最近的版本。
kubectl rollout undo daemonset 向服务器表明启动 DaemonSet 回滚。
真正的回滚是在集群的
控制面
异步完成的。
执行以下命令,来监视 DaemonSet 回滚进度:
kubectl rollout status ds/<daemonset-name>
回滚完成时,输出形如:
daemonset "<daemonset-name>" successfully rolled out
在前面的 kubectl rollout history 步骤中,你获得了一个修订版本列表,每个修订版本都存储在名为
ControllerRevision 的资源中。
要查看每个修订版本中保存的内容,可以找到 DaemonSet 修订版本的原生资源:
kubectl get controllerrevision -l <daemonset-selector-key>=<daemonset-selector-value>
该命令返回 ControllerRevisions 列表:
NAME CONTROLLER REVISION AGE
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 1 1h
<daemonset-name>-<revision-hash> DaemonSet/<daemonset-name> 2 1h
每个 ControllerRevision 中存储了相应 DaemonSet 版本的注解和模板。
kubectl rollout undo 选择特定的 ControllerRevision,并用
ControllerRevision 中存储的模板代替 DaemonSet 的模板。
kubectl rollout undo 相当于通过其他命令(如 kubectl edit 或 kubectl apply)
将 DaemonSet 模板更新至先前的版本。
ControllerRevision 版本号 (.revision 字段) 会增加。
例如,如果用户在系统中有版本 1 和版本 2,并从版本 2 回滚到版本 1,
带有 .revision: 1 的 ControllerRevision 将变为 .revision: 3。
本页演示了你如何能够仅在某些节点上作为 DaemonSet 的一部分运行Pod。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
设想一下你想要运行 DaemonSet, 但你只需要在配备了本地固态 (SSD) 存储的节点上运行这些守护进程 Pod。 例如,Pod 可以向节点提供缓存服务,而缓存仅在低延迟本地存储可用时才有用。
在配有 SSD 的节点上打标签 ssd=true。
kubectl label nodes example-node-1 example-node-2 ssd=true
让我们创建一个 DaemonSet, 它将仅在打了 SSD 标签的节点上制备守护进程 Pod。
接下来,使用 nodeSelector 确保 DaemonSet 仅在 ssd 标签设为 "true" 的节点上运行 Pod。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ssd-driver
labels:
app: nginx
spec:
selector:
matchLabels:
app: ssd-driver-pod
template:
metadata:
labels:
app: ssd-driver-pod
spec:
nodeSelector:
ssd: "true"
containers:
- name: example-container
image: example-image使用 kubectl create 或 kubectl apply 从清单创建 DaemonSet。
让我们为另一个节点打上标签 ssd=true。
kubectl label nodes example-node-3 ssd=true
节点打上标签后将自动触发控制平面(具体而言是 DaemonSet 控制器)在该节点上运行新的守护进程 Pod。
kubectl get pods -o wide
输出类似于:
NAME READY STATUS RESTARTS AGE IP NODE
<daemonset-name><some-hash-01> 1/1 Running 0 13s ..... example-node-1
<daemonset-name><some-hash-02> 1/1 Running 0 13s ..... example-node-2
<daemonset-name><some-hash-03> 1/1 Running 0 5s ..... example-node-3
当 DNS 配置以及其它选项不合理的时候,通过向 Pod 的 /etc/hosts 文件中添加条目,
可以在 Pod 级别覆盖对主机名的解析。你可以通过 PodSpec 的 HostAliases
字段来添加这些自定义条目。
建议通过使用 HostAliases 来进行修改,因为该文件由 Kubelet 管理,并且 可以在 Pod 创建/重启过程中被重写。
让我们从一个 Nginx Pod 开始,该 Pod 被分配一个 IP:
kubectl run nginx --image nginx
pod/nginx created
检查 Pod IP:
kubectl get pods --output=wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
主机文件的内容如下所示:
kubectl exec nginx -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.4 nginx
默认情况下,hosts 文件只包含 IPv4 和 IPv6 的样板内容,像 localhost 和主机名称。
除了默认的样板内容,你可以向 hosts 文件添加额外的条目。
例如,要将 foo.local、bar.local 解析为 127.0.0.1,
将 foo.remote、 bar.remote 解析为 10.1.2.3,你可以在
.spec.hostAliases 下为 Pod 配置 HostAliases。
apiVersion: v1
kind: Pod
metadata:
name: hostaliases-pod
spec:
restartPolicy: Never
hostAliases:
- ip: "127.0.0.1"
hostnames:
- "foo.local"
- "bar.local"
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
containers:
- name: cat-hosts
image: busybox:1.28
command:
- cat
args:
- "/etc/hosts"
你可以使用以下命令用此配置启动 Pod:
kubectl apply -f https://k8s.io/examples/service/networking/hostaliases-pod.yaml
pod/hostaliases-pod created
检查 Pod 详情,查看其 IPv4 地址和状态:
kubectl get pod --output=wide
NAME READY STATUS RESTARTS AGE IP NODE
hostaliases-pod 0/1 Completed 0 6s 10.200.0.5 worker0
hosts 文件的内容看起来类似如下所示:
kubectl logs hostaliases-pod
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.200.0.5 hostaliases-pod
# Entries added by HostAliases.
127.0.0.1 foo.local bar.local
10.1.2.3 foo.remote bar.remote
在最下面额外添加了一些条目。
kubelet 管理每个Pod 容器的 hosts 文件,以防止容器运行时在容器已经启动后修改文件。
由于历史原因,Kubernetes 总是使用 Docker Engine 作为其容器运行时,而 Docker Engine
将在容器启动后修改 /etc/hosts 文件。
当前的 Kubernetes 可以使用多种容器运行时;即便如此,kubelet 管理在每个容器中创建 hosts文件, 以便你使用任何容器运行时运行容器时,结果都符合预期。
请避免手工更改容器内的 hosts 文件内容。
如果你对 hosts 文件做了手工修改,这些修改都会在容器退出时丢失。
Kubernetes v1.29 [alpha]
本文将介绍如何扩展分配给集群的现有 Service IP 范围。
你必须拥有一个 Kubernetes 的集群,同时你必须配置 kubectl 命令行工具与你的集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面的 Kubernetes 练习环境之一:
你的 Kubernetes 服务器版本必须是 v1.29. 要获知版本信息,请输入kubectl version.
如果 Kubernetes 集群的 kube-apiserver 启用了 MultiCIDRServiceAllocator
特性门控和
networking.k8s.io/v1alpha1 API,集群将创建一个新的 ServiceCIDR 对象,
该对象采用 kubernetes 这个众所周知的名称并基于 kube-apiserver 的 --service-cluster-ip-range
命令行参数的值来使用 IP 地址范围。
kubectl get servicecidr
NAME CIDRS AGE
kubernetes 10.96.0.0/28 17d
公认的 kubernetes Service 将 kube-apiserver 的端点暴露给 Pod,
计算出默认 ServiceCIDR 范围中的第一个 IP 地址,并将该 IP 地址用作其集群 IP 地址。
kubectl get service kubernetes
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17d
在本例中,默认 Service 使用具有对应 IPAddress 对象的 ClusterIP 10.96.0.1。
kubectl get ipaddress 10.96.0.1
NAME PARENTREF
10.96.0.1 services/default/kubernetes
ServiceCIDR 受到 终结器 的保护, 以避免留下孤立的 Service ClusterIP;只有在存在包含现有 IPAddress 的另一个子网或者没有属于此子网的 IPAddress 时,才会移除终结器。
有时候用户需要增加可供 Service 使用的 IP 地址数量。 以前,增加 Service 范围是一个可能导致数据丢失的破坏性操作。 有了这个新的特性后,用户只需添加一个新的 ServiceCIDR 对象,便能增加可用地址的数量。
对于 Service 范围为 10.96.0.0/28 的集群,只有 2^(32-28) - 2 = 14 个可用的 IP 地址。
kubernetes.default Service 始终会被创建;在这个例子中,你只剩下了 13 个可能的 Service。
for i in $(seq 1 13); do kubectl create service clusterip "test-$i" --tcp 80 -o json | jq -r .spec.clusterIP; done
10.96.0.11
10.96.0.5
10.96.0.12
10.96.0.13
10.96.0.14
10.96.0.2
10.96.0.3
10.96.0.4
10.96.0.6
10.96.0.7
10.96.0.8
10.96.0.9
error: failed to create ClusterIP service: Internal error occurred: failed to allocate a serviceIP: range is full
通过创建一个扩展或新增 IP 地址范围的新 ServiceCIDR,你可以提高 Service 可用的 IP 地址数量。
cat <EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1alpha1
kind: ServiceCIDR
metadata:
name: newcidr1
spec:
cidrs:
- 10.96.0.0/24
EOF
servicecidr.networking.k8s.io/newcidr1 created
这将允许你创建新的 Service,其 ClusterIP 将从这个新的范围中选取。
for i in $(seq 13 16); do kubectl create service clusterip "test-$i" --tcp 80 -o json | jq -r .spec.clusterIP; done
10.96.0.48
10.96.0.200
10.96.0.121
10.96.0.144
如果存在依赖于 ServiceCIDR 的 IPAddress,你将无法删除 ServiceCIDR。
kubectl delete servicecidr newcidr1
servicecidr.networking.k8s.io "newcidr1" deleted
Kubernetes 在 ServiceCIDR 上使用一个终结器来跟踪这种依赖关系。
kubectl get servicecidr newcidr1 -o yaml
apiVersion: networking.k8s.io/v1alpha1
kind: ServiceCIDR
metadata:
creationTimestamp: "2023-10-12T15:11:07Z"
deletionGracePeriodSeconds: 0
deletionTimestamp: "2023-10-12T15:12:45Z"
finalizers:
- networking.k8s.io/service-cidr-finalizer
name: newcidr1
resourceVersion: "1133"
uid: 5ffd8afe-c78f-4e60-ae76-cec448a8af40
spec:
cidrs:
- 10.96.0.0/24
status:
conditions:
- lastTransitionTime: "2023-10-12T15:12:45Z"
message:
There are still IPAddresses referencing the ServiceCIDR, please remove
them or create a new ServiceCIDR
reason: OrphanIPAddress
status: "False"
type: Ready
移除一些 Service,这些 Service 包含阻止删除 ServiceCIDR 的 IP 地址:
for i in $(seq 13 16); do kubectl delete service "test-$i" ; done
service "test-13" deleted
service "test-14" deleted
service "test-15" deleted
service "test-16" deleted
控制平面会注意到这种移除操作。控制平面随后会移除其终结器,以便真正移除待删除的 ServiceCIDR。
kubectl get servicecidr newcidr1
Error from server (NotFound): servicecidrs.networking.k8s.io "newcidr1" not found
本文分享了如何验证 IPv4/IPv6 双协议栈的 Kubernetes 集群。
kubectl version.
每个双协议栈节点应分配一个 IPv4 块和一个 IPv6 块。
通过运行以下命令来验证是否配置了 IPv4/IPv6 Pod 地址范围。
将示例节点名称替换为集群中的有效双协议栈节点。
在此示例中,节点的名称为 k8s-linuxpool1-34450317-0:
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template='{{range .spec.podCIDRs}}{{printf "%s\n" .}}{{end}}'
10.244.1.0/24
2001:db8::/64
应该分配一个 IPv4 块和一个 IPv6 块。
验证节点是否检测到 IPv4 和 IPv6 接口。用集群中的有效节点替换节点名称。
在此示例中,节点名称为 k8s-linuxpool1-34450317-0:
kubectl get nodes k8s-linuxpool1-34450317-0 -o go-template --template='{{range .status.addresses}}{{printf "%s: %s\n" .type .address}}{{end}}'
Hostname: k8s-linuxpool1-34450317-0
InternalIP: 10.0.0.5
InternalIP: 2001:db8:10::5
验证 Pod 已分配了 IPv4 和 IPv6 地址。用集群中的有效 Pod 替换 Pod 名称。
在此示例中,Pod 名称为 pod01:
kubectl get pods pod01 -o go-template --template='{{range .status.podIPs}}{{printf "%s\n" .ip}}{{end}}'
10.244.1.4
2001:db8::4
你也可以通过 status.podIPs 使用 Downward API 验证 Pod IP。
以下代码段演示了如何通过容器内称为 MY_POD_IPS 的环境变量公开 Pod 的 IP 地址。
env:
- name: MY_POD_IPS
valueFrom:
fieldRef:
fieldPath: status.podIPs
使用以下命令打印出容器内部 MY_POD_IPS 环境变量的值。
该值是一个逗号分隔的列表,与 Pod 的 IPv4 和 IPv6 地址相对应。
kubectl exec -it pod01 -- set | grep MY_POD_IPS
MY_POD_IPS=10.244.1.4,2001:db8::4
Pod 的 IP 地址也将被写入容器内的 /etc/hosts 文件中。
在双栈 Pod 上执行 cat /etc/hosts 命令操作。
从输出结果中,你可以验证 Pod 的 IPv4 和 IPv6 地址。
kubectl exec -it pod01 -- cat /etc/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.244.1.4 pod01
2001:db8::4 pod01
创建以下未显式定义 .spec.ipFamilyPolicy 的 Service。
Kubernetes 将从首个配置的 service-cluster-ip-range 给 Service 分配集群 IP,
并将 .spec.ipFamilyPolicy 设置为 SingleStack。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
使用 kubectl 查看 Service 的 YAML 定义。
kubectl get svc my-service -o yaml
该 Service 通过在 kube-controller-manager 的 --service-cluster-ip-range
标志设置的第一个配置范围,将 .spec.ipFamilyPolicy 设置为 SingleStack,
将 .spec.clusterIP 设置为 IPv4 地址。
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: default
spec:
clusterIP: 10.0.217.164
clusterIPs:
- 10.0.217.164
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 9376
selector:
app.kubernetes.io/name: MyApp
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
创建以下显式定义 .spec.ipFamilies 数组中的第一个元素为 IPv6 的 Service。
Kubernetes 将 service-cluster-ip-range 配置的 IPv6 地址范围给 Service 分配集群 IP,
并将 .spec.ipFamilyPolicy 设置为 SingleStack。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
ipFamilies:
- IPv6
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
使用 kubectl 查看 Service 的 YAML 定义。
kubectl get svc my-service -o yaml
该 Service 通过在 kube-controller-manager 的 --service-cluster-ip-range
标志设置的 IPv6 地址范围,将 .spec.ipFamilyPolicy 设置为 SingleStack,
将 .spec.clusterIP 设置为 IPv6 地址。
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: MyApp
name: my-service
spec:
clusterIP: 2001:db8:fd00::5118
clusterIPs:
- 2001:db8:fd00::5118
ipFamilies:
- IPv6
ipFamilyPolicy: SingleStack
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app.kubernetes.io/name: MyApp
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
创建以下显式定义 .spec.ipFamilyPolicy 为 PreferDualStack 的 Service。
Kubernetes 将分配 IPv4 和 IPv6 地址(因为该集群启用了双栈),
并根据 .spec.ipFamilies 数组中第一个元素的地址族,
从 .spec.ClusterIPs 列表中选择 .spec.ClusterIP。
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
ipFamilyPolicy: PreferDualStack
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
kubectl get svc 命令将仅在 CLUSTER-IP 字段中显示主 IP。
kubectl get svc -l app.kubernetes.io/name=MyApp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service ClusterIP 10.0.216.242 <none> 80/TCP 5s
使用 kubectl describe 验证服务是否从 IPv4 和 IPv6 地址块中获取了集群 IP。
然后你就可以通过 IP 和端口,验证对服务的访问。
kubectl describe svc -l app.kubernetes.io/name=MyApp
Name: my-service
Namespace: default
Labels: app.kubernetes.io/name=MyApp
Annotations: <none>
Selector: app.kubernetes.io/name=MyApp
Type: ClusterIP
IP Family Policy: PreferDualStack
IP Families: IPv4,IPv6
IP: 10.0.216.242
IPs: 10.0.216.242,2001:db8:fd00::af55
Port: <unset> 80/TCP
TargetPort: 9376/TCP
Endpoints: <none>
Session Affinity: None
Events: <none>
如果云提供商支持配置启用 IPv6 的外部负载均衡器,则创建如下 Service 时将
.spec.ipFamilyPolicy 设置为 PreferDualStack, 并将 spec.ipFamilies 字段
的第一个元素设置为 IPv6,将 type 字段设置为 LoadBalancer:
apiVersion: v1
kind: Service
metadata:
name: my-service
labels:
app.kubernetes.io/name: MyApp
spec:
ipFamilyPolicy: PreferDualStack
ipFamilies:
- IPv6
type: LoadBalancer
selector:
app.kubernetes.io/name: MyApp
ports:
- protocol: TCP
port: 80
检查服务:
kubectl get svc -l app.kubernetes.io/name=MyApp
验证服务是否从 IPv6 地址块中接收到 CLUSTER-IP 地址以及 EXTERNAL-IP。
然后,你可以通过 IP 和端口验证对服务的访问。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service LoadBalancer 2001:db8:fd00::7ebc 2603:1030:805::5 80:30790/TCP 35s
Kubernetes v1.26 [stable]
Kubernetes 支持使用设备插件来跨集群中的不同节点管理 AMD 和 NVIDIA GPU(图形处理单元),目前处于稳定状态。
本页介绍用户如何使用 GPU 以及当前存在的一些限制。
Kubernetes 实现了设备插件(Device Plugin),让 Pod 可以访问类似 GPU 这类特殊的硬件功能特性。
作为集群管理员,你要在节点上安装来自对应硬件厂商的 GPU 驱动程序,并运行来自 GPU 厂商的对应设备插件。以下是一些厂商说明的链接:
一旦你安装了插件,你的集群就会暴露一个自定义可调度的资源,例如 amd.com/gpu 或 nvidia.com/gpu。
你可以通过请求这个自定义的 GPU 资源在你的容器中使用这些 GPU,其请求方式与请求 cpu 或 memory 时相同。
不过,在如何指定自定义设备的资源请求方面存在一些限制。
GPU 只能在 limits 部分指定,这意味着:
limits 而不指定其 requests,因为 Kubernetes 将默认使用限制值作为请求值。limits 和 requests,不过这两个值必须相等。requests 而不指定 limits。以下是一个 Pod 请求 GPU 的示例清单:
apiVersion: v1
kind: Pod
metadata:
name: example-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: example-vector-add
image: "registry.example/example-vector-add:v42"
resources:
limits:
gpu-vendor.example/example-gpu: 1 # 请求 1 个 GPU
如果集群内部的不同节点上有不同类型的 NVIDIA GPU, 那么你可以使用节点标签和节点选择器来将 Pod 调度到合适的节点上。
例如:
# 为你的节点加上它们所拥有的加速器类型的标签
kubectl label nodes node1 accelerator=example-gpu-x100
kubectl label nodes node2 accelerator=other-gpu-k915
这个标签键 accelerator 只是一个例子;如果你愿意,可以使用不同的标签键。
作为管理员,你可以通过部署 Kubernetes Node Feature Discovery (NFD) 来自动发现所有启用 GPU 的节点并为其打标签。NFD 检测 Kubernetes 集群中每个节点上可用的硬件特性。 通常,NFD 被配置为以节点标签广告这些特性,但 NFD 也可以添加扩展的资源、注解和节点污点。 NFD 兼容所有支持版本的 Kubernetes。 NFD 默认会为检测到的特性创建特性标签。 管理员可以利用 NFD 对具有某些具体特性的节点添加污点,以便只有请求这些特性的 Pod 可以被调度到这些节点上。
你还需要一个 NFD 插件,将适当的标签添加到你的节点上; 这些标签可以是通用的,也可以是供应商特定的。你的 GPU 供应商可能会为 NFD 提供第三方插件; 更多细节请查阅他们的文档。
apiVersion: v1
kind: Pod
metadata:
name: example-vector-add
spec:
restartPolicy: OnFailure
# 你可以使用 Kubernetes 节点亲和性将此 Pod 调度到提供其容器所需的那种 GPU 的节点上
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "gpu.gpu-vendor.example/installed-memory"
operator: Gt #(大于)
values: ["40535"]
- key: "feature.node.kubernetes.io/pci-10.present" # NFD 特性标签
values: ["true"] #(可选)仅调度到具有 PCI 设备 10 的节点上
containers:
- name: example-vector-add
image: "registry.example/example-vector-add:v42"
resources:
limits:
gpu-vendor.example/example-gpu: 1 # 请求 1 个 GPUKubernetes v1.29 [stable]
Kubernetes 支持在 Pod 应用中使用预先分配的巨页。本文描述了用户如何使用巨页,以及当前的限制。
为了使节点能够上报巨页容量,Kubernetes 节点必须预先分配巨页。
节点能够预先分配多种规格的巨页。例如,在 /etc/default/grub
中的以下这一行分配了 2*1GiB 的 1 GiB 页面和 512*2 MiB 的 2 MiB 页面。
GRUB_CMDLINE_LINUX="hugepagesz=1G hugepages=2 hugepagesz=2M hugepages=512"
节点将自动发现并报告所有巨页资源作为可调度资源。
当你描述 Node 时,你应该在 Capacity 和 Allocatable 节中看到类似以下内容:
Capacity:
cpu: ...
ephemeral-storage: ...
hugepages-1Gi: 2Gi
hugepages-2Mi: 1Gi
memory: ...
pods: ...
Allocatable:
cpu: ...
ephemeral-storage: ...
hugepages-1Gi: 2Gi
hugepages-2Mi: 1Gi
memory: ...
pods: ...
对于动态分配的页面(引导后),kubelet 需要被重新启动才能更新为新的分配。
用户可以通过在容器级别的资源需求中使用资源名称 hugepages-<size>
来使用巨页,其中的 size 是特定节点上支持的以整数值表示的最小二进制单位。
例如,如果一个节点支持 2048KiB 和 1048576KiB 页面大小,它将公开可调度的资源
hugepages-2Mi 和 hugepages-1Gi。与 CPU 或内存不同,巨页不支持过量使用(overcommit)。
注意,在请求巨页资源时,还必须请求内存或 CPU 资源。
同一 Pod 的 spec 中可能会消耗不同尺寸的巨页。在这种情况下,它必须对所有挂载卷使用
medium: HugePages-<hugepagesize> 标识。
apiVersion: v1
kind: Pod
metadata:
name: huge-pages-example
spec:
containers:
- name: example
image: fedora:latest
command:
- sleep
- inf
volumeMounts:
- mountPath: /hugepages-2Mi
name: hugepage-2mi
- mountPath: /hugepages-1Gi
name: hugepage-1gi
resources:
limits:
hugepages-2Mi: 100Mi
hugepages-1Gi: 2Gi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage-2mi
emptyDir:
medium: HugePages-2Mi
- name: hugepage-1gi
emptyDir:
medium: HugePages-1Gi
Pod 只有在请求同一大小的巨页时才使用 medium:HugePages。
apiVersion: v1
kind: Pod
metadata:
name: huge-pages-example
spec:
containers:
- name: example
image: fedora:latest
command:
- sleep
- inf
volumeMounts:
- mountPath: /hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage
emptyDir:
medium: HugePages
SHM_HUGETLB 的 shmget() 使用巨页的应用,必须运行在一个与
proc/sys/vm/hugetlb_shm_group 匹配的补充组下。hugepages-<size> 标记控制每个命名空间下的巨页使用量,
类似于使用 cpu 或 memory 来控制其他计算资源。本指南演示了如何为 kubectl 安装和编写扩展。
通过将核心 kubectl 命令看作与 Kubernetes 集群交互的基本构建块,
集群管理员可以将插件视为一种利用这些构建块创建更复杂行为的方法。
插件用新的子命令扩展了 kubectl,允许新的和自定义的特性不包括在 kubectl 的主要发行版中。
你需要安装一个可用的 kubectl 可执行文件。
插件是一个独立的可执行文件,名称以 kubectl- 开头。
要安装插件,将其可执行文件移动到 PATH 中的任何位置。
你也可以使用 Krew 来发现和安装开源的 kubectl 插件。 Krew 是一个由 Kubernetes SIG CLI 社区维护的插件管理器。
kubectl 提供一个命令 kubectl plugin list,用于搜索 PATH 查找有效的插件可执行文件。
执行此命令将遍历 PATH 中的所有文件。任何以 kubectl- 开头的可执行文件都将在这个命令的输出中以它们在
PATH 中出现的顺序显示。
任何以 kubectl- 开头的文件如果不可执行,都将包含一个警告。
对于任何相同的有效插件文件,都将包含一个警告。
你可以使用 Krew 从社区策划的插件索引
中发现和安装 kubectl 插件。
目前无法创建覆盖现有 kubectl 命令的插件。
例如,创建一个插件 kubectl-version 将导致该插件永远不会被执行,
因为现有的 kubectl version 命令总是优先于它执行。
由于这个限制,也不可能使用插件将新的子命令添加到现有的 kubectl 命令中。
例如,通过将插件命名为 kubectl-create-foo 来添加子命令 kubectl create foo 将导致该插件被忽略。
对于任何试图这样做的有效插件 kubectl plugin list 的输出中将显示警告。
你可以用任何编程语言或脚本编写插件,允许你编写命令行命令。
不需要安装插件或预加载,插件可执行程序从 kubectl 二进制文件接收继承的环境,
插件根据其名称确定它希望实现的命令路径。
例如,名为 kubectl-foo 的插件提供了命令 kubectl foo。
必须将插件的可执行文件安装在 PATH 中的某个位置。
#!/bin/bash
# 可选的参数处理
if [[ "$1" == "version" ]]
then
echo "1.0.0"
exit 0
fi
# 可选的参数处理
if [[ "$1" == "config" ]]
then
echo $KUBECONFIG
exit 0
fi
echo "I am a plugin named kubectl-foo"
要使用某插件,先要使其可执行:
sudo chmod +x ./kubectl-foo
并将它放在你的 PATH 中的任何地方:
sudo mv ./kubectl-foo /usr/local/bin
你现在可以调用你的插件作为 kubectl 命令:
kubectl foo
I am a plugin named kubectl-foo
所有参数和标记按原样传递给可执行文件:
kubectl foo version
1.0.0
所有环境变量也按原样传递给可执行文件:
export KUBECONFIG=~/.kube/config
kubectl foo config
/home/<user>/.kube/config
KUBECONFIG=/etc/kube/config kubectl foo config
/etc/kube/config
此外,传递给插件的第一个参数总是调用它的位置的绝对路径(在上面的例子中,$0 将等于 /usr/local/bin/kubectl-foo)。
如上面的例子所示,插件根据文件名确定要实现的命令路径,插件所针对的命令路径中的每个子命令都由破折号(-)分隔。
例如,当用户调用命令 kubectl foo bar baz 时,希望调用该命令的插件的文件名为 kubectl-foo-bar-baz。
插件机制不会为插件进程创建任何定制的、特定于插件的值或环境变量。
较老的插件机制会提供环境变量(例如 KUBECTL_PLUGINS_CURRENT_NAMESPACE);这种机制已被废弃。
kubectl 插件必须解析并检查传递给它们的所有参数。 参阅使用命令行运行时包了解针对 插件开发人员的 Go 库的细节。
这里是一些用户调用你的插件的时候提供额外标志和参数的场景。
这些场景时基于上述案例中的 kubectl-foo-bar-baz 插件的。
如果你运行 kubectl foo bar baz arg1 --flag=value arg2,kubectl 的插件机制将首先尝试找到
最长可能名称的插件,在本例中是 kubectl-foo-bar-baz-arg1。
当没有找到这个插件时,kubectl 就会将最后一个以破折号分隔的值视为参数(在本例中为 arg1),
并尝试找到下一个最长的名称 kubectl-foo-bar-baz。
在找到具有此名称的插件后,它将调用该插件,并在其名称之后将所有参数和标志传递给插件进程。
示例:
# 创建一个插件
echo -e '#!/bin/bash\n\necho "My first command-line argument was $1"' > kubectl-foo-bar-baz
sudo chmod +x ./kubectl-foo-bar-baz
# 将插件放到 PATH 下完成"安装"
sudo mv ./kubectl-foo-bar-baz /usr/local/bin
# 确保 kubectl 能够识别我们的插件
kubectl plugin list
The following kubectl-compatible plugins are available:
/usr/local/bin/kubectl-foo-bar-baz
# 测试通过 "kubectl" 命令来调用我们的插件时可行的
# 即使我们给插件传递一些额外的参数或标志
kubectl foo bar baz arg1 --meaningless-flag=true
My first command-line argument was arg1
正如你所看到的,你的插件是基于用户指定的 kubectl 命令找到的,
所有额外的参数和标记都是按原样传递给插件可执行文件的。
虽然 kubectl 插件机制在插件文件名中使用破折号(-)分隔插件处理的子命令序列,
但是仍然可以通过在文件名中使用下划线(_)来创建命令行中包含破折号的插件命令。
例子:
# 创建文件名中包含下划线的插件
echo -e '#!/bin/bash\n\necho "I am a plugin with a dash in my name"' > ./kubectl-foo_bar
sudo chmod +x ./kubectl-foo_bar
# 将插件放到 PATH 下
sudo mv ./kubectl-foo_bar /usr/local/bin
# 现在可以通过 kubectl 来调用插件
kubectl foo-bar
I am a plugin with a dash in my name
请注意,在插件文件名中引入下划线并不会阻止你使用 kubectl foo_bar 之类的命令。
可以使用破折号(-)或下划线(_)调用上面示例中的命令:
# 我们的插件也可以用破折号来调用
kubectl foo-bar
I am a plugin with a dash in my name
# 你也可以使用下划线来调用我们的定制命令
kubectl foo_bar
I am a plugin with a dash in my name
可以在 PATH 的不同位置提供多个文件名相同的插件,
例如,给定一个 PATH 为: PATH=/usr/local/bin/plugins:/usr/local/bin/moreplugins,
在 /usr/local/bin/plugins 和 /usr/local/bin/moreplugins 中可以存在一个插件
kubectl-foo 的副本,这样 kubectl plugin list 命令的输出就是:
PATH=/usr/local/bin/plugins:/usr/local/bin/moreplugins kubectl plugin list
The following kubectl-compatible plugins are available:
/usr/local/bin/plugins/kubectl-foo
/usr/local/bin/moreplugins/kubectl-foo
- warning: /usr/local/bin/moreplugins/kubectl-foo is overshadowed by a similarly named plugin: /usr/local/bin/plugins/kubectl-foo
error: one plugin warning was found
在上面的场景中 /usr/local/bin/moreplugins/kubectl-foo 下的警告告诉你这个插件永远不会被执行。
相反,首先出现在你 PATH 中的可执行文件 /usr/local/bin/plugins/kubectl-foo
总是首先被 kubectl 插件机制找到并执行。
解决这个问题的一种方法是你确保你希望与 kubectl 一起使用的插件的位置总是在你的 PATH 中首先出现。
例如,如果你总是想使用 /usr/local/bin/moreplugins/kubectl foo,
那么在调用 kubectl 命令 kubectl foo 时,你只需将路径的值更改为 /usr/local/bin/moreplugins:/usr/local/bin/plugins。
对于插件文件名而言还有另一种弊端,给定用户 PATH 中的两个插件 kubectl-foo-bar 和 kubectl-foo-bar-baz,
kubectl 插件机制总是为给定的用户命令选择尽可能长的插件名称。下面的一些例子进一步的说明了这一点:
# 对于给定的 kubectl 命令,最长可能文件名的插件是被优先选择的
kubectl foo bar baz
Plugin kubectl-foo-bar-baz is executed
kubectl foo bar
Plugin kubectl-foo-bar is executed
kubectl foo bar baz buz
Plugin kubectl-foo-bar-baz is executed, with "buz" as its first argument
kubectl foo bar buz
Plugin kubectl-foo-bar is executed, with "buz" as its first argument
这种设计选择确保插件子命令可以跨多个文件实现,如果需要,这些子命令可以嵌套在"父"插件命令下:
ls ./plugin_command_tree
kubectl-parent
kubectl-parent-subcommand
kubectl-parent-subcommand-subsubcommand
你可以使用前面提到的 kubectl plugin list 命令来确保你的插件可以被 kubectl 看到,
并且验证没有警告防止它被称为 kubectl 命令。
kubectl plugin list
The following kubectl-compatible plugins are available:
test/fixtures/pkg/kubectl/plugins/kubectl-foo
/usr/local/bin/kubectl-foo
- warning: /usr/local/bin/kubectl-foo is overshadowed by a similarly named plugin: test/fixtures/pkg/kubectl/plugins/kubectl-foo
plugins/kubectl-invalid
- warning: plugins/kubectl-invalid identified as a kubectl plugin, but it is not executable
error: 2 plugin warnings were found
如果你在编写 kubectl 插件,而且你选择使用 Go 语言,你可以利用 cli-runtime 工具库。
这些库提供了一些辅助函数,用来解析和更新用户的 kubeconfig 文件,向 API 服务器发起 REST 风格的请求,或者将参数绑定到某配置上, 抑或将其打印输出。
关于 CLI Runtime 仓库所提供的工具的使用实例,可参考 CLI 插件示例 项目。
如果你开发了一个插件给别人使用,你应该考虑如何为其封装打包、如何分发软件 以及将来的更新到用户。
Krew 提供了一种对插件进行打包和分发的跨平台方式。 基于这种方式,你会在所有的目标平台(Linux、Windows、macOS 等)使用同一 种打包形式,包括为用户提供更新。 Krew 也维护一个插件索引(plugin index) 以便其他人能够发现你的插件并安装之。
另一种方式是,你可以使用传统的包管理器(例如 Linux 上 的 apt 或 yum,
Windows 上的 Chocolatey、macOs 上的 Homebrew)。
只要能够将新的可执行文件放到用户的 PATH 路径上某处,这种包管理器就符合需要。
作为一个插件作者,如果你选择这种方式来分发,你就需要自己来管理和更新
你的 kubectl 插件的分发包,包括所有平台和所有发行版本。
你也可以发布你的源代码,例如,发布为某个 Git 仓库。 如果你选择这条路线,希望使用该插件的用户必须取回代码、配置一个构造环境 (如果需要编译的话)并部署该插件。 如果你也提供编译后的软件包,或者使用 Krew,那就会大大简化安装过程了。
